Pour les entreprises qui sont confrontées à un virage vers le data driven, le fait de sous-estimer le besoin de changement organisationnel est souvent un problème plus important que les questions de technologie. Une entreprise peut disposer d’outils puissants et de données significatives, mais sans l’accompagnement et les processus appropriés pour mettre ces données entre les mains des bonnes personnes, l’extraction de la valeur peut s’avérer difficile.
Mettre en place une culture de l’apprentissage continu au sein de l’entreprise est un vrai levier de performance pour votre organisation et d’épanouissement de vos salariés.
Prenons l’exemple d’un programme de libre accès aux données:
Lorsque les données sont fondamentales pour la gestion de votre organisation, des analyses doivent être effectuées très rapidement au sein de toute votre organisation car elles sont essentielles à votre business.
L’idée des données en libre-service est la suivante : plutôt que d’engager un nombre infini de talents hautement qualifiés en data, pourquoi ne pas employer votre capital intellectuel et votre capital humain existant au sein votre organisation et leur donner les moyens de faire leur propre travail d’analyse des données ? Dans un système en libre-service, les différents métiers de votre organisation et les analystes peuvent accéder et travailler directement avec les données et leur visualisation. Ils sont aidés par des experts data, mais sans en dépendre, pour effectuer leur travail. C’est l’essor des “citizen data scientist”.
Ce type de programme permet aux entreprises de supprimer les frontières techniques et donne aux collaborateurs la possibilité d’utiliser leur propre expertise en la matière – après tout, ils connaissent mieux les problèmes auxquels ils s’attaquent, et ils savent de quelles données ils ont besoin – pour générer des idées et exécuter leur travail.
Qu’est-ce que cela signifie pour la gouvernance des données ?
Les données en libre-service et la gouvernance vont certainement de pair. Il y a un équilibre délicat à trouver dès le départ. Vous devez protéger les utilisateurs et l’entreprise, vous assurer que vous êtes en conformité et que vous respectez les règlements, et permettre une meilleure compréhension des données. Mais en même temps, vous ne voulez pas être un obstacle tel que les gens ne puissent pas faire leur travail.
Le catalogage des données, la traçabilité des données et la mise en place d’un cadre d’utilisation (rôles, responsabilités, process, etc.) autour des données sont des éléments clefs de la gouvernance, car les collaborateurs doivent disposer des bonnes informations et du bon contexte concernant les données qu’ils consultent pour réussir.
Construisez la culture data d’apprentissage et prévoyez un temps de réflexion
Ce paragraphe ne concerne pas uniquement vos enjeux data, mais peut répondre à la question plus globale de l’organisation apprenante.
Établissez les bonnes bases culturelles en plaçant l’apprentissage au centre de votre organisation. Une organisation apprenante ne peut voir le jour que dans le cadre d’une culture d’intégration, de confiance, de collaboration et de leadership engagés sur le lieu de travail. Le changement cela ne se décrète pas. Donnez à votre équipe l’espace et le temps de réfléchir, de prendre du recul et de travailler sur leurs idées. Créez une culture de travail personnalisée et adaptée, qui accueille la dissidence, récompense la créativité et sollicite des avis extérieurs pour améliorer la prise de décision globale.
In fine ces bonnes pratiques d’acculturation data en interne et de gouvernance des données vous aideront à répondre à une solution simple à fort potentiel : au lieu de trouver un objectif pour les données, trouvez des données pour un objectif. Cela vous permet de piloter vos données comme des actifs précieux au service des besoins métiers à valeur !
Depuis quelque temps, la question de la conformité interne prend une place indéniable dans les entreprises. En effet, même si le RGPD est un règlement datant de 2018, l’attention a été portée aux données clients, aux besoins des équipes marketing, data ou digital et fournisseurs, délaissant de fait les données RH des organisations.
Une conformité RGPD permet cependant d’améliorer l’image employeur de son entreprise (pour les employés mais aussi pour les candidats) au travers du respect de la confidentialité et de la gestion des risques sur la vie privée, par une politique de protection des données.
De plus, c’est un moyen d’améliorer la gestion des employés et de mettre à la disposition du DRH, des informations à jour, complètes et centralisées qui permettront d’améliorer la prise de décision et de planification des ressources humaines.
Enfin, c’est aussi un moyen d’éviter à l’entreprise des sanctions financières et des poursuites en cas de violation des données des employés, sans compter les conséquences sur la réputation de l’entreprise.
Cet article a pour but de donner quelques conseils aux équipes RH et aux consultants. J’ai procédé à un exercice de collecte d’informations qui, je l’espère, vous sera utile pour vous guider dans votre mise en conformité.
Cependant, je n’aborderai pas tous les sujets nécessaires pour se mettre complètement en conformité, mais uniquement les points récurrents qui me sont souvent demandés.
Les 3 points à respecter pour que votre RH soit conforme à la RGPD
La base légale des traitements des données
Chaque traitement de données personnelles doit respecter une base légale.
Bases légales envisageables (sous réserve de choix différents justifiés par un contexte spécifique)
Recrutement
Traitement des candidatures (CV et lettre de motivation) et gestion des entretiens
Mesures précontractuelles
Constitution d’une CV-thèque
Intérêt légitime
Gestion administrative du personnel
Gestion du dossier professionnel des employés, tenu conformément aux dispositions législatives et réglementaires, ainsi qu’aux dispositions statutaires, conventionnelles ou contractuelles qui régissent les intéressés.
Exécution du contrat
Réalisation d’états statistiques ou de listes d’employés pour répondre à des besoins de gestion administrative.
Intérêt légitime
Gestion des annuaires internes et des organigrammes.
Intérêt légitime
Gestion des dotations individuelles en fournitures, équipements, véhicules et cartes de paiement.
Intérêt légitime
Gestion des élections professionnelles.
Obligation légale
Organisation des réunions des instances représentatives du personnel.
Obligation légale
Gestion des rémunérations et accomplissement des formalités administratives
Etablissement des rémunérations, mise à disposition des bulletins de salaire
Exécution du contrat
Déclaration sociale nominative.
Obligation légale
Mise à disposition des personnels d’outils informatiques
Suivi et maintenance du parc informatique.
Intérêt légitime
Gestion des annuaires informatiques permettant de définir les autorisations d’accès aux applications et aux réseaux.
Intérêt légitime
Mise en œuvre de dispositifs destinés à assurer la sécurité et le bon fonctionnement des applications informatiques et des réseaux.
Intérêt légitime
Gestion de la messagerie électronique professionnelle.
Intérêt légitime
Réseaux privés virtuels internes à l’organisme permettant la diffusion ou la collecte de données de gestion administrative des personnels (intranet).
Intérêt légitime
Organisation du travail
Gestion des agendas et projets professionnels.
