Dans un récent post de blog, le Gartner prévoit que d’ici 2030, 60% des données d’entrainement des modèles d’apprentissage seront générées artificiellement. Souvent considérées comme substituts de qualité moindre et uniquement utiles dans des contextes réglementaires forts ou en cas de volumétrie réduite ou déséquilibrée des datasets, les données synthétiques ont aujourd’hui un rôle fort à jouer dans les systèmes d’IA.
Nous dresserons donc dans cet article un portrait des données synthétiques, les différents usages gravitant autour de leur utilisation, leur histoire, les méthodologies et technologies de génération ainsi qu’un rapide overview des acteurs du marché.
Les données synthétiques, outil de performance et de confidentialité des modèles de machine learning
Vous avez dit données synthétiques ?
Le travail sur les données d’entrainement lors du développement d’un modèle de Machine Learning est une étape d’amélioration de ses performances parfois négligée, au profit d’un fine-tuning itératif et laborieux des hyperparamètres. Volumétrie trop faible, déséquilibre des classes, échantillons biaisés, sous-représentativité ou encore mauvaise qualité sont tout autant de problématiques à adresser. Cette attention portée aux données comme unique outil d’amélioration des performances a d’ailleurs été mis à l’honneur dans une récente compétition organisée par Andrew Ng, la Data-centric AI competition.
Également, le renforcement des différentes réglementations sur les données personnelles et la prise de conscience des particuliers sur la valeur de leurs données et la nécessité de les protéger imposent aujourd’hui aux entreprises de faire évoluer leurs pratiques analytiques. Fini « l’open bar » et les partages et transferts bruts, il est aujourd’hui indispensable de mettre en place des protections de l’asset données personnelles.
C’est ainsi qu’entre en jeu un outil bien pratique quand il s’agit d’adresser de front ces deux contraintes : les données synthétiques.
Par opposition aux données « traditionnelles » générées par des événements concrets et retranscrivant le fonctionnement de systèmes de la vie réelle, elles sont générées artificiellement par des algorithmes qui ingèrent des données réelles, s’entraînent sur les modèles de comportement, puis produisent des données entièrement artificielles qui conservent les caractéristiques statistiques de l’ensemble de données d’origine.
D’un point de vue utilisabilité data on peut alors adresser des situations où :
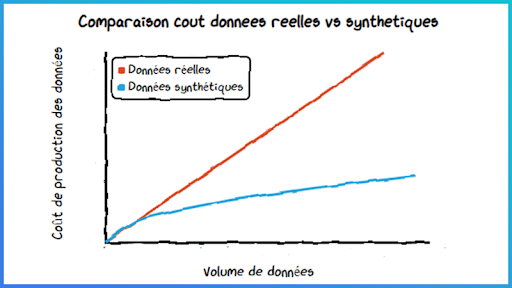
La donnée est coûteuse à collecter ou à produire – certains usages nécessitent par exemple l’acquisition de jeux de données auprès de data brokers. Ici, la génération et l’utilisation de données synthétiques permettent de diminuer les coûts d’acquisition et favorisent ainsi une économie d’échelle pour l’usage data considéré.
Le volume de données existant n’est pas suffisant pour l’application souhaitée – on peut citer les cas d’usage de détection de fraude ou de classification d’imagerie médicale, où les situations « d’anomalie » sont souvent bien moins représentées dans les jeux d’apprentissage. Dans certains cas, la donnée n’existe simplement pas et le phénomène que l’on souhaite modéliser n’est pas présent dans les datasets collectés. Dans ce cas d’usage, la génération de données synthétiques est toutefois à différencier des méthodes de « data augmentation », technique consistant à altérer une donnée existante pour en créer une nouvelle. Dans le cas d’une base d’images par exemple, ce processus d’augmentation pourra passer par des rotations, des colorisations, l’ajout de bruits… l’objectif étant d’aboutir à différentes versions de l’image de départ.
Il n’est pas nécessaire d’utiliser des données réelles, comme lors du développement d’un pipeline d’alimentation en données. Dans ces situations, un dataset synthétique peut être largement suffisant pour pouvoir itérer rapidement sur la mise en place de l’usage, sans se préoccuper de l’alimentation en données réelles en amont.
Mais comme vu précédemment, ces données synthétiques permettent aussi d’adresser certaines problématiques de confidentialité des données personnelles. En raison de leur nature synthétique, elles ne sont pas régies par les mêmes réglementations puisque non représentatives d’individus réels. Les data scientists peuvent donc utiliser en toute confiance ces données synthétiques pour leurs analyses et modélisations, sachant qu’elles se comporteront de la même manière que les données réelles. Cela protège simultanément la confidentialité des clients et atténue les risques (sécuritaires, concurrentiels, …) pour les entreprises qui en tirent parti, tout en levant les barrières de conformité imposées par le RGPD…
Parmi les bénéfices réglementaires de cette pratique :
Les cyber-attaques par techniques de ré-identification sont, par essence, inefficaces sur des jeux de données synthétiques, à la différence de datasets anonymisés : les données synthétiques n’étant pas issues du monde réel, le risque de ré-identification est ainsi nul.
La réglementation limite la durée pendant laquelle une entreprise peut conserver des données personnelles, ce qui peut rendre difficile la réalisation d’analyses à plus long terme, comme lorsqu’il s’agit de détecter une saisonnalité sur plusieurs années. Ici, les données synthétiques s’avèrent pratiques puisque non identifiantes : les entreprises ont ainsi le droit de conserver leurs données synthétiques aussi longtemps qu’elles le souhaitent. Ces données pourront être réutilisées à tout moment dans le futur pour effectuer de nouvelles analyses qui n’étaient pas menées auparavant ou même technologiquement irréalisables au moment de la collecte des données.
L’utilisation de services tiers (ex : ressources de stockage / calcul dans le cloud) nécessitent la transmission de données (parfois personnelles et sensibles) vers ce service. Il en va de même pour le partage de données avec des tiers pour réalisation d’analyses externes. En plus du casse-tête habituel de la conformité, cela peut (et devrait) être une préoccupation importante pour les entreprises, car une faille de sécurité peut rendre vulnérables à la fois leurs clients et leur réputation. Dans ce cas, utiliser des données synthétiques permet de réduire les risques liés aux transferts de données (vers des tiers, des fournisseurs de cloud, des prestataires ou encore des entités hors UE pour les entreprises européennes).
Un peu d’histoire…
L’idée de mettre en place des techniques de préservation de la confidentialité des données via les données synthétiques date d’une trentaine d’années, période à laquelle le US Census Bureau (organisme de recensement américain) décida de partager plus largement les données collectées dans le cadre de son activité. A l’époque, Donald B. Rubin, professeur de statistiques à Harvard, aide le gouvernement américain à régler des problèmes tels que le sous-dénombrement, en particulier des pauvres, dans un recensement, lorsqu’il a eu une idée, décrite dans un article de 1993 .
« J’ai utilisé le terme ‘données synthétiques’ dans cet article en référence à plusieurs ensembles de données simulées. Chacun semble avoir pu être créé par le même processus qui a créé l’ensemble de données réel, mais aucun des ensembles de données ne révèle de données réelles – cela présente un énorme avantage lors de l’étude d’ensembles de données personnels et confidentiels. »
Les données synthétiques sont nées.
Par la suite, on retrouvera des données synthétiques dans le concours ImageNet de 2012 et, en 2018, elles font l’objet d’un défi d’innovation lancé par le National Institute of Standards and Technology des États-Unis sur la thématique des techniques de confidentialité. En 2019, Deloitte et l’équipe du Forum économique mondial ont publié une étude soulignant le potentiel des technologies améliorant la confidentialité, y compris les données synthétiques, dans l’avenir des services financiers. Depuis, ces données artificielles ont infiltré le monde professionnel et servent aujourd’hui des usages analytiques multiples.
Méthodologies de génération de données synthétiques
Pour un dataset réel donné, on peut distinguer 3 types d’approche quant à la génération et l’utilisation de données synthétiques :
Données entièrement synthétiques – Ces données sont purement synthétiques et ne contiennent rien des données d’origine.
Données partiellement synthétiques – Ces données remplacent uniquement les valeurs de certaines caractéristiques sensibles sélectionnées par les valeurs synthétiques. Les valeurs réelles, dans ce cas, ne sont remplacées que si elles comportent un risque élevé de divulgation. Ceci est fait pour préserver la confidentialité des données nouvellement générées. Il est également possible d’utiliser des données synthétiques pour adresser les valeurs manquantes de certaines lignes pour une colonne donnée, soit par méthode déterministe (exemple : compléter un âge manquant avec la moyenne des âges du dataset) ou statistique (exemple : entraîner un modèle qui déterminerait l’âge de la personne en fonction d’autres données – niveau d’emploi, statut marital, …).
Données synthétiques hybrides – Ces données sont générées à l’aide de données réelles et synthétiques. Pour chaque enregistrement aléatoire de données réelles, un enregistrement proche dans les données synthétiques est choisi, puis les deux sont combinés pour former des données hybrides. Il est prisé pour fournir une bonne préservation de la vie privée avec une grande utilité par rapport aux deux autres, mais avec un inconvénient de plus de mémoire et de temps de traitement.
GAN ?
Certaines des solutions de génération de données synthétiques utilisent des réseaux de neurones dits « GAN » pour « Generative Adversarial Networks » (ou Réseaux Antagonistes Génératifs).
