Aujourd’hui, on entend de plus en plus parler de Green IT et de Numérique Responsable. Une des composantes principales de ces concepts vise à faire de l’écoconception dans le secteur du numérique (équipement ou logiciel).
Pourquoi faire de l’écoconception ? Quand doit-on le faire ? Qui est concerné ? Comment écoconcevoir concrètement nos services numériques ? Cet article a pour but de répondre à ces questions et briser quelques mythes qui circulent.
Qu’est ce que l’écoconception ?
L’écoconception dans le numérique, c’est concevoir des produits, services et équipements avec une démarche préventive consistant à intégrer la protection de l’environnement dès l’expression du besoin.
L’écoconception des services numériques n’est pas uniquement une recherche d’optimisation, d’efficience ou de performance mais une réflexion plus globale sur l’usage des technologies afin qu’ils soient le plus sobre possible.
Concrètement elle a pour objectif de réduire la consommation de ressources informatiques et l’obsolescence des équipements (augmenter la durée de vie), qu’il s’agisse des équipements utilisateurs ou des équipements réseau ou serveur.
On pourrait également parler d’éco-socio-conception qui ajoute la prise en compte de l’ensemble des utilisateurs du service numérique. On intègre alors des éléments d’e-accessibilité et d’inclusion numérique. Car pourquoi s’occuper de la planète et pas de ses habitants ? Nous publierons un article sur la socio-conception prochainement afin de montrer pourquoi cela nous concerne tous et comment prendre en compte la performance sociale dans nos projets.
Pourquoi parle-t-on de l’écoconception ?
Pour répondre à cette question, il est dans un premier temps important de faire face à ces constats concernant l’impact du numérique dans nos vies et sur l’environnement :
En 2022, un Terrien aurait en moyenne 8 équipements numériques contre 15 pour un Français (dont 10 écrans) selon l’ADEME. Il y a 10 ans ce chiffre était de 6,5. De plus, en 2018, il y avait 34 milliards d’équipements numériques sur Terre. Ce chiffre en augmentation constante se rapprocherait des 50 milliards en 2023.
Pour fabriquer ces différents équipements numériques, cela nécessite beaucoup de ressources naturelles. Par exemple, pour fabriquer un ordinateur de 2kg, cela nécessite 800kg de ressources naturelles (600kg minéraux, 200kg d’énergies fossiles) selon l’ADEME. Dans ces 800kg ne sont pas comptés les milliers de litres d’eau utilisés pour les différents processus industriels.
Aujourd’hui, un français change de téléphone tous les 2 ans. L’obsolescence en est la cause. Qu’elle soit technique avec des terminaux moins robustes et des services demandant toujours plus de performances, ou qu’elle soit psychologique avec l’envie d’avoir un appareil à la pointe, pas beaucoup plus performant mais vendu comme tel.
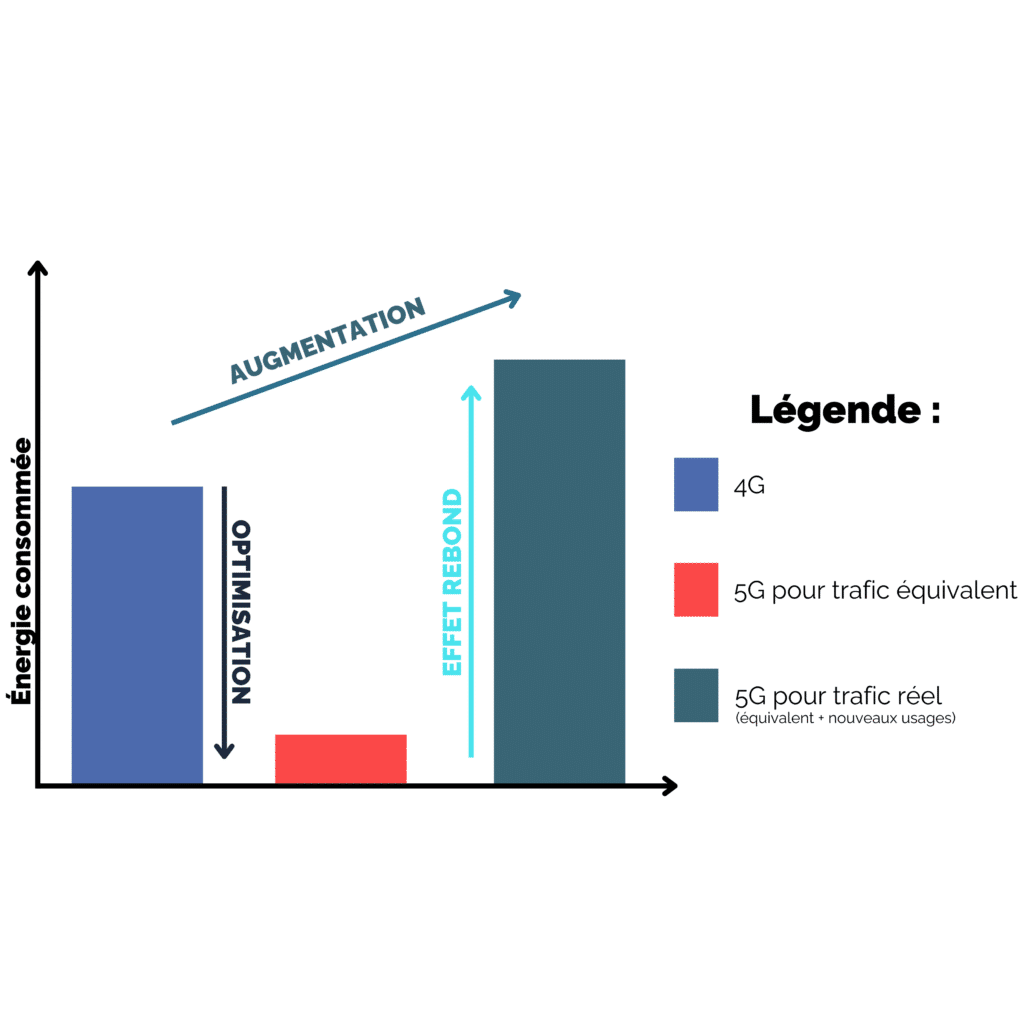
Derrière chaque nouvelle technologie se trouvent divers effets rebond. L’effet rebond désigne un phénomène observé lorsque les économies d’énergie attendues avec l’utilisation d’une ressource ou d’une technologie plus efficace énergétiquement ne sont pas obtenues, voire aboutissent à des sur-consommations, à cause d’une adaptation des comportements. Voici un exemple ci-dessous illustrant l’effet rebond causé par l’adoption de la 5G.
Explication de l’effet rebond : Exemple du passage de la 4G à la 5G
Dans ce diagramme n’apparaissent pas les multiples autres effets rebonds causés par le 5G comme l’obsolescence perçu d’un téléphone avec une antenne qui nous en fait racheter un nouveau, ce qui veut dire qu’il faut fabriquer une puce 5G, qu’il faut que le territoire soit couvert donc que des travaux soient menés pour installer des antennes 5G, elles même fabriquées et pas en France, etc.
Les équipements numériques sont donc le plus gros problème. En France, l’étape de fabrication représente 80% de l’empreinte carbone du numérique selon GreenIT.fr contre 44% dans le monde. Cependant, l’étape d’utilisation reste nécessaire à aborder car elle est de plus en plus hors de contrôle.
En 2023, entre 10% et 15% de l’électricité mondiale alimente le numérique et cela ne cesse d’augmenter. En France, notre énergie est certes en majorité décarbonée donc on pourrait se dire que ce n’est pas notre sujet. Cependant, la pollution et le réchauffement climatique n’ont pas de frontières et certains de nos voisins, parfois même très proches, ne produisent pas tous de l’énergie en majorité décarbonée donc nous en subissons également les conséquences. De plus, beaucoup d’entreprises françaises hébergent leurs données dans le monde entier que ce soit dans des data centers on premise ou sur le cloud.
D’après une agrégation d’étude effectuée par Statista, le volume de données échangées est passé de 6,5 Zettaoctet en 2012 à 97 Zettaoctet en 2022 (sachant que 1 Zo = 1 milliard de To). Ce chiffre devrait certainement atteindre les 181 Zettaoctet en 2025. Il est donc impératif de repenser nos usages de la données.
En résumé, si l’on parle d’écoconception, c’est qu’il est nécessaire aujourd’hui de cadrer le numérique, pas seulement sur un aspect économique mais aussi d’un point de vue environnemental. Pour cela, nous pouvons agir sur plusieurs points :
Le nombre d’équipements en utilisant des équipements existants le plus possible et mutualiser les usages sur un seul et même équipement;
Leur fréquence de renouvellement en développant des services interopérables sur plusieurs générations de systèmes d’exploitation et en permettant d’utiliser son service avec le moins de performance possible (client ou serveur) afin d’éviter l’usure des composants.
Leur consommation d’électricité en faisant tout pour que le temps passé sur le service soit le plus productif possible;
Les volumes de données consommées en ne générant et conservant que des données utiles, utilisables et utilisées.
Deux mythes à briser sur l’écoconception :
Le développeur peut régler ce problème en codant de façon plus écologique !
Que veut dire “coder de façon plus écologique” ?
Cela s’apparente à effectuer plusieurs actions au niveau des paramétrages serveurs et du code afin de réduire la charge sur le serveur et donc la consommation d’énergie lors de la navigation.
Comment ? En limitant le poids des éléments, le nombre de requêtes entre le site et le serveur, etc. Un ensemble d’optimisations permettant d’améliorer les performances d’un service afin d’être moins énergivores.
