Comment réduire l’impact environnemental de l’IA via le Contract Management pour un numérique plus responsable ?
Comment réduire l'impact environnemental de l’IA via le Contract Management pour un numérique plus responsable ?
16 décembre 2024
Contract & Vendor Management
Jessica HONORINE
Consultante Contract & Vendor Management
Selon le journal Le Monde, les quatre grands acteurs du numérique américain (Amazon, Meta, Google et Microsoft) prévoient d’investir 200 milliards de dollars en 2024 dans de nouvelles infrastructures afin de soutenir le développement de l’intelligence artificielle (IA).
Ce financement vise à répondre à la demande croissante de puissance de calcul et à la nécessité d’augmenter le nombre de datacenters pour faire fonctionner des intelligences artificielles génératives, telles que ChatGPT ou les assistants virtuels. Les systèmes d’intelligence artificielle nécessitent d’immenses quantités de données et des calculs intensifs qui doivent être traités dans des datacenters. Les datacenters, qui fonctionnent 24/7 consomment d’énormes quantités d’énergie et d’eau.
En seulement cinq ans, les émissions de gaz à effet de serre associées au secteur numérique ont augmenté de 48 %. Le numérique, et plus particulièrement l’IA, est responsable de 3 à 4 % des émissions mondiales de gaz à effet de serre, selon le rapport de The Shift Project « Lean ICT : Pour une sobriété numérique ».
En effet, les recherches ont montré que les modèles d’IA nécessitent de plus en plus de puissance de calcul à mesure de leur sophistication, ce qui entraînerait la hausse de besoin énergétique. Il a été démontré que la consommation d’énergie pour entraîner l’IA à un langage naturel peut être supérieure à la consommation d’énergie des systèmes de machines learning.
Cette situation appelle à une action urgente pour minimiser l’impact environnemental de l’IA, notamment par le biais du Contract Management, un levier stratégique pour un numérique plus responsable.
Définir précisément le besoin avant de s’engager sur des outils de l’IA
Avant de se lancer dans l’utilisation d’outils d’intelligence artificielle, il est essentiel de définir précisément ses besoins. On peut fréquemment observer que les clients expriment un engouement pour ces technologies sans avoir une vision claire de leurs objectifs réels.
Il incombe au contract manager de jouer un rôle clé en incitant le client à clarifier et à remettre en question ses besoins. En accompagnant le client dans cette réflexion, le contract manager peut l’aider à identifier la solution la plus pertinente et à optimiser l’usage des technologies proposées, évitant ainsi la surconsommation inutile de l’intelligence artificielle.
Il peut ainsi guider le client dans ses choix en veillant à ce que les outils sélectionnés répondent réellement aux enjeux et objectifs spécifiques de l’entreprise, tout en maximisant l’efficacité et la rentabilité des projets.
Sélectionner dans la mesure du possible stratégiquement les fournisseurs garantissant l’utilisation de ressources durables
Pour limiter l’impact écologique de l’IA, il est essentiel de sélectionner des fournisseurs qui garantissent une utilisation responsable des ressources énergétiques. Cela peut se faire en intégrant des critères de sélection visant à prioriser les fournisseurs qui utilisent un pourcentage minimum d’énergie renouvelable pour alimenter leurs datacenters et infrastructures IT. En cas d’appel d’offres, il est possible de définir précisément dans le cahier des charges les attendus en termes écologiques et favoriser les fournisseurs qui ont des certifications telles que l’ISO 50 001 et 14 001 sur la performance énergétique et environnementale, ISO 26000 sur la responsabilité sociétale des entreprises ou qui ont signé le Code of Conduct for Energy Efficiency in Data Centres
Par exemple, on peut sélectionner des fournisseurs qui adoptent des technologies qui répartissent la charge de calcul sur plusieurs datacenters, minimisant ainsi la surconsommation dans un seul centre et réduisant l’empreinte carbone. D’autres fournisseurs peuvent proposer des solutions novatrices. Par exemple, un hébergeur suisse (Infomaniak) récupère la chaleur dégagée par leur datacenter et l’intègre au réseau de chauffage urbain, permettant de chauffer des foyers et fournir de l’eau chaude toute l’année, de jour comme de nuit. Cela en fait un exemple de double usage innovant : le datacenter remplit à la fois ses fonctions de stockage et de calcul de données tout en participant à la production d’énergie thermique pour les habitants locaux.
A noter qu’il peut être intéressant de faire attention au Power Usage of Effectiveness (PUE) et Water Usage of Effectiveness (WUE) qui mesure le rendement d’un datacenter entre l’énergie et l’eau qu’il utilise par rapport aux équipements dont il est pourvu. Même si ce ne sont pas les seuls indicateurs, de bons PUE et WUE garantissent un datacenter qui dispose d’une consommation d’énergie et d’eau optimale.
Pousser à l’amélioration des calculs massifs via les clauses d’amélioration continue
L’un des principaux défis de l’IA réside dans l’optimisation des calculs massifs nécessaires pour le traitement de grandes quantités de données. Ces opérations sont particulièrement énergivores. En introduisant des clauses d’amélioration continue dans les contrats, il est possible de garantir que les fournisseurs s’engagent à optimiser l’efficacité énergétique des algorithmes et des infrastructures utilisées.
Pour cela, on peut prévoir dans une clause une réévaluation régulière de l’efficacité de ses algorithmes et des infrastructures et à mettre en œuvre des technologies durables et plus efficientes.
Entre autres, on peut également encourager l’adoption de technologies qui répartissent la charge de calcul sur plusieurs datacenters, minimisant ainsi la surconsommation dans un seul centre et réduisant l’empreinte carbone.
Enfin, il est possible d’exiger que le fournisseur mette un plan d’optimisation des infrastructures de calcul à chaque cycle contractuel pour garantir que celles-ci restent à la pointe de l’efficacité énergétique.
Garantir l’optimisation des ressources IT
Il est recommandé d’ajouter des audits énergétiques réguliers dans les contrats avec les fournisseurs, permettant de mesurer l’efficacité des serveurs, des centres de données et des algorithmes IA. Ces audits doivent s’appuyer sur des indicateurs de performance précis, tels que la consommation énergétique, la réduction des ressources inactives et la répartition des flux informatiques.
Cela peut se faire en intégrant des accords de niveau de service (SLA) qui incluent des critères de performance énergétique. Une façon innovante serait d’imaginer des SLA de limitation de la consommation d’énergie. Cela nécessite d’accepter des logiciels ou des équipements plus lents. On parlerait alors de “Slow IT”.
Encourager le fournisseur à aller vers l’économie circulaire via des clauses dédiées
Il s’agit de promouvoir l’économie circulaire dans le cycle de vie des équipements technologiques, notamment pour les serveurs en fin de vie.
En effet, l’impact principal des équipements se situant durant la phase de fabrication, il est primordial de prolonger au maximum leur durée de vie. Si le fournisseur ne peut pas utiliser un équipement aussi longtemps qu’il le faudrait, il est de sa responsabilité d’organiser sa deuxième vie.
De plus, les déchets électroniques générés en fin de vie des équipements posent des défis en matière de gestion et de recyclage, souvent aboutissant à une contamination des sols et des nappes phréatiques.
Pour encourager l’économie circulaire, il serait intéressant d’inclure dans les contrats des dispositions concernant le recyclage et la réutilisation des équipements informatiques ainsi que des plans de gestion des déchets électroniques afin de minimiser leur impact environnemental pour le matériel en fin de vie.
En somme, l’impact environnemental de l’intelligence artificielle est bien plus profond qu’il n’y paraît. Au-delà des émissions de gaz à effet de serre, la construction et l’exploitation des datacenters contribuent à la pollution des sols en raison de l’extraction intensive de minerais nécessaires à la fabrication des composants électroniques. L’utilisation massive d’eau pour le refroidissement des serveurs exerce également une pression sur les ressources hydriques locales, pouvant aggraver les problèmes de pénurie d’eau dans certaines régions. Ces enjeux soulignent l’importance d’adopter une approche plus responsable et durable dans le développement de l’IA. Il est essentiel que tous les acteurs impliqués prennent des mesures concrètes pour atténuer ces impacts, en intégrant des pratiques d’économie circulaire et en favorisant des technologies moins gourmandes en ressources. Seule une prise de conscience collective permettra de concilier innovation technologique et préservation de notre environnement.