Intérêt légitime
Suivi des carrières et de la mobilité
Évaluation professionnelle des personnels, dans le respect des dispositions législatives, réglementaires ou conventionnelles qui la régissent.
Intérêt légitime
Gestion des compétences professionnelles internes.
Intérêt légitime
Gestion prévisionnelle de l’emploi et des compétences (GPEC)
Intérêt légitime
Gestion de la mobilité professionnelle.
Exécution du contrat
Formation
Gestion des demandes de formation et des périodes de formation effectuées.
Exécution du contrat
Organisation des sessions de formation et évaluation des connaissances et des formations.
Intérêt légitime
Gestion des aides sociales
Gestion de l’action sociale et culturelle directement mise en œuvre par l’employeur, à l’exclusion des activités de médecine du travail, de service social ou de soutien psychologique.
Intérêt légitime
La durée de conservation des données RH
Les données personnelles ne pouvant pas être conservées à vie, il est nécessaire de mettre en place des purges automatisées ou non (selon la taille de vos espaces de stockage, il est parfois indispensable de passer par une purge automatisée).
Les durées de conservations sont généralement à définir par le métier, selon son besoin (la personne utilisant la donnée ou la collectant) ; dans votre cas : le DRH ou le responsable administratif en collaboration avec votre DPO ou le référent RGPD de votre organisation. Cependant, certains documents doivent respecter des durées légales de conservation déjà prévues par le droit.
Le tableau ci-dessous vous permet d’avoir une liste (non exhaustive) des documents les plus souvent demandés/collectés en interne :
Activités de traitement
Détails du traitement
Base active
Archivage intermédiaire
Textes de référence
Gestion de la paie
Bulletin de salaire
1 mois
5 ans
L. 3243-4 du code du travail
Bulletin de salaire
1 mois
50 ans (en version dématérialisée)
D. 3243-8 du code du travail
Eléments nécessaires au calcul de l’assiette
1 mois
6 ans
L. 243-16 du code sécurité sociale
Saisie des données calculées (DSN)
Le temps nécessaire à l’accomplissement de la déclaration
6 ans
L. 243-16 du code sécurité sociale
Ordre de virement pour paiement
Le temps nécessaire à l’émission du bulletin de paie
10 ans à compter de la clôture de l’exercice comptable
L. 123-22 du code du commerce
Registre unique du personnel
Ordre de virement pour paiement
La durée pendant laquelle le salarié fait partie des effectifs
5 ans à compter du départ du salarié de l’organisme
R. 1221-26 du code du travail
Gestion des mandats des représentants du personnel
Nature du mandat et syndicat d’appartenance
6 mois après la fin du mandat
6 ans (prescription pénale pour délit)
L. 2411-5 du code du travail
Les données relatives aux sujétions particulières ouvrant droit à congés spéciaux ou à crédit d’heures de délégation (ex: exercice d’un mandat électif ou représentatif syndical)
Le temps de la période de sujétion de l’employé concerné
6 ans (prescription pénale pour délit)
L. 2142-1-3 du code du travail
La gestion des droits des personnes (candidats et employés)
La gestion des droits des personnes est une obligation sur toutes les données personnelles, il faut donc prendre en compte le processus de réponse à ces demandes. Les droits sont : le droit d’accès (avoir une copie des données personnelles), le droit de suppression (demander la suppression de tout ou partie de ses données personnelles), le droit de modification (demander la modification de ses données personnelles en cas d’erreur), le droit de portabilité (demander une copie sous format lisible par une machine (ex. : csv) de ses données personnelles), le droit de limitation (demander la non utilisation de ses données personnelles pour un traitement spécifique).
Des règles simples sont à respecter :
La réponse à une demande doit se faire au maximum 30 jours après la réception de celle-ci. Il peut y avoir une exception si la demande est complexe (si on vous demande une copie de la totalité des données personnelles que vous avez en votre possession), dans ce cas le délai monte à 3 mois, mais il faudra prévenir la personne que la durée est augmentée de 23 mois, un mois maximum à partir de la réception de la demande.
La confirmation de l’identité du demandeur est nécessaire afin d’éviter d’envoyer/modifier/supprimer les données d’une une tierce personne. Si ça arrive, il s’agit alors d’une fuite de donnée qui doit être notifiée auprès de la CNIL. La confirmation est nécessaire seulement en cas de doute sur l’identité de la personne, elle n’est donc pas obligatoire. Enfin, une fois l’identité de la personne confirmée, la preuve doit être supprimée.
La réponse doit être sous le format de la demande, c’est-à-dire qu’une demande par courrier doit avoir une réponse par voie postale, et une demande par mail, par mail.
Il est possible de refuser une demande si celle-ci n’est pas fondée ou paraît excessive, ou encore si les données de la personne concernée ont été effacées. Ou enfin, s’il est demandé de supprimer des documents légaux ou devant être conservés obligatoirement (ex. : fiche de paie, contrat, …).
Mettre en place la conformité RGPD de vos Ressources Humaines
Pour bien commencer, il est important d’avoir une équipe dédiée à la conformité, en complément du DPO et du DRH qui sont indispensables. Cette équipe devra être formée et aura des rôles précis. Cette formation peut se faire directement par le MOOC de la CNIL, régulièrement mis à jour, qui est complet et qui donne de très bonnes bases (testé et approuvé par mon équipe).
En interne, il est indispensable de pouvoir sensibiliser les collaborateurs sur leurs droits (droits des personnes, bases légales, limitations, …), mais aussi leurs devoirs vis-à-vis des données personnelles qu’ils traitent (sécurité des postes de travail, sécurité des documents, politique de mot de passe, …).
Enfin et afin de pouvoir être totalement conforme, il est nécessaire de créer un registre de traitement, de faire une revue des process de gestion des droits des personnes, d’analyser les applications internes, les contrats de sous-traitance et les mesures de sécurité de la DSI. Il est également nécessaire de s’assurer du bon fonctionnement des purges et archivages ou encore de mettre en place des analyses d’impacts sur la vie privée et des audits.
Les entreprises, dans la mise en place de leur stratégie Data Driven, s’appliquent à rendre la donnée accessible à tous leurs acteurs métiers. Parmi les solutions d’exposition des données, on trouve majoritairement des outils de data visualisation ou « dataviz ». Ces outils sont choisis pour leur facilité d’interaction avec les différentes sources de données de l’entreprise, et également pour leurs fonctionnalités de présentation des données et d’indicateurs sous forme de graphique, carte, etc. Les cas d’usage de ces solutions sont multiples :
Suivre le développement d’un produit,
Étudier l’impact d’une campagne marketing,
Piloter l’activité,
Produire des rapports réglementaires (index égalité F/H, bilan social, etc.),
Prévoir une situation future,
Suivre la qualité des données.