Le développeur pourra bien sûr optimiser votre service mais il ne pourra pas le rendre foncièrement plus sobre. Or, l’un ne doit pas aller sans l’autre, c’est en étant plus sobre que nous améliorons d’autant plus concrètement la performance environnementale.
Et pour être plus sobre, il faut agir en amont du développement et donc en amont de la phase de réalisation, au moment de l’expression du besoin et de la phase de conception pour de meilleurs résultats. En effet, le service numérique ayant l‘empreinte la plus faible est celui qu’on ne développe pas !
Faire de l’écoconception c’est du temps et de l’argent !
L’investissement de départ en argent et en temps est un peu plus important quand on fait de l’écoconception car l’on doit constamment questionner l’utilité de telle ou telle fonctionnalité et les inscrire dans un processus durable. Cela peut prendre du temps au début. Cependant, c’est en prenant ce temps dès la conception du service que nous parviendrons à rendre cet investissement de départ marginal et un facteur de réduction des problèmes de maintenance et d’évolutivité.
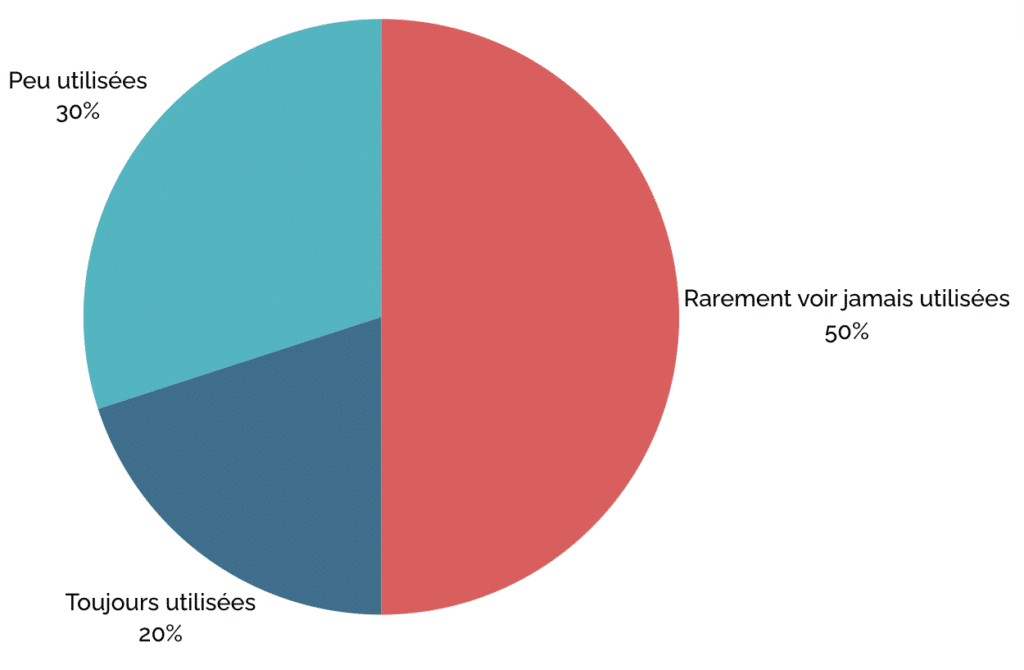
Le service écoconçu cible concentrera uniquement des fonctionnalités essentielles, dans un monde où 50% des fonctionnalités développées des services numériques ne sont pas ou presque jamais utilisées. Il aura des coûts de maintenance réduits et aura à sa disposition une infrastructure adaptée au juste nécessaire et donc plus économique.
Estimation des fonctionnalités utilisées ou non dans des développements spécifiques Exceeding Value – étude effectuée par Standish Group en 2014
Enfin, il sera plus simple à maintenir et à évoluer et donc aura une durée de vie plus longue.
J’achète ! Par où commencer ?
L’écoconception s’articule autour de toutes les parties prenantes d’un projet, tout le long de son cycle de vie. En phase de conception, de réalisation, d’exploitation et de maintenance, et même en fin de vie !
Voici donc toutes les équipes concernées :
Direction
Métier
Chefferie de projet
Design
Développement et Test
Architecture Métier et Entreprise / Architecture Solutions et Applicatives / Architecture Technique et Matérielle
En phase de conception les équipes de chefferie de projet sont mobilisées avec les métiers pour établir une stratégie qui permet de déterminer et de suivre la pertinence, les enjeux et le pilotage de la conception du service numérique. Dans le cadre de l’expression du besoin et de la réponse à ce dernier, un travail sur les spécifications du service sera également à faire. Les spécifications regroupent les éléments de cadrage projet, les moyens mis en œuvre, les objectifs et contraintes du projet sur toute la durée de vie du service numérique.
Une fois les spécifications fonctionnelles établies, les équipes de design auront pour but de définir les meilleures solutions d’interactions destinées aux utilisateurs. Pour ce faire, elles devront prendre en compte tous les documents et médias informatifs ajoutés au service numérique par des personnes contributrices et disponibles pour l’utilisateur final ainsi que leurs impacts environnementaux.
Ensuite, les architectes solutions auront pour objectif de concevoir des architectures en prenant en compte en particulier l’impact environnemental des solutions choisies et surtout leur durabilité. Les architectes techniques auront pour objectif de proposer une infrastructure au juste nécessaire sans surdimensionnement et de favoriser les hébergements les moins polluants. Les architectes matériels devront quant à eux pousser l’utilisation au minimum d’équipements et si cela est obligé, qu’ils soient durables et adaptés aux besoins de l’utilisateur final.
Enfin, pendant la réalisation, l’équipe de développement devra veiller à diminuer les besoins en ressources de ce qui est développé. Le frontend étant souvent plus gourmand en ressources, une attention particulière est exigée pendant son développement.
Pendant toute la vie de nos services numériques, il est donc nécessaire de les suivre pour savoir ce qui existe dans notre portefeuille d’applications, mutualiser certaines fonctionnalités avec des futurs projets, etc.
En fin de vie du service, il est important de le décommissionner afin de réduire les coûts (et donc la consommation d’énergie), de rationaliser et sécuriser le SI et même de valoriser des équipements ou des données.
Le Référentiel Général d’Écoconception des Services Numériques (RGESN) pour agir plus concrètement
Pour aller plus loin dans la démarche d’écoconception, n’hésitez pas à vous renseigner sur le RGESN, référentiel regroupant des actions concrètes à mettre en place.
Une corde à notre arc en plus pour combattre les effets néfastes de l’activité humaine sur le monde
Écoconcevoir des services numériques ce n’est pas que faire du Green Code pour ces 3 raisons :
Il s’agit d’embarquer toutes les parties prenantes du service, au-delà du projet seulement, de l’expression du besoin par le métier jusqu’à sa fin de vie, en passant par sa conception et son exploitation. Ce serait trop simple de placer tous nos espoirs sur une seule et même équipe alors qu’il n’y a qu’ensemble que nous pourrons avoir un impact significatif.
Si ce n’était qu’une histoire de code, nos leviers d’évitement et de réduction d’empreinte environnementale seraient trop peu nombreux et le cœur de notre action ne serait constitué que d’actions d’optimisation de la consommation de ressources informatiques. On oublierait donc les principaux : l’impact des équipements numérique et les effets rebonds additionnels.
Écoconcevoir c’est surtout essayer de ne pas développer ! On développe aujourd’hui tellement de fonctionnalités n’apportant pas ou peu de valeur que l’écoconception se doit d’être un catalyseur de développements de valeurs.
En conclusion, il est aujourd’hui indispensable de se mettre en marche dans la prise en compte de la performance environnementale dans vos projets de conception et dans l’exploitation de vos services numériques. Au-delà d’une démarche citoyenne, c’est une démarche pour nous même qui a pour but de ne délivrer que de la valeur utile et non destructrice.
De plus, dans un contexte légal en constante évolution dans ce domaine, faire de l’écoconception est une manière de respecter la loi REEN et d’anticiper toute loi ou mise à jour de cette loi à venir qui pourrait obliger d’afficher l’empreinte environnementale des activités des entreprises. C’est aussi une manière d’attirer de nouveaux talents, conscients des enjeux du monde de demain, à rejoindre des entreprises engagées pour la planète.
L’Open Data est un concept qui repose sur la mise à disposition libre et gratuite de données. Cela va permettre leur consultation, leur réutilisation, leur partage. C’est aujourd’hui un enjeu majeur pour la transparence gouvernementale, l’innovation et le développement économique.
Nous allons explorer ce qu’est l’Open Data, son contexte légal et son obligation pour certains acteurs publics. Mais aussi les pratiques de mutualisation de données hybrides telles que le data sharing et les plateformes data.
Enfin, nous aborderons les enjeux organisationnels et techniques nécessaires à prendre en compte avant de se lancer dans une telle démarche.
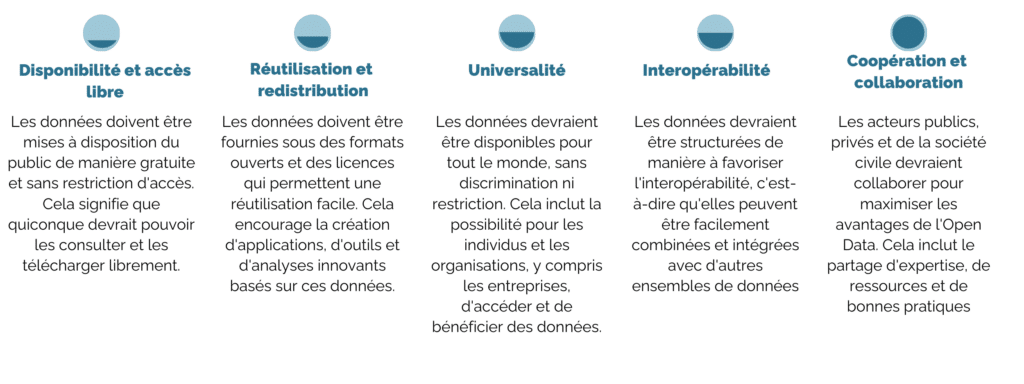
Qu’est-ce que l’Open Data ?