ISO 50001:2018 (Norme sur les systèmes de management de l’énergie)
GÉRER SES DÉPENSES CLOUD: UNE INTRODUCTION AU FINOPS
GÉRER SES DÉPENSES CLOUD: UNE INTRODUCTION AU FINOPS
12 décembre 2024
Architecture
Samira Hama Djibo
Consultante
Dans cette ère où les infrastructures Cloud et on premise se côtoient et se toisent, le critère de la rentabilité est déterminant. Cependant là où le Cloud nous promet des économies à petite mais surtout à grande échelle, on peut parfois tomber sur des mauvaises surprises une fois la facture reçue.
Quelle que soit la taille de l’architecture Cloud, on n’est jamais vraiment à l’abri d’un dépassement budgétaire inattendu. Mais en appliquant quelques principes simples du FinOps, on peut arriver à facilement minimiser ce risque.
Comment donc suivre efficacement ses dépenses ? Et comment optimiser financièrement son infrastructure Cloud ?
Nous allons ici nous appuyer sur le Cloud Provider AWS pour étayer nos propos ainsi que nos exemples.
Pourquoi est-ce qu’on peut se retrouver avec des factures plus importantes qu’attendu ?
Une des particularités d’une infrastructure Cloud, c’est qu’il est très facile de commissionner des ressources. Prenons a contrario une architecture on-premise: pour commissionner un serveur physique et installer des machines virtuelles, ce n’est souvent pas une mince affaire. Il faut choisir un fournisseur, lancer la commande et souvent attendre plusieurs mois sans compter d’éventuels problèmes logistiques.
De plus, la commande d’un serveur on-premise est souvent conditionnée par une étude minutieuse des caractéristiques nécessaires du serveur en question et une étude de budget à valider, réétudier etc.
En comparaison, la commande d’un serveur avec les mêmes caractéristiques sur le Cloud se fait en quelques clics, même pour un non-initié, et la disponibilité est immédiate.
La promesse du Cloud, c’est de pouvoir héberger tout aussi bien une architecture basique (comme par exemple un site web statique) qu’ une architecture extrêmement complexe répondant à des besoins spécifiques et des contraintes exigeantes. L’un des principaux clients d’AWS, l’entreprise Netflix responsable de 15% du trafic internet mondial, stocke jusqu’à 10 exaoctets (10 millions de téraoctets) de données vidéo sur le serviceAmazon S3. Ce chiffre inclut les copies stockées dans différentes régions afin d’assurer la haute disponibilité du service ainsi que sa résilience en cas de panne dans un des data centers d’AWS.
Une telle variance des offres et des possibilités que permettent le Cloud rend facile d’allouer des ressources largement supérieures à celles nécessaires, ou souscrire à des options qui, normalement conçues pour des cas très précis, font augmenter votre facture de façon apparemment démesurée..
Qu’on utilise l’interface graphique du Cloud Provider, ou alors un outil d’Infrastructure As Codecomme Terraform ou CloudFormation, sans la maîtrise suffisante au moment de l’allocation des ressources, ou par simple erreur humaine, on peut réquisitionner des ressources largement au-dessus de nos besoins, et donc se faire surprendre par une facture exorbitante.
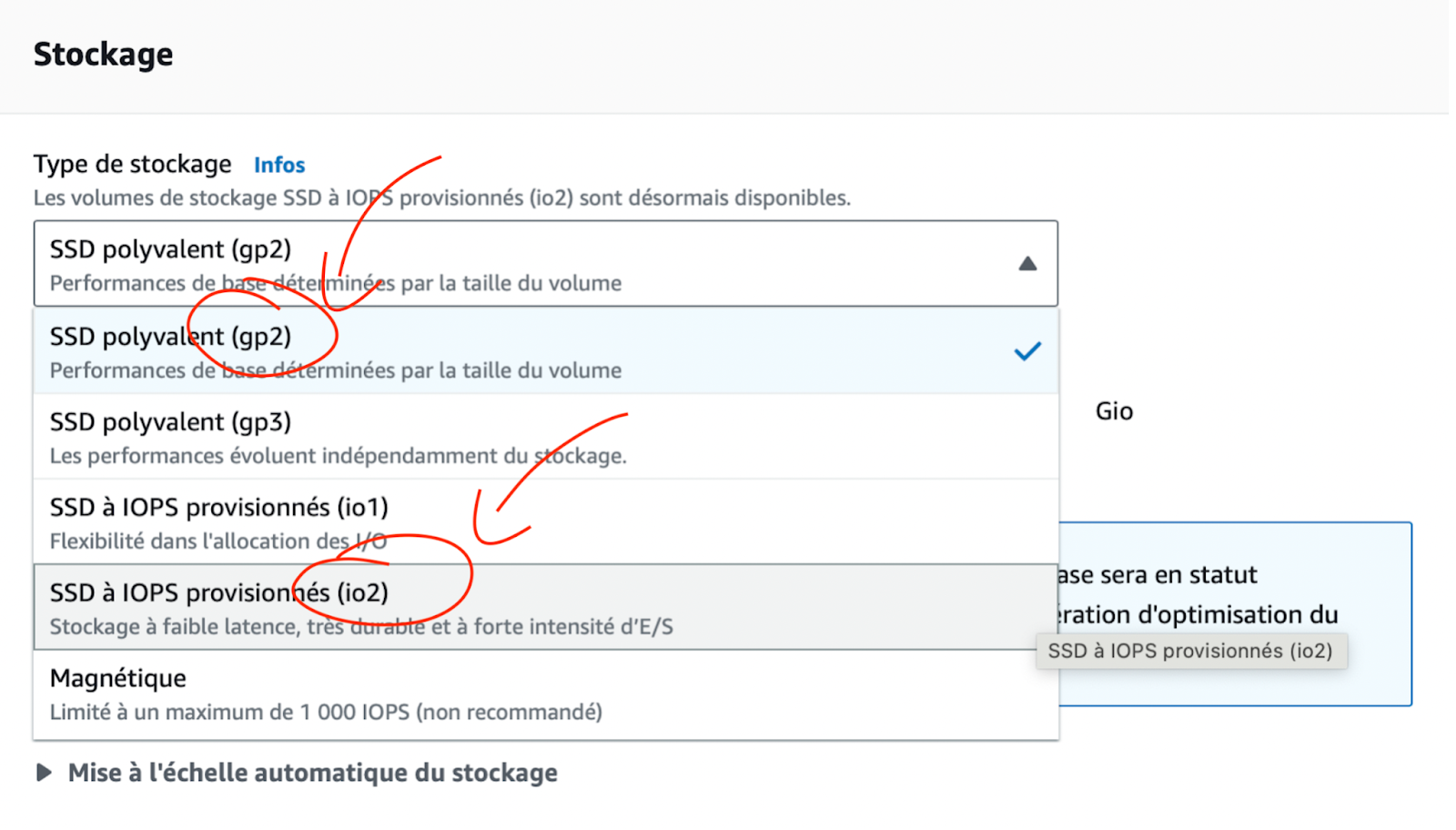
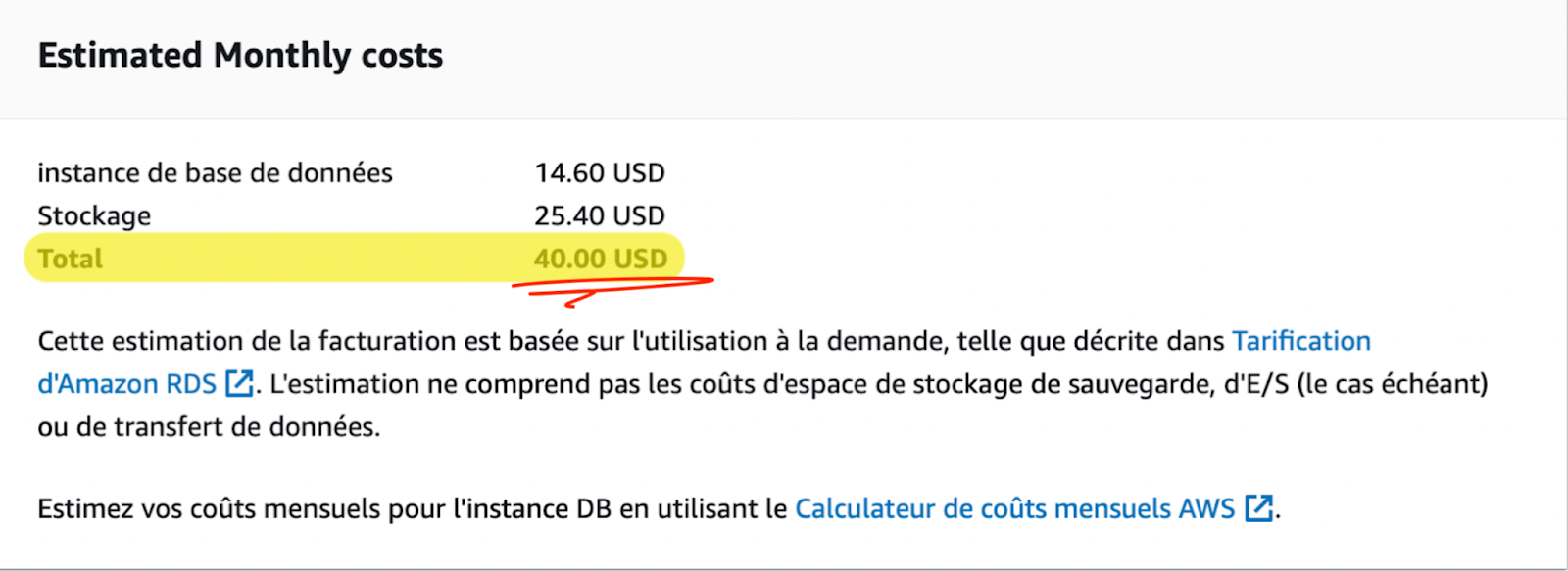