Vous connaissez le jeu du menteur ? Cette technologie combine deux joueurs, les « antagonistes » : un générateur (le menteur) et un discriminant (le « devineur »). Ils interagissent selon la dynamique suivante :
Le générateur ment : il essaie de créer une observation de dataset censée ressembler à une observation du dataset réel, qui peut être une image, du texte ou simplement des données tabulaires.
Le discriminateur – devineur essaie de distinguer l’observation générée de l’observation réelle.
Le menteur marque un point si le devineur n’est pas capable de faire la distinction entre le contenu réel et généré. Le devineur marque un point s’il détecte le mensonge.
Plus le jeu avance, plus le menteur devient performant et marquera de points. Ces « points » gagnés se retrouveront modélisés sous la forme de poids dans un réseau de neurones génératif.
L’objectif final est que le générateur soit capable de produire des données qui semblent si proches des données réelles que le discriminateur ne puisse plus éviter la tromperie.
Pour une lecture plus approfondie sur le sujet des GANs, il en existe une excellente et détaillée dans un article du blog Google Developers.
Un marché dynamique pour les solutions de génération de données synthétiques
Plusieurs approches sont aujourd’hui envisageables, selon que l’on souhaite s’équiper d’une solution dédiée ou bien prendre soi-même en charge la génération de ces jeux de données artificielles.
Parmi les solutions Open Source, on peut citer les quelques librairies Python suivantes :
Mais des éditeurs ont également mis sur le marché des solutions packagées de génération de données artificielles. Aux Etats-Unis, notamment, les éditeurs spécialisés se multiplient. Parmi eux figurent Tonic.ai, Mostly AI, Latice ou encore Gretel.ai, qui affichent de fortes croissances et qui ont toutes récemment bouclé d’importantes levées de fond
Un outil puissant, mais…
Même si l’on doit être optimiste et confiant quant à l’avenir des données synthétiques pour, entre autres, les projets de Machine Learning, il existe quelques limites, techniques ou business, à cette technologie.
De nombreux utilisateurs peuvent ne pas accepter que des données synthétiques, « artificielles », non issues du monde réel, … soient valides et permettent des applications analytiques pertinentes. Il convient alors de mener des initiatives de sensibilisation auprès des parties prenantes business afin de les rassurer sur les avantages à utiliser de telles données et d’instaurer une confiance en la pertinence de l’usage. Pour asseoir cette confiance :
Bien que de nombreux progrès soient réalisés dans ce domaine, un défi qui persiste est de garantir l’exactitude des données synthétiques. Il faut s’assurer que les propriétés statistiques des données synthétiques correspondent aux propriétés des données d’origine et mettre en place une supervision sur le long terme de ce matching. Mais ce qui fait également la complexité d’un jeu de données réelles, c’est qu’il capture les micro-spécificités et les cas hyper particuliers d’un cas d’usage donné, et ces « outliers » sont parfois autant voire plus important que les données plus traditionnelles. La génération de données synthétiques ne permettra pas d’adresser ni de générer ce genre de cas particuliers à valeur.
Également, une attention particulière est à porter sur les performances des modèles entrainés, partiellement ou complètement, avec des données synthétiques. Si un modèle performe moins bien en utilisant des données synthétiques, il convient de mettre cette sous-performance en regard du gain de confidentialité et d’arbitrer la perte de performance que l’on peut accepter. Dans le cas contraire où un modèle venait à mieux performer quand entrainé avec des données synthétiques, cela peut lever des inquiétudes quand à sa généralisation future sur des vraies données : un monitoring est donc nécessaire pour suivre les performances dans le temps et empêcher toute dérive du modèle, qu’elle soit de concept ou de données.
Aussi, si les données synthétiques permettent d’adresser des problématiques de confidentialité, elles ne protègent naturellement pas des biais présents dans les jeux de données initiaux et ils seront statistiquement répliqués si une attention n’y est pas portée. Elles sont cependant un outil puissant pour les réduire, en permettant par exemple de « peupler » d’observations synthétiques des classes sous-représentées dans un jeu de données déséquilibré. Un moteur de classification des CV des candidats développé chez Amazon est un exemple de modèle comportant un biais sexiste du fait de la sous représentativité des individus de sexe féminin dans le dataset d’apprentissage. Il aurait pu être corrigé via l’injection de données synthétiques représentant des CV féminins.
On conclura sur un triptyque synthétique imageant bien la puissance des sus-cités réseaux GAN, utilisés dans ce cas là pour générer des visages humains synthétiques, d’un réalisme frappant.
Il est à noter que c’est également cette technologie qui est à l’origine des deepfakes, vidéos mettant en scène des personnalités publiques ou politiques tenant des propos qu’ils n’ont en réalité jamais déclarés (un exemple récent est celui de Volodymyr Zelensky, président Ukrainien, victime d’un deepfake diffusé sur une chaine de télévision d’information).
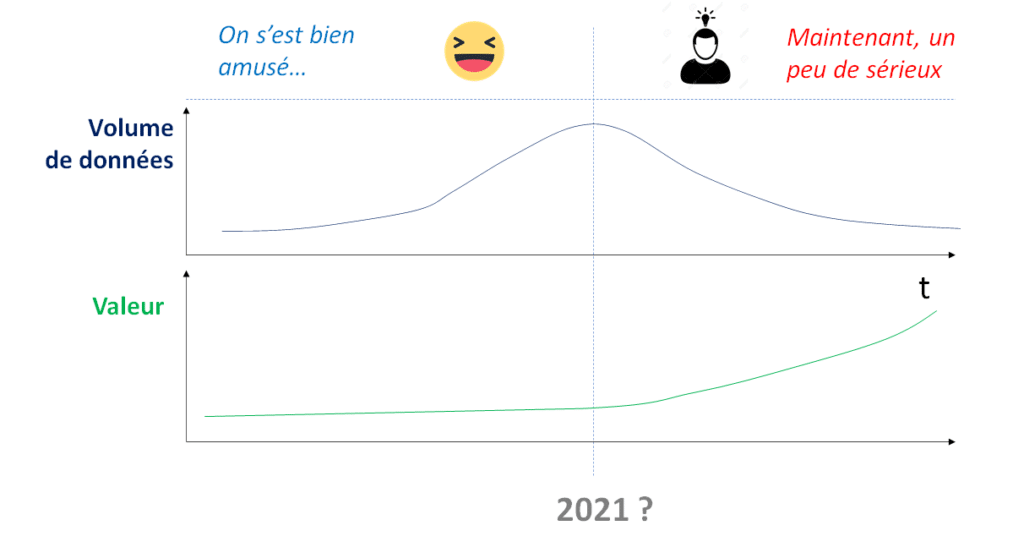
Nous entrons dans une ère où les actifs de l’organisation doivent être mis au service de l’essentiel. Il est temps de dire au revoir au data lake « fourre tout », et d’assurer la maîtrise des données essentielles pour la stratégie et la raison d’être de l’organisation. La gouvernance des données devra être pragmatique pour assurer que les investissements (stockages, traitements, compétences data, …) sont mis au service de ce qui compte vraiment.
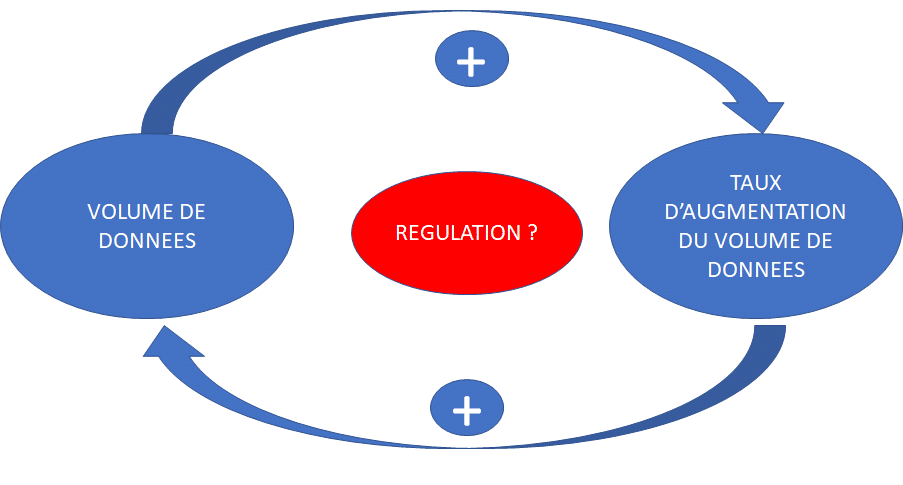
Le rôle du Chief Data Officer de 2021 est de réguler/minimiser au maximum les comportements automatisés ou humains qui génèrent toujours plus de volume, mais… pas toujours plus de valeur. Ces comportements prennent parfois la forme de boucles de rétroactions positives, non régulées. Il est temps de trouver le bon niveau de régulation pour limiter ces proliférations, vers plus de sobriété. Ce sera un bien pour votre portefeuille et pour l’environnement.
Une donnée… fait des petits
Voici un exemple de rétroaction :
Une donnée fait des petits (copies, données transformées pour des usages spécifiques, parfois ponctuels, ,..). Plus les volumes de données stockées sont importantes dans votre organisation et plus l’augmentation de ces mêmes volumes demain aura tendance à être grande. Duplication des données, copier coller à droite à gauche… Sans une gouvernance aboutie des données en guise de régulation : plus il y a de données… plus il y aura de données, sans même que vous l’ayez demandé ou voulu ! Au même titre que plus il y a de gens sur cette planète, plus il y aura de naissances…
Quelles régulations ?