Tout d’abord, l’Open Data se caractérise, entre autres, par les principes suivants :
L’Open Data et la loi
Image générée automatiquement / Midjourney: A judge in a tribunal, surrounded by datas in assembly.
En France, l’Open Data a été promu par la Loi pour une République Numérique, adoptée en octobre 2016. Cette loi impose aux administrations publiques de publier certaines catégories de données de manière ouverte, à moins que des exceptions ne s’appliquent. Ces données incluent les données relatives aux marchés publics, aux prestations et services publics, aux résultats électoraux, et bien d’autres.
Cette loi a modifié le paradigme de publication de l’Open Data. Avant, la publication était souvent conditionnée à une demande d’accès à l’administration, avec des modalités de refus spécifiques à chaque demande qui étaient encadrées par la Commission d’Accès aux Documents Administratifs (CADA). Dorénavant, la publication en Open Data devient la norme, et doit anticiper une éventuelle demande par un citoyen, une association.
Les administrations peuvent toujours choisir de ne pas publier certaines données, en justifiant par exemple que leur publication porterait atteinte à la sureté de l’Etat. Ou bien encore qu’une anonymisation des données personnelles serait un effort disproportionné ou qu’elle dénaturerait le sens des données. Il convient de préciser que la publication des documents est obligatoire uniquement pour les documents dits « achevés» (a atteint sa version finale, à date : les brouillons, documents de travail, notes préalables ne sont pas considérés comme des documents achevés), c’est à dire validés et n’ayant plus objet à évoluer.
Il est également important de noter que les articles L. 300-2 et L. 300-3 du CRPA précisent que les acteurs privés investis d’une mission de service publique sont également soumis à ces obligations de publication.
Quels usages de l’Open Data
Image générée automatiquement / MidJourney: An anthropomorphic computer ingesting data and creating charts and plots.
Un des principes de l’Open Data est de permettre le “re-use” des données, à des fins d’analyses simples ou croisées, à titre non lucratif ou commerciales.
Le site datagouv.fr permet d’inventorier toutes les réutilisations des données liées à un data set, par exemple pour le data set des parcelles et agricultures biologiques :
Sur la page « Parcelles en Agriculture Biologique (AB) déclarées à la PAC » comprenant les données issues des demandes d’aides de la Politique Agricole Commune entre 2019 et 2021, on peut trouver des utilisations de ces données par l’agence bio elle-même, par l’Institut Technique et Scientifique de l’Abeille et de la Pollinisation ou par des sociétés privées de cartographies.
Ces exemples montrent la diversité des réutilisations de données, aussi bien en termes de cas d’usage, que d’acteurs impliqués.
Autres pratiques de Mutualisation de Données
Outre l’Open Data dans le sens “Obligation légale” auprès des acteurs publics, on trouve aujourd’hui des formes hybrides qui font du partage de la donnée un sujet transverse :
Le Data Sharing
Le data sharing, ou partage de données, implique la collaboration entre différentes organisations pour partager leurs données. Par exemple, des acteurs économiques ayant un domaine d’activité similaire mais n’étant pas en concurrence directe (Verticalité de l’offre, Disparité géographique) peuvent mutualiser des donner afin d’optimiser leur R&D, ou leurs études commerciales.
Les Plateformes Data
Les plateformes data sont des infrastructures qui facilitent le stockage, la gestion et le partage de données. On les retrouve au sein de structures, qui souhaitent mutualiser le patrimoine de leurs services, voire de leurs filiales. Il s’agit souvent de créer un point de référence unique, standardisé et facilement accessible des données pour toutes les parties intéressées. Cette plateforme n’est applicable que dans certain cas de figure (plusieurs filiales d’un même groupe par exemple).
L’Open Data s’adresse donc à la fois à la sphère publique et aux acteurs privés de par les obligations légales. Mais aussi par adoption volontaire du principe, ou par exploitation de données mises en open data. Et avec les pratiques liées (plateformes de données, data sharing), on retrouve des enjeux et des risques communs.
Image générée automatiquement / MidJourney: Three books on a table, one of them is open, the two others are closed
Cet article est le premier d’une trilogie consacrée à l’Open Data, qui se conclura par les modes opératoires et les prérequis de réalisation. D’ici-là, le second tome fera office de prequel, en s’intéressant aux origines culturelles de l’Open Data, notamment l’Open Source.
J’ai pu constater régulièrement que beaucoup de gens s’emmêlent les pinceaux quand il est question de définir et d’expliquer les différences entre Service Mesh, Event Mesh et Data Mesh.
Ces trois concepts, au-delà de l’utilisation du mot “Mesh”, n’ont pas grand chose de semblable. Quand d’un côté, nous avons :
Le Service Mesh qui est un pattern technique pour les microservices, qui se matérialise par la mise en place d’une plateforme qui aide les applications en ligne à mieux communiquer entre elles de manière fiable, sécurisée et efficace
L’Event Mesh, qui est un pattern technique d’échanges, afin de désiloter les différentes technologies de messaging
Et le Data Mesh qui lui, est un pattern général d’architecture de données, qui se matérialise par toute une série d’outils à mettre en place, et qui pousse le sujet de la productification de la donnée
On se dit déjà que comparer ces trois patterns ne fait pas sens ! Néanmoins, il y a peut-être un petit quelque chose, une évidence naturelle, qui peut découler de la comparaison.
Mais commençons donc d’abord par présenter nos trois protagonistes !
Le Service Mesh, ou la re-centralisation des fonctions régaliennes des microservices
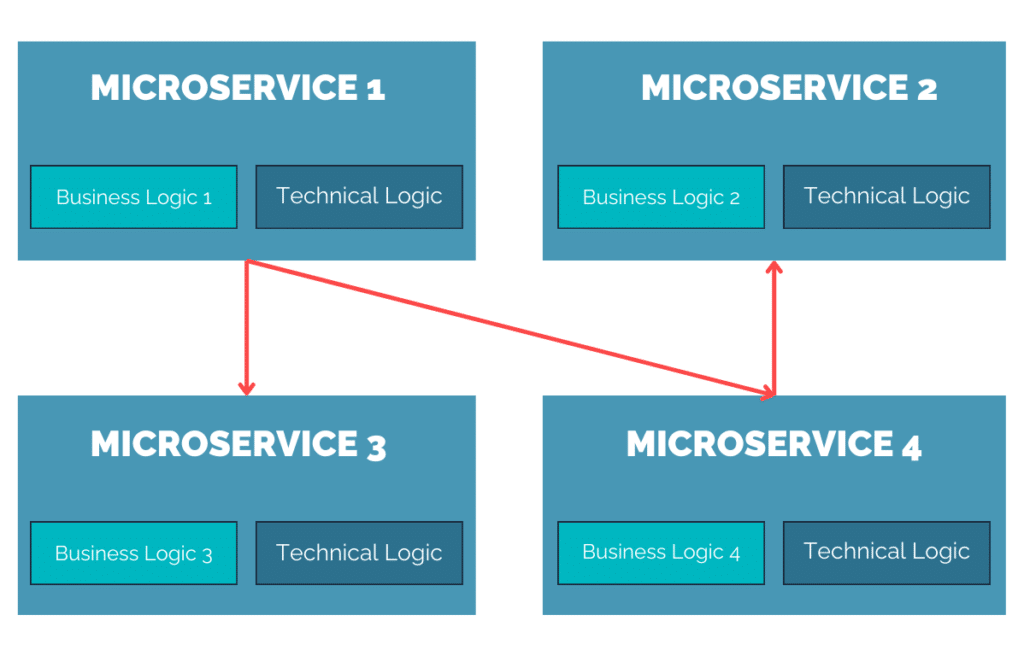
Historiquement, l’approche microservice a été motivée, entre autres, par cette passion que nous autres informaticiens avons souvent, pour la décentralisation. Adieu horrible monolithe qui centralise tout, avec autant d’impacts que de nouvelles lignes de code, impossible à scaler en fonction des besoins fonctionnels réels. Sans compter qu’on peut quasiment avoir autant d’équipes de développement que de microservices ! A nous la scalabilité organisationnelle !
Cela a abouti, de manière simplifiée bien sûr, au schéma suivant :
Chaque microservice discute avec le micro service de son choix, indépendamment de toute considération. La liberté en somme ! Mais en y regardant de plus près, on voit bien une sous-brique qui est TRÈS commune à tous les microservices, ce que j’appelle ici la “Technical Logic”. Cette partie commune s’occupe des points suivants :
La découverte de services
La gestion du trafic
La gestion de tolérance aux pannes
La sécurité
Or quel intérêt à “exploser” cette partie en autant de microservices développés? Ne serait-ce pas plutôt une horreur à gérer en cas de mise à jour de cette partie? Et nous, les microserviciens (désolé pour le néologisme…), ne serions nous pas contradictoire dans nos souhaits de décentralisation? Oui! Car autant avoir une/des équipes dédiées à cette partie, qui travaillerait un peu de manière décentralisée, mais tout en centralisant sur elle-même ce point?