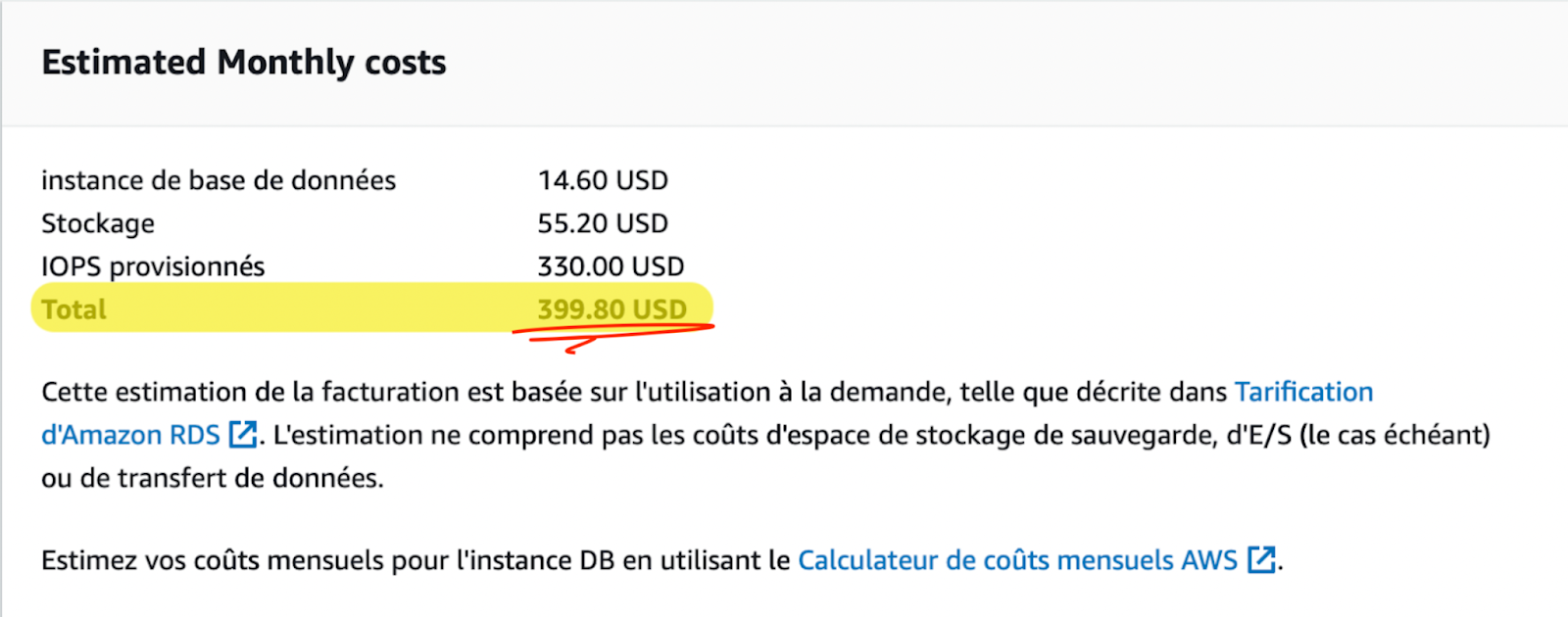
Pour illustrer ce point, prenons par exemple l’allocation d’une petite base de données via l’interface graphique d’AWS. Pour les mêmes caractéristiques de vCPU et de RAM, en choisissant par erreur, ou en méconnaissance de nos besoins réels, un stockage io2 au lieu de gp2, on multiplie tout simplement la facture par 10 !
Pour bien maîtriser les coûts, il faut donc tout d’abord une bonne maîtrise des termes techniques, du vocabulaire spécifique au Cloud Provider et ne pas se perdre dans des options trop avancées.
Une fois cela pris en compte, il faut noter que ces mêmes cloud providers mettent à disposition des outils qui permettent de facilement détecter et limiter l’impact d’erreurs de jugement ou d’implémentation.
Les solutions mises en place par les cloud providers pour pallier à ce problème
AWS a mis en place le Well-Architected Framework qui sert de guide pour la conception d’applications dotées d’infrastructures sûres, hautement performantes, résilientes et efficientes.
Le framework est basé sur six piliers: excellence opérationnelle, sécurité, fiabilité, efficacité de la performance, optimisation des coûts et durabilité.
Le pilier Optimisation des coûts qui nous intéresse le plus ici est axé sur l’évitement des coûts inutiles.
A toutes les échelles, des services sont mis en place par AWS pour faciliter l’implémentation de ce pilier. Leur connaissance et leur utilisation permettent sans faute d’optimiser le coût de son architecture.
Nous allons voir ici les approches de base qui permettent de s’assurer à un cadrage et une compréhension exhaustive de sa facture cloud et en amont l’optimisation des ressources allouées.
Il existe pour cela trois approches complémentaires:
Surveillance et budgétisation de ses dépenses,
Limitation des accès au strict nécessaire,
Optimisation des ressources avec des méthodes comme par exemple:
Le rightsizing: Le rightsizing est le processus consistant à adapter les types et tailles d’instances ni plus ni moins qu’aux exigences de performance et de capacité de la charge de travail.
Par exemple, cela peut se traduire par le fait de faire appel à de l’auto-scaling qui est la possibilité d’ajouter et supprimer des instances d’une ressources (scalability) ou augmenter et diminuer la taille de ces instances (elasticity) en fonction de l’utilisation en temps réel qui en est faite. Lorsque la charge de travail augmente, plus de ressources sont allouées, et lorsqu’elle diminue, une partie des ressources allouées est libérée.
.
Voici un autre exemple de rightsizing: Dans un projet les environnements de développement et de test sont généralement utilisés uniquement 8h par jour pendant la semaine de travail. Il est donc possible d’arrêter ces ressources lorsqu’elles ne sont pas utilisées pour réaliser des économies potentielles de 75 % (40 heures contre 168 heures).
L’utilisation de Saving Plans & Reserved instances: Prévoir et réserver à l’avance les ressources dont on aura besoin sur 1 ou 3ans permet de faire des économies jusqu’à 72% ! L’utilisation de Spot Instances – des instances éphémères – permet, elle, des économies jusqu’à 90% !
L’utilisation des classes de stockage dont on verra un exemple détaillé plus bas.
