Les métadonnées deviennent une composante clé des approches data, en particulier pour s’y retrouver dans les méandres des sources de données et autres Data lakes / Data hubs.
Cet article, en Anglais, propose une vision historique et exhaustive des métadonnées jusque dans la dimension marketing, d’automatisation des traitements et, plus récemment, de GDPR.
Il y a une journée mondiale de la protection des données et c’est aujourd’hui, lundi 28 janvier 2019.
C’est le Conseil de l’Europe qui a, le premier et dès 2007, proclamé une journée européenne de la protection des données à caractère personnel.
Dernièrement, et au-delà de GDPR (oui je fais le pari qu’il n’y a plus besoin de dire ce que c’est), l’actualité nous a montré à quel point les données personnelles étaient un enjeu énorme et qu’il y avait encore une longue route à parcourir. La liste des « évènements » liés aux données personnelles ne cesse de s’allonger : Amende Google, Facebook et Cambridge Analytica, vol des données d’élus Allemands, piratage « Collection #1 »… et ce ne sont que les plus emblématiques (il y en a de multiples rien qu’avec Facebook).
Au-delà du fait de mettre en place des responsabilités, des procédures et des outils pour se conformer à GDPR, il me semble important de mettre en avant quelques éléments-clés :
La finalité de GDPR c’est de protéger les individus : oui, il ne s’agit pas juste de protéger des données et de mettre en place des procédures,
GDPR ne peut être vue comme une simple approche de protection et de sécurité : le cycle de vie des données personnelles concerne quasiment tous les acteurs des organisations,
On parle beaucoup des « clients » lorsqu’il s’agit de GDPR : n’oublions pas que les « collaborateurs » d’une organisation sont également à traiter avec, a minima, la même sensibilité,
C’est la « finalité » des traitements sur les données personnelles qui permet de justifier ces traitements : cela milite pour une approche orientée « usages » pour avoir la bonne maille d’étude.
Dès lors, c’est au sein de la culture même de chaque organisation qu’il faut intégrer la protection des données personnelles et, plus largement, la valeur des données. D’un côté, nous avons la culture d’une organisation qui peut se caractériser par ses valeurs partagées, ses croyances et convictions, ses pratiques, ses comportements. De l’autre, nous avons une Culture Data qu’il devient de plus en plus nécessaire de partager le plus largement possible.
Il faut donc diffuser une Culture Data à tous les étages des organisations : C’est cela qui va permettre de prendre la mesure, à l’échelle de l’organisation, de la protection des données personnelles mais aussi de la valeur des données (qualité, disponibilité…). Mais il faut faire cela en s’insérant dans la culture en place, pour venir l’étendre et l’enrichir, et pour s’assurer que cela est fait de façon durable. En effet, penser qu’il suffirait de mettre en place un plan « Culture Data pour tous » générique et sans personnalisation est probablement voué à l’échec.
Et comme il ne faut pas rester sur un « échec », espérons que cette journée de protection des données personnelles permettra de faire avancer la Culture Data à tous les étages de la société.
Data scientist, data analyst, data cruncher,… ces dernières années, le nombre d’intitulés de postes relatifs au traitement, et plus particulièrement à l’analyse, de données a explosé. On constate également la popularité croissante des compétences inhérentes à ces postes via divers tops ‘in-demand skills’, publiés annuellement sur LinkedIn. Ces postes ont tous une compétence requise en commun, l’analyse de données, aujourd’hui jugée primordiale dans le monde professionnel par le cabinet Gartner, jusqu’à l’élever au rang de norme.
Mais ne sommes-nous pas déjà entrés dans une nouvelle époque, durant laquelle les composantes basiques de ces compétences vont peu à peu migrer dans le ‘savoir commun’ et devenir des pré-requis pour un scope plus large de métiers ? Ne sommes-nous pas entrés dans l’ère de la ‘data democratization’ ?
Pourquoi une explosion de de la demande relative à ces compétences ?
A l’heure où plus de la moitié de l’Humanité a quotidiennement accès à Internet et où 90% des données disponibles ont été créées dans les deux dernières années, toute entreprise collecte et stocke une quantité importante de ces données. De formats et types variés, ces dernières sont également transversalement issues de la totalité des métiers de l’organisation. Les capacités de traitement (stockage et puissance de calcul, ‘asservis’ à la loi de Moore depuis des décennies) ont elles aussi explosé, passant d’un statut de facteur limitant à celui de non-sujet.