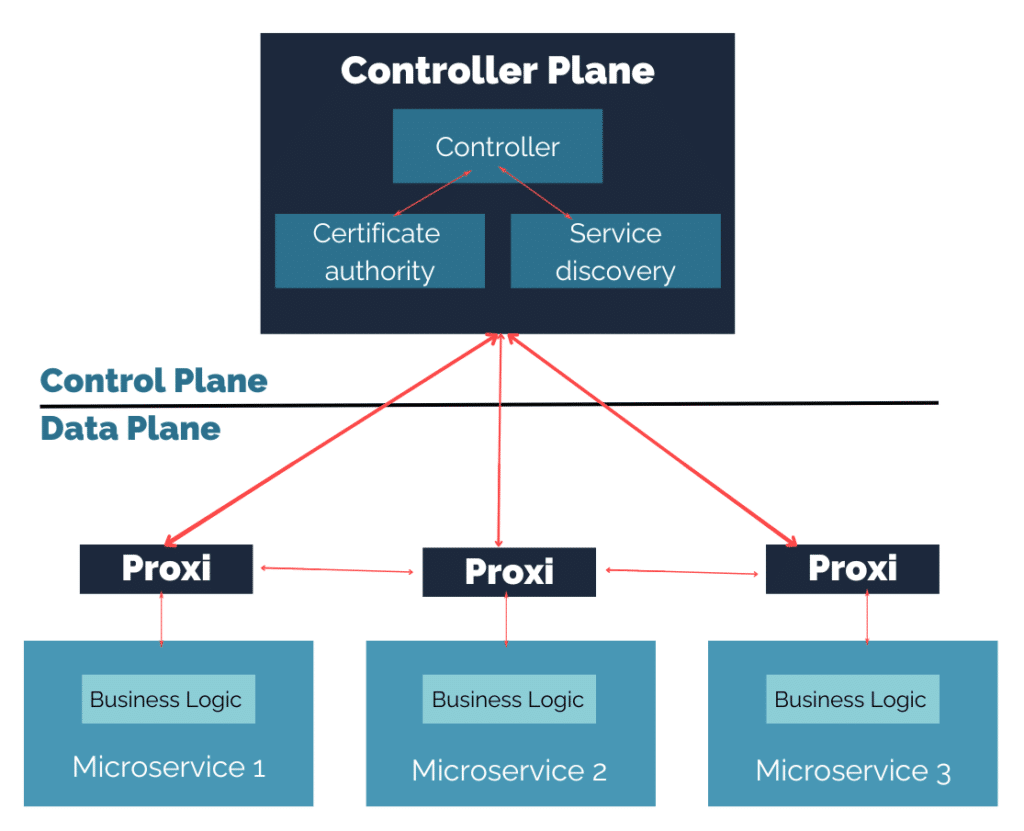
C’est ainsi qu’est apparu le pattern de Service Mesh, décrit dans le schéma suivant :
Dans ce pattern, les fonctions techniques sont définies de manière centralisée (Control Plane), mais déployées de manière décentralisée (Data Plane) afin de toujours plus découpler au final son architecture. Et cela se matérialise par des plateformes comme Consul ou Istio, mais aussi tout un tas d’autres plus ou moins compatibles avec votre clouder, voire propres à votre clouder.
Maintenant que nous avons apporté un premier niveau de définition pour le service mesh, allons donc voir du côté de l’Event Mesh !
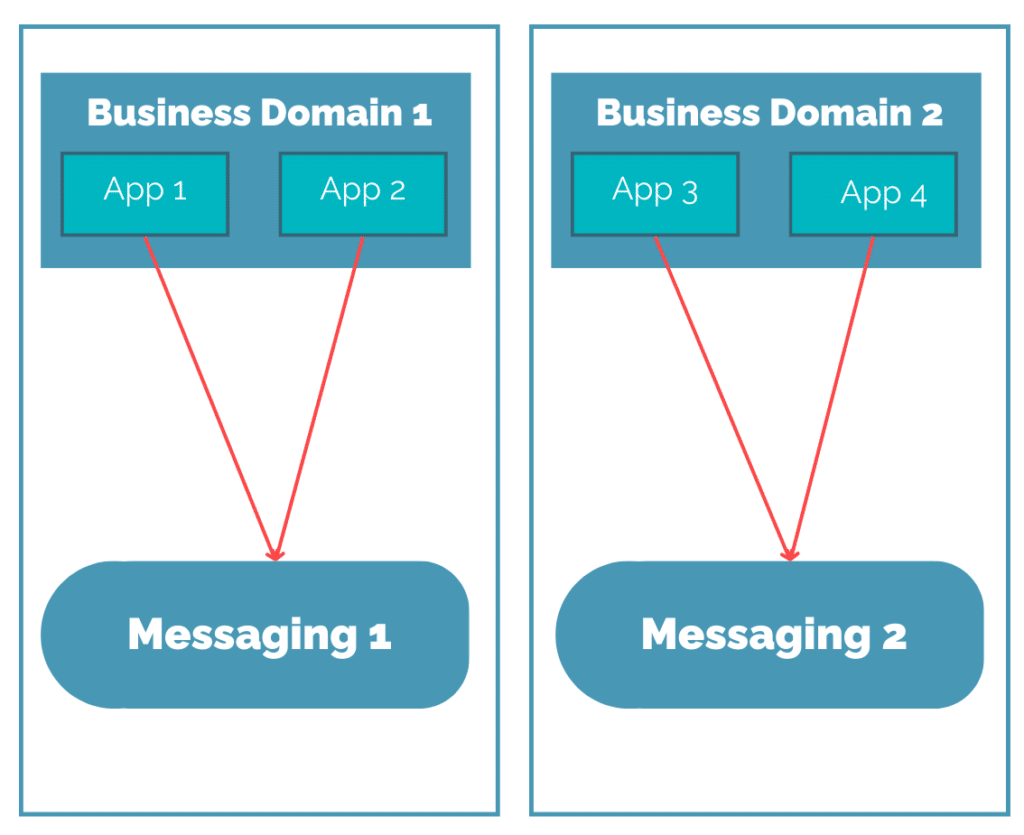
L’Event Mesh, ou la re-centralisation pour désiloter
L’histoire informatique a eu l’occasion de voir tout un ensemble de solutions de messaging différentes, avec des origines différentes. Qu’on retourne à l’époque des mainframes, ou qu’on regarde de côté des technologies comme Kafka qui ont “nourri” les plateformes Big Data, les solutions se sont multipliées. Et c’est sans compter le fait de faire du messaging par dessus du http!
On obtient donc assez facilement des silos applicatifs qui sont freinés dans leur capacité à échanger, comme montré sur le schéma suivant :
Certes, les solutions de bridge existaient, mais elles permettaient souvent de faire le pont entre seulement deux technologies en même temps, le tout avec des difficultés à la configuration et l’exploitation.
Et si on rajoute le fait qu’un certain nombre d’entreprises se sont dit qu’il serait intéressant d’utiliser les technologies propriétaires de chacun de leurs clouders, on imagine bien les difficultés auxquelles elles font face.
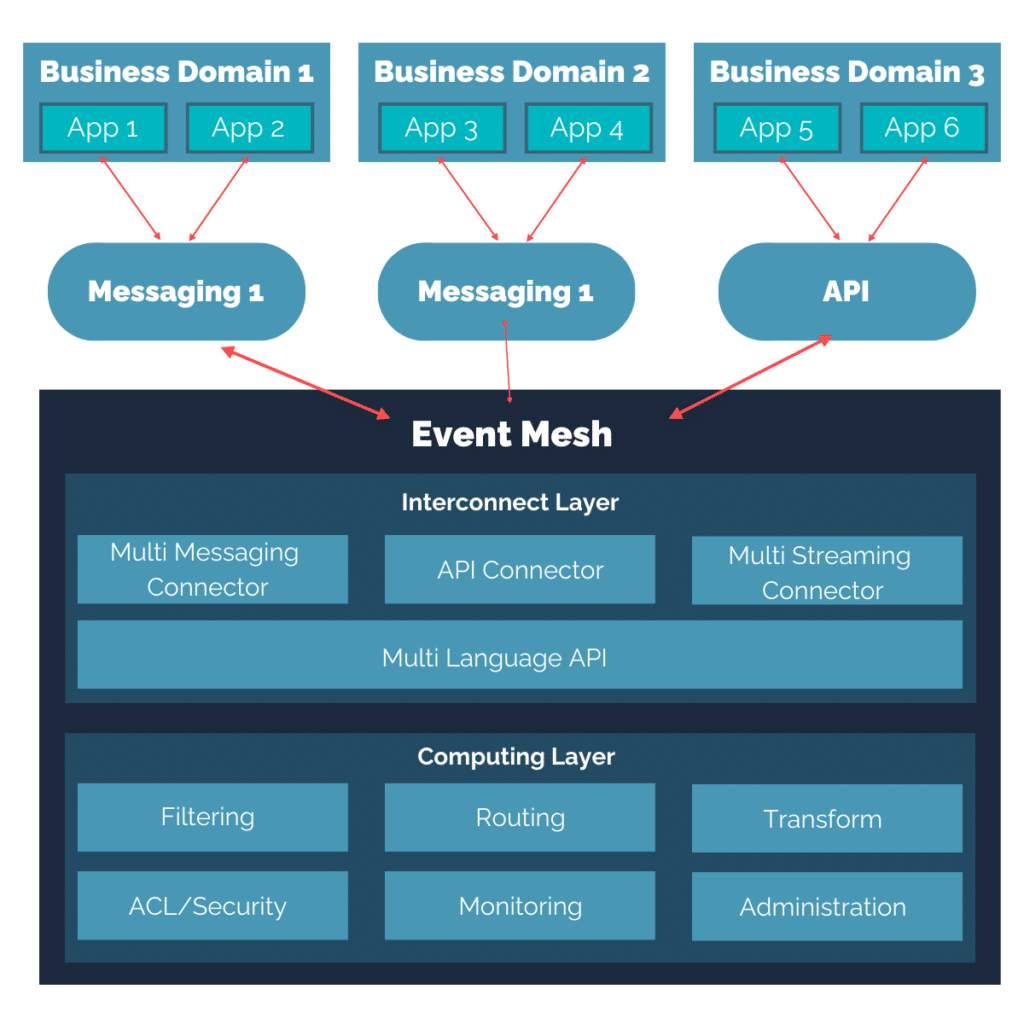
Est donc apparu le pattern Event Mesh, imaginé entre autre, implémenté et popularisé par l’éditeur Solace, qui permet de centraliser sur une solution unique, capable entre autres d’avoir des “agents” locaux aux SI (selon la zone réseau, le datacenter, le clouder, le domaine métier, etc…). Digression mise à part, on notera que le terme Event Mesh a été repris aussi bien par le Gartner que par des solutions open-source.