Voici quelques pratiques et services incontournables suivant ces différentes approches :
Surveiller et budgétiser ses dépenses
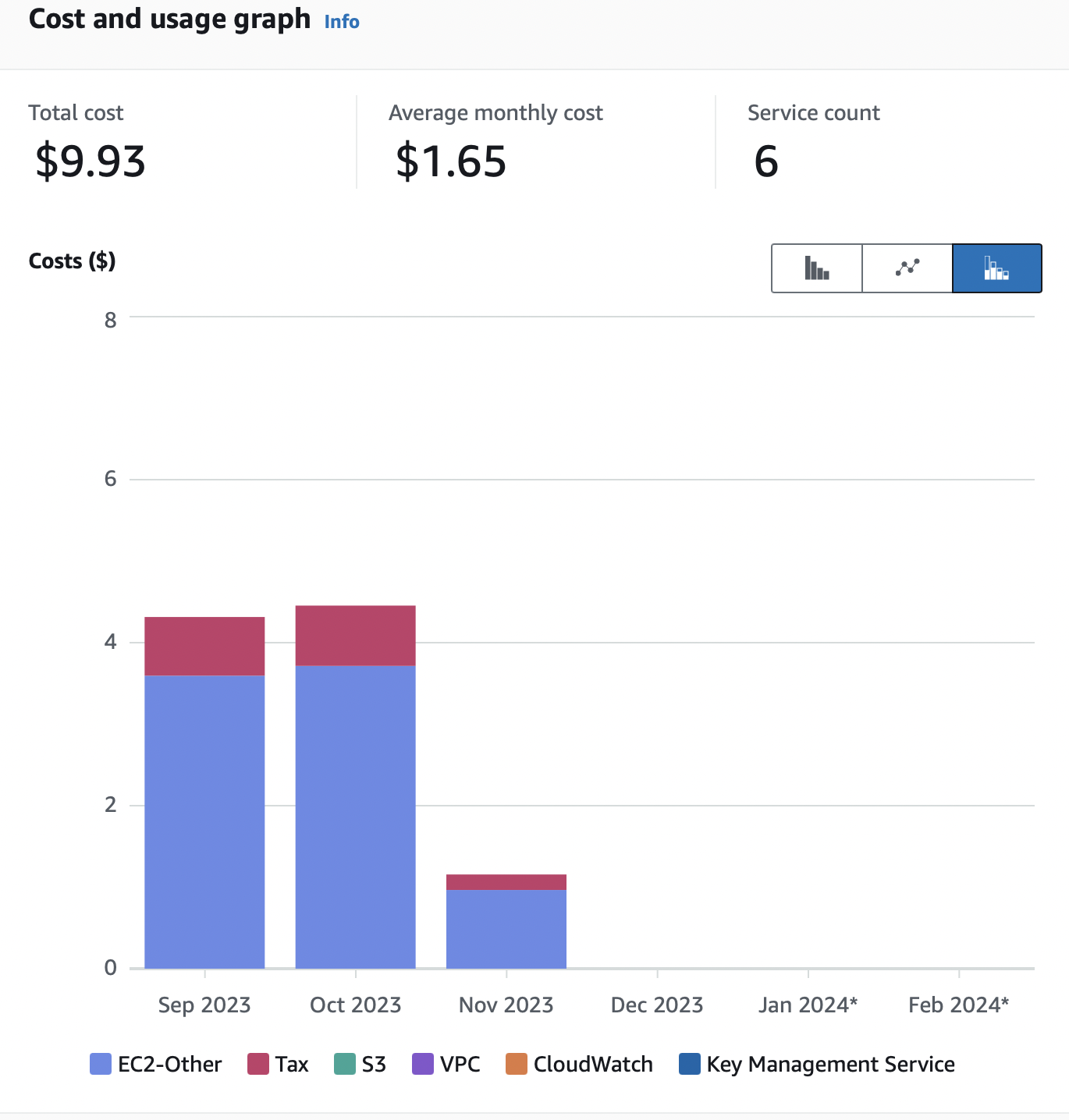
AWS Cost Explorer
C’est une solution de Cost Analysis Dashboard qui permet de voir en temps réel sur une certaine période le total des dépenses par services utilisés.
Exemple d’un Cost Analysis Dashboard
AWS Budgets
AWS Budgets permet de créer des Budgets de dépense et de les exporter notamment sous forme de rapports. Des alertes sont levées et des emails envoyés lorsque les budgets sont dépassés.
AWS Cost Anomaly detection
Grâce au machine learning, AWS peut détecter une augmentation anormales des dépenses qu’il serait plus difficile de repérer manuellement.
Parmi les services de gestion de coûts proposés par AWS, on voit que ceux présentés ici, gratuits et mis en place par défaut, permettent déjà à eux trois d’obtenir une vue assez synthétique de ses dépenses et d’être alerté en cas de potentielles anomalies.
Limiter les accès au strict nécessaire
Un des principes de base qu’il s’agit de sécurité est la limitation au maximum des accès aux ressources au strict minimum et uniquement aux personnes accréditées (principe du RBAC). Ce même principe permet de réserver la création de ressources sensibles qui peuvent, comme on l’a vu, faire rapidement monter la facture aux personnes qui sauront faire bon usage de ces droits..
Que ce soit cloud ou hors cloud, la règle est la même : le least privilege access, c’est-à-dire limiter les droits au strict minimum, en fonction du rôle, du groupe d’appartenance, et même pour les grosses organisations en fonction du département ou du sous compte AWS depuis laquelle la requête est faite.
En plus de monitorer et contrôler ses dépenses, le cloud offre plusieurs possibilités d’optimisation des coûts dont voici un exemple.
Exemples d’optimisations possibles: les classes de stockage
Prenons comme exemple une boite de finance qui stocke les dossiers de leurs clients, tout comme notre géant Netflix sur le service de stockage Amazon S3.
Au début de la procédure, les dossiers sont consultés très souvent, plus le dossier avance, moins ils sont consultés, une fois clôturés ils sont archivés. Chaque année les services d’audit consultent les dossiers archivés. Après 10 ans, ils ne sont pratiquement jamais consultés mais doivent être conservés pour des raisons légales.
AWS met en place des classes de stockage en fonction de la fréquence d’utilisation des fichiers permettant ainsi de réduire les coûts sur les fichiers qui sont plus rarement consultés.
Ainsi nous mettrons les les dossiers en cours dans la classe S3 standard, puis dans la classe S3 Standard Infrequent Accessau fur et à mesure qu’ils sont moins consultés. Une fois le dossier clôturé, nous le déplaçons dans une des classes S3 Glacier à accès instantané ou flexible. Puis une fois la période d’Audit passée, nous les archivons finalement dans la classe S3 Deep Glacier aux coûts de stockage les plus bas.
A noter que nous pouvons également déposer les fichiers directement dans la classe S3 Intelligent Tiering dans laquelle AWS se chargera automatiquement de déplacer les fichiers dans les classes les plus rentables en fonction de l’utilisation réelle constatée.
Par exemple, pour la région Europe(Irlande), les tarifs en fonction des classes sont les suivants :
S3 Standard
S3 Infrequent access
S3 Glacier
S3 Deep Archive
Prix par GB/mois
0,021€
0,011€
0,0033€
0,00091€
Frais de récupération des fichiers ?
Non
Non
Oui
Oui
En analysant le besoin ou en faisant appel aux Intelligent Tiering d’AWS, nous pouvons donc économiser jusqu’à 100% du prix standard de stockage / Gb et par mois pour les fichiers les moins consultés.
Nous avons vu ici une partie des optimisations financières rendues possibles en faisant levier de la puissance du Cloud. Les labs du Well-Architected Framework mis fournis par AWS permettent de voir de façon concrète les voies d’optimisation des coûts présentées par le Cloud provider lui-même.
En plus de l’application des principes essentiels vu dans cet article, vous pourrez creuser facilement le sujet à cette adresse.
En guise de conclusion, je me permets d’appuyer sur le fait que la connaissance à minima basique des principes fondamentaux du FinOps comme décrits dans cet article est essentielle autant au développeur qu’à l’architecte en passant par le management et la finance. C’est uniquement cette collaboration étroite qui permettra une surveillance à toutes les échelles des coûts engendrés et une optimisation financière d’un projet Cloud.
A l’air d’un monde ultra-connecté, toute moyenne ou grande entreprise envisage d’adopter ou exploite déjà au moins une nouvelle technologie telle que l’Internet des objets (IoT), l’Intelligence artificielle (IA), ou encore le streaming. Leur point commun : la gestion des données générées.
Afin de garantir la performance des systèmes, réduire les coûts de stockage, et respecter les obligations réglementaires, il est nécessaire de mettre en œuvre des solutions avancées et appliquer des bonnes pratiques pour absorber et résorber l’augmentation exponentielle des volumes de données.