Traditionnellement, ces données étaient propriétés de la DSI. Certes, les décisions des BU métiers et du top management s’appuyaient déjà sur ces données. On ne pouvait toutefois pas se passer d’un intermédiaire pour leur consultation et traitement, augmentant les risques de non compréhension de la donnée ainsi que les temps de traitement des demandes. Aujourd’hui, de plus en plus d’organisations transversalisent leur entité ‘data’, afin de rapprocher les données des métiers, porteurs de la connaissance de la donnée, et des usages, délivreurs de valeur.
Car il est évident que, bien qu’elle soit complexe à déterminer précisément et instantanément, la donnée a une valeur évidente qu’il convient d’exploiter. Pour cela, une capacité d’analyse, plus ou moins poussée, est nécessaire à tous les niveaux de l’entreprise, au plus proche de la donnée et ce pour ne pas en perdre la signification.
Mais il existe encore des freins à cette démocratisation. En entreprise, le nouvel analyste peut se heurter à une mauvaise compréhension de la donnée. Même si la tendance est au partage et à la “transversalisation”, les données sont encore parfois stockées et gérées en silo, rendant difficile l’accès et la transparence de la signification métier de cette donnée.
Mais multiplier les analystes peut aussi représenter un risque de multiplier les analyses…identiques. Aussi, un sujet apparaît lorsque la donnée est rendue accessible plus largement : celui de la protection des données personnelles, récemment encadré par la nouvelle réglementation GDPR. En effet, la finalité d’un traitement de données doit aujourd’hui être systématiquement précisée, tout comme la population de personnes accédant aux données en question. Cette dernière doit par ailleurs être réduite au strict minimum et justifiable.
Cette data democratization est donc porteuse, dans le monde de l’entreprise, d’un message supplémentaire : une gouvernance bien établie agrémentée d’une communication efficace sont nécessaires et catalyseront la démocratisation.
Et concrètement, analyser des données ?
Avant toute chose…
Il existe une règle d’or dans le monde de l’analyse de données et elle s’appliquera également aux nouveaux analystes issus de la data democratization. Cette règle, éprouvée et vérifiée, stipule qu’en moyenne 80% du temps effectif d’un analyste sera consommé par la collecte, le nettoyage l’organisation et la consolidation des données, ne laissant que les 20% restants pour les analyser et en tirer de la valeur. Il faut donc que les nouveaux analystes prennent conscience de cette contrainte et aient une base de connaissances sur les réflexes de vérification à avoir lors de la réception d’une nouvelle source de données.
Visualiser
On peut définir la visualisation de données (ou dataviz) comme une exploration visuelle et interactive de données et leur représentation graphique, indépendamment de leur volumétrie, nature (structurées ou non) ou origine. La visualisation aide à percevoir des choses non évidentes en premier lieu, répondant à deux enjeux majeurs du monde de l’entreprise : la prise de décision et la communication.
Mais attention, un graphique mal utilisé peut faire passer un message erroné, laisser percevoir une tendance peu fiable ou maquiller une réalité. C’est donc pour cela qu’il convient de donner à tous une base méthodologique permettant d’exploiter la puissance de la dataviz tout en évitant les écueils.