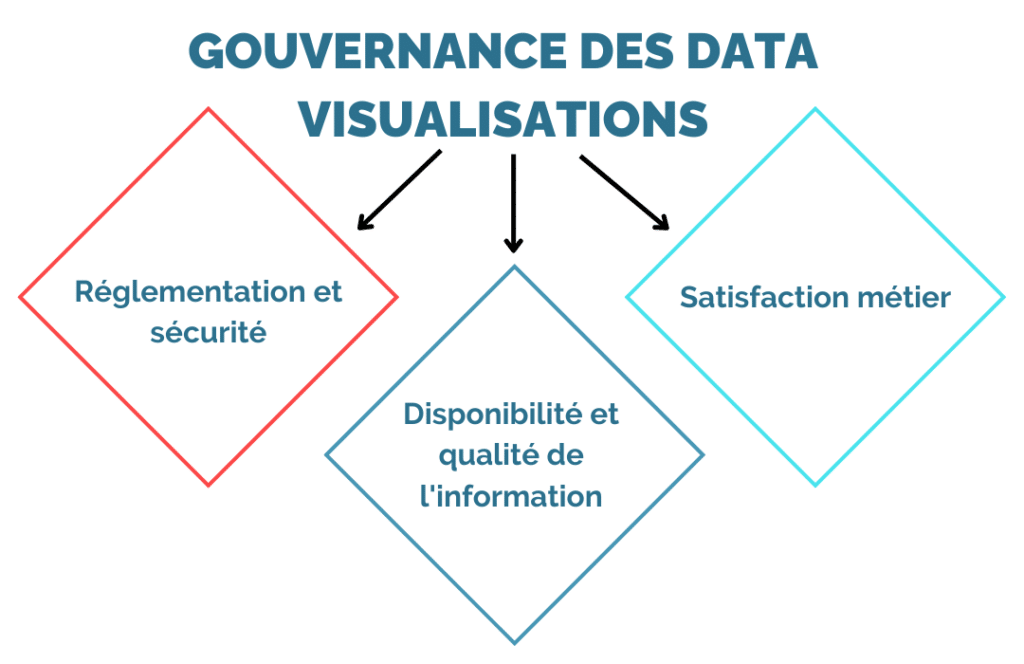
Réglementation et sécurité de la Data Visualisation
De plus en plus de liberté et d’autonomie sont laissées au métier aujourd’hui pour construire et publier leurs data visualisations. Ce gain d’autonomie ne doit pas aller à l’encontre des principes de base sur la sécurité des données. La sécurité et la compliance doivent rester sous contrôle. Pour cela, les usages de données sont à répertorier dans un “portefeuille d’usage”, ce qui va assurer leur documentation et faciliter leur partage au sein de l’entreprise. Pour ceux utilisant des données à caractère personnel, les référencer permettra d’assurer le respect de la réglementation RGPD.
Lors de la documentation des usages, la liste des utilisateurs est définie. La politique de gestion des habilitations est ensuite utilisée pour rapprocher chaque utilisateur à un rôle lié au type de persona défini. Cette gestion des habilitations restreint les risques de diffusion des données sensibles et/ou stratégiques de l’entreprise auprès d’acteurs ne devant pas y avoir accès. Centraliser cette politique d’accès améliore le suivi et l’évolution des habilitations, à la suite de réorganisations par exemple. Cette politique doit être menée de front par les équipes DSI en responsabilité des outils de data visualisation, les équipes d’audit interne ainsi que risque et conformité.
Disponibilité et qualité de l’information de la Data Visualisation
La multiplication des data visualisations a tendance également à augmenter le nombre d’indicateurs (parfois dupliquer), avec un manque de transparence sur la traçabilité et la qualité des données sous jacentes. L’utilisateur d’une data visualisation doit systématiquement pouvoir identifier le niveau de confiance qu’il peut avoir dans les chiffres qui lui sont fournis. Cet axe est donc majeur et on y distingue deux phases : la mise en production et le maintien en condition opérationnelle de la data visualisation.
Phase de mise en production de la donnée
Lors de la mise en production, l’inscription des sources de données dans le plan d’actualisation assure la fraicheur des données en correspondance avec le besoin métier. Avant la mise en place de plan d’actualisation, on observe parfois chez nos clients utilisant des bases de données dans le Cloud, des surcoûts non anticipés. Ils sont liés à des interactions trop nombreuses ou trop consommatrices den ressources.
Une non-gouvernance des plans d’actualisation peut également se traduire par un « plantage » du système s’il n’est pas prévu d’élargir les ressources disponibles. L’impact budgétaire dans le cas d’un environnement Cloud, est d’autant plus important que les data visualisations se multiplient et tendent à sur-solliciter les serveurs des data sources. Lister les data sources permet de répondre par la suite à des besoins de mutualisation des data préparations, pour notamment réduire les interactions serveurs, ou des besoins liés à des études d’impact en cas de correctif en amont dans le cycle de vie des données.
Maintien en condition opérationnelle de la donnée
Au quotidien, les rapports sont utilisés à des fin de reporting et d’aide à la prise de décision. Pour assurer la bonne qualité des données utilisées dans les data source, un suivi de la qualité peut être effectué dans un rapport annexe. Les indicateurs de qualité sont à construire selon différentes dimensions pour s’assurer de couvrir tout le spectre de la qualité des données.
Ce rapport n’a pas une visée à réaliser du data profiling, mais assure que les données sont en qualité pour répondre à l’usage. Des alertes sur des seuils par exemple, sont à paramétrer pour déclencher des actions de mise en qualité ainsi que pour alerter les utilisateurs dans un principe de transparence.
Une Data Visualisation qui satisfait les métiers
Donner de l’autonomie au métier dans la production de ces data visualisations ne va pas automatiquement leur permettre de répondre à leurs usages et ainsi provoquer leur satisfaction. Ce gain d’autonomie nécessite aussi un accompagnement plus important en termes de formation et de change management. De même, la multiplication des data visualisations peut voir la quantité l’emporter au dépend de la qualité et donc drastiquement réduire l’expérience utilisateur qui se retrouve perdue dans une multitude de visualisations de données. La satisfaction métier est donc évidemment un axe clé à maîtriser.
En effet si l’on résume les deux points précédents, on obtient, une data visualisation :
Conforme aux diverses réglementations,
Partagée et accessible à une liste d’utilisateurs pilotée,
Présentant des données de qualité,
Mutualisable pour d’autres usages (notamment la data préparation).
Ceci a pour bénéfice de maximiser la satisfaction des utilisateurs mais également des acteurs projets internes.
La satisfaction des métiers s’apprécie au regard de leur utilisation des data visualisations auxquelles ils peuvent accéder. La mise en place de rapport de suivi de l’utilisation des data visualisations est un outil qui est à utiliser pour effectuer des revues des rapports en production. Ces revues peuvent déclencher des actions pour réétudier le besoin métier. Ceci fait partie d’un axe important de la gouvernance qui s’assure que le produit répond à un besoin et est maintenu dans le temps.