C’est dans ce contexte que la purge et l’archivage de données jouent un rôle déterminant.
L’objectif de cet article est d’explorer les stratégies efficaces, les outils à implémenter pour soutenir ces activités, et énoncer les avantages de ces deux processus dans une approche de gestion durable des données.
Avant d’aborder les meilleures pratiques, il nous semble indispensable de clarifier ces deux notions fondamentales.
Deux concepts clés
Ces termes sont couramment employés dans le quotidien professionnel du monde IT, mais que signifient-ils ?
La purge physique de données (à différencier de la purge logique) est une opération qui a pour objectif de supprimer définitivement des données obsolètes ou inutilisées afin d’alléger la charge sur les systèmes.
L’archivage de données fait référence à la collecte et au transfert des données vers une plateforme sécurisée pourvue des capacités d’accessibilité et d’intégrité des données.
Bien que distincts, ces deux processus sont complémentaires, mais dans quel intérêt ?
La purge et l’archivage, une perte de temps et d’énergie ?
Une stratégie de purge et d’archivage des données ne se limite pas à simple exercice technique !
Au contraire, ces pratiques apportent de nombreux avantages :
Une meilleure performance des systèmes
Réduire les données, à plus forte raison en Production, améliore la rapidité des traitements.
Une réduction des coûts de stockage
Diminuer les données actives permet d’optimiser l’usage des ressources matérielles.
Une mise en conformité réglementaire
Conserver les données essentielles garantit le respect des normes en vigueur (ex : RGPD, HIPAA) et les politiques internes.
Une maîtrise du cycle de vie des données
Adapter la durée de conservation et la disposition des données favorise leur valeur et leur utilité.
Ces actions tendent donc à améliorer l’efficacité opérationnelle lorsqu’elles sont réalisées de manière proactive.
Quelles actions appliquer à travers ces deux processus afin d’atteindre les résultats mentionnés plus haut ?
Processus de purge et d’archivage
Les étapes structurantes de la purge
Identifier les données obsolètes
Comment reconnaître des données obsolètes ou inutilisées ?
Elles correspondent habituellement à des données redondantes, des fichiers temporaires ou des données anciennes qui n’ont plus de valeur opérationnelle.
Le responsable de l’application, les équipes Projet et Métier doivent tous contribuer à cet exercice. En effet, chacun détient une part de connaissance dans les données interprétées et générées.
Suivant la difficulté, l’identification de ces données peut être automatisée grâce à des outils d’analyse, qui repèrent les fichiers rarement voire jamais consultés.
Une fois les données obsolètes identifiées, il convient de définir des règles précises pour la purge.
Définir des règles de purge : rétention et obsolescence
A quoi correspondent les règles ?
Elles déterminent la durée de conservation des données avant de pouvoir être supprimées, en fonction de critères comme leur date de création, leur dernière utilisation ou leur classification (données sensibles, transactionnelles, etc.).
Ces règles sont alignées avec les exigences de rétention légale, réglementaire ou interne. Il est donc indispensable de réaliser ce travail avec les entités Légale et Juridique, voire la direction Financière de votre entreprise.
Après avoir défini les règles, la purge peut être activée.
Exécuter la purge en assurant une traçabilité et une validation
Ce processus doit être testé (étape importante car certaines actions pourraient être irréversibles !), puis réalisé avec la mise en œuvre d’une traçabilité afin de conserver un historique des données supprimées.
Une étape de validation finale est souvent nécessaire et conseillée pour s’assurer que des données essentielles n’ont pas été accidentellement supprimées.
L’automatisation de la purge peut inclure des étapes de vérification pour garantir l’intégrité des systèmes après l’exécution (par exemple, à travers l’interprétation des tags attribués aux données qui contribue au pilotage de la qualité de la donnée).
Pour les données non utilisées mais qui nécessitent une conservation, il convient de les archiver.
Les étapes clés de l’archivage
Sélectionner les données non critiques
L’archivage concerne les données qui ne sont plus essentielles à l’exploitation quotidienne, mais qui doivent encore être conservées pour des raisons légales, historiques ou analytiques.
Cette étape implique de trier les données pour identifier celles qui peuvent être déplacées vers un stockage de longue durée.
Les données non critiques incluent souvent des fichiers inactifs, des logs ou des versions précédentes de documents.
Une fois les données sélectionnées, il est crucial de choisir le bon support d’archivage.
Choisir un support d’archivage (cloud, stockage physique)
Les options incluent des solutions de stockage en Cloud (par exemple, Amazon S3, Microsoft Azure) ou des solutions physiques comme des serveurs internes ou des bandes magnétiques.
Le choix dépend des exigences en matière de sécurité, de coût et d’accessibilité.
Les données archivées doivent rester consultables en cas de besoin, mais sans impacter les performances des systèmes de Production.
Un plan de rétention doit être mis en place pour gérer la durée de conservation des archives et prévoir leur suppression ou leur migration à terme.
Mettre en place un plan de rétention et de restauration des archives
Ce plan doit aussi inclure des processus de restauration des données, garantissant que les informations archivées peuvent être récupérées facilement (attention à la compatibilité des données archivées avec les versions des outils qui permettent de les consulter !) et rapidement en cas de besoin.
Le temps de restauration des archives doit être en phase avec les besoins de mise à disposition des données : audit, analyse historique, etc.
Enfin, une stratégie de test régulier des archives est également recommandée pour assurer leur intégrité sur le long terme.
Plusieurs solutions techniques existent pour soutenir les processus de purge et d’archivage.
Outils et technologies pour la purge et l’archivage
Aujourd’hui, de nombreuses solutions sont disponibles sur le marché pour répondre aux besoins spécifiques des entreprises, qu’il s’agisse de supprimer des données obsolètes ou de les archiver dans des environnements sécurisés.
Voici un aperçu des principales technologies utilisées pour ces processus.
Solutions de purge
Scripts d’automatisation
Les scripts d’automatisation sont souvent utilisés pour la purge des données stockées sous forme de fichier plat.
Ces scripts peuvent être développés dans des langages comme Python, Bash, ou PowerShell et permettent de planifier la suppression des données obsolètes de manière régulière, tout en minimisant les erreurs humaines.
Ils offrent une grande flexibilité, sont moins coûteux, mais nécessitent des compétences techniques pour leur développement, leur configuration et leur maintenance.
Logiciels de gestion de bases de données (DBMS)
La majorité des systèmes tels que Oracle, SQL Server, ou MySQL intègrent des fonctionnalités de purge automatisée pour interagir avec les bases de données.
Ces outils sur étagère permettent de définir des règles de rétention des données et de planifier la suppression des données dépassant une certaine limite temporelle ou devenues inactives.
Cela aide à maintenir les bases de données à jour, légères et performantes, tout en assurant la conformité aux règles de gouvernance des données.
Outils spécialisés de purge
Enfin, des solutions comme Commvault Data Management, SAP Information Lifecycle Management ou Dell EMC Data Erasure offrent des fonctionnalités avancées pour gérer la suppression des données obsolètes dans les environnements complexes.
Ces outils permettent de s’assurer que la suppression est effectuée de manière sécurisée et traçable, tout en garantissant que les données critiques ne sont pas affectées par inadvertance.
Solutions d’archivage
Solution dans le Cloud
Les entreprises font régulièrement appel à une plateforme de stockage tierce hébergée dans le cloud pour l’archivage des données à long terme.
Par exemple, Amazon S3 (Simple Storage Service), avec ses options comme S3 Glacier ou S3 Glacier Deep Archive, offre des niveaux de stockage à faibles coûts adaptés aux données rarement consultées mais qui doivent rester accessibles en cas de besoin.
S3 permet aussi de définir des politiques de rétention et de restauration faciles à gérer, garantissant la sécurité des données archivées.
Le fournisseur Azure propose quant à lui une solution similaire avec Azure Blob Storage, permettant de stocker des données dans des couches de stockage chaudes (hot), froides (cool) ou archivées selon leur fréquence d’accès.
De manière générale, le niveau d’archivage dans le Cloud offre un espace de stockage très économique pour les données à long terme, avec des options de sécurité avancées comme le chiffrement et la gestion des accès basés sur les rôles.