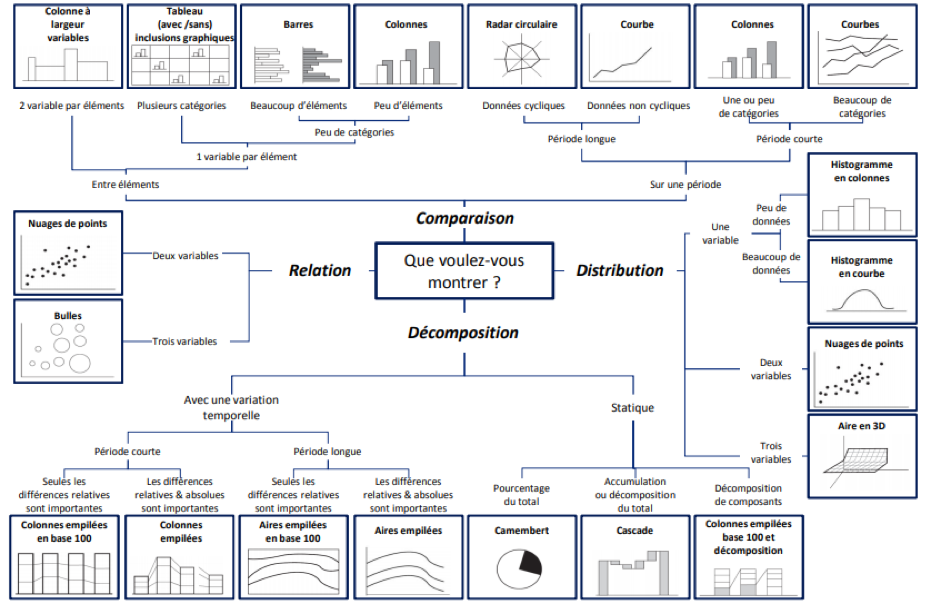
La force de la visualisation réside en l’aperçu instantané qu’elle permet d’avoir sur une large quantité de données, pour peu que son créateur ait fait le bon choix de représentation. Plusieurs paramètres sont à considérer lorsque l’on souhaite choisir une visualisation : quel phénomène je souhaite mettre en évidence ? de combien de variables ai-je affaire ? ma représentation doit-elle être continue ou discrète ? …
Ci-dessous, une cheatsheet sous forme de visualisation, avec pour thème : “Quel type de graphe pour quel usage ?”
Avec quels outils, pour commencer ?
Une des raisons d’occurrence de cette ‘data democratization’ est l’émergence de technologies facilitatrices, permettant à un plus grand nombre d’interagir avec les données, à l’aide de frameworks de code ou d’interfaces graphiques accueillantes pour une expérience guidée et visuelle :
Logiciels de ‘data federation’ et dataviz : des interfaces graphiques simples, guidant la manipulation de l’import des données de formats et de sources différentes jusqu’à leur visualisation, intégration dans des dashboards et publication de rapports. On peut citer les solutions leaders du marché : Tableau Software, QlikView, Microsoft Power BI,…
Solutions “all included” et plateformes : dans une unique application, la possibilité est donnée de mener des analyses automatiques jusqu’à de la modélisation complexe, le tout sans avoir à toucher (ou peu) une ligne de code (exemples de solutions : IBM Watson Analytics, Dataiku, Saagie,…)
Frameworks et librairies : s’adressant à un public plus averti, il s’agit là de fonctions et méthodes prêtes à être ré-utilisées et adressant des problématiques et utilisation bien particulières (exemples : librairies NumPy et Pandas en Python pour faciliter la manipulation de données, librairie D3js en JavaScript pour la dataviz, …)
Mais il est toutefois un outil encore très majoritairement utilisé pour des cas simples de reporting, visualisation, agrégation et modélisation simple. Il s’agit du tableur on-ne-peut-plus-classique : Excel et l’ensemble de sa cour d’alternatives (GSheets, LibreOffice Calc,…). Et il est évident que l’on ne peut pas parler de démocratisation sans citer cet outil.
L’utilisation du tableur est aujourd’hui un pré-requis pour un grand nombre de métiers, dont certains sans aucun rapport à l’informatique. Aussi, le niveau de compétence en la matière n’a fait que s’élever d’années en années et c’est une tendance qu’il convient d’accompagner. De son côté, Microsoft ne cesse d’enrichir les fonctionnalités et, paradoxalement, de simplifier l’utilisation de son outil, en ajoutant des suggestions basées sur une analyse intelligente des contenus.
Notre conviction
Bien que nous n’ayons aujourd’hui pas le recul pour l’affirmer, on peut avoir bon espoir que cette démocratisation révolutionne la prise de décision en entreprise, en permettant aux employés à tous les niveaux de l’organisation d’avoir accès à des données et d’en tirer conclusions, plans d’action et projections.
Et nous pouvons espérer que cette démocratisation ne se cantonne pas au périmètre de l’entreprise traditionnelle : quid du travailleur indépendant, du petit commerçant ou du restaurateur ? Il est évident que ces individus également, dans l’exercice de leur activité, génèrent ou reçoivent des données qu’ils pourraient exploiter et valoriser (optimisation des stocks, analyses de résultats,…). Pour ces professionnels, un minimum de compétence internalisée mènerait à des économies en prestations et en temps passé, mais également à un éventuel ROI issu de l’analyse et de l’exploitation de leurs données.