Faire le tri dans vos données existantes, c’est comme faire le tri dans votre appartement après une grosse dépression : C’est le « bordel ». Vous devez ranger. Vous commencez par enlever tout ce qui n’a clairement rien à faire là et qui n’est pas utile (les déchets, les vieux papiers sans utilité, …), vous remplissez quelques poubelles sans trop d’état d’âme. Puis vient l’étape plus minutieuse, où vous prenez le temps par catégorie. Vous vous posez vraiment la question : « Dans ce qui reste, de quoi puis-je me passer ? ». Alors vous triez en paquets « je garde, je ne peux pas m’en passer », « ça peut, peut être, servir », « je suis décidé, je m’en débarrasse ».
Pour les données c’est pareil. Il y a toujours des petits malins pour dire : « Gardons l’historique, après tout, ça peut peut être servir un jour, c’est le principe du data lake non ? » Non, parce qu’une donnée stockée a un coût environnemental et financier, si on ne sait pas dire simplement pourquoi elle est là, alors elle n’a pas à être là. Fin de la partie. « Delete »… Dans l’ère du « Big Data », ce réflexe n’est pas naturel (c’est le moins qu’on puisse dire) et pourtant il est précieux, et vous évitera bien des problèmes, plus qu’il ne vous fera manquer d’opportunités…
L’ajout d’une nouvelle donnée doit être justifiée « by design ». Une application sera conçue en appliquant le principe de « Data Minimization », pas seulement pour les données personnelles mais pour toutes les données. Si la valeur de la donnée n’est pas avérée, alors on ne demande pas à l’utilisateur de la saisir. L’UX n’en sera que plus épurée, et ça fera un problème de moins à gérer, et un bienfait pour la charge mentale de vos utilisateurs, clients, collaborateurs.
La gouvernance des données doit intégrer dans son ADN ce principe simple et parfois oublié : une donnée qui n’a pas d’usages clairement qualifiés n’a rien à faire dans les bases de données de votre organisation.
Et malheureusement, l’augmentation des volumes peut générer rapidement des pertes de qualité
Parce que plus il y a d’objets et de meubles dans votre appartement, plus il faut prendre du temps pour nettoyer…Il faut bouger les meubles pour nettoyer derrière, soulever les objets pour nettoyer en dessous… Vous n’y échapperez pas, pour les données c’est pareil. La gouvernance des données doit assurer le coup de chiffon qui va bien au bon moment pour limiter les risques de non qualité ou de sécurité, et réduire l’empreinte carbone du système d’information.
Voilà un challenge que le Chief Data Officer devrait s’approprier davantage à l’échelle de son organisation. Maîtriser les volumes et la prolifération des données, pour être capable de maintenir un niveau de qualité acceptable, et documenté : Un utilisateur ou un projet doit être alors capable en toute autonomie de décider si le niveau de qualité de l’information est suffisant pour l’usage qu’il veut en faire, et, si son usage le justifie, qualifier des exigences de qualité supérieur à ce qu’il a aujourd’hui (fraicheur, complétude, ..) avec les équipes en charge des données.
C’est également la juste contribution du CDO dans les prochaines années à la maîtrise de l’empreinte carbone du numérique, en régulant la masse de ses actifs data plus sérieusement qu’il ne le fait aujourd’hui.
Moins de volume ET plus de valeur : Vous relevez le défi ?
« La data actif essentiel et incontestable de nombreuses organisations ».
Il suffit de poursuivre cette phrase en citant 2 ou 3 chiffres clefs de grands cabinets de conseil en stratégie, et voilà l’argument d’autorité posé… Oui mais quand on a dit ça, hé bien, qu’est-ce qu’on en fait ?
« La data » est en effet transverse aux entités d’une organisation, source d’opportunités commerciales, d’innovation ou de relation client de qualité, mais elle est bien souvent jugée comme un sujet technique ou abstrait. Le rôle de CDO est encore récent dans de nombreuses organisations : il lui faut trouver sa place et la meilleure articulation avec les Métiers, la DSI, mais aussi la Direction Générale. Il y a donc un enjeu à ce que ce dernier asseye son rôle stratégique dans toute organisation qui veut gérer ses données comme des actifs stratégiques. Le Chief Data Officer a un rôle clef, transverse et à de multiples facettes pour exploiter pleinement le potentiel que représentent les données : compétences humaines, techniques et de leadership. Il doit incarner la transformation vers un mode d’organisation orienté données.
Constructeur de fondations stables
Partons du plus évident (mais pas forcément du plus simple !). Pour toute construction il faut des fondations stables, hé bien avec la data c’est pareil. Des « datas », objets parfois suspects et mal identifiés, sont stockées un peu partout dans les bases de données des entreprises, des Sharepoint collaboratifs ou des fichiers Excel sur le disque dur des collaborateurs… La clef sera dans un premier temps de maîtriser et de sécuriser ces données. Le CDO doit impulser cette dynamique, s’assurer que les données soient connues (recensement dans un data catalog par exemple), accessibles (stockage efficient ), de qualité (règle de gouvernance des données avec des data owners), conformes aux réglementations et à l’éthique (RGPD ou autre) et répondent à des cas d’usages simples et concrets (avant de vouloir faire de l’IA ne faut-il pas que les reporting opérationnels les plus basiques et indispensables soient bien accessibles par les bonnes personnes au bon moment et avec le bon niveau de qualité ?).
Le CDO : architecte et chef d’orchestre
Le Chief Data Officer doit être l’architecte (rôle opérationnel) et le chef d’orchestre (rôle stratégique) de ces projets de fondations en concertation avec les métiers et l’IT. Avec son équipe, il doit accompagner les métiers pour répondre aux usages à valeur et avancer de façon pragmatique. Rien ne sert de lancer 12 projets stratégiques sur la data en même temps : apporter des preuves concrètes en traitant de façon pertinente 2 ou 3 cas d’usages clefs pour améliorer les enjeux opérationnels et vous pouvez être certain que la dynamique métier autour de votre transformation data sera bien mieux lancée ! Il en est de même pour l’IT : il doit aussi soigner sa relation avec la DSI avec laquelle il doit travailler sur des solutions concrètes nécessaires à la mise en œuvre de sa vision data et des usages métiers.
Le Chief Data Officer doit être fédérateur
Le CDO n’a pas nécessairement pour vocation à prendre en charge lui-même l’ensemble des sujets qui traitent de la donnée. Les métiers doivent être des acteurs de première ligne sur le sujet. Le CDO s’intègre régulièrement à un existant désordonné, où les sujets sont déjà plus ou moins traités, mais de façon dispersée. Il doit apporter la vision transverse tout en laissant de l’autonomie aux métiers. Dans la mesure où les équipes data se sont constituées et professionnalisées dans les grands groupes, l’enjeu se déplace aujourd’hui vers la capacité à faire travailler ensemble tous les départements de l’organisation. L’acculturation de l’entreprise et la formation des équipes sont au cœur des enjeux du CDO en 2021.
En résumé : le Chief Data Officer doit faire preuve de savoir-faire mais aussi de savoir-être. Il doit incarner la vision, adosser son action au sponsorship inconditionnel de la Direction Générale, tout en restant au contact des équipes métier et en travaillant avec bonne intelligence avec les équipes IT.
Chiefs Data Officers, si vous n’aviez qu’une idée à retenir de cet article : pour en tirer sa valeur, la data doit pouvoir être expliquée et comprise par ma grand-mère (et je précise que ma grand-mère n’est pas data scientist !) ; visez le pragmatisme et les sujets à valeur immédiate pour votre organisation. Cela fondera le socle indispensable de votre transformation data dans la durée : expériences, résultats concrets et crédibilité !
Les idées exposées ici sont peut-être évidentes pour certains, utiles pour d’autres ! En tout cas, chez Rhapsodies Conseil, au sein de notre équipe Transformation Data, nous essayons d’appliquer cela systématiquement, et nous pensons que c’est le minimum vital.
A l’heure de l’omniprésence algorithmique dans une multitude de domaines de notre société, une commission européenne dédiée publiait, il y a un an déjà, un livre blanc mettant en lumière le concept d’IA de confiance. Si ce concept englobe une multitude de notions et d’axes de réflexion (prise en compte des biais, robustesse des algorithmes, respect de la privacy, …), nous nous intéresserons ici particulièrement à la transparence et l’explicabilité des systèmes d’IA. Dans cette optique et après un rappel des enjeux et challenges de l’explication des modèles, nous construirons un simple tableau de bord rassemblant les principales métriques d’explicabilité d’un modèle, à l’aide d’une librairie Python spécialisée : Explainer-Dashboard.
Vous avez dit “explicabilité” ?
L’IA Explicable est l’intelligence artificielle dans laquelle les résultats de la solution peuvent être compris par les humains. Cela contraste avec le concept de «boîte noire» où parfois même les concepteurs du modèle ne peuvent pas expliquer pourquoi il est arrivé à une prédiction spécifique.