Indépendamment des architectures de déploiement, cela nous donne l’architecture simplifiée suivante :
Son intérêt vient qu’on peut ainsi relier tout le monde, y compris du Kafka avec du JMS, ou avec des API.
Le Data Mesh, décentralisation ou relocalisation des compétences ?
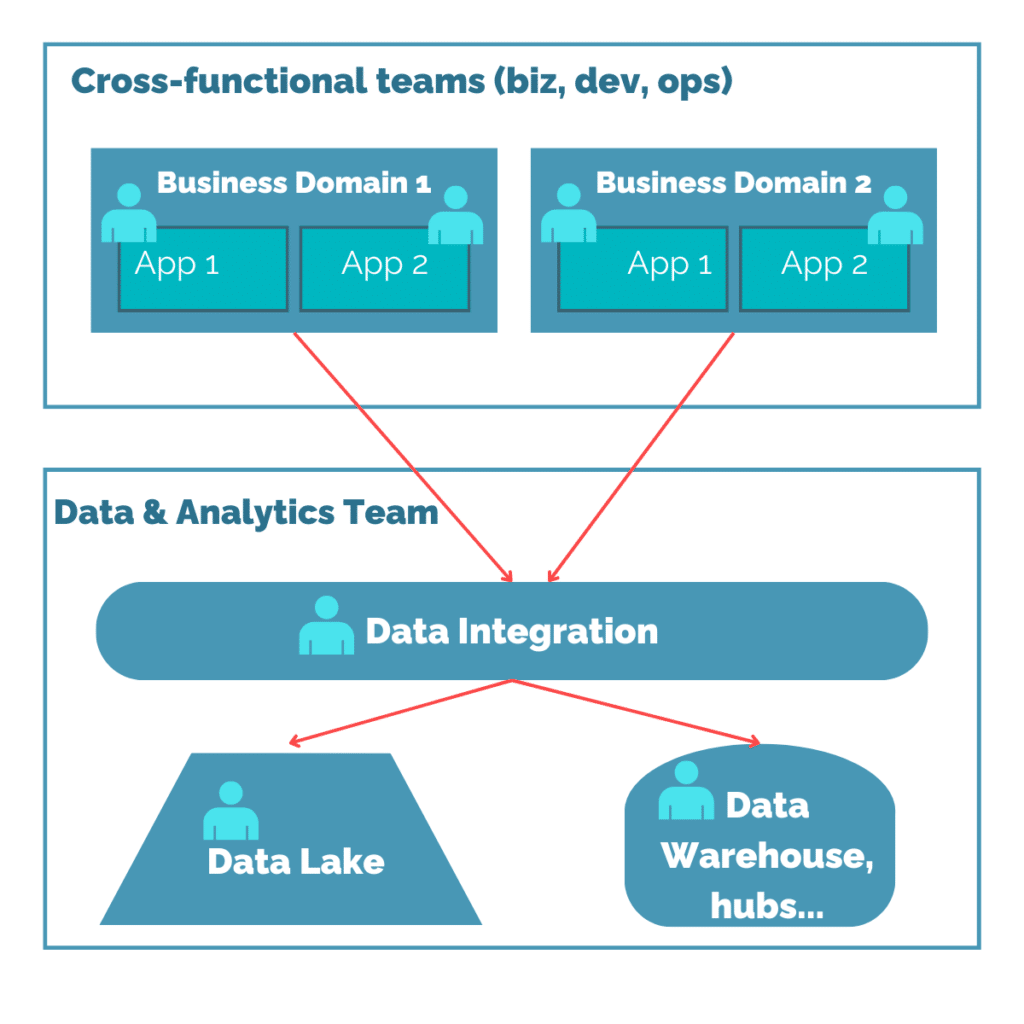
Le Data Mesh, de son côté, vient de son côté en réaction d’une précédente architecture très centralisée, faite de Data Lake, de Datawarehouse, de compétences BI, d’intégration via ETL ou messaging, le tout géré de manière très centralisée.
En effet, il était coutume de dire que c’est à une même équipe de gérer tous ces points, faisant d’eux des spécialistes de la data certes, mais surtout des grands généralistes de la connaissance de la data. Comment faire pour être un expert de la donnée client, de la donnée RH, de la donnée logistique, tout en étant un expert aussi en BI et en intégration de la donnée?
Ce paradigme d’une culture centralisatrice, a du coup amené un certain nombre de grosses équipes Data à splitter leur compétences, créant toujours plus de silos de compétences. De l’autre côté, les petites équipes pouvaient devenir très tributaires des connaissances des sachants métiers. Si cela vous rappelle les affres de la bureaucratie, ce serait évidemment pur hasard!
Ci-joint une représentation simplifiée de l’architecture dont nous avons pu hériter :
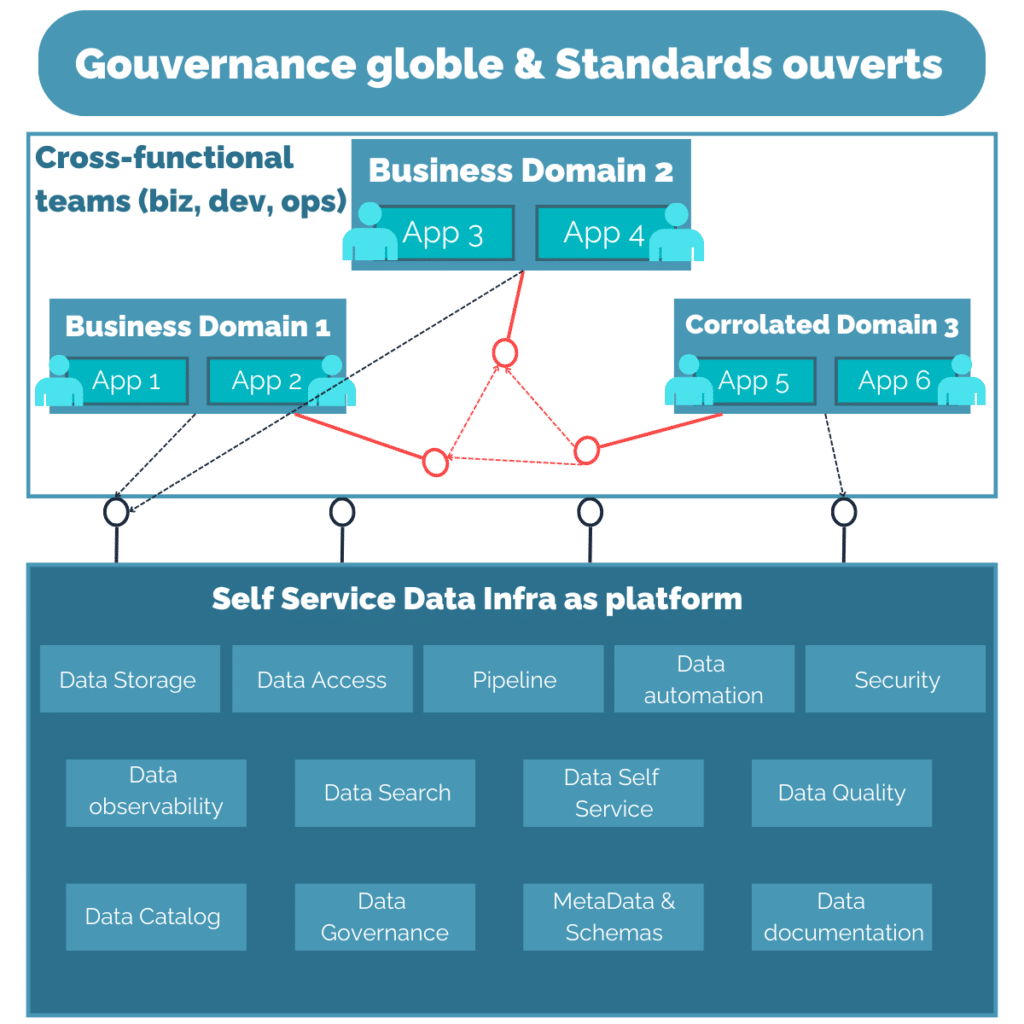
C’est ainsi qu’est apparu le pattern Data Mesh. Dans ce pattern, ce sont aux équipes Domaine de :
Collecter, stocker, qualifier et distribuer les données
Productifier la donnée pour qu’elle ait du sens à tous
Fédérer les données
Exposer des données de manière normée
Ce qui impose en l’occurrence de :
Mettre en place un self-service de données
Participer activement à la gouvernance globale
Et d’avoir un nouveau rôle de Data Engineer, qui doit mettre en place la plateforme de données pour justement faciliter techniquement, et proposer des outils.
Nous avons donc en schéma d’architecture le suivant :
Mais alors quid des points communs ?
Et en réalité, le gros point commun de ces trois patterns, c’est leur histoire !
