#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L’ECOMMERCE
#2 DÉFINIR POURQUOI L’ARCHITECTURE MACH S’ADAPTE BIEN À L'E COMMERCE
3 juin 2024
Architecture
Erik Zanga
Manager Architecture
L’architecture MACH convient-elle à tous les métiers et cas d’usages, ou existe-t-il des situations où elle est plus avantageuse et d’autres où elle est moins adaptée ?
Pour répondre à cette question nous allons à nouveau décomposer ce style d’architecture dans ses 4 briques essentielles : Microservices, API First, Cloud First et Headless.
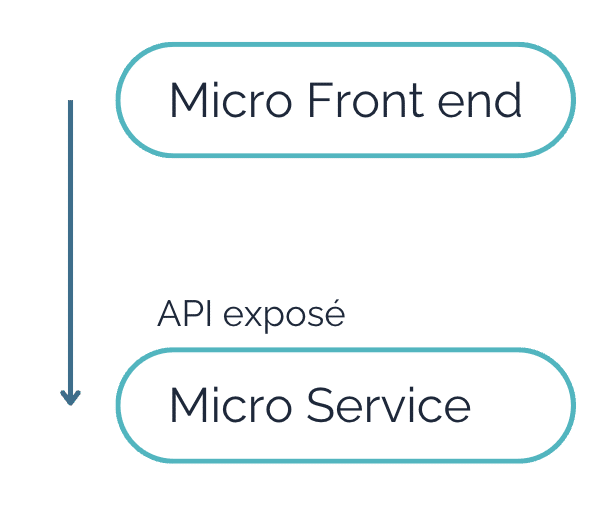
La lettre M : Micro-services
C’est probablement ce premier point qui dirige notre choix de partir vers une architecture MACH vs aller chercher ailleurs.
Nous pourrions presque dire que si l’architecture s’adapte à un découpage en Micro-services, le MACH est servi.
Pour aller un peu plus dans le détail, nous allons introduire le concept de “point de bascule” dans le parcours utilisateur. Nous définissons “point de bascule”, dans un processus, chaque étape qui permet de passer d’une donnée à une autre, ou d’un cycle de vie de la donnée à une autre.
Une première analyse pour comprendre si notre architecture s’adapte ou pas à une architecture MACH, est d’établir si dans le parcours utilisateur nous pouvons introduire ces points de bascule, qui permettent de découper l’architecture des front-end et back-end en micro front-end et micro-services.
Un processus eCommerce par exemple s’adapte bien à ce type de raisonnement. Les étapes sont souvent découpée en :
Recherche dans le catalogue
Mise en panier
Confirmation
Paiement
Gestion de la livraison
Ces 5 étapes traitent les données de façon séparée, et sont donc adaptées à un découpage en Micro-services.
Résultat : Le “M” de MACH et l’efficacité de cette architecture est fortement liée au cas d’usage et au domaine d’application.
La lettre A : API-First
Qui parle web a forcément dû penser aux APIs, dans le sens de Rest API, pour garantir la communication entre front-end et back-end.
Pas de surprise que cela s’adapte à pas mal de solutions, car la communication entre le front-end (navigateur) et le back-end (application) se base sur le protocole HTTP et donc très adapté à ce type d’interface.
Nous ajoutons à tout ça le fait que la création d’un Micro-services et d’un Micro front-end, avec un découpage vertical sur les données traitées, implique naturellement la mise en place d’APIs et ressources spécifiques à chaque étape du parcours client.
Le contexte eCommerce, encore une fois, est bien adapté à ce cas de figure. Les étapes de parcours dont nous avons parlé avant s’inscrivent dans une logique d’APIsation, avec pour chacune d’entre elles une API dédiée.
Recherche dans le catalogue : adresser une API produits
Mise en panier : adresser une API panier ou devis
Confirmation : adresser une API commande
Paiement : adresser les APIs de paiement d’un prestataire (PSP, orchéstrateur de paiement, etc.)
Gestion de la livraison : adresser une API livraison
Résultat : Le “A” de MACH impacte moins que le “M” dans le choix de l’architecture mais épouse bien les concepts définis dans le “M”. Il est donc également très approprié pour un contexte eCommerce.
Pexels – ThisIsEngineering
La lettre “C” : Cloud-Native
Ce cas est probablement le plus simple : les seules raisons qui nous poussent à rester chez soi (infrastructure on premise), à ne pas s’ouvrir au cloud aujourd’hui sont de l’ordre de la sécurité, de l’accès et de la confidentialité de nos données (éviter le Cloud Act, etc.).
Au-delà de ces considérations, le passage au Cloud est une décision d’entreprise plus dans une optique d’optimisation de l’infrastructure que dans le cadre d’un cas d’usage, de processus spécifiques.
Résultat : Le “C” de MACH n’est pas d’un point de vue architectural pure une variante forte.
Néanmoins si nous regardons le cas d’usage cité auparavant, eCommerce, les restrictions sont levées car qui parle eCommerce parle naturellement d’ouverture, de mise à disposition sur le web, d’élasticité, concepts bien adaptés au contexte Cloud.
La lettre “H” : Headless
L’approche Headless convient particulièrement aux entreprises qui recherchent une personnalisation poussée de l’expérience utilisateur et qui ont la capacité de gérer plusieurs interfaces utilisateur en parallèle.
C’est le cas pour du eCommerce, où l’évolution rapide, le time to market et la réactivité au changements du marché peuvent influencer l’appétence, le ciblage du besoin client et le taux de conversion.
Résultat : Le « H » de MACH souligne l’importance de l’expérience utilisateur et de la flexibilité dans la conception des interfaces. Il est particulièrement avantageux dans les contextes où la personnalisation et l’innovation de l’interface utilisateur sont prioritaires. Cependant, il nécessite une réflexion stratégique sur la gestion des ressources et des compétences au sein de l’équipe de développement.
En somme, l’architecture MACH offre une grande flexibilité, évolutivité, et permet une innovation rapide, ce qui la rend particulièrement adaptée aux entreprises qui évoluent dans des environnements dynamiques et qui ont besoin de s’adapter rapidement aux changements du marché. Les secteurs tels que l’e-commerce, les services financiers, et les médias, où les besoins en personnalisation et en évolutivité sont élevés, peuvent particulièrement bénéficier de cette approche.
Cependant, l’adoption de l’architecture MACH peut représenter un défi pour les organisations avec des contraintes fortes en termes de sécurité et de confidentialité des données, ou pour celles qui n’ont pas la structure ou la culture nécessaires pour gérer la complexité d’un écosystème distribué. De même, pour les projets plus petits ou moins complexes, l’approche traditionnelle monolithique pourrait s’avérer plus simple et plus économique à gérer.
En définitive, la décision d’adopter une architecture MACH doit être prise après une évaluation minutieuse des besoins spécifiques de l’entreprise, de ses capacités techniques, et de ses objectifs à long terme.
L’architecture MACH, de par son acronyme, regroupe quatre pratiques courantes et actuelles dans le développement d’applications web.
C’est quoi Architecture MACH ?
Dans ce premier volet, nous allons nous concentrer sur les concepts fondamentaux qui composent ce concept : Microservices, API First, Cloud First, Headless, afin d’adresser l’objectif de chacun.
Tout d’abord un avis personnel, le fait de mettre ces concepts ensemble découle du bon sens : ce type d’architecture est considéré comme simple, efficace, intuitive, bien structurée, modularisée, bref… un travail que les vrais architectes doivent forcément apprécier !
Quid d’Amazon annonçant faire marche arrière pour Prime Video car la mise en application des micro-services implique un nombre d’orchestrations élevées ?
Les Micro-services, tels qu’expliqués dans d’autres articles (voir article micro-services), sont dans notre vision très fortement liés à un découpage DDD (Domain Driven Design).
Dans notre conception un micro-service définit un composant, dérivé d’un découpage métier et fonctionnel, agissant sur une donnée définie.
Le micro-service ne se limite pas uniquement à la partie back-end. Dans un contexte d’architecture web, il peut s’appliquer également au front-end.
Le Micro front-end et le Micro back-end se retrouvent intimement liés par une logique “composant d’affichage” et “composant qui traite applicativement la donnée affichée”.
Une architecture micro-services implique donc une certaine verticalité affichage, traitement et data.
API-First
C’est presque logique, on fait communiquer les différents composants par APIs.
Être API-first signifie d’intégrer la conception des APIs au cœur du processus de conception globale de l’application. Un peu comme si les APIs étaient le produit final.
Attention par contre, autant nous allons retenir l’API entre micro front end et micro back end, autant ce principe n’est pas partagé avec la communication entre le micro-service et d’autres composants du SI.
Une étude des différents patterns d’échange et un choix judicieux entre des méthodes synchrones et asynchrones est très importante pour éviter de mettre des contraintes fortes là où nous n’en avons pas besoin : pour partager une donnée avec les applications back office, tels qu’une confirmation de prise de commande avec un SAP, nous n’avons pas toujours besoin de désigner des flux synchrones ou API, nous pouvons par exemple découpler avec une logique de messaging, le cas d’usage nous le dira !
Cloud-First
Une vraie prédilection pour le Cloud, que du buzzword ?
En réalité, le fait de mettre en avant du Cloud dans cette démarche n’est que du bon sens.
Nous pouvons mettre en place une architecture on premise, pourquoi pas, mais dans certains cas il s’agit d’un vrai challenge : mise en place des serveurs, déploiement de la couche OS, des services, de la partie VM ou Container, etc.
Le Cloud First des architecture MACH vise la puissance des services managés, rapides de déploiement, scalables et élastiques, sur lesquels le déploiement en serverless ou en conteneur et la mise en place des chaînes CI/CD sont en pratique les seules choses à maîtriser, le reste étant fourni dans le package des fournisseurs de services cloud !
HEADLESS
Le Headless représente une tendance croissante dans le développement web et mobile. Cette approche met l’accent sur la séparation entre la couche de présentation, ou « front-end », et la logique métier, ou « back-end ». Cette séparation permet une plus grande flexibilité dans la manière dont le contenu est présenté et consommé. Elle offre ainsi une liberté de création sans précédent aux concepteurs d’expérience utilisateur et aux développeurs front-end.
Dans un contexte Headless, les front-ends peuvent être développés de manière indépendante. Les développeurs peuvent utiliser les meilleures technologies adaptées à chaque plateforme. Cela s’applique au web, aux applications mobiles, aux assistants vocaux, et à tout autre dispositif connecté. Cette approche favorise une innovation rapide. Cela permet aux entreprises de déployer ou de mettre à jour leurs interfaces utilisateur sans avoir à toucher à la logique métier sous-jacente.
La question qui nous vient à l’esprit maintenant est :
Ce type d’architecture s’applique à tout cas d’usage ? Certains sont plus réceptifs que d’autres de par leur configuration, gestion du parcours utilisateur ?
Nous l’avons vu dans les deux premiers articles de cette trilogie: la question du libre accès à l’information date d’avant l’ère informatique. Cette question, qui s’est transformée en obligation pour les acteurs ayant trait au service public, doit bénéficier d’une réponse adaptée. En France, la plateforme “data.gouv.fr” joue un rôle central en permettant aux administrations de publier et de partager leurs données de manière transparente avec le public. Cependant, pour garantir une publication de qualité et exploitable, les contributeurs doivent entre autres suivre trois étapes importantes.
Midjourney, prompt : A technical