Le besoin d’explicabilité de ces algorithmes peut être motivé par différents facteurs :
la confiance des utilisateurs et personnes concernées en leur justesse et en l’absence de biais ;
l’obligation réglementaire de pouvoir justifier et expliquer toute décision prise sur recommandation de l’algorithme : si le RGPD prévoit vaguement que toute décision prise par une IA doive être expliquée à la personne concernée sur demande, la loi française est bien plus précise. En prévoyant la mise à disposition d’informations concernant le degré et le mode de contribution du traitement algorithmique à la prise de décision, les données traitées et leurs sources, les paramètres de traitement et, le cas échéant, leur pondération, appliqués à la situation de l’intéressé et les différentes opérations effectuées par le traitement. Les secteurs bancaires et assurantiels sont particulièrement surveillés sur le sujet, notamment via l’action de l’ACPR.
Quand on adresse cette problématique, il convient de définir les différents termes (étroitement liés) que l’on peut retrouver :
La transparence donne à comprendre les décisions algorithmiques : elle traduit une possibilité d’accéder au code source des algorithmes, aux modèles qu’ils produisent. Dans le cas extrême d’une opacité totale, on qualifie l’algorithme de « boîte noire » ;
L’auditabilité caractérise la faisabilité pratique d’une évaluation analytique et empirique de l’algorithme, et vise plus largement à obtenir non seulement des explications sur ses prédictions, mais aussi à l’évaluer selon les autres critères indiqués précédemment (performance, stabilité, traitement des données) ;
L’explicabilité et l’interprétabilité, que l’on peut distinguer comme suit :
Si l’on considère des travaux de chimie au lycée, une interprétabilité de cette expérience serait “on constate un précipité rouge”. De son côté, l’explicabilité de l’expériencenécessitera de plonger dans les formules des différents composants chimiques.
Note : dans un souci de simplification, nous utiliserons largement le terme “explicabilité” dans la suite de cet article.
Via l’explication d’un modèle, nous allons chercher à répondre à des questions telles que :
Quelles sont les causes d’une décision ou prédiction donnée ?
Quelle est l’incertitude inhérente au modèle ?
Quelles informations supplémentaires sont disponibles pour la prise de décision finale ?
Les objectifs de ces explications sont multiples, car dépendants des parties prenantes :
faciliterles échanges itératifs avec les métiers, en imageant rapidement comment le modèle utilise les variables d’entrée pour répondre au problème posé ;
rassurerles experts métiers et les équipes en charge de la conformité sur l’absence de biais algorithmique ;
faciliter la validation du modèle par les équipes de conception et de validation ;
garantir la confiance des individus impactés par les décisions ou prédictions de l’algorithme.
Et concrètement ?
Le caractère “explicable” d’une IA donnée va principalement dépendre de la méthode d’apprentissage associée. Les méthodes d’apprentissage sont structurées en deux groupes conduisant, selon leur type, à un modèle explicite ou à une boîte noire :
Dans le cas d’un modèle explicite (linéaire, gaussien, binomial, arbres de décision,…), la décision qui en découle est nativement explicable. Sa complexité (principalement son nombre de paramètres) peut toutefois endommager son explicabilité ;
La plupart des autres méthodes et algorithmes d’apprentissage (réseaux neuronaux, agrégation de modèles, KNN, SVM,…) sont considérés comme des boîtes noires avec néanmoins la possibilité de construire des indicateurs d’importance des variables.
Lors du choix d’un modèle de Machine Learning, on parle alors du compromis Performance / Explicabilité.
Récupérer les données et entraîner un modèle simple
Pour cette démonstration, notre cas d’usage analytique sera de prédire, pour un individu donné, le risque d’occurrence d’une défaillance cardiaque en fonction de données de santé, genre, âge, vie professionnelle, …
Si cette problématique ne revêt pas spécifiquement d’aspect éthique relatif à la transparence de l’algorithme utilisé, nous pouvons toutefois bien percevoir l’utilité de l’explicabilité d’un diagnostic de risque assisté par IA : collaboration facilitée avec l’expert métier (en l’occurrence, le médecin) et information plus concrète du patient, entre autres bénéfices.
Le jeu de données éducatif utilisé est fourni par l’OMS et peut être téléchargé sur la plateforme de data science Kaggle :
Il contient les données de 5110 personnes, réparties comme suit :
Données :
Age du sujet ;
Genre du sujet ;
A déjà souffert d’hypertension (oui / non)
A déjà souffert de maladies cardiaques (oui / non)
Statut marital
Type d’emploi
Type de résidence (citadin, rural)
Niveau moyen sanguin de glucose
IMC
Fumeur (oui / non)
Note : nous avons procédé à une simple préparation des données qu’il est possible de retrouver dans le notebook complet en bas de page.
Pour la partie modélisation, nous utiliserons un modèle « baseline » de Random Forest. Pour éviter que notre modèle ne reflète seulement que la distribution des classes (très déséquilibrée dans notre cas, 95-5), nous avons ajouté des données “synthétiques” à la classe la moins représentée (i.e. les patients victimes de crises cardiaques) en utilisant l’algorithme SMOTE, pour atteindre une répartition équilibrée (50-50) :
Notre modèle est prêt, nous pouvons à présent l’utiliser en input du dashboard !
Création du dashboard
Nous avons donc à disposition un modèle entraîné sur notre dataset et allons à présent construire notre tableau de bord d’interprétation de ce modèle.
Pour ce faire, nous utilisons la librairie explainer-dashboard, qui s’installe directement via le package installer pip :
pip install --upgrade explainerdashboard
Une fois la librairie installée, nous pouvons l’importer et créer simplement une instance “Explainer” à l’aide des lignes suivantes :
Plusieurs modes d’exécution sont possibles (directement dans le notebook, dans un onglet séparé hébergé sur une IP locale, …) (plus d’informations sur les différents paramètres de la librairie dans sa documentation).
Note : le dashboard nécessitera d’avoir installé la librairie de visualisation “Dash” pour fonctionner.
Interprétation des différents indicateurs
Le tableau de bord se présente sous la forme de différents onglets, qu’il est possible d’afficher / masquer via son paramétrage :
Features importance : impact des différents features du jeu de données sur les prédictions ;
Classification Stats : aperçu complet de la performance du modèle de classification utilisé (ici, Random Forest) ;
Individual Predictions & What if analysis : zoom sur les prédictions individuelles et influence des features sur ces dernières ;
Features dependance : visualisation de l’impact de couples de features sur les prédictions et corrélations entre features ;
Decision Trees : permet, pour les modèles à base d’arbres de décision, de visualiser les paramètres et cheminement de décisions de chacun de ces arbres.
Plongeons à présent dans les détails de chacun de ces onglets !
Features Importance
A l’instar de l’attribut feature_importances_ de notre modèle de Random Forest, cet onglet nous permet de visualiser, pour chaque colonne de notre dataset, le pouvoir de prédiction de chaque variable.
L’importance des features a ici été calculée selon la méthode des valeurs de SHAP (acronyme de SHapley Additive exPlanations). Nous n’approfondirons pas ce concept dans cet article (voir rubrique “aller plus loin”).
Ces scores d’importance peuvent permettre de :
Mieux comprendre les données à disposition et ainsi, avec l’aide d’un expert métier, détecter lesquelles seront les plus pertinentes pour notre modèle ;
Mieux comprendre notre modèle et son fonctionnement, puisque les scores d’importance peuvent varier en fonction du modèle choisi ;
En phase d’optimisation de celui-ci, diminuer son nombre de variables pour en réduire sa durée d’entraînement, en augmenter son explicabilité, faciliter son déploiement ou encore atténuer le phénomène d’over-fitting.
Dans l’exemple ci-dessous, on peut constater que :
l’âge, l’IMC et le niveau moyen de glucose dans le sang sont des prédicteurs forts du risque de crise cardiaque, ce qui correspond bien à une intuition commune ;
Toutefois, d’autres prédicteurs forts sortent du lot, comme le fait de ne jamais avoir été marié ou encore le fait d’habiter en zone rurale, qui ne sont pas évidents à première vue …
Classification Stats
Cet onglet nous permet de visualiser les différentes métriques de performance de notre modèle de classification : matrice de confusion, listing des différents scores, courbes AUC, … Il sera utile en phase de paramétrage / optimisation du modèle pour avoir un aperçu rapide et complet de sa performance :
Individual Predictions
Cet onglet va nous permettre, pour un individu donné, de visualiser les 2 indicateurs principaux relatifs à la décision prise par le modèle :
Le graphe des contributions :
La contribution d’un feature à une prédiction représente l’impact probabilistique sur la décision finale de la valeur de la donnée considérée.
Suite à notre traitement du déséquilibre des classes, nous avons autant de sujets “sains” que de sujets “à risque” dans notre jeu de données d’apprentissage. Un estimateur aléatoire aura donc 50% de chances de trouver la bonne prédiction. Cette probabilité est donc la valeur “baseline” d’entrée dans notre graphe des contributions.
Ensuite, viennent s’ajouter en vert sur le visuel les contributions des features pour lesquelles la valeur a fait pencher la décision vers un sujet “à risque”. Ces features et leur contribution amènent la décision à une probabilité de ~60% de risque.
Puis, les features dont la contribution fait pencher la décision vers un sujet “sain” viennent s’ajouter (en rouge sur le graphe). On retrouve ici nos prédicteurs forts tels que l’âge ou encore l’IMC.
> Le sujet est proposé comme sain par l’algorithme
Le graphe des dépendances partielles :
Ce visuel nous permet de visualiser la probabilité de risque en fonction de la variation d’une des features, en conservant la valeur des autres constantes. Dans l’exemple ci-dessus, on peut voir que pour l’individu considéré, augmenter son âge aura pour effet d’augmenter sa probabilité d’être détecté comme “à risque”, ce qui correspond bien au sens commun.