Les trois proviennent de cette même logique centralisatrice, et les trois cherchent à éviter les affres d’une décentralisation dogmatique. A quoi cela sert de décentraliser ce que tout le monde doit faire, qui est compliqué, et qui en vrai n’intéresse pas tout le monde?
Et à quoi cela sert de forcément tout vouloir centraliser, alors même que les compétences/appétences/expertises/spécialisations sont elles-même “explosées” en plusieurs personnes ?
Certes, la centralisation peut avoir comme intérêt de mettre tout le monde autour de la même table, ce qui peut être intéressant pour de gros projets qui ne vivront pas, ou quand on est dans des phases d’une maturité exploratoire…
Et cela pousse tout un ensemble de principes, dont entre autre (liste non exhaustive):
Découvrabilité : Il faut pouvoir retrouver les services et les données simplement, en les exposants via des « registry » dédiés simples d’accès
Flexibilité et évolutivité : Il faut qu’une modification dans l’infrastructure ou dans un domaine puisse être accueilli sans douleur
Sécurité : Les politiques de sécurité sont propres aux champs d’actions de ces patterns, et sont donc inclus dans ces patterns
Distribution et autonomie : On distribue les responsabilités, les droits et les devoirs, afin de construire un système robuste organisationnellement
Alors oui, je vous entend marmonner “Et oui, c’est toujours la même chose! C’est comme ça”.
Mais en fait pas forcément ! En ayant en tête :
Ces éternels mouvements de yoyo,
Le Domain Driven Design qui est aussi un point commun au Data Mesh et à l’Event Mesh,
La professionnalisation du marketing comportemental a entièrement changé la façon dont les entreprises interagissent avec leurs clients. Nous assistons aujourd’hui à l’avènement de l’hyper-personnalisation, voire de l’individualisation de l’expérience client.
Le champ des possibles est encore repoussé par les nouvelles technologies émergentes qui viennent booster les techniques de marketing comportemental. Celles-ci reposent sur une compréhension en profondeur du profil et des habitudes du client pour lui offrir une expérience unique avec la marque et ainsi le rendre fidèle.
Le marketing comportemental, qu’est-ce que c’est ?
Avant de définir lemarketing comportemental, intéressons-nous d’abord à la définition du marketing classique : “ Ensemble des actions qui ont pour objet de connaître, de prévoir et, éventuellement, de stimuler les besoins des clients à l’égard des biens et des services et d’adapter la production et la commercialisation aux besoins ainsi précisés.” (Merci Le Larousse 📖).
Nous pouvons ensuite l’appliquer et l’adapter pour notre définition du marketing comportemental : “Ensemble des actions reposant sur l’analyse poussée des comportements clients (online et offline), pour connaître et anticiper ses besoins et lui offrir une expérience hyper-personnalisée”. (Merci Rhapsodies 🙏)
Beaucoup de similitudes entre les deux non ? Finalement le marketing comportemental a toujours été partie intégrante du marketing. Mais aujourd’hui, le développement de solutions marketing orientées client permet de le mettre en application de manière toujours plus efficace.
La collecte des données client
La collecte des données client est bien entendu à la base du marketing comportemental. Les données collectées sont de tous types : données client sur les comportements online et offline, comme le comportement utilisateur sur le site web, les historiques d’achats en ligne et en magasin, les commentaires sur les réseaux, et bien d’autres.
L’analyse des données client
Après la collecte, s’ensuit l’analyse des données, qui permet notamment d’identifier et d’affiner les profils clients.
Des analyses telles que :
Descriptives : analyse des données existantes pour établir des tendances et des modèles comportementaux
Prédictives : prévoir les comportements clients en se basant sur des techniques de modélisation en fonction des actions passées
Aujourd’hui, l’Intelligence Artificielle vient rendre ces analyses de plus en plus pointues et pertinentes. Les algorithmes d’apprentissage automatique permettent d’identifier des tendances cachées et de prédire de manière de plus en plus précise les comportements clients.
L’activation des données client
Les analyses permettent ensuite de mettre en place des actions marketing différenciées en fonction des profils définis. Il s’agit « d’activer le client », c’est-à-dire de susciter une action engageante de sa part (ex : un achat, un abonnement, un clic, …). Voici quelques exemples d’actions ou de parcours construits grâce aux techniques de marketing comportemental :
Parcours omnicanal spécifique “churner” ou intentionniste
Personnalisation de site web (ex : personnalisation de bannière, bandeau, page)
Recommandation de produits en fonction des affinités client en omnicanal
Anticipation des demandes au SAV
Sollicitation sur le canal préféré du client et au meilleur moment
Pour aller plus loin, différentes stratégies de marketing relationnel telles que le lancement de programmes de fidélité sont envisageables. Pour mettre en place ces stratégies, il est nécessaire d’étudier les différents scénarios de générosités possibles (générosité réelle, maximum, faciale, etc.) et de formuler plusieurs hypothèses sur des KPIs clés tels que le taux de réachat, le taux d’acquisition ou encore le taux de fidélité. Grâce à cela, il est possible d’avoir une idée des différents bénéfices d’un programme de fidélité d’un point de vue budgétaire et fidélisation. Mais nous en parlerons une autre fois…
Quels sont les avantages et défis du marketing comportemental pour les entreprises ?
Puissant moteur de fidélisation, le marketing comportemental est aujourd’hui capital pour transformer ses clients en “fans fidèles”. Plus un client est ancien, plus le nombre de données sur son comportement sera important, plus il sera possible d’hyper-personnaliser son contenu et donc de le rendre fidèle. Le ciblage des campagnes de marketing direct est rendu plus fin, les recommandations d’offres plus pertinentes ou le traitement des demandes SAV plus efficace. C’est donc là tout l’intérêt du marketing comportemental : faire entrer le client dans un cercle vertueux de fidélité. Le marketing comportemental devient ainsi un élément clé pour développer son activité en améliorant son taux de rétention.
Quels sont les avantages RSE du marketing comportemental ?
Une fidélisation qui peut être renforcée par les aspects durables du marketing comportemental. Celui-ci favorise une approche RSE des activités marketing de l’entreprise. Les communications vers les clients sont réduites, car plus efficaces et envoyées aux bonnes personnes, au bon moment, avec le contenu le plus pertinent. Si nous prenons l’exemple des emails, ceux-ci seront adressés avec un ciblage optimisé et donc avec un volume moindre.
En emprunte carbone qu’est-ce que cela donne ?
Un email envoyé équivaut à 0,3g de CO2. Si sur 1 année vous parvenez à réduire d’1 million le nombre d’envois, alors c’est 300 tonnes de CO2 qui ne seront pas produites.
Et 300 tonnes de CO2, qu’est-ce que c’est ?
1 554 300 km en voiture (38 fois le tour de la terre)
662 400 litres d’eau en bouteille (Consommations moyenne d’eau de 1200 français sur 1 an)
16 200 jours de chauffage au gaz (Consommation moyenne de gaz pour 44 français sur 1 an)
Une autre bonne raison d’implanter une stratégie de marketing comportemental dans votre entreprise !
Quels sont les défis du marketing comportemental ?
L’hyper-personnalisation, atout incontestable de l’expérience client, s’accompagne également de ses défis.
Chaque client se voit de plus en plus préoccupé par la protection de sa vie privée. Il est capital de pouvoir offrir des expériences personnalisées à ses clients tout en respectant les réglementations en vigueur.
On ne vous le présente plus, mais nous allons bien parler du RGPD. Cette réglementation impose des restrictions strictes sur la collecte et le stockage des données. Une réglementation à respecter sous peine d’une sanction financière. Ce règlement vise à donner aux citoyens européens le contrôle sur leurs données personnelles. Il exige le consentement du client lors de la collecte des données client. Le RGPD réglemente également l’utilisation, la conservation, la sécurité des données, ainsi que les droits des individus sur leurs données, tels que l’accès, la correction, la suppression et la portabilité.
De plus, si le marketing comportemental contribue à fidéliser un client, il peut aussi l’effrayer. L’hyper-personnalisation peut inquiéter au vu de la masse d’informations qu’une entreprise peut détenir sur ses comportements. Aussi, un client peut vite se retrouver face à une surcharge d’informations et son expérience s’en retrouvera impactée.
Il est alors capital d’être transparent quant à la collecte des données et de garantir la sécurité de celles-ci, tout en surveillant de près la pression marketing imposée à ses clients.
Illustration d’une expérience client rendue possible par le marketing comportemental
Plus haut, nous avons listé quelques exemples concrets rendus possibles par le marketing comportemental. Ces exemples illustrent comment le marketing comportemental peut être utilisé sur l’ensemble des étapes du cycle de vie du client, de la découverte d’un produit, à son achat, au SAV, jusqu’à la rétention et à la fidélisation du client.
Alors pour illustrer ceci, suivons l’histoire d’Eric :
Eric est un père de famille et client régulier depuis 3 ans d’une entreprise d’électroménager. Pendant ces 3 années, l’entreprise a pu récolter différentes données sur Eric et les a analysées. Elle en a pu tirer les informations suivantes :
Sa segmentation RFM : Eric est identifié comme “à réactiver” par l’entreprise. Il a effectué des achats d’une somme importante il y a plusieurs mois, mais rien depuis.
Canal de communication favori : SMS en 1 & Emails en 2
Catégorie de produit favori : Cuisine, rayon pâtisserie
Tendance d’achat : En promotion
Avis laissés : note moyenne de 4,8 étoiles
Membre du programme de fidélité : Oui
Taux de participation : moyen (2 à 3 sollicitations maximum selon les réactions du client)
L’objectif de l’entreprise est donc ici de réactiver Eric en lui proposant des offres qui répondront à ses besoins. Pour cela, elle va utiliser les techniques de marketing comportemental, en se basant sur les données récoltées. Nous allons donc voir au travers du parcours d’Eric, comment une entreprise peut employer le marketing comportemental à différents niveaux du parcours d’achat.