Vous l’aurez compris par ces trois enjeux, gouverner les data visualisations passe par des actions simples, qui permettent d’assurer leur gouvernance. Celle-ci est importante et permettra d’assurer que ces rapports soient fiables, de confiance, et utilisés à bon escient pour tous les utilisateurs.
Pour en savoir plus, n’hésitez pas à contacter nos experts Transformation Data.
Après avoir été successivement décrit comme le job le plus sexy du 21ème siècle puis comme aisément remplaçable par la suite, le data scientist a de quoi souffrir aujourd’hui de sacrés questionnements. Son remplaçant le plus pertinent ? Les solutions d’Auto-Machine Learning, véritables scientifiques artificiels des données, capables de développer seuls des pipelines d’apprentissage automatique pour répondre à des problématiques métier données.
Mais une IA peut-elle prendre en charge la totalité du métier de data scientist ? Peut-elle saisir les nuances et spécificités fonctionnelles d’un métier, distinguer variables statistiquement intéressantes et fonctionnellement pertinentes ? Mais aussi, les considérations d’éthique des algorithmes peuvent-elles être laissées à la main … des mêmes algorithmes ?
Le Data Scientist, vraiment éphémère ?
Le data scientist est une figure centrale de la transformation numérique et data des entreprises. Il est l’un des maîtres d’œuvre de la data au sein de l’organisation. Ses tâches principales impliquent de comprendre, analyser, interpréter, modéliser et restituer les données, avec pour objectifs d’améliorer les performances et processus de l’entreprise ou encore d’aller expérimenter de nouveaux usages.
Toutes les études sur les métiers du numérique depuis 5 ans sont unanimes : le data scientist est l’un des métiers les plus en vogue du moment. Pourtant, il est plus récemment la cible de critiques.
Des observateurs notent une baisse de la « hype » autour de la fonction et une décroissance du ratio offre – demande, qui viendrait même pour certains à s’inverser. Trop de data scientists, pas assez de postes ni de missions.
Deux principales raisons à cela :
La multiplication de formations et bootcamps certifiants pour le poste, résultant en une inondation de profils juniors sur le marché ;
Une rationalisation des organisations autour de l’IA et une (parfois) limitation des cas d’usage – l’époque de l’armée de data scientists délivrant en série des POCs morts dans l’œuf est belle est bien révolue.
Mais également, et c’est cela qui va nous intéresser pour la suite, pour certains experts, le « data scientist » ne serait qu’un buzzword : l’apport de valeur de ce rôle et de ses missions serait surévalué, jusqu’à considérer le poste comme un effet de mode passager voué à disparaître des organisations.
En effet, les mêmes experts affirment qu’il sera facilement remplacé par des algorithmes dans les années à venir. D’ici là, les modèles en question deviendraient de plus en plus performants et seraient capable de réaliser la plupart des tâches incombées mieux que leurs homologues humains.
Mais ces systèmes si menaçants, qui sont-ils ?
L’Auto-ML, qu’est-ce que c’est ?
L’apprentissage automatique automatisé (Auto-ML) est le processus d’automatisation des différentes activités menées dans le cadre du développement d’un système d’intelligence artificielle, et notamment d’un modèle de Machine Learning.
Cette technologie permet d’automatiser la plupart des étapes du procédé de développement d’un modèle de Machine Learning :
Analyse exploratoire : préparation et nettoyage des données, détection de la typologie de problème à adresser ;
Ingénierie et sélection des variables : analyse purement statistique (et non fonctionnelle, c’est l’un des points faibles) des différentes variables, sélection des variables pertinentes, création de nouvelles variables (ces modèles peuvent-ils le faire… ?) ;
Sélection du ou des modèles à tester, entraînement, mise en place de méthodes ensemblistes de modèles, fine tuning des hyper-paramètres, analyse et reporting de la performance ;
Agencement de l’analyse : mise en place du pipeline sous contrainte (coût / durée d’entrainement, complexité du ou des modèles, …) ;
Industrialisation et cycle de vie : restitution à l’utilisateur des résultats sous la forme de graphes ou d’interface, branchement simplifié à un tableau de bord prêt à l’emploi, sauvegarde et versionning des différents modèles.
L’Auto-ML démocratise ainsi l’accès aux modèles d’IA et techniques d’apprentissage automatique. L’automatisation du processus de bout en bout offre l’opportunité de produire des solutions (ou à minima POC ou MVP) plus simplement et plus rapidement. Il est également possible d’obtenir en résultat des modèles pouvant surpasser les modèles conçus « à la main » en matière de performances pures.
En pratique, l’utilisateur fournit au système :
Un jeu de données pour lesquelles il souhaite mettre en place son usage d’intelligence artificielle – par exemple une base de données client et d’indicateurs calculés (chiffre d’affaires total, sur la dernière année, nombre de transactions, panier moyen, propension à abandonner son panier, …)
Une variable cible d’entraînement, qu’il souhaite prédire dans le cadre de l’usage en question – par exemple la probabilité de CHURN du client en question ;
Des contraintes vis-à-vis de la sélection du modèle : quelle typologie de modèle à utiliser / exclure, quelle(s) métrique(s) de performance considérer, quels seuils de performance accepter, quelle durée d’entraînement maximale tolérer, …
Le système va alors entraîner plusieurs modèles – ensemble de modèles et modéliser les résultats de cette tache sous la forme d’un « leaderboard », soit un podium des modèles les plus pertinents dans le cadre de l’usage donné et des contraintes listées par l’utilisateur.
Source : Microsoft Learn
Quelles sont les limites de l’Auto-ML ?
Pour autant, l’Auto-ML n’est pas de la magie et ne vient pas sans son lot de faiblesses.
Tout d’abord, les technologies d’Auto-ML rencontrent encore des difficultés à traiter des données brutes complexes et à optimiser le processus de construction de nouvelles variables. N’ayant qu’une perception statistique d’un jeu de données et (aujourd’hui) étant dénué d’intuition fonctionnelle, il est difficile de faire comprendre à ces modèles les finesses et particularités de tel ou tel métier. La sélection des variables significatives restant l’une des pierres angulaires du processus d’apprentissage du modèle, apparaît ainsi une limite à l’utilisation d’Auto-ML : l’intuition business humaine n’est ainsi pas (encore) remplaçable.