What if Analysis
Dans l’optique de l’onglet précédent, l’analyse “what if” nous permet de renseigner nous mêmes les valeurs des différents features et de calculer l’output du modèle pour le profil de patient renseigné :
Il reprend par ailleurs les différents indicateurs présentés dans l’onglet précédent : graphe des contributions, dépendances partielles, …
Features Dependance
Cet onglet présente un graphe intéressant : la dépendance des features.
Il nous renseigne sur la relation entre les valeurs de features et les valeurs de SHAP. Il permet ainsi d’étudier la relation générale entre la valeur des features et l’impact sur la prédiction.
Dans notre exemple ci-dessus, le nuage de points nous apprend deux choses :
L’âge (abscisses) est un fort prédicteur pour notre cas d’usage car, pour chaque observation, les valeurs de SHAP (ordonnées) sont élevées (mais nous le savions déjà). On remarque une inversion de la tendance autour de l’âge de 50 ans, ce qui conforte notre intuition (i.e. les sujets plus jeunes sont moins enclins à être considérés comme “à risque”) : une valeur de SHAP “hautement négative” nous indique que la feature est un prédicteur fort d’un résultat associé à la classe nulle (ici, un individu désigné comme “sain”) – à l’inverse, une valeur de SHAP “hautement positive” indique que la feature est un prédicteur fort d’un résultat associé à la classe positive (ici, un individu désigné comme “à risque”).
L’âge est fortement corrélé au statut marital des individus observés (points rouges = individus célibataires). Cela est cohérent avec le sens commun mais nous renseigne également sur le pouvoir prédictif du statut marital qui ne serait finalement dû qu’à sa forte corrélation à l’âge, vrai prédicteur important de notre problématique. Dans une optique d’optimisation du modèle, cette feature pourrait potentiellement être retirée.
Decision Trees
Enfin, dans le cas où l’input du dashboard est un modèle à base d’arbres de décisions (gradient boosted trees, random forest, …), cet onglet sera utile pour visualiser le cheminement des décisions de la totalité des arbres du modèle.
Dans l’exemple ci-dessous, nous considérons le 2712ème individu du jeu de données pour lequel 50 arbres ont été calculés via l’algorithme de Random Forest. Nous visualisons la matrice de décision de l’arbre n°13 :
Ce tableau nous montre le cheminement de la décision, depuis une probabilité de ~50% (qui serait la prédiction d’un estimateur ne se basant que sur la moyenne observée sur le jeu de données). On peut constater que, pour cet individu et pour l’arbre de décision considéré :
La ruralité, l’occupation professionnelle et le statut marital (bien que démontré précédemment comme prédicteur faible) ont poussé la décision de cet arbre vers “individu à risque” ;
Les autres données de l’individu telles que son genre ou encore son âge ont fait basculer la décision finale de l’arbre à “individu sain” (probabilité de risque finale : 7.14%).
L’onglet nous propose également une fonctionnalité de visualisation des arbres via la librairie graphviz.
L’étude des différents indicateurs présentés dans les onglets du dashboard nous a permis :
De confirmer des premières intuitions sur les variables importantes de ce problème de modélisation : l’âge du patient, son IMC ou encore son taux moyen de glucose ;
A l’inverse, de conclure de la pertinence relativement moindre de variables telles que le statut marital (merci à la dépendance des features !), le statut professionnel, le lieu de résidence mais également les antécédents cardiaques (moins évident à priori…). On pourra alors se poser la question de conserver ou non ces variables dans une optique de simplification du modèle ;
De mesurer la performance globale du modèle et, derrière une accuracy honorable de ~0.80, de découvrir de pauvres recall et precision (respectivement 0.44 et 0.14) : notre modèle est donc plus performant pour détecter les Vrais Négatifs (les sujets “sains”) que les sujets réellement à risque. Il faudra travailler à l’optimiser autrement.
De procéder à des analyses de risque et de comportement du modèle sur un patient donné via l’interface de l’onglet “What if…”.
L’étude de ces indicateurs doit être partie intégrante de tout projet d’IA actuel et futur
L’explicabilité des modèles de Machine Learning, aujourd’hui considéré comme l’un des piliers d’une IA éthique, responsable et de confiance, représente un challenge important pour accroître la confiance de la société envers les algorithmes et la transparence de leurs décisions, mais également la conformité réglementaire des traitements en résultant.
Dans notre cas d’étude, si la librairie explainer-dashboard est à l’initiative d’un particulier, on remarque une propension à l’éclosion de plusieurs frameworks et outils servant le mouvement “Fair AI”, dont plusieurs développés par des mastodontes du domaine. On peut citer le projet AIF360 lancé par IBM, une boîte à outils d’identification et de traitement des biais dans les jeux de données et algorithmes.
Cette librairie est utile en phase de développement et d’échanges avec le métier mais peut toutefois ne pas suffire en industrialisation. Alors un dashboard “maison” sera nécessaire. Elle a toutefois un potentiel élevé de personnalisation qui lui permettra de répondre à de nombreux usages.
La data science est devenue un levier clé aujourd’hui, pour mettre les données au service de bénéfices et de problématiques métiers : Automatisation de tâches & de choix, Fourniture de nouveaux services « intelligents », Amélioration de l’expérience client, Recommandations, etc.
C’est aussi une discipline qui passionne par son caractère particulièrement « innovant », encore aujourd’hui, mais qui génère des croyances sur ce qu’elle peut réellement apporter à une organisation. Certains dirigeants ont souvent donné trop de valeur intrinsèque à la discipline, s’attendant à des retours importants sur leurs investissements (data lake & armées de data scientist / engineers).
En réalité, la Data Science n’est qu’une technique qui a besoin de méthodologie et de discipline. A ce titre, elle nécessite au préalable de très bien définir les problèmes métiers à résoudre. Et quand bien même le problème est bien défini, et le modèle statistique pour y répondre performant, cela ne suffit pas encore. Le modèle doit être utilisable « en pratique » dans les processus métiers opérationnels, s’intégrer parfaitement dans l’expérience utilisateur, etc.
Quels principes clés peut-on se proposer d’appliquer pour maximiser la valeur de cette capacité ? Essayons ici de donner quelques pistes.
Comprendre le métier : analyser les risques, les besoins d’optimisation, les nouvelles opportunités
L’identification d’usages métier, qui nécessitent des méthodes d’analyse de données avancées, est une étape clé. Ces usages ne tombent souvent pas du ciel. Une démarche proactive avec les métiers est nécessaire pour les identifier. C’est d’autant plus vrai lorsque le métier est encore peu familiarisé avec les techniques de data science, et ce qu’il est possible d’en tirer concrètement.
C’est un travail de “business analysis”, dont la Data Science n’a absolument pas le luxe de se passer contrairement à ce qui est pratiqué parfois : Comment travaille le métier aujourd’hui ? Quels sont ses enjeux, ses drivers, ses axes d’innovation, ses axes d’optimisations des processus opérationnels en place, et quelles données sont manipulées aujourd’hui, comment et pour quoi faire ? Quel est le niveau de qualité de la donnée, manque-t-il des informations clés pour répondre aux problèmes quotidiens, ou pour innover ? etc.
Quand on est au clair sur toutes ces questions, on est prêt à identifier des usages concrets avec le métier, qui pourraient bénéficier de techniques d’analyse avancée.
Comprendre l’usage et le système concerné : adopter le point de vue systémique !
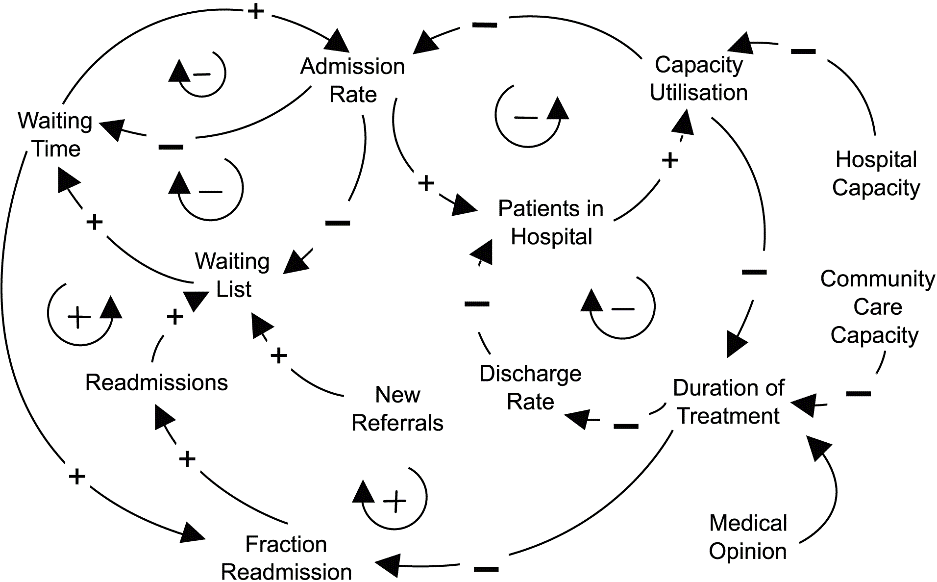
Imaginons que nous cherchons à prédire le flux de patients sur un jour donné dans un hôpital, afin d’adapter les ressources, les processus, les dispositifs pour limiter le temps d’attente. Il convient, avant de foncer tête baissée dans l’analyse des données, de comprendre l’ensemble de la problématique. Par exemple, les approches de « system thinking » peuvent être tout à fait adaptées pour que le data scientist s’assure de ne pas oublier de paramètres clés dans la dynamique du problème qu’il veut résoudre. Ainsi, il n’oubliera pas non plus des données clés pour son modèle (existantes ou dont il faudrait organiser la collecte à l’avenir pour améliorer le modèle).