Comment une entreprise peut employer le marketing comportemental à différents niveaux du parcours d’achat d’Éric.
Et c’est ainsi que se termine l’histoire d’Eric.
Chacune des actions était pertinente avec son profil. Chacun des messages était en cohérence avec les attentes du client et les sollicitations ont été justement dosées afin que le client ne se sente pas oppressé. Les préférences ont toutes été respectées, du choix de support de communication jusqu’à la recommandation de produits ou de contenu. Grâce à cela, l’entreprise parvient à maintenir son engagement. Eric et l’entreprise trouvent donc tous les deux leur bonheur dans cette stratégie de marketing comportemental.
Comment le mettre en place chez vous ?
Une stratégie de marketing comportemental doit être finement réfléchie et suivre quelques étapes incontournables :
Définir ses ambitions en termes d’expérience client : ce que nous souhaitons que nos clients vivent, en fonction de leurs profils, de leurs besoins (ex : autonomie, disponibilité, …) et de la promesse de marque
Définir les parcours cibles : quel canal, pour quel cas d’usage, pour quel type de client
Construire une feuille de route portant sur : l’enrichissement de la connaissance client, le dispositif de marketing relationnel et digital, l’omnicanalité
Mettre en place une organisation propice à l’omnicanalité : pas de barrière entre les canaux, les passerelles doivent être facilitées et fluides
Se doter des bons outils et les intégrer de manière pertinente dans son paysage IT
Comme évoqué plus haut, les solutions de marketing orienté client répondent aujourd’hui à des besoins toujours plus pointus pour optimiser l’expérience client. Outre les outils classiques que nous connaissons en support à la relation client (CRM, Marketing automation, DMP), nous assistons aujourd’hui à l’avènement d’un nouvel outil, la Customer Data Platform (CDP). La CDP présente l’avantage de réconcilier les données online et offline sur des volumes qui peuvent être très importants. Elle analyse ces données finement pour activer efficacement le client en fonction de son comportement. Pour en savoir plus, vous pouvez télécharger notre livre blanc sur les Customer Data Platform.
Maintenant que nous avons fait un tour d’horizon du marketing comportemental, ses défis, ses opportunités et ses bénéfices, il ne reste qu’une seule question à résoudre : comment l’implémenter dans votre entreprise ?
Une telle stratégie demande des interventions à différents niveaux. Utopique sur le papier, mais complexe à implanter, le marketing comportemental permet de se réinventer et d’exploiter les données pour une meilleure expérience client. Que cela soit sur les outils employés, la digitalisation du SI ou la digitalisation de l’expérience client globale, chacun de ces éléments doit être pensé et organisé en harmonie les uns avec les autres. C’est pour cela que nous accompagnons nos clients sur l’implémentation de stratégies digitales de fidélisation en veillant à toujours se positionner dans une vision client.
La dataviz périodique est une publication qui a pour objectif de mettre en évidence les bonnes pratiques et les écueils à éviter en matière de data visualisation (aussi appelée dataviz). A chaque publication, nous vous proposons de décrypter un nouveau sujet et un exemple de dataviz pour comprendre les ficelles de la réussite en datavisualisation.
Dans cette édition, nous aborderons le thème des biais de perception en dataviz et nous verrons comment les limiter en prenant exemple sur une publication du Monde : lien vers la dataviz.
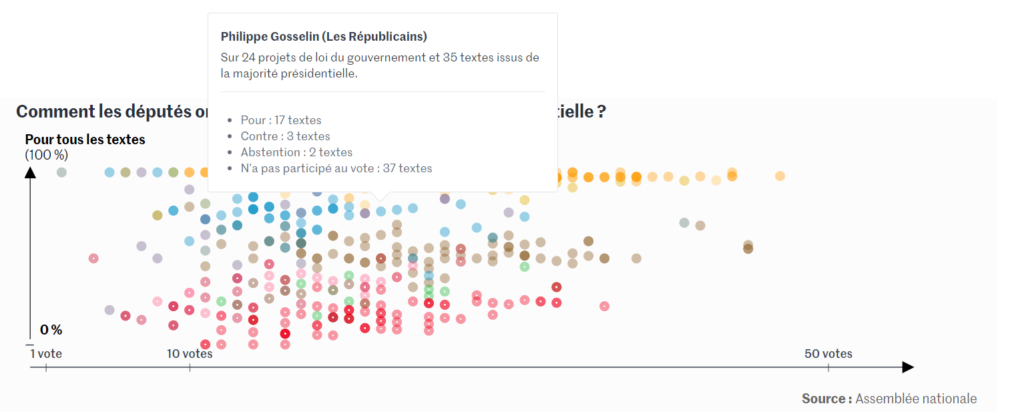
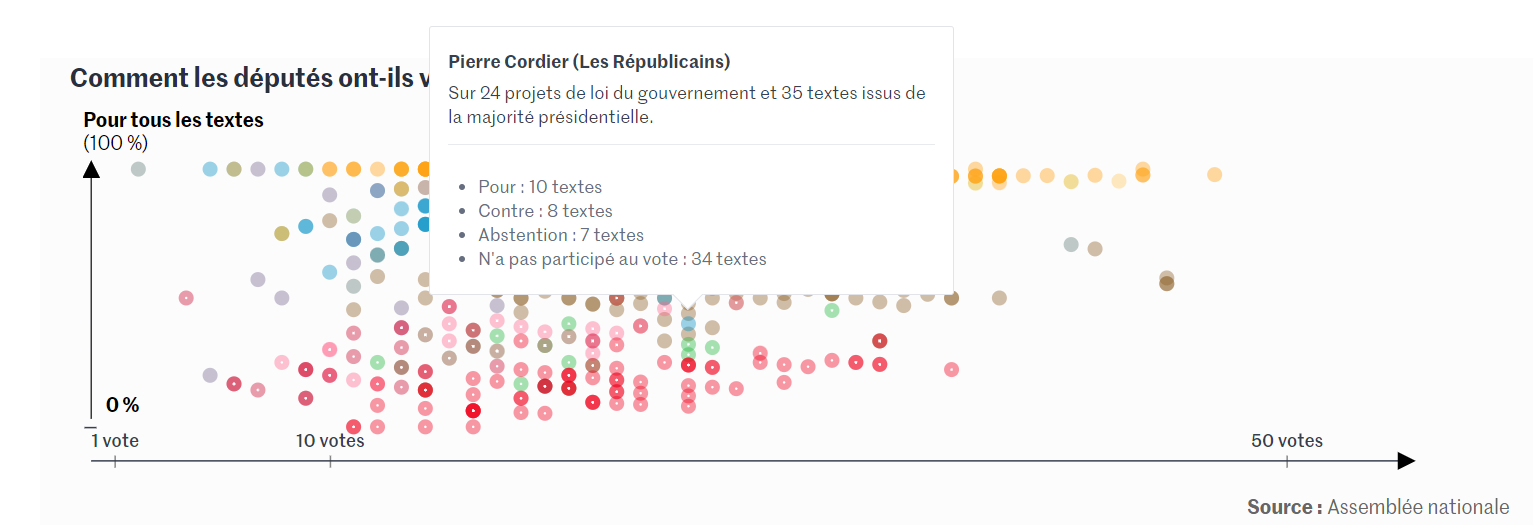
Visuel extrait de l’article du Monde présenté en introduction (lien vers l’article)
Si vous souhaitez aborder un sujet complexe, comme celui du Monde qui s’attache à expliquer le positionnement des députés par rapport à la majorité de l’Assemblée nationale, il est nécessaire de porter une attention particulière au type de graphique utilisé.
Une pratique courante est de proposer une vision moyennée d’un phénomène mesurable sur un groupe (e.g. individus, produits) séparé en catégories (e.g. taille, lieu) en utilisant un graphique en barre. Ce type de visuel a l’avantage de comparer les sujets simplement et de donner l’impression de pouvoir appréhender la réalité d’un coup d’œil.
Or ce n’est qu’une impression. La plupart du temps, nous ne nous rendons pas compte du biais de perception qu’induisent les graphiques en barre en gommant les disparités présentes au sein de chaque catégorie (ou barre du graphique).
Dans son article publié sur Data Visualisation Society, Eli Holder explique l’importance de réintroduire de la dispersion dans la dataviz afin de ne pas créer ou confirmer des stéréotypes. [1]
Le stéréotype est une tendance naturelle, souvent inconsciente, qui consiste à penser aux individus en termes d’appartenance à leur groupe social. C’est une façon pratique et utile de réduire la complexité du monde qui nous entoure. Par exemple, au moment de visiter une ville que nous ne connaissons pas, nous pouvons nous adresser à un officier de police ou à un chauffeur de taxi pour demander notre direction, en partant du présupposé que ces personnes seront à même de détenir l’information. [2]
Cependant, il n’est pas opportun d’encourager cette tendance naturelle quand nous concevons des dataviz, en particulier quand le sujet est complexe et appelle une prise de décision éclairée et réfléchie.