Également, du fait de leur complexité, les modèles développés par les technologies d’Auto-ML sont souvent opaques vis-à-vis de leur architecture et processus de décision (phénomène de boîte noire). Il peut être ainsi complexe de comprendre comment ils sont arrivés à un modèle particulier, malgré les efforts apportés à l’explicabilité par certaines solutions. Cela peut ainsi amoindrir la confiance dans les résultats affichés, limiter la reproductibilité et éloigner l’humain dans le processus de contrôle. Dans une dynamique actuelle de prise de conscience et de premiers travaux autour de l’IA éthique, durable et de confiance, l’utilisation de cette technologie pourrait être remise en question.
Enfin, cette technologie peut aussi être coûteuse à exécuter. Elle nécessite souvent beaucoup de ressources de calcul (entrainement d’une grande volumétrie de modèles en « one-shot », fine tuning multiple des hyperparamètres, choix fréquent de modèles complexes – deep learning, …) ce qui peut rendre son utilisation contraignante pour beaucoup d’organisations. Pour cette même raison, dans une optique de mise en place de bonnes pratiques de numérique durable et responsable, ces technologies seraient naturellement écartées au profit de méthodologies de modélisation et d’entrainement plus sobres (mais potentiellement moins performantes).
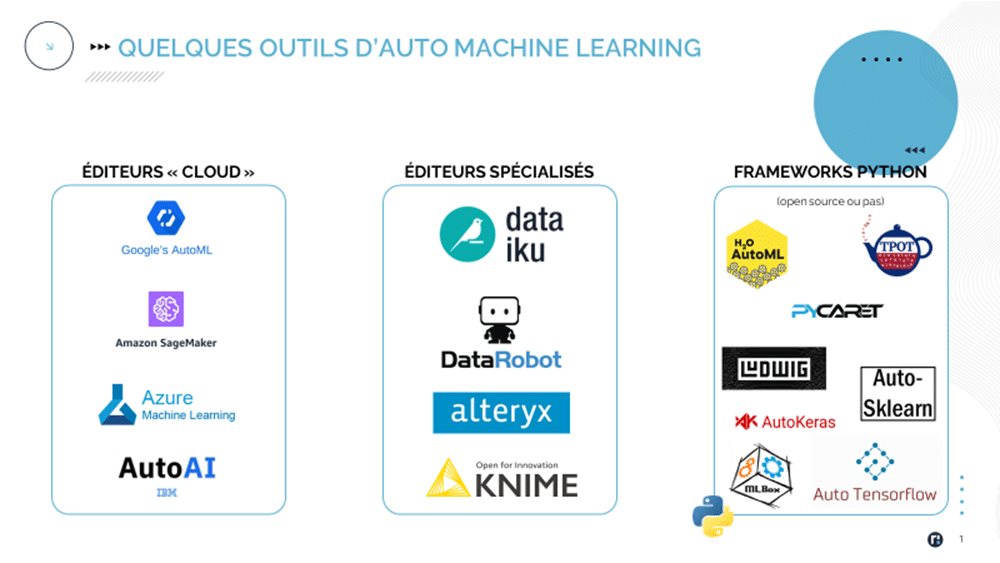
Quelles solutions d’Auto-ML sur le marché ?
On peut noter 3 typologies de solutions sur le marché :
Les solutions des éditeurs de cloud (GCP, AWS, …), pré-packagées dans les offres, permettant de profiter d’infrastructures d’entraînement performantes et de modèles pré-entraînés ;
Les éditeurs spécialisés dans les plateformes de data science, comme la licorne française Dataïku ou le pure-player ML DataRobot ;
Les librairies Python (et leur pendant R, parfois) open-source, certaines se branchant sur des frameworks bien connus de la profession (Auto Sklearn, AutoKeras, …)
H2o Auto-ML en pratique
Jetons un coup d’œil à H2o.ai, librairie Python open source d’Auto-ML développée par l’entreprise éponyme. Nous prendrons comme cas d’usage un problème de classification binaire classique sur des données tabulaires, issu du challenge mensuel Kaggle d’Août dernier.
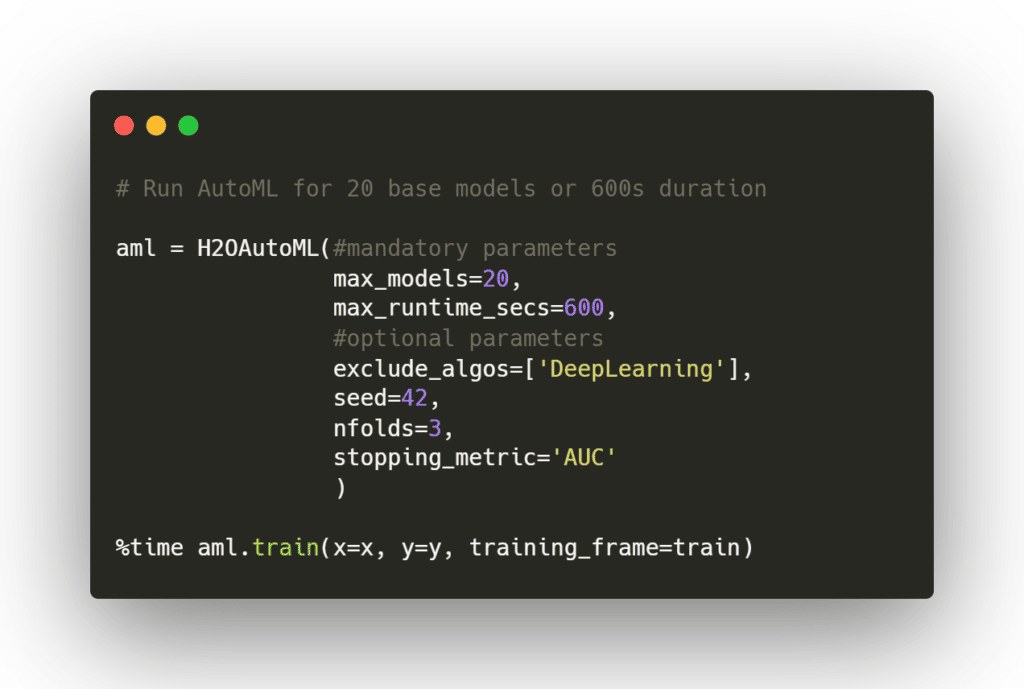
Après un chargement des données et une initialisation de l’instance locale, on va pouvoir lancer le moteur d’AutoML :
Doivent être spécifiés :
La volumétrie maximale de modèles à entraîner (permet d’ajuster les performances et de ne pas aller dans le « toujours plus ») ;
Une durée maximale de temps d’exécution, pratique en phase de prototypage du pipeline ;
Le H2o dataframe d’entraînement en indiquant les variables indépendantes (x) et la variable à prédire (y). A noter qu’il s’agit d’un format de dataframe spécifique mais que la conversion depuis et vers un dataframe pandas « traditionnel » se fait très simplement.