Solutions sur site (on-premise)
Pour les entreprises qui préfèrent garder leurs données en interne, les solutions de stockage sur site, comme les NAS (Network Attached Storage) ou SAN (Storage Area Network), offrent des options d’archivage robustes.
Les bandes magnétiques restent également une solution fiable et économique pour l’archivage à très long terme. Ces technologies permettent un contrôle total sur les données et sont idéales pour les organisations soumises à des réglementations strictes en matière de confidentialité et de sécurité.
Pour optimiser les coûts de stockage, pensez à compresser (si possible) vos données avant de les archiver !
Data platform is the new Cloud Storage !
Pourquoi ne pas utiliser votre plateforme Data comme option alternative au support de stockage ?
En effet, une plateforme Data accueille déjà les données non essentielles et utiles, et pourrait donc jouer le rôle de lieu d’archivage tout en mettant à disposition les données sous un format anonymisé à des fins analytiques ou pour le machine learning !
Il convient évidemment de conserver ces données dans un état brut (non transformé). De la même manière, un plan de rétention doit être mis en œuvre pour gérer leur conservation et envisager une suppression définitive.
En premier lieu, il est primordial de mettre en place une stratégie de stockage hiérarchisée sur cette plateforme Data !
Enfin, le coût est bien entendu plus élevé qu’un stockage en mode archivage, mais il faut considérer cette solution comme un moyen de valoriser la donnée ! Quels que soient les choix stratégiques en termes de purge et d’archivage, il est important d’être rigoureux sur les actions menées.
Appliquer les bonnes pratiques
Comme en médecine : mieux vaut prévenir que guérir ! Effectivement, les actions de purge et d’archivage ne sont pas sans risque, et il est recommandé de prendre quelques précautions avant de se lancer.
La perte de données importantes
L’un des principaux risques de la purge des données est la suppression accidentelle d’informations critiques ou encore nécessaires pour l’entreprise. Pour éviter cet incident, il est essentiel d’implémenter des mécanismes qui permettent de valider que seules les données réellement obsolètes sont purgées.
Une solution serait de réaliser la purge en deux temps :
Une purge logique : Cette action masque les données et celles-ci sont inaccessibles du point de vue de l’utilisateur ou de l’application
Une purge physique : Passé un certain délai et sans incident remonté et avéré, ces mêmes données sont supprimées définitivement
Garantir l’intégrité des archives
L’intégrité des données archivées est cruciale pour s’assurer que celles-ci restent accessibles, exploitables et conformes à long terme.
Voici quelques pratiques :
Opter pour des technologies d’archivage qui offrent des garanties sur la durabilité des données
Appliquer des mécanismes de chiffrement pour protéger les archives contre les accès non autorisés ou les modifications malveillantes
Choisir une plateforme d’archivage alignée avec les réglementations (GDPR, HIPAA, etc.)
Mettre en place des procédures claires pour restaurer les archives en cas de besoin
Tester régulièrement la récupération des archives, vérifier leur accessibilité et confirmer que les données n’ont pas été altérées par le temps ou l’usure des supports dans le cadre d’une solution sur site
Automatiser et mettre en place un suivi et un audit
Automatiser la gestion des données permet de garantir une purge et un archivage continus et efficaces, tout en respectant les politiques internes et les obligations réglementaires.
Tracer toute action réalisée sur les données et générer des rapports pour homologuer la conformité avec toutes les exigences internes et externes.
Conclusion
La purge et l’archivage des données sont des processus applicables à toutes les strates de l’entreprise, depuis le poste d’ordinateur d’un collaborateur aux serveurs applicatifs en passant par les boîtes email.
Bien entendu, les règles et les consignes sont à ajuster et à appliquer en fonction de la criticité de la donnée présente au sein de ces plateformes.
L’équipe Sécurité de l’entreprise est également partie prenante de ces activités. N’hésitez donc pas à les solliciter ! Purger et archiver sont des écogestes et contribuent naturellement à la sobriété numérique ! Alors, qu’attendez-vous pour les mettre en œuvre ? 🌱
CARTOGRAPHIE SI : Quels acteurs et quelle démarche pour le succès ?
CARTOGRAPHIE SI : Quels acteurs et quelle démarche pour le succès?
2 décembre 2024
Architecture
David Hauterville
Consultant
Puisque pour la gestion pérenne de votre SI, vous avez saisi tout l’intérêt de l’architecture d’entreprise, vous avez réalisé l’importance d’avoir une cartographie à jour de votre patrimoine. La mise en place et le maintien de ces données centralisées ne se résument pas à l’acquisition ou au développement d’une application.
La solution technique de cartographie doit se déployer dans un environnement où les acteurs et les moyens s’anticipent et s’adaptent en fonction des objectifs souhaités face aux réalités rencontrées. Quelle que soit la solution utilisée ou envisagée, il faudra faire face aux différents défis qui se dressent lors de son déploiement. L’outil doit s’implanter dans un contexte propice à sa prise rapide et son implantation durable.
Nous allons donc d’abord vous présenter les différents acteurs d’une démarche de cartographie réussie, du sponsor aux responsables du run, pour ensuite vous proposer une démarche issue de notre expérience auprès de nos différents clients.
Source : Pexels – Brett Sayles
Les acteurs d’une démarche de cartographie réussie
Un sponsor fort, une tête de proue
C’est l’ incarnation du projet consciente des moyens, du temps, de l’énergie qu’il sera nécessaire d’y consacrer. C’est le moteur qui fournit les conditions et prend les décisions sur les efforts à adapter à chaque phase du déploiement (sur plusieurs mois à quelques années).
Il est haut placé dans le board ( DSI …) pour ouvrir les portes et parler du projet dans les instances de gouvernance de haut niveau (ex: des réunions de directeurs).
Un product owner dédié à la solution
C’est idéalement un profil d’architecte expérimenté en mesure de rapporter au sponsor l’état d’avancement et les points d’alerte. Il est garant du produit et capable de comprendre les organisations et leurs enjeux. Il sera sera à même de définir les quick wins du référentiel, la démarche et l’organisation qui en découle. Il se doit d’être force de communication proactive tout en sachant se rendre disponible pour adresser les demandes d’accompagnement issues de toutes les entités de l’entreprise.
Des responsables désignés au suivi des applications
Les responsables d’application sont chargés de garantir la fraîcheur des informations relatives aux applications dans le référentiel. Ils sont idéalement en accès direct avec les utilisateurs de ces applications. Ils vont former une communauté d’échanges autour des bonnes pratiques de récolte des informations et l’utilisation de l’outil de référencement. Ils se feront les relais de l’effort de sensibilisation et d’accompagnement au bénéfice de l’usage du référentiel.
Des sachants identifiés
Parfois elles-même responsables d’application, ces personnes font office de sachants concernant l’historique du patrimoine applicatif. Elles sont souvent une mémoire vivante de l’évolution des applications et de l’organisation (historiques des contraintes et décisions). Elles contribuent à identifier les référentiels déjà présents. Depuis quand existent-ils, pour quels objectifs et usages, pour quels usagers et quelles en sont les limites et les points de douleurs.
Une équipe Build
En pointe de la connaissance et de la maîtrise de l’outil, elle construit le métamodèle des données et implémente les fonctionnalités nécessaires à l’exploitation de l’outil. Elle entretient une relation rapprochée auprès de l’éditeur. Elle teste et approuve l’activation, voire la création, des nouvelles fonctionnalités. Elle s’assure de tirer le meilleur parti des montées de version et mise à jour éditeur.
Une équipe Run
Au plus près des contributeurs et utilisateurs, elle assure leur accompagnement technique. Elle gère l’administration et le paramétrage de l’outil. Elle veille aux bonnes performances du service pour garantir un confort d’utilisation optimal.
Au début du projet, les fonctions Build et Run sont confondues.
Les étapes successives d’une démarche de cartographie réussie
Les fondamentaux, des chantiers à lancer les uns après les autres
La mise en place de la comitologie ad hoc
Dans l’optique d’améliorer la démarche en continue, les acteurs du projet doivent être prêts à consacrer du temps pour suivre la comitologie :
Entre le sponsor, l’équipe de build et l’équipe de run.
Avec la communauté des responsables d’application.
Avec les métiers.
Avec les utilisateurs.
Avec les concepteurs/éditeurs de l’outil.