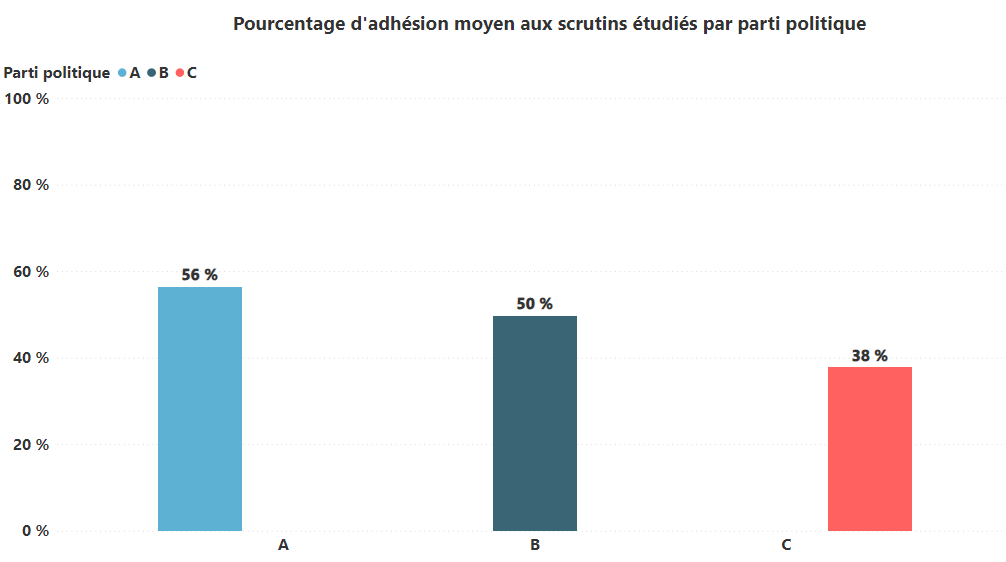
Dans le cas du sujet traité par le Monde, il aurait été possible de représenter l’adhésion au texte de la majorité non pas par député mais par parti politique. Or une représentation en graphique en barre du taux d’adhésion moyen des parlementaires par parti politique aurait renvoyé une illusion de similarité au sein des différents partis et aurait amené mécaniquement le lecteur à penser (cf schéma ci-dessous) : « Le parti politique A vote davantage en faveur des textes portés par la majorité que le parti politique C. Donc tous les députés du parti politique A sont plus proches de la majorité que tous les députés du parti politique C. »
Schéma illustratif réalisé à partir de données fictives (toute ressemblance avec des éléments réels serait fortuite)
Pour casser ces biais de perception, il est possible d’introduire de la dispersion dans nos dataviz et ainsi mieux refléter la complexité de la réalité. Des visuels tels que le nuage de point (Scatter Plot) ou le Jitter Plot sont de bonnes alternatives aux graphiques en barre ou histogrammes.
Dans la dataviz du Monde, le nuage de points a été judicieusement choisi pour montrer le positionnement de chaque député. Cette représentation permet par ailleurs de croiser le taux d’adhésion des députés avec leur niveau de participation aux scrutins étudiés. Cela permet de calculer un indice de proximité plus complet et d’éclairer le sujet avec un nouvel axe d’analyse.
Le lecteur est alors moins tenté de confondre le positionnement des députés avec celui des partis politiques pour le comprendre, et donc moins enclins à faire des préjugés.
Visuel extrait de l’article du Monde présenté en introduction (lien vers l’article)
En définitive, nous observons à travers l’exemple du Monde, qu’il est parfois nécessaire d’introduire de la dispersion dans les représentations visuelles pour traiter un sujet complexe.
Les nuages de points et autres diagrammes de dispersion, permettent au lecteur d’appréhender un phénomène à la maille la plus fine et de limiter la création ou l’entretien de stéréotypes. Le lecteur est alors plus à-même de prendre du recul par rapport au sujet traité et de développer un point de vue éclairé quant au phénomène étudié.
De manière plus générale, Eli Holder propose d’élargir notre conception de la “bonne dataviz” et d’aller au-delà de la représentation claire, accessible et esthétique. Il est nécessaire de prendre en compte sa responsabilité, en tant que créateur de dataviz, vis-à-vis de son public et du sujet traité. Il est essentiel de porter une attention particulière aux visuels choisis pour minimiser les interprétations inexactes, et par extension, la création de stéréotypes.
Cet article est le troisième d’une série présentant les évolutions des rôles des différents architectes dans la nouvelle version 6 du framework SAFe.
Après avoir étudié le System Architect et le Solution Architect, rencontrons l’Enterprise Architect ! Avant de rentrer dans le vif du sujet, nous souhaitions vous faire part de nos impressions quant aux évolutions du rôle de l’Enterprise Architect.
Dans les versions précédentes, le rôle de l’architecte d’entreprise n’était pas très détaillé. Il était clair que celui-ci intervenait dans la définition de la stratégie et aidait à mettre en adéquation les évolutions du système d’information avec celles du métier de l’entreprise, mais cela s’arrêtait là.
Dans cette nouvelle version, le framework contient beaucoup plus de détails sur les responsabilités de l’architecte d’entreprise. Celui-ci gagne ses lettres de noblesse et récupère dans sa bannette des sujets qu’il aurait toujours dû avoir (par exemple la rationalisation du portefeuille technologique). Son rôle n’est plus dans la pure stratégie décorrélée du terrain, il devient plus concret.
En revanche, il a aussi tout un lot d’activités nouvelles, que nous détaillerons dans la suite, et qui nous font dire qu’il faut avoir les épaules très larges pour occuper ce poste. L’architecte d’entreprise semble être partout à la fois, il est devenu une sorte de couteau-suisse ou d’architecte tout terrain si vous me passez l’expression.
Serait-il devenu l’architecte de l’entreprise ? Celui qui cumule bon nombre de responsabilités et qui collabore très largement avec l’ensemble de l’entreprise ? C’est ce que nous allons découvrir dans la suite !
De nouvelles responsabilités : De la définition de la stratégie, aux mains dans le code.
L’entreprise Architect s’est ainsi beaucoup musclé au passage de la version 5 vers la version 6 du framework Safe. Il est certes toujours responsable, au mot près, de la stratégie. Mais d’un rôle de facilitateur semi-passif (« Collaborating », « Assisting », « Helping », « Participating », etc…), il bascule vers un rôle de prescripteur. Un regard critique dirait qu’il retrouve ses prérogatives naturelles… Ainsi les différents (et nouveaux) rôles définis par le framework Safe sont :
Aligning Business and Technical Strategies
Coeur de métier de l’entreprise architect, son rôle est avant tout d’aligner l’architecture avec la stratégie IT, le tout en partageant ainsi sa vision et la stratégie business. Il identifie également les value streams à mettre en place, entretient ses relations avec les différentes équipes et va même jusqu’à participer aux démos.
Establish the Portfolio’s Intentional Architecture
Il s’agit là de définir une architecture cible avec des technologies cibles, des patterns d’architecture, le tout en synchronisant toutes les équipes ensemble. Fait marquant, l’apparition de la démarche inverse de Conway, consistant à définir une architecture, puis à calquer l’organisation sur cette architecture. Le contraire de ce qui est fait en général somme toute. L’architecte d’entreprise devient donc le responsable de la définition de l’organisation des équipes, ce qui en soit est un gros shift!
Rationalizing the Technology Portfolio
Le grand classique de l’architecture d’entreprise. On mutualise, on réduit les coûts, on réduit la complexité, etc…
Fostering Innovative Ideas and Technologies
Le titre est presque trompeur. Il s’agit surtout de permettre d’avoir un environnement technologique moderne et “propre”, en supprimant les technologies obsolètes, apporter du support aux environnements de développements, mais aussi en alignant les choix technologiques avec les business models pressentis.
Guiding Enabler Epics
Il est epic owner sur les initiatives d’architecture, et participe aux réunions safe pour s’assurer du bon alignement des équipes.
L’architecte d’entreprise reprend donc son rôle d’architecte d’entreprise, du métier aux développeurs, en passant par l’organisation des équipes. Par contre, son rôle est beaucoup plus étendu que dans la version 5, se retrouvant ainsi au milieu de nombreux acteurs.
Un accent mis sur la collaboration : D’une tour d’ivoire à un lean-agile leader
En effet, dans la version précédente de Safe, l’architecte d’entreprise était vu comme gravitant surtout dans les hautes sphères et ne collaborait qu’avec les autres architectes et des acteurs de haut niveau ou très transverses (Lean Portfolio Management, Agile Program Management Office, et le Lean-Agile Center of Excellence par exemple).
Il était supposé maintenir des relations avec les personnes de chaque Train mais ses activités quotidiennes ne s’y prêtaient guère. A présent que son périmètre s’étend considérablement, il sera amené à croiser des acteurs beaucoup plus nombreux. Il intervient comme proxy des acteurs business et doit être capable de porter la vision et la stratégie business auprès des différentes parties prenantes.
Il participe également à tous les événements en lien avec les enablers epics et aura donc l’occasion d’interagir avec les acteurs opérationnels des différents Trains.
Ses responsabilités étant également plus distinctes de celles des autres architectes, leur complémentarité est d’autant plus mise en évidence. Une collaboration efficace entre l’Entreprise Architect, le Solution Architect et le System Architect garantit l’alignement.
Enfin, l’Entreprise Architect doit incarner le Lead Agile Leader par excellence. Il mentore les équipes agiles, contribue à la mise en place de nouveaux modes de fonctionnement, et montre l’exemple en continuant à apprendre et à évoluer. Une forme de super héros inspirant tout le monde sur son passage, facile non ?
Si ces sujets vous intéressent…
Pour plus d’informations sur ces sujets et sur le rôle d’architecte dans un environnement agile, n’hésitez pas à aller voir notre série d’articles sur l’architecture et l’agilité.
Les articles 4 et 6 peuvent en particulier se révéler utiles :
Dans l’article 6, intitulé “Les 7 formations de l’Architecte Agile”, nous avions évoqué le besoin de formation SAFE pour l’architecte, et nous avions également parlé de la posture de coach de l’architecte via la process communication et la PNL.
Parmi la littérature conseillée par le framework Safe, on ne peut que vous conseiller le fameux livre “Team Topologies” qui évoque le rapprochement des équipes technologies et business :