Forts de ces constats, nous nous sommes aujourd’hui forgé la conviction suivante :
Le 27 novembre, à l’hôtel Peninsula, plus de 50 participants de tous les secteurs d’activité ont assisté à notre événement « Maîtriser et Augmenter la valeur des données ».
Cette table ronde était l’occasion de faire un 360° sur les usages faisant des données un actif majeur pour les organisations. Rythmée par les témoignages exceptionnels de Lydia Bertelle de Paris La Défense, Laurent Drouin de la RATP, Isaac Look de Malakoff Médéric et l’artiste Filipe Vilas-Boas, nos intervenants ont pris le temps de, partager leur vision, présenter leurs cas d’usage et détailler les leviers et les freins afin de structurer une approche pragmatique pour augmenter la valeur des données.
4 temps forts ont rythmés cette matinée:
Le regard Artistique et Numérique porté par Filipe Vilas-Boas, un artiste citoyen qui a installé un Casino permettant à tout un chacun de réfléchir et comprendre l’impact des données sur nos vies.
Les choix et investissements de Malakoff Médéric en temps et en ressources sur le sujet de la Gouvernance des Données porté par Isaac Look
Les Usages comme les vecteurs de la valeur de données, éclairés par des exemples de la RATP, portée par Laurent Drouin
L’approche choisie par Paris La Défense et Lydia Bertelle pour augmenter la valeur des données illustrant la feuille de route, le fonctionnement, les difficultés et les résultats concrets atteints.
Rhapsodies Conseil a pu, à cette occasion, présenter et remettre aux participants un exemplaire de son Livre-Blanc « Augmentez la valeur de vos données ! » détaillant sa méthodologie de mesure et d’identification des actions permettant d’augmenter la valeur des données.
Revivez les moments forts de l’évènement sur nos médias:
Vidéo
Podcast
Photos
Accueil de l’Hôtel Peninsula
Introduction de la Table Ronde
Casino Las Datas
Evénement DATA – Témoignage Isaac Look de Malakoff Médéric
« Gouvernance », le mot fait souvent peur. Si vous êtes consultant, vos clients les plus opérationnels vous font certainement un sourire poli quand vous évoquez le sujet, alors qu’ils pensent « Mais qu’est ce qu’il veut encore me vendre celui-là. Une machine à gaz qui va prendre beaucoup de temps, beaucoup de slides, et ne servir à rien ! » ; « Vous savez, nous avons déjà bien d’autres sujets à traiter ».
« Gouvernance des données », vous amenez l’expression avec habileté, en rappelant le volume considérable des données qui deviennent de plus en plus complexes à maintenir, sécuriser, exploiter, BLA, BLA, BLA. Et votre client le plus pragmatique vous dira « C’est bien gentil, mais ça ne m’aide pas à répondre à la demande de ce matin de l’équipe Marketing qui veut que je lui propose une solution pour cibler plus intelligemment les opérations / campagnes marketing… ou celle de l’autre jour de l’équipe Finance, qui n’en peut plus de faire à la main tous ses rapports sur Excel… »
Toute gouvernance, la gouvernance de données incluse, doit être une solution pour répondre à des usages et des points d’attention du métier (la DSI étant un métier parmi les autres).
Évitez la gouvernance de données pour la gouvernance de données !
Il existe une démarche qui a depuis longtemps trouvé sa place dans de nombreuses entreprises, mais qui a très vite montré ses limites, la voici (cela va vous parler si vous avez déjà challengé vos consultants sur le sujet) :
On va modéliser toutes les données existantes dans votre système d’informations
On va identifier les sources applicatives associées à ces différentes données
On va désigner des responsables pour chaque objet de données (des data owners, data stewards, …)
On va écrire des processus de gouvernances des données (validation, workflow, …)
On va mettre en place une instance de gouvernance sur la donnée
On fait tout ça d’abord avec notre vision DSI, on ira voir les métiers une fois qu’on aura une démarche déjà bien en place…
Alors, cela vous rappelle quelque chose ? Cette démarche : c’est faire de la gouvernance pour… SE FAIRE PLAISIR !
Une fois à l’étape 6, je vous défie de répondre précisément à la question suivante : « Alors, à quoi sert-elle cette nouvelle gouvernance ? Que va-t-elle améliorer précisément pour le marketing ? pour l’équipe financière ? pour l’équipe communication ? etc. ». N’ayez aucun doute là-dessus, la question vous sera posée !