Il est également possible d’ajouter des paramètres tels que :
Les éventuelles typologies de modèles à exclure – ici on retire les modèles de deep learning mais peuvent également être exclus l’empilement (« stacking ») de modèles, les xgboost ou encore les algorithmes de « gradient boosting » ;
Une métrique d’arrêt (ex : logloss, AUC, …) qui permettra, une fois la valeur cible atteinte ou un nombre de rounds d’entrainement sans amélioration dépassé d’arrêter le processus de training ;
Tout un ensemble de paramètres pour gérer la validation croisée (nombre de folds, conservation des modèles non retenus et leurs prédictions, …) ;
Des fonctionnalités de ré-équilibrage des classes, afin d’adresser les problématiques de datasets déséquilibrés (par exemple, dans un problème de classification binaire, une répartition 90-10 sur la variable à prédire dans le jeu d’entraînement) ;
Il est important de noter que H2o AutoML ne propose aujourd’hui qu’une fonctionnalité limitée de préparation des données, se limitant à de l’encodage de variables catégorielles. Mais la société travaille aujourd’hui à enrichir ces fonctionnalités.
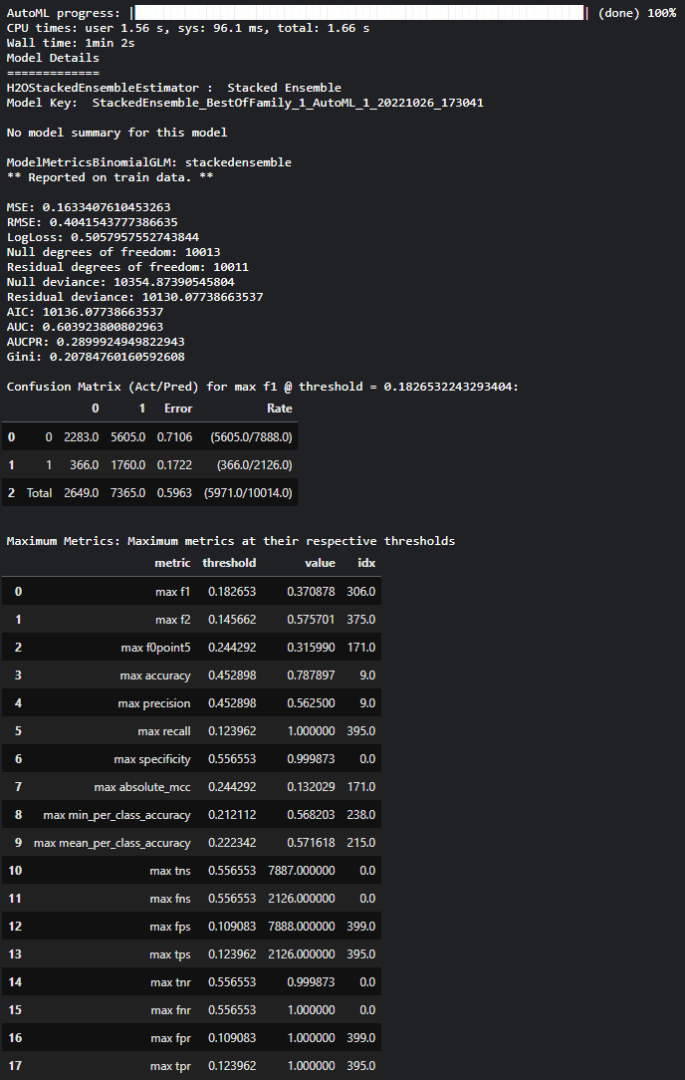
Une fois l’entraînement terminé, des informations sur le modèle vainqueur sont affichées :
Informations de base sur le modèle : nom, typologie, paramètres, … Dans notre cas, il s’agit d’un ensemble de plusieurs modèles et l’ensemble des paramètres n’est pas affiché (disponible via une commande supplémentaire)
Un listing des performances du modèle : matrice de confusion, métriques de classification (voir ci-dessous)
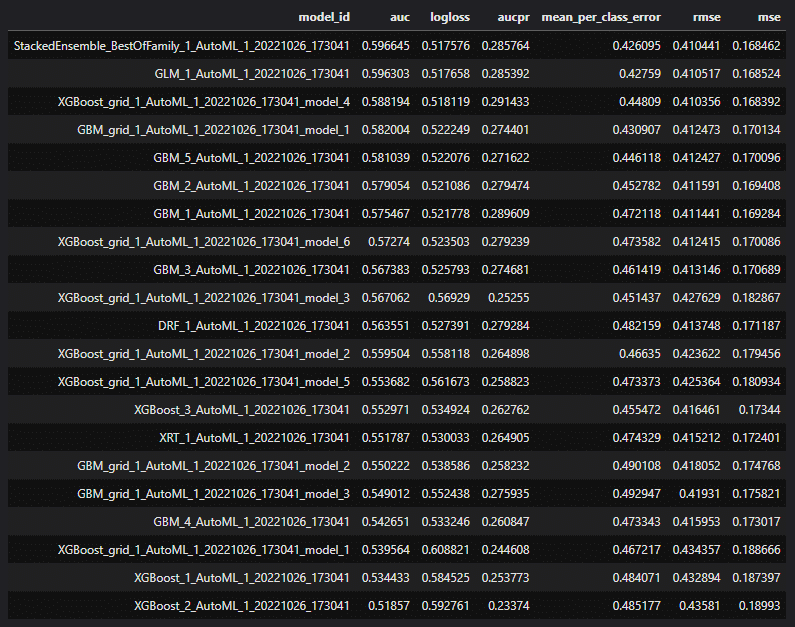
Il est également possible d’avoir accès au « leaderboard » des modèles entrainés et testés : identifiant, performances, temps d’entrainement et de prédiction, typologies des modèles (ensembles, gradient boosting, …) .