Un métamodèle initial
Il s’agit de définir les objets à référencer dans l’outil. Une bonne base de départ est constituées des objets suivants:
Profil utilisateurs : souvent représenté par les entités organisationnelles, identifie qui est impacté par la vie des applications qu’ils utilisent et/ou dont ils sont propriétaires.
Capacité métier : souvent inspirée des Plan d’Occupation des Sols ou de Standard du métier, représente les fonctions métiers à couvrir par les applications.
Application : objet au centre du référentiel, en lien avec chacun des autres objets.
Données : manipulées ou échangées par l’application.
Flux : matérialise l’échange de données entre applications.
Brique technologique: dont se sert l’application pour fonctionner.
Si pour la plupart des objets, leur définition paraît évidente, certaines, comme celle des capacités métier hors standard ou surtout celles de l’application, peuvent faire débat. De même les attributs à renseigner pour chacun des objets est potentiellement sans limite. Le métamodèle initial pose les hypothèses de définition les plus simples et inclusives possibles. Seuls les attributs essentiels aux rapports et analyses prioritaires sont retenus pour les premières collectes.
Une première campagne de collecte savamment orchestrée
Une fois ces éléments identifiés, il est alors possible de lancer la première itération de collecte des données identifiées dans le métamodèle initial. Elle est circonscrite à un périmètre limité, pour une entité perçue comme représentative et une période réduite à maximum trois semaines à la façon d’un sprint en mode Agile. Durant cette période les interlocuteurs clés identifiés sont sûrs d’être disponibles. Donc éviter les périodes propices aux congés, audits, bilans réglementaires, etc.
Cette première collecte est la matière première à soumettre aux processus et méthodologies à mettre en place pour l’harmonisation et l’optimisation du référencement. Elle peut être complétée par une deuxième ou troisième campagne afin de valider les hypothèses de modélisation et de modalité de collecte.
Un guide de la modélisation partagé à tous
Une fois cette première campagne réalisée, vient le moment de partager à tous une base documentaire.
Les processus doivent avoir pour but de rendre l’information disponible et compréhensible pour tous par un maximum d’intervenants à leur échelle. Afin de s’assurer que tous parlent le même langage, il est donc indispensable de rédiger le glossaire de l’organisation.
Ce glossaire sert de socle pour l’élaboration des règles de nommage (application, flux,…) et conventions de traitement de cas (modalité de prise en compte des applications, flux hors SI de l’organisation,…) à mettre en pratique lors de l’exploitation des informations collectées.
Cette documentation est tenue à jour à l’occasion de revues régulières en fonction de leur efficacité. Elle se nourrit de l’épreuve du concret et des suggestions rencontrées sur le terrain.
Cette documentation s’illustre sous la forme d’un guide utilisateur personnalisé du portefeuille d’application, même (surtout!) si c’est une solution du marché.
Un temps sacralisé pour la formation
Une fois les leçons des premières campagnes tirées et transcrites dans la documentation, il est temps de décentraliser progressivement la saisie des informations vers les responsables identifiés. Il est indispensable de leur dédier le temps nécessaire à la montée en compétence sur l’outil. Veillez à ce que l’éditeur soit en mesure de vous accompagner sur les fondamentaux et les impacts des mises à jour. Avec le renfort d’une prestation externe, l’équipe bénéficie de son expérience agnostique, d’une détection des limites de la solution au-delà du marketing, de propositions hors du paradigme propriétaire.
Une stratégie de suivi des objectifs
Au fur et à mesure que la collecte s’intensifie, le référentiel s’élargit en termes d’entités organisationnelles couvertes, ainsi qu’en quantité, variété, et qualité des données tout en faisant évoluer son métamodèle . Cet élargissement doit être maîtrisé et soutenu. La maîtrise se matérialise par le choix, la revue et la planification des objectifs afin qu’ils restent atteignables et porteurs de valeur pour les utilisateurs. Le soutien passe par la mise à disposition des moyens évoqués plus tôt : documentation, guide méthodologique, session régulière d’information et de formation, animation de la communauté mais aussi l’automatisation des processus.
Le suivi de l’évolution de la couverture est effectué via un tableau de bord personnalisé en fonction des besoins de l’organisation. Y sontrassemblés des indicateurs quantitatifs (nombre de fiches référencées, nombre d’utilisateurs, … ) et qualitatifs (taux de complétude des fiches, fraîcheur des données).
Penser à célébrer régulièrement les jalons atteints avec succès via des canaux de communication internes ( newsletters, workplace,…).
À ce stade de l’implémentation, nous recommandons d’officialiser la distinction :
équipe de Run qui s’occupe du suivi des indicateurs
équipe de Build qui reste dédiée à l’amélioration continue de l’outil.
Un événement annuel pour faire le point
Le suivi par tableau de bord se complète par une revue de patrimoine a minima une fois par an. Durant une période de plusieurs jours, les conditions sont créées pour que tous les acteurs concentrent leurs efforts sur :
la mise à jour du référentiel,
la mise à jour de leur compétence et de leur connaissance sur l’outil,
la mise en commun de leurs retours d’expérience et bonnes pratiques,
la remontée des doléances.
L’événement peut combiner différentes formes : défis, concours, hackathon, tout mode d’implication pour rassembler le plus large spectre possible d’utilisateurs.
C’est l’occasion de mettre en lumière d’une part, les événements et les acteurs qui ont marqué la saison qui vient de passer; et d’autre part d’afficher les ambitions et les nouveautés de la saison à venir.
Les étapes pour aller plus loin
Des connecteurs pour les bases existantes
Une étape dont l’importance nous pousse à la mettre dans les fondamentaux, mais dont le planning associé n’est pas toujours compatible avec les ambitions. Mais tirer parti automatiquement des autres sources de données en production est un énorme gain de temps et de fiabilité sur le moyen-long terme. C’est pour cela que cette initiative doit être réfléchie au plus tôt. Dès que possible il faut s’interfacer avec les autres référentiels à disposition : CMDB, Plateforme d’échanges, Data, Achat, RH, Portefeuille des projets, … Cette stratégie permet d’enrichir et maintenir à jour le patrimoine avec des sources automatiquement croisées. Cependant, avant de mettre en place ces interfaces, certains prérequis sont nécessaires à une intégration efficace :
le modèle du référentiel de cartographie est stabilisé
La golden source est identifiée pour chaque donnée partagée.
Les équipes techniques de chaque outil ont les ressources nécessaires en interne et auprès des éditeurs pour mener à bien les intégrations.
Des règles de cohabitation organisationnelle
Plus la cartographie s’étend, plus elle se confronte à des revendications qui peuvent remettre en cause l’homogénéité du modèle global. Il est alors temps de penser à comment évaluer les critères de granularité et de segmentation. La plupart des critères dépendent des profils utilisateur. La segmentation peut s’opérer par :
son entité organisationnelle (division, filiale,..),
son groupe fonctionnel,
sa langue,
sa région géographique,
…
Cette liste est non exhaustive et ses éléments sont combinables.
Des marqueurs de réussite!!
Avec ces acteurs et cette approche vous êtes sur la voie de la pérennisation de la cartographie. Quelques signes qui montrent que l’implémentation de votre outil de cartographie est un succès :
Ses utilisateurs sont passés du statut de « remplisseur de fiche » à « responsable impliqué dans la qualité des informations» et se font ambassadeurs de l’outil.
Ses utilisateurs peuvent spontanément partager les bénéfices dans leur cas d’usage.
Son évolution continue indépendamment du sponsor.
Son statut de source de vérité de la connaissance de l’architecture d’entreprise.
Son existence et son intérêt sont reconnus par tous les collaborateurs.
Son statut de point de départ et d’arrivée de projets de transformation.
Le référentiel ainsi complet et à jour, se révèle être un puissant facilitateur de préparation et de suivi d’exécution des projets de transformation.
En conclusion, le suivi ordonnancé de ces étapes et la mise en place de ses acteurs, vous permettra d’installer une cartographie adoptée par les utilisateurs clé du maintien de votre SI, dans les meilleurs délais. Dans cette course contre la montre face aux exigences de réactivité de votre SI , certains raccourcis peuvent se révéler plus coûteux à long terme que le bénéfice perçu à court terme. Chez Rhapsodies Conseil, fort de notre expertise en gestion de Patrimoine et Gouvernance SI, nous restons à votre disposition pour vous guider sur ce parcours stratégique vers le succès.