Ce type de représentation (ici : Causal loop diagram), peut permettre au métier de s’exprimer sur le processus, sur l’identification des variables clés, et de formuler ses intuitions sur les paramètres et les dynamiques en jeu qui peuvent influer sur la variable à prédire ! (ici les influences positives ou négatives entre les variables structurantes décrivant la dynamique du système).
Le diagramme ci-dessus n’est qu’un exemple de représentation systémique, on peut adopter d’autres types de représentation du système au besoin. L’important étant d’étendre la compréhension du système, qui peut nous amener à identifier des variables cachées (non intuitives a priori).
Concrétiser un usage : prototyper au plus tôt avec le métier, dans son environnement de travail, au risque de rester éternellement au statut de POC !
Une fois que le système est bien défini, et que les hypothèses et intuitions sont posées, il faut comprendre : comment le modèle analytique sera concrétisé en pratique, qui sera l’utilisateur final, quel est son environnement de travail actuel et comment on pourra intégrer les résultats d’un modèle statistique dans son travail quotidien.
Une technique simple et confortable pour le métier : faire un prototype rapide, même avec des fausses données pour commencer, des faux résultats de modèles statistiques. Bref, l’idée est rapidement de se projeter dans l’usage final de la manière la plus concrète possible, pour aider le métier à s’inscrire dans sa future expérience. Évidemment, nous ne resterons pas éternellement avec des fausses données.
L’objectif est d’être tout à fait au clair, dès le départ, sur le produit fini que l’on veut atteindre, et de s’assurer que le métier le soit tout à fait (ce qui est loin d’être toujours le cas). Ensuite, nous pourrons pousser le prototype plus loin (des vrais données, des vraies conditions pour évaluer la performance, etc.).
Cette méthode permet au data scientist de se mettre à la place de l’utilisateur final, et de mieux comprendre comment son modèle devra aider (est-ce qu’il doit apporter juste une classification, un niveau de probabilité, des informations contextuelles sur la décision prise par le modèle, est-ce qu’il doit favoriser le temps de réponse, l’explicabilité, la performance du modèle, etc.). Toutes ces questions trouvent rapidement une réponse quand on se projette dans le contexte d’usage final.
Interagir par itération avec le business, éviter l’effet Kaggle
Nous pouvons rencontrer parfois un comportement (compréhensible), qui est de vouloir faire le modèle le plus performant possible, à tout prix. On passe des heures et des jours en feature engineering, tuning du modèle, on tente toutes combinaisons possibles, on ajoute / teste des données exotiques (au cas où) qui ne sont pourtant pas identifiées en phase de “business analysis”. Je l’appellerai l’effet « Data Challenge » ou l’effet « KAGGLE*».
Et après avoir passé des jours enfermés dans sa grotte, on arrive tout fier devant le métier en annonçant une augmentation de 1% du score de performance du modèle, sans même avoir songé que 1% de moins pourrait tout à fait répondre aux exigences du métier… Comme on dit… « Le mieux est l’ennemi du bien ». Pour éviter cet effet tunnel qui peut être tentant pour l’analyste (qui veut annoncer le meilleur score à tout prix ou qui joue trop sur Kaggle*), des itérations les plus fréquentes possibles avec le métier sont clés.
Arrêtons-nous au bon moment ! Et cela vaut pour toutes les phases du projet. Commençons par chiffrer le système décrit en phase de business analyse, avec des données réelles, et itérons avec le métier sur cette base. Cela permet d’améliorer déjà la compréhension du problème du data scientist, et du métier concerné. Et cela a déjà une vraie valeur pour le métier ! Alors qu’aucun modèle statistique n’a été conçu pour le moment.
Si un modèle nécessite des données inexistantes, organisons la collecte de ces données avec le Chief data officer, dans le temps. Mais ne nous battons pas à vouloir faire un modèle avec des miettes, si nous savons que cela ne permettra pas d’être à la hauteur des attentes opérationnelles.
Le Data Scientist peut avoir aussi ce réflexe un peu étrange de dire « On va essayer, on va faire avec ce qu’on a et on verra ! » comme s’il croyait lui-même que son métier relève de l’incantation.
Evidemment, je ne fais là aucune généralité. Le rôle d’expert nous oblige à prendre nos responsabilités, et à dire « Non, après examen et quelques tests, je ne suis pas confiant du tout pour répondre à votre besoin avec les données qu’on a aujourd’hui ». Humilité, responsabilité et transparence, à chaque itération avec le métier, sont de mise.
On trouve souvent ce risque de dérive dans la relation Expert vs Métier. Ne tombons pas dans le piège de jouer sur l’ignorance de l’autre pour se créer un travail inutile !
Ces quelques principes sont peut-être évidents pour certains, utiles pour d’autres ! En tous les cas, chez Rhapsodies Conseil, au sein de notre équipe Transformation Data, nous essayons d’appliquer cela systématiquement, et nous pensons que c’est le minimum vital.
Pour éviter de faire perdre du temps à nos clients (et de l’argent), nous commençons nos missions BI & Analytics, systématiquement avec une « micro mission » préliminaire qui nous permet de valider la réelle valeur & la faisabilité de l’innovation recherchée (avec toutes les parties prenantes, en faisant des analyses flash des données…) avant d’aller plus loin !
Nous considérons que dans tout projet de Data Science, le prototype métier, tel que décrit dans l’article, est obligatoire. Nous proposons systématiquement un prototypage métier, toujours dans le soucis de bien projeter la valeur attendue pour le métier !
Nous allons plus loin sur la solution que l’analyse avancée des données. Notre expertise globale sur la transformation data, nous permet y compris sur des missions BI & Analytics, de ne pas hésiter à relever si pertinents des axes clés d’amélioration sur la gouvernance de certaines données, l’organisation, la data quality, la stratégie data long terme de l’organisation ou la culture data de l’entreprise, qui pourraient être profitables ou indispensables à l’usage traité.
Pour nous, traiter un usage BI & Analytics, c’est le traiter dans son ensemble, de manière systémique ! Notre solution finale n’est pas un modèle statistique. Notre solution finale est potentiellement un modèle statistique, mais aussi une gouvernance adaptée pour avoir la qualité de données nécessaire, un modèle qui s’adapte à l’expérience utilisateur souhaitée (et pas l’inverse), et un suivi du ROI de l’usage analytique et de sa pertinence par rapport à la stratégie de l’entreprise.
Les entreprises de tout secteur industriel cherchent à maîtriser et améliorer les processus de gestion des données de leurs produits. Ce sujet comporte de nombreux défis car les produits n’arrêtent pas d’évoluer pour satisfaire les besoins des clients d’une part et pour être conformes aux exigences réglementaires et normatives d’autre part.
Si l’on veut exploiter les données de ses produits, il s’agit là d’une difficulté supplémentaire qui ne peut être surmontée à l’aide d’un simple référentiel de données générique (un outil de Master Data Management par exemple).
Mais avant d’en arriver là, tachons déjà de définir ce qu’est un référentiel Produit et de faire un tour d’horizon des solutions existantes sur le marché. Nous verrons ensuite ce qui fait la différence dans un référentiel produit.
Référentiel de données produit
Qu’est-ce qu’un référentiel produit ?
Le référentiel Produit constitue la base de données centrale dans laquelle est intégrée, stockée et liée toute l’information liée aux produits vendus par l’entreprise. Il est nourri à chaque étape du cycle de vie du produit par les différentes équipes qui travaillent dessus et permet de diffuser simplement une information qui a été qualifiée, unifiée et normée. Chaque intervenant peut ainsi travailler sur une base commune d’informations Produit fiable et complète.
Prenons l’exemple d’une enseigne de bricolage, elle propose à ses clients un catalogue de produits variés avec une grande différence entre eux (Boulon, Vis, Marteau, Clé à molette, Perceuse sans fil ou avec fil, Compresseur d’air, etc.). Dans son référentiel, chaque produit a sa propre nomenclature de composants qui peut être basique pour des produits comme les marteaux ou les clés à molette ou complexe comme dans le cas d’un compresseur d’air ou d’une perceuse et chaque composant de la nomenclature a ses propres caractéristiques. Grâce à son référentiel Produit, l’entreprise peut aussi gérer les multiples variantes associées à une perceuse par exemple (Perceuse rouge sans fil, Perceuse noire avec fil 2m, Perceuse jaune avec fil 4m, etc.). L’enseigne peut ainsi gérer les informations liées aux différentes étapes du cycle de vie de ses produits depuis leur conception jusqu’à leur retrait du marché.
L’importance d’un référentiel produit
Lorsqu’une entreprise possède un portefeuille produits étendu et/ou en constante évolution, la quantité de données liées aux produits ne cesse d’augmenter elle aussi. Il devient essentiel de les centraliser, les normer et finalement de les gérer plus simplement pour gagner en efficacité et en fiabilité.