Informations modèle leader
Leaderboard
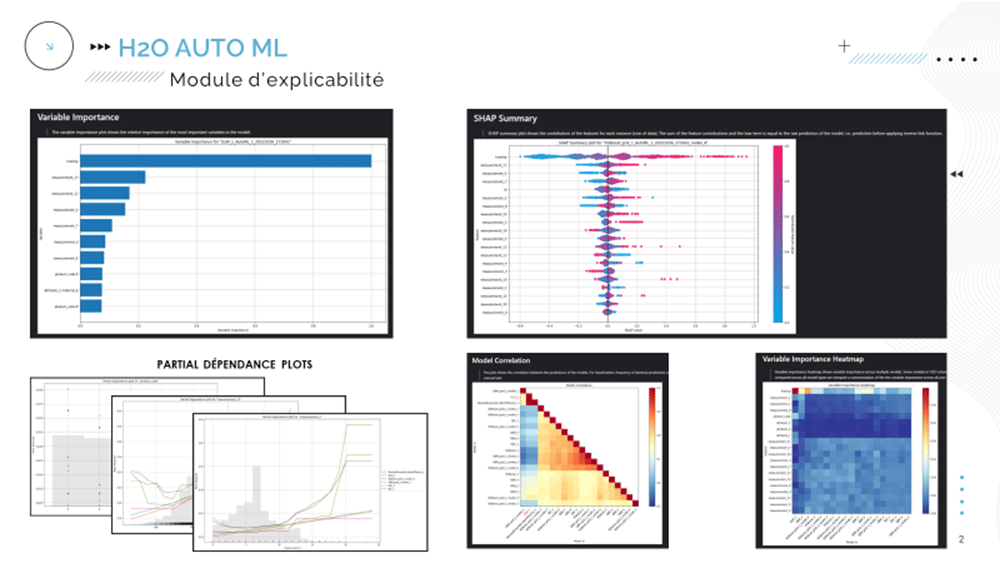
Enfin, le module d’explicabilité (restreinte…) nous permet d’obtenir des informations sur l’importance globale des variables dans les décisions du modèle, ainsi que l’importance globale des variables par modèle entraîné / testé, des graphes de dépendance partielle, une représentation des valeurs de SHAP des variables, … Il est également possible d’obtenir des explications locales sur des prédictions données.
En définitive, H2o AutoML permet d’expérimenter rapidement sur un cas d’usage donné, permettant par exemple de valider l’intérêt d’une approche par Machine Learning. Pour autant, dans notre cas précis, le modèle vainqueur constitue un assemblage complexe de plusieurs modèles non clairement spécifiés (il faut chercher…longtemps !) et cette complexité et ce manque de transparence peuvent en premier lieu rebuter les utilisateurs.
En définitive, l’Auto-ML signe-t-il vraiment la fin du Data Scientist ?
Le succès futur de cette technologie repose aujourd’hui sur les progrès à venir en matière d’apprentissage par renforcement, discipline qui peine aujourd’hui à percer et convaincre dans le monde professionnel. L’explicabilité et la transparence sont également des challenges à relever par cette technologie pour accélérer son adoption.
Mais de toute évidence, l’Auto-ML s’inscrira durablement dans le paysage IA des années à venir.
Quant au data scientist, il est certain que la profession telle que nous la connaissons va être amenée à évoluer. Nouvelle au début des années 2010, comme tous les métiers depuis et selon les organisations, leurs profils et activités vont évoluer.
D’un côté, des profils data scientists plus « business » et moins « tech » vont certainement se dégager se concentrant sur des échanges avec les métiers et la compréhension fine du fonctionnement et des enjeux des organisations. On peut d’ores et déjà voir que ces profils émergent des équipes business elles-mêmes : les fameux citizen data scientists. Ces derniers seront très certainement des fervents utilisateurs des outils d’AutoML.
Également, des profils hybrides data scientist – engineer se multiplient aujourd’hui, ajoutant aux activités classiques de data science la mise en place de pipelines d’alimentation en données et l’exposition des résultats et prédictions sous un format packagé (API, web app, …). L’ère du Machine Learning Engineer a déjà démarré !
Le site internet est une vitrine de l’entreprise, celui qui vous permet de vous présenter à vos partenaires, candidats, clients, prospects… bref, à tout votre écosystème. Il est donc primordial qu’il donne confiance quant à la gestion des données de vos visiteurs, et qu’il soit conforme à la réglementation en vigueur. Un site conforme au RGPD, transparent sur l’utilisation qu’il fait des données que le visiteur lui fournit, offre une bonne première impression et évite de devoir expliquer à vos clients que vous n’êtes pas conforme RGPD si la CNIL décide d’auditer votre entreprise.
Le RGPD n’est pas l’unique règle qu’il faille appliquer pour considérer son site internet comme absolument conforme (règle EPrivacy, régle de régulation des mentions légales, …). Nous nous sommes principalement focalisés ici sur le RGPD.
Il n’est toutefois pas toujours aisé de démêler concrètement les impacts de la réglementation sur votre site et de savoir s’il est bien en phase avec celle-ci. Chez Rhapsodies Conseil, nous vous avons donc préparé une synthèse des quelques points clefs auxquels vous devez vous intéresser.
1. Les cookies
Première action du visiteur sur le site : le bandeau cookie
Un bandeau cookie, doit répondre à 3 obligations indispensables :
Acceptation, refus, paramétrage
Les boutons accepter tous les cookies et refuser tous les cookies sont obligatoires. L’interface ne doit pas avantager un choix plus qu’un autre, les deux boutons doivent, entre autre, avoir la même taille, la même forme et la même couleur.
Le bouton paramètrage n’a pas l’obligation d’être identique aux deux autres, et doit permettre de choisir quel type de cookie j’accepte et quel type de cookie je refuse.
Lors du paramètrage, lesopt-in doivent obligatoirement être désactivés par défaut. Accepter tel ou tel type de cookie doit résulter d’une action du visiteur.
Chaque type de cookie (Fonctionnel, Performance, Analytique, …) doit être décrit afin d’éclairer le visiteur dans son choix. Chaque choix doit se faire par finalité, c’est-à-dire que le visiteur peut refuser les cookies de Performance et de Publicité et accepter tous les autres sans que son parcours sur le site ne soit différent.
Tant que le visiteur n’a pas donné son accord explicite de dépôt de cookies (autre qu’obligatoire), aucun cookie ne doit être déposé.
L’utilisateur doit pouvoir revenir sur son choix dès qu’il le souhaite, il doit donc y avoir un moyen pour le visiteur de revenir sur le paramétrage des cookies afin de refuser/accepter les cookies.
Le bon fonctionnement du paramétrage des cookies & preuve de consentement
Il arrive souvent que, bien que le bandeau cookie permette de refuser le dépôt de certains cookies, celui-ci ne soit pas totalement fonctionnel. Il est donc primordial de vérifier régulièrement que l’outil de paramétrage est bien opérationnel.
Enfin, il est indispensable de pouvoir conserver la preuve du consentement (article 7 du RGPD).
Lien vers la charte des données ou charte des cookies
Le visiteur doit pouvoir accéder à la politique d’utilisation des cookies, rapidement et avant de faire son choix. Un lien vers la politique d’utilisation des cookies doit donc être présent sur le bandeau.
Cette Politique des cookies doit comprendre : une description de ce qu’est un cookie, une description de comment supprimer les cookies par navigateur, la finalité et la durée de conservation des cookies, le type de cookies et préciser (dans le cas d’un cookie tiers) le tiers en question et le lien vers sa propre politique de confidentialité ou de cookies. Contrairement aux idées reçues, la liste exhaustive des cookies n’est pas obligatoire.