Contrairement à une idée reçue, la réglementation de l’IA à vocation à favoriser son développement et son partage dans les projets des organisations.
Chez Rhapsodies Conseil, nous considérons que les bonnes pratiques Data sont indispensables à la réussite des projets IA (intégration d’un outil ou développement interne). Nous abordons le sujet de l’IA par les usages raisonnés de ces technologies. Pour assurer le succès de l’intégration de l’IA dans notre quotidien, nous mettons l’accent sur la gouvernance et la mise en qualité des données. En effet la maîtrise des données est pour nous un incontournable de la réussite d’un projet IA, au même titre que les questions éthiques et réglementaires que nous avons dû nous poser pour définir notre charte d’IA qui intègre les exigences de l’AI Act comme la gestion des risques tout au long du cycle de vie du système d’IA.
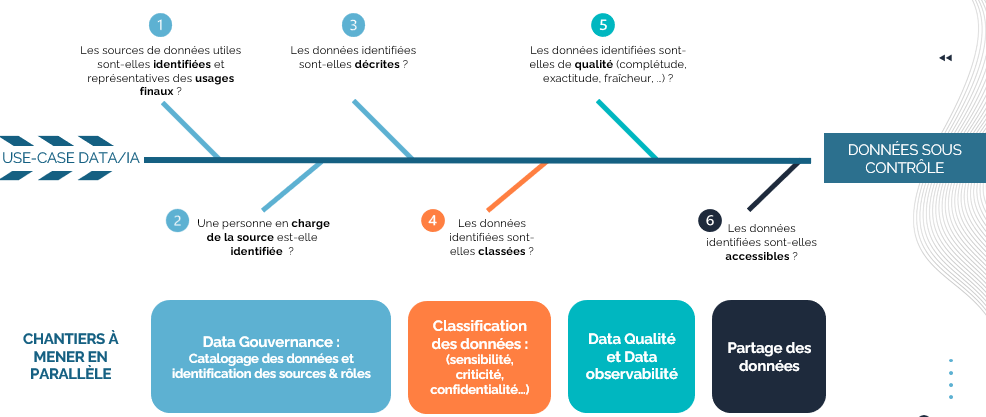
Gouvernance des données : Une structure solide
Une gouvernance des données efficace est cruciale pour garantir des données maîtrisées et conformes à la réglementation. Cette efficacité passe par des politiques claires de gestion et suivi de la qualité des données, des responsabilités définies, ainsi que par une traçabilité des données. Et ce, en lien avec le cycle de vie du projet IA.
En assurant une supervision continue, la gouvernance aide à éviter les biais, à respecter les droits des individus et à maintenir la transparence des processus, en ligne avec les exigences des autorités régulatrices.
Qualité des données : L’essence de l’IA
Pour que les modèles d’IA fonctionnent de manière optimale, il est essentiel de fournir des données de haute qualité. Cela implique la vérification de la cohérence, de l’exactitude et de la pertinence des données. Des processus de validation et de nettoyage des données doivent être mis en place pour éviter les erreurs, les biais et garantir que les modèles sont alimentés par des informations fiables.
Cette démarche est d’autant plus essentielle pour les applications classées « à haut risque » par l’AI Act. Tout traitement automatisé de données personnelles pour évaluer divers aspects de la vie d’une personne (situation économique, intérêts, localisation, etc.), est considéré comme un traitement à haut risque. Ainsi les défaillances peuvent avoir des conséquences majeures comme des fuites de données personnelles, des biais discriminatoires ou la mise en place par ceux qui déploient des systèmes de surveillance humaine.
Conformité avec l’AI Act : Processus intégrés et documentation
L’AI Act impose des obligations précises aux projets IA, notamment en matière de documentation, de traçabilité des décisions et d’explicabilité des modèles. Les fournisseurs de modèles doivent effectuer des évaluations de modèles, y compris mener et documenter des tests contradictoires afin d’identifier et d’atténuer le risque systémique. Ils doivent repérer, documenter et signaler les incidents graves et les éventuelles mesures correctives à l’Office AI et aux autorités nationales compétentes dans les meilleurs délais.
Pour répondre à ces obligations, il est essentiel de mettre en place des processus intégrés qui permettent de suivre, documenter et auditer les données utilisées à chaque étape du projet.
Cette approche préventive renforce non seulement la conformité, mais facilite également l’adaptation aux futures régulations et les audits de conformité éventuels.
En résumé, avant de vous lancer dans un projet IA nous vous conseillons fortement de respecter un ensemble de bonnes pratiques Data et de les personnaliser selon votre contexte :
Nous attirons aussi votre lecture sur un sujet crucial de l’impact de l’IA. En raison de l’impact environnemental et social important et croissant de l’IA et en particulier de l’IA Générative, ses usages doivent rester limités au strict nécessaire pour les organisations. Les prises de décision autour du déploiement de ces technologies doivent se faire en prenant en compte systématiquement ces enjeux.
–> Voir la norme AFNOR de référence sur le sujet !
Pour aller plus loin, n’hésitez pas à contacter l’un de nos experts Transformation Data :
Octobre Rose et Movember sont deux mois clés dans la lutte contre les cancers qui touchent des millions de personnes chaque année. Octobre Rose est dédié à la prévention du cancer du sein. Movember se concentre sur la santé masculine : prévention des cancers de la prostate et des testicules, ainsi que la santé mentale des hommes.
Pourquoi ces campagnes sont-elles si importantes ?
Le dépistage précoce est un élément crucial pour améliorer les chances de survie face à ces maladies. Octobre Rose encourage les femmes à se faire dépister régulièrement pour le cancer du sein, une étape clé pour détecter la maladie à temps. Movember, de son côté, sensibilise les hommes à l’importance de surveiller leur santé, souvent négligée, et d’oser parler de sujets tels que le cancer ou la dépression.
La flexibilité chez Rhapsodies Conseil, un levier pour le bien-être
Chez Rhapsodies Conseil, nous croyons fermement que la flexibilité au travail peut jouer un rôle important dans la prise en charge de la santé, qu’il s’agisse de prévention, de dépistage ou de traitement. Voici comment nos pratiques actuelles et celles que nous pourrions développer y contribuent :
Encourager les rendez-vous médicaux : Grâce à la flexibilité de nos horaires, nos collaborateurs peuvent facilement planifier des rendez-vous médicaux pour des dépistages ou des suivis réguliers, sans avoir à sacrifier leurs engagements professionnels. Prendre soin de sa santé ne doit pas être une contrainte.
Faciliter les absences pour traitements : Pour les collaborateurs qui doivent suivre un traitement médical ou accompagner un proche touché par la maladie, le télétravail ou la flexibilité des horaires permettent d’aménager leur emploi du temps afin qu’ils puissent prendre soin d’eux ou de leurs proches, tout en restant connectés à l’entreprise.
Sensibiliser et informer : Le bien-être des collaborateurs est au cœur de nos actions. Nous menons déjà de nombreuses initiatives, que nous enrichissons en octobre et novembre pour Octobre Rose et Movember. Ces moments de sensibilisation permettent de rappeler l’importance des dépistages et de la santé mentale, tout en créant un espace de discussion ouvert et inclusif.
Un engagement au quotidien pour le bien-être des collaborateurs
Chez Rhapsodies Conseil, la sensibilisation à ces enjeux ne s’arrête pas là. Chaque année, nous organisons la Semaine de la Qualité de Vie au Travail pour aborder ces questions essentielles et encourager les discussions sur la santé et le bien-être. De plus, des réunions régulières sont tenues autour de projets d’inclusion afin de garantir que chacun se sente soutenu et inclus dans nos démarches.
Ces sujets sont également abordés dans notre newsletter interne, qui informe les collaborateurs des initiatives en cours, des bonnes pratiques, et des ressources disponibles pour mieux concilier santé et travail.
La flexibilité au service de la santé : un engagement durable
Nous soutenons activement Octobre Rose et Movember, avec des politiques de flexibilité au travail. Au-delà de nos objectifs professionnels, la santé de nos collaborateurs est une priorité. Aller à un dépistage, suivre un traitement, ou prendre soin de sa santé mentale : chacun doit bénéficier d’un environnement de travail flexible adapté à ses besoins.
Chez Rhapsodies Conseil, nous nous engageons à faire en sorte que la conciliation entre vie professionnelle et santé soit non seulement possible, mais encouragée.