Le référentiel Produit permet de réaliser cet objectif en concentrant dans un outil flexible et transversal toutes les données associées. Il permet de les unifier afin d’assurer leur cohérence et de les lier entre elles pour créer un maillage produit pertinent pour l’utilisateur et un produit fini de qualité et à temps pour le client final.
Exemple et types de référentiels produit
PIM : Abréviation anglaise de Product Information Management. Il permet de centraliser, d’organiser et de gérer les données produit. Le PIM est une sorte de catalogue des produits de l’entreprise et il est très orienté pour des utilisations marketing. En effet, il centralise les données destinées à être diffusées aux prospects / clients telles que les données marketing, les données commerciales, les données techniques.
PLM : Abréviation anglaise de Product Lifecycle Management. Il permet, comme son nom l’indique, de gérer le cycle de vie du produit depuis sa conception, jusqu’à sa fin de vie (fabrication, gestion des stocks, logistique et transport, vente, éventuellement recyclage). Il centralise ainsi toutes les données liées au produit, et permet ainsi de gérer d’une manière plus transversale les données du produit.
Qu’est-ce qui différencie un référentiel produit d’un référentiel générique de données ?
Avec la capacité croissante d’enregistrement des données industrielles, plein de nouveaux concepts caractérisant la gestion des données produit ont vu le jour chez les entreprises. Contrairement aux référentiels génériques, les référentiels Produit ont été conçus pour maîtriser ces concepts et répondre aux enjeux des entreprises en proposant des fonctionnalités et des outils, spécialement, dédiés à la gestion des données Produit.
1. La gestion des cycles de vie des produits :
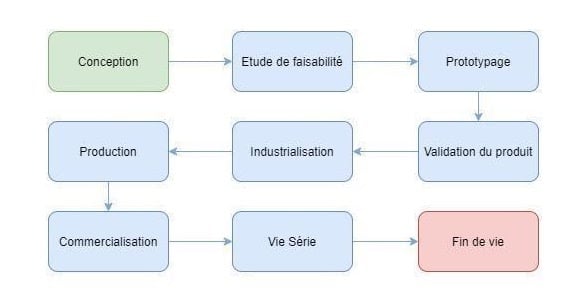
Les cycles de vie diffèrent d’un produit à un autre. Chacun possède un cycle de vie qui caractérise son développement, sa production, sa commercialisation et sa fin de vie (Exemple ci-dessous)
Dans un référentiel de données Produit la notion de cycle de vie pour un produit fini est liée à la notion de la chaîne de valeur industrielle. Cette dernière permet de supporter les différentes phases de vie d’un produit depuis l’idéation jusqu’à son recyclage ou son retrait du marché.
Le référentiel Produit permet de gérer ces phases sous mode projet avec des jalons et des livrables précis associés à chaque phase.
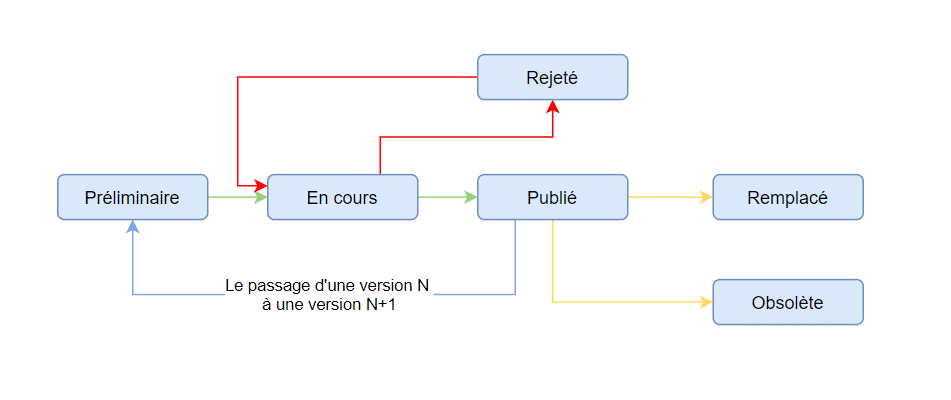
Quant aux composants de la nomenclature du produit final, ils ont un cycle de vie qui leurs est associé et qui, à l’aide des boucles ou workflows de validation, permet le passage d’une version N à une version N-1 en cas de modifications appliquées à quelques éléments de la nomenclature comme le montre l’illustration basique ci-dessous. Il faut savoir que les cycles de vie des composants peuvent avoir plus de complexité en fonction du secteur d’activités de l’entreprise (Défense, Aérospatial, etc.) ou de l’utilisation finale du produit (Nucléaire, Sous-marin, etc.)
Exemple de cycle de vie d’un composant de nomenclature :
Exemple de cycle de vie d’un produit :
2. La favorisation du co-développement interne et externe :
Le co-développement interne est la collaboration entre les acteurs métiers impliqués dans le développement d’un nouveau produit.
Le co-développement externe est la collaboration d’une entreprise avec ses clients et fournisseurs pour développer de nouveaux produits et services. C’est un vecteur d’innovation et de performance dans un modèle gagnant pour les trois acteurs.
Un référentiel Produit permet de supporter le co-développement interne en mettant à disposition des outils de collaboration entre tous les métiers autour de la nomenclature du produit avec une vue dédiée pour chaque métier. Par exemple, le bureau d’étude veut voir le matériau, les dimensions et les contraintes mécaniques liés au produit alors que les bureaux des achats et des ventes veulent voir les coûts de production, de montage et de maintenance, etc. Le référentiel Produit permet d’avoir une appropriation du contenu et du discours de chaque produit et la création d’un vocabulaire commun. Les entreprises peuvent ainsi avoir des propositions de valeur concrètes répondant aux besoins évolutifs des clients.
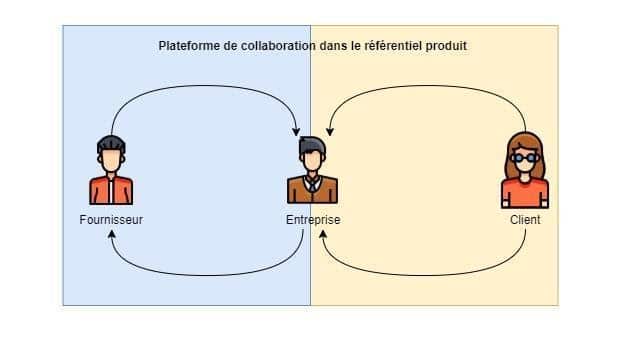
Le référentiel Produit permet aussi de favoriser le co-développement externe entre une entreprise, ses clients et ses sous-traitants en donnant la possibilité de partager en toute sécurité les informations qu’elle souhaite avec ces acteurs via une plateforme dédiée. Cela permet d’avoir un gain considérable dans le temps de mise sur le marché des produits car la plateforme permet aux entreprises d’avoir des boucles d’itérations et d’échange avec ses clients et ses fournisseurs lors de la phase du développement du produit et non pas à sa fin comme le montre l’illustration ci-dessous.
Grâce au co-développement les entreprises peuvent minimiser le temps de mise sur le marché des produits et donc réduire leur coût de développement.
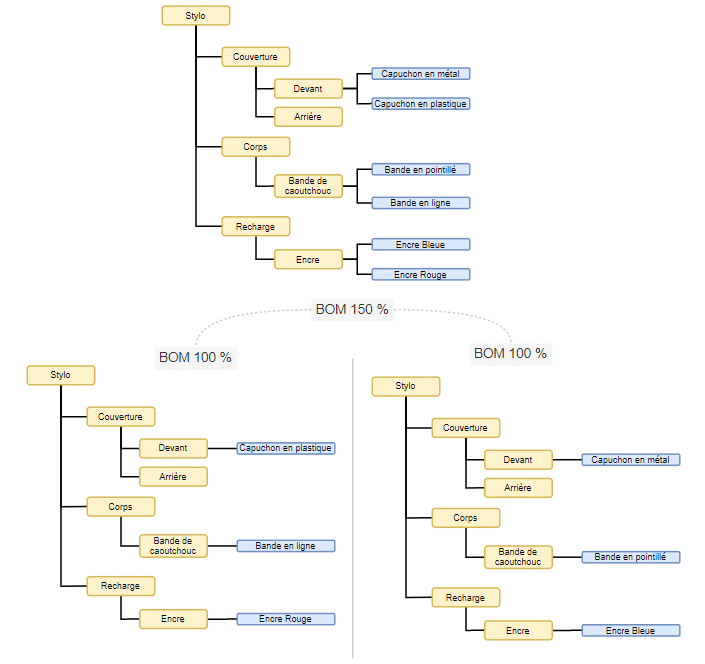
3. La gestion des options/variantes et des bom 150% (bill of materials)
La BOM 150 % ou la nomenclature à 150 % n’est qu’un autre nom pour une structure à variantes, ou plus précisément, une nomenclature configurable. Les nomenclatures configurables comportent un ou plusieurs composants optionnels et/ou sous-ensembles modulaires qui, lorsqu’ils sont correctement configurés, définissent une variation spécifique d’un produit. En fait, une nomenclature configurable est constituée de plusieurs nomenclatures possibles chargées dans une seule structure de produit. Lorsqu’elle n’est pas configurée, la nomenclature contient plus de pièces et de sous-ensembles que nécessaire, c’est-à-dire plus de 100 %. D’où l’expression « nomenclature à 150 % ». Cette approche est un moyen pour les ingénieurs de gérer la complexité de la structure et de la variation des produits.