La gouvernance des données doit être une solution pour mieux répondre aux usages :
Vos métiers utilisent les données. Ils savent ce qui doit être amélioré, ce qui leur manque comme données pour mieux travailler, tout ce qu’ils doivent faire aujourd’hui pour parer aux problématiques de qualité des données, le nombre de mails qu’ils doivent faire pour trouver la bonne donnée, parfois en urgence, pour leurs usages courants … Ils savent tout cela. Alors plutôt que d’inventorier toutes les données de vos systèmes, partez des usages des métiers et de leur point de vue et formalisez ces usages existants et les usages de demain
Concentrez vos efforts de gouvernance pour améliorer ou permettre les usages à plus forts enjeux ou risques pour l’entreprise
Cherchez à maîtriser l’ensemble de la chaîne de valeur, usage par usage (de la collecte à l’utilisation effective de la donnée pour l’usage) : organisation, responsabilités, outillages/SI
Faites évoluer votre gouvernance par itération, en partant toujours des usages.
Comprenez la stratégie de votre entreprise. Votre direction générale doit être sponsor. Donnez-lui les éléments pour la faire se prononcer sur une question simple : Sur quel pied doit danser en priorité la gouvernance Data, 40% sur le pied offensif (Aide au développement de nouveaux usages innovants), 60% sur le pied défensif ? (Gestion des risques GDPR, maîtrise de la qualité des données concernant les usages identifiés les plus critiques, …) ? 50/50 ? Elle doit vous donner les clés pour prioriser et itérer en adéquation avec la stratégie de l’entreprise.
La gouvernance des données est avant tout un sujet métier. Vous ne le traiteriez pas correctement en restant dans votre étage DSI… Cela peut paraître évident. Mais même quand certains le savent, ils choisissent la facilité : Rester à la maison…
Sortez, rencontrez tous les métiers, et vous formerez une base solide pour votre gouvernance. Ne sortez pas, et vous perdrez beaucoup de temps et d’argent…
Vous avez peut-être souvent entendu ces mots « Data is an Asset ». Mais la personne qui les prononce va rarement au bout de l’idée. Et pour cause, l’exercice est plus complexe qu’il n’en a l’air. Cet article a pour ambition d’éclairer le domaine et, pour cela, procédons par étape :
1 – Qu’est-ce qu’un Asset ?
Nous n’allons pas l’inventer, il existe une très bonne définition sur ce site : https://www.investopedia.com/ask/answers/12/what-is-an-asset.asp)
« An asset is anything of value that can be converted into cash. Assets are owned by individuals, businesses and governments »
« Un asset est quelque chose qui peut être converti en monnaie sonnante et trébuchante ».
Avec une maison, cela marche bien en effet. Une expertise suffira à vous donner une bonne idée de la valeur euro de votre maison. Mais pour vos données, ça ne paraît pas si simple.
Le défi aujourd’hui est d’être en mesure de valoriser une donnée, ce qui signifie :
Pouvoir par exemple très formellement comparer deux actifs Data entre eux, deux jeux de données (par exemple sur la base de critères bien définis)
Mettre une valeur « euro » sur un jeu de données (monétisation, prise en compte de l’actif Data sur des opérations d’acquisition / fusion, etc.)
Gérer nos données comme des Actifs, pour maintenir ou développer leur valeur dans le temps
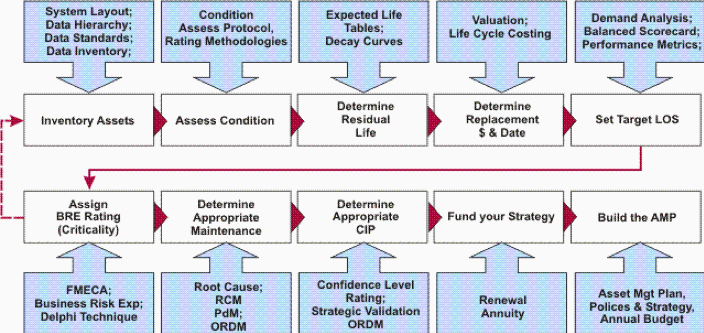
Sur ce dernier point, faisons l’exercice rapide ensemble. Prenons un processus d’asset management standard, appliquons-le à la donnée.