ATTENTION : les cookies collectent des données personnelles, ils ne peuvent donc pas être transférés vers des pays où la réglementation sur la protection des données personnelles n’est pas conforme au RGPD. Les Etats-Unis, par exemple, ne donnent pas une protection sur les données personnelles suffisante pour que les données y soient envoyées. L’utilisation des Cookies Google Analytics (_ga, _gat, …) n’est donc pas acceptée.
2. Les mentions d’informations et la charte des données personnelles
Les mentions d’informations sont les petits textes se trouvant sous les « points de collecte de données » (Newsletter, point de contact, inscription, …). Afin de pouvoir faciliter la compréhension, j’aime décrire les mentions d’informations comme une « charte des données personnelles spécifique au point de collecte »
Une mention d’information doit notamment contenir certaines informations que sont :
Un rappel des données personnelles qui sont collectées suivi par l’utilisation qui en est faite ;
Un lien vers la charte des données personnelles ;
La base légale sur lequel s’appuie le traitement ;
Le destinataire des données (préciser si un transfert des données hors de l’UE est effectué) ;
La durée de conservation des données (non-obligatoire si celles-ci sont présentes dans la charte des données personnelles) ;
Le rappel des droits ;
Le point de contact (DPO).
Toutes les informations peuvent se trouver dans un texte sous le point de collecte, il est possible de créer une page spécifique à la mention d’information accessible via un lien (cf. exemple ci-dessus). L’important est de respecter le principe de transparence qui implique que les informations soient présentées d’une forme claire. Il est conseillé que cela soit ludique et adapté aux interlocuteurs concernés.
La charte des données personnelles quant à elle est indispensable dès qu’une donnée personnelle est collectée sur le site. Cette charte doit comprendre les informations suivantes :
Le nom du responsable de traitement ;
Les finalités de traitement ;
Les bases légales sur lesquelles reposent les traitements (si un traitement repose sur le consentement, il faut préciser que celui-ci peut être retiré) ;
Les destinataires des données (avec précision si les données sont transférées hors de l’UE et les garantis quant au respect des règles de sécurités imposées par le RGPD (anonymisation, pseudonymisation, …)) ;
La durée de conservation des données personnelles ;
Le rappel des droits des personnes (accès, limitation, suppression, opposition, rectification et portabilité) ;
Le contact pour faire valoir ses droits (DPO) ;
Le droit de déposer une réclamation auprès de la CNIL ;
L’existence (ou non) d’une prise de décision automatisée ;
La source des données s’il existe une collecte indirecte.
La charte doit être mise à jour dès qu’un nouveau traitement est créé.
Il est possible que vous n’ayez pas besoin de créer de charte des données personnelles. C’est le cas si les mentions d’informations de tous les points de collecte de votre site internet contiennent des mentions d’informations spécifiques et complètes comprenant les informations obligatoires. Si vous répondez à ce cas de figure, il vous faudra cependant une charte des cookies.
3. CGU, CGV, mentions légales
Les CGU ne sont pas obligatoires mais apportent un cadre d’utilisation du site internet (droits et obligations respectives à l’éditeur et au visiteur). Si votre site internet n’est qu’une vitrine et qu’il ne permet pas la création d’un compte, un achat, le dépôt d’un commentaire, … il n’est pas obligatoire d’avoir des CGU.
Cependant, celles-ci sont indispensables dans les cas contraires. En effet, les CGU peuvent être considérées comme le “règlement intérieur du site”. Elles donnent les droits de l’utilisateur, ses responsabilités et également celles en cas de non-respect.
Les droits de l’utilisateur doivent être précisés, par exemple dans le cas de la création d’un espace personnel. Ces dispositions des conditions générales d’utilisation permettent d’engager la responsabilité de l’utilisateur en cas de dommage résultant du non-respect desdites obligations.
Francenum.gouv.fr
L’utilisateur du site doit accepter explicitement les CGU pour qu’elles puissent être considérées comme légales.
Contrairement aux CGU, les CGV sont obligatoires dès que le site propose un service de paiement, vente, livraison en ligne. Les CGV correspondent à la politique commerciale du site internet (modalité de paiement, délais de livraison, rétractation, …). Elles sont particulièrement utiles en cas de contentieux. Cependant, il n’est pas obligatoire de les avoir disponibles directement sur votre site internet, si vos clients sont professionnels (B2B). Elles le sont si vos clients sont des particuliers (obligation précontractuelle d’information du vendeur). Pour chaque vente, les CGV doivent être acceptées par le particulier (B2C).
Les mentions légales sont les informations permettant d’identifier facilement les responsables du site. Pour une personne physique, il faut inclure :
Le nom et le prénom ;
L’adresse du domicile ;
Le numéros de téléphone et l’adresse mail.
Pour une personne morale (une société), il faut inclure :
Le nom de l’entreprise et le numéro SIRET ;
La forme juridique de la société ;
Le montant de son capital social ;
L’adresse du siège social.
Il est aussi impératif de préciser les mentions relatives à la propriété intellectuelle :
La propriété intellectuelle des photos, images, illustrations, textes qui ne sont pas les vôtre (à minima la source des tactes).
En complément de ces informations, il est indispensable d’inclure :
Le nom de l’hébergeur et sa raison sociale ;
L’adresse de l’hébergeur ;
Le numéros de SIRET de l’hébergeur ;
Le numéro de téléphone de l’hébergeur.
Certaines activités impliquent d’ajouter certaines informations :
le numéro d’inscription au registre du commerce et des sociétés (RCS) (et numéro de TVA intercommunautaire, si vous en avez un) ;
le numéro d’immatriculation au répertoire des métiers (RM) ;
le nom du directeur/codirecteur ou responsable de la publication (si vous proposez des articles, des blogs, des informations, …) ;
le nom et l’adresse de l’autorité vous ayant délivré l’autorisation d’exercer (si votre activité est soumise à un régime d’autorisation).
4. Le principe de minimisation
Très souvent, on a tendance à vouloir collecter le plus de données possibles « au cas où », sans finalité précise. Cependant, depuis le RGPD, le principe de minimisation limite cette tendance.
Le principe de minimisation prévoit que les données à caractère personnel doivent être adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées.
CNIL
Ainsi, il n’est plus possible de collecter des données ne pouvant pas être justifiées par la finalité de traitement. Par exemple, demander le genre de la personne pour une inscription à une Newsletter n’est pas possible, sauf si on le justifie (par ex. le contenu de la Newsletter est différent selon que l’on est un homme ou une femme).
Ces quelques points vous donnent une première approche à avoir pour vérifier que votre site est bien conforme. La revue du site est aussi un bon moyen de faire une passe sur les données collectées et lancer une véritable mise en conformité de vos traitements de données (bases de données, contrats, CRM, …).
Chez Rhapsodies Conseil, nous nous appuyons sur des outils internes et externes qui ont fait leurs preuves et sur l’expertise de consultants expérimentés pour analyser la conformité de vos sites internet.