La différence entre les options et les variantes dans un produit est que l’option est un système qui s’ajoute sans impact sur l’architecture du produit et les autres variantes et options choisies (Exemple : Climatisation dans une voiture) alors qu’une variante est un choix obligatoire et exclusif parmi des sous-ensembles et peut impacter l’architecture produit et même la structure de gamme d’assemblage (Exemple : Voiture 3 portes ou 5 portes)
Le référentiel Produit a la capacité de supporter toute la complexité liée à la gestion des BOMs 150 % en gérant non seulement les nomenclatures configurables associées à chaque produit mais aussi les règles de compatibilité entre toutes les options et les variantes possibles.
La gestion des nomenclatures configurables dans les référentiels Produit permet aux entreprises la possibilité de réutiliser les données de définition d’un produit et éviter d’avoir des doublons avec plusieurs numéros d’article pour un même composant.
L’illustration ci-dessous montre un exemple de déclinaison d’une BOM 150 % d’un stylo en deux nomenclatures du même produit mais avec des options et des variantes différentes.
4. Le support des différents types de processus de vente et de production
L’un des atouts majeurs d’un référentiel Produit est le fait qu’il puisse gérer la définition du produit pour les différents processus de vente et de production. Ces derniers varient entre les entreprises et peuvent même coexister pour différents produits au sein de la même entreprise, ce qui ajoute une couche de complexité à la gestion des données de ces produits.
Il existe divers processus de vente et de production dans le marché, on peut en citer :
Make To Stock : Lorsqu’un produit peut être vendu à partir d’un catalogue et qu’il est défini et spécifié par une fiche. La fabrication du produit peut être planifiée en se basant sur les prévisions.
Make To Order : Cette stratégie s’applique toujours aux produits standard dont les spécifications sont clairement définies. Pour ce type de produit, il n’est pas possible d’établir des prévisions et les produits sont fabriqués sur commande.
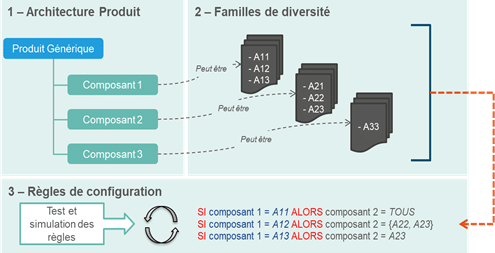
Configure To Order : C’est le processus le plus complexe du marché car le produit standard comporte un grand nombre de variantes. Il n’est donc pas possible de créer un numéro de produit pour chaque nomenclature à cause des nombreuses combinaisons possibles. Comme le montre l’illustration ci-dessous, la gestion des produits de ce type nécessite 3 briques essentielles que le référentiel Produit comporte :
Architecture produit : C’est le squelette générique du produit.
Familles de diversité : à chaque élément de l’architecture est attachée une famille de diversité donnant le champ des choix possibles pour chaque composant.
Règles de configuration : Les règles de configuration sont un mélange de règles de compatibilité entre les éléments des familles de diversité et de règles de productions qui permettent de configurer une produit fini réalisable par l’entreprise. Elles doivent être définies dans le référentiel et elles sont exécutées lors de la configuration du produit final.
Engineer To Order : C’est une approche de la production caractérisée par plusieurs activités d’ingénierie et soumis à un délai de livraison défini à la réception d’une commande du client accompagné d’un cahier de charge. (Exemple : Fabrication de câble pour un projet de construction d’un pont)
Avoir un outil capable de couvrir les différents processus, comme le référentiel Produit, permet aux entreprises d’optimiser et de centraliser la gestion des données de chaque produit. Par exemple, pour le processus CTO, le référentiel Produit aide les entreprises à éviter les retards de fabrication et les rejets des commandes en empêchant une mauvaise configuration du produit grâce aux règles de compatibilité entre les différents éléments. Chaque produit configuré dans un référentiel Produit est donc réalisable par l’entreprise.
5. La gestion de la conformité par rapport aux exigences
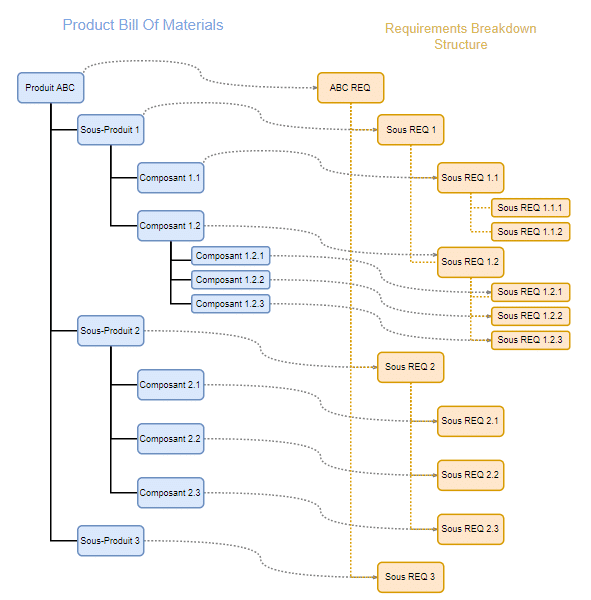
Les référentiels Produit permettent d’améliorer et d’optimiser la gestion de la conformité par rapport aux exigences. Il est possible de stocker, classifier et ordonner les métadonnées liées aux exigences (Client, Réglementaires, etc.) et cela permettra d’avoir une arborescence d’exigences (Requirements Breakdown Structure) qui est en lien direct avec la nomenclature du produit (BOM) comme le montre la figure ci-dessous. Chaque composant ou sous-ensemble est alors attaché aux exigences auxquelles il doit répondre et sa conformité est vérifiée en temps réel.
Cette méthode permet aux ingénieurs d’avoir une couverture totale des sous-ensembles et des exigences qui leurs sont associées. Le développement du produit devient ainsi plus efficace et sa commercialisation sera plus rapide.
6. La gestion des processus de modifications
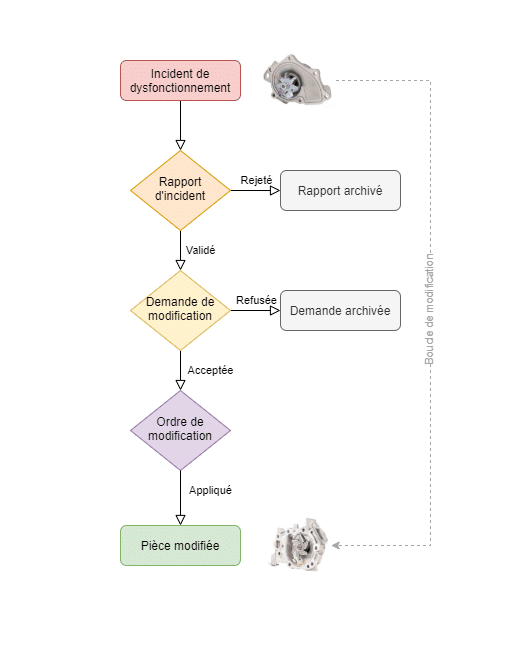
Dans les référentiels Produit, les boucles de modification sont constituées d’une séquence d’événements comme le montre le logigramme ci-dessous. Les étapes principales de cette boucle sont :
Rapport d’incident ou Problem Report (PR) : c’est un signalement de problème ou une source potentielle de panne dans le produit. Le PR peut déboucher sur une demande d’évolution technique (modification) du produit ou d’un processus.
Demande de modification ou Engineering Change Request (ECR) : Un problème, si retenu, peut donner lieu à une ou plusieurs demandes de changement. Cette étape consiste à consolider les analyses sur les objets potentiellement concernés et impactés.
Ordre de modification ou Engineering Change Order (ECO) : Si l’ECR est accepté, on passe à un ordre de changement pour valider la liste complète des objets impactés devant être modifiés.
Grâce aux référentiels Produit, les processus de modification sont automatisés en suivant une logique d’étapes qui garantit une efficacité et une rapidité dans la réalisation des changements sur un produit donné. L’outil permet de gérer les passages de versions majeures et mineures sur chaque composant de la nomenclature et peut même produire une matrice d’impact sur le reste de la structure du produit et proposer d’appliquer des modifications sur d’autres composants.
Conclusion
Depuis son arrivée, le Digital a eu un impact de plus en plus important sur le monde de la Data avec un besoin croissant de garantir la consistance des données sur l’ensemble des canaux. Grâce à lui, le rythme ne cesse pas d’accélérer et il demande encore plus de rigueur dans la gestion des données Produit. Cette dernière, en plus de sa particularité, est devenue plus challengeante pour les entreprises avec des clients de plus en plus exigeants, des contraintes réglementaires en évolution continue et dans un marché de plus en plus compétitif.
Contrairement aux référentiels génériques de données, les référentiels de données Produit permettent aux entreprises de surmonter ces défis en leurs offrant un panel étendu de fonctionnalités et en introduisant plusieurs concepts pour les aider à améliorer les processus de gestion des données produit et à maîtriser les étapes du cycle de vie.
Si vous avez des questions sur les référentiels produits ou souhaitez être accompagnés sur le sujet ? Contactez transfodata@rhapsodiesconseil.fr
Découvrez-en davantage concernant l’expertise de Zied : Transformation Data.