2 – Appliquons un Processus d’Asset management à la Data
Alors allons y ! Appliquons ce processus sur les données pour voir si elle peut être gérée comme un Asset ?
« Inventory » :Inventorier les assets Data. Jusque-là tout va bien.
« Asset Condition Assessment » :Évaluer l’état des biens: Est-ce que la donnée est de qualité, est-ce qu’elle il y a souvent des erreurs qui apparaissent ? Comment les gère-t-on ?
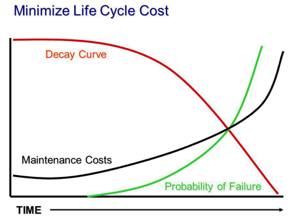
« Determine residual Life / Decay curve » : Il s’agit d’évaluer l’évolution potentielle de différents critères de valeur dans le temps. Par exemple est-ce que la donnée risque de perdre en rareté ? Les usages vont-ils être moins importants ? etc. En général cette notion porte sur le vieillissement d’un bien physique :
« Valuation » : Pour valoriser la donnée, on sent qu’il nous faut poser clairement un cadre de valorisation sur base d’un ensemble de critères. Au même titre que l’expert par exemple en Asset commercial connaît parfaitement les critères qui permettent da valoriser un commerce (surface du commerce, chiffre d’affaire, situation géographique, etc…). Notre conviction est qu’il faut aujourd’hui développer ce cadre pour l’actif « Data ».
« Life Cycle Costing » : C’est le processus qui permet d’identifier tous les coûts impliqués dans le cycle de vie de l’actif (coût d’une erreur, coût de la réparation / correction, coût de la perte de production éventuelle, coût de la maintenance corrective, ….)
« Determine replacements» : Est-ce qu’il faut revoir la manière de gérer certains asset Data ? Faut-il en abandonner/purger certains, non rentables ?
« Set target LOS » : Quel est le niveau de service attendu sur chaque asset Data ? A quels besoins faut-il répondre pour que l’asset ait de la valeur, soit viable ? Quels critères de valorisation veut-on améliorer ? (rareté, qualité, …)
« Assign BRE rating » = Business Risk Evaluation : Et quels sont les risques ? (GDPR, perte de données, …) : « Comment est-ce que des problèmes / incidents peuvent apparaître ? Quelle probabilité d’apparition ? Qu’est cela coûterait si le problème apparaissait ? Quelles en seraient les différentes conséquences ? »
« Determine Appropriate Maintenance » : Si l’on veut maintenir la qualité d’une donnée par exemple, par exemple 3 stratégies de maintenance existent dans le monde physique, elles sont applicables à l’actif Data (Use Base Maintenance : revue à une fréquence donnée, Fail based maintenance : correction sur incident/erreur, Condition Bases Maintenance : Maintenance plus préventive)
« Determine Appropriate CIP » (Capital Investment Program) : Initier (ou mettre à jour) notre programme d’investissement (Projet d’extension du capital d’assets Data, de renouvellement/modification de la gestion de certains Assets, mise en place de nouveaux processus de maintenance = gouvernance…)
« Fund your strategy » : On obtient le financement pour tout cela
« Build the Asset Management Plan » : Enfin on construit, ou on met à jour notre plan de gestion et de valorisation de nos assets Data
La méthode a l’air adaptée. Mais elle soulève des questions clés, auxquelles il va nous falloir répondre, notamment concernant les critères de valorisation. A titre d’exemple, le CIGREF a travaillé sur un cadre d’appréciation de la valeur économique des projets de transformation numérique. Il est intéressant d’avoir une approche comparable pour l’actif « Data ».
3 – Et après ?
Nous venons de voir que la data est effectivement un actif, d’un type bien particulier. Pour aller plus loin, il va falloir identifier des critères objectifs de valorisation des données, et faire des usages de ces données un vecteur clé de sa valorisation.
Dans cet optique, nous pensons qu’un cadre méthodologique de valorisation des données est nécessaire.
Rhapsodies Conseil construit une approche méthodologique pour mesurer la valeur des données, en mettant les usages métiers des données au cœur de la méthodologie, approche que nous vous invitons à découvrir prochainement. En parallèle, nous vous recommandons les travaux initiés sur ces sujets par Doug Laney pour Gartner Inc., en particulier à travers son ouvrage « Infonomics » aux éditions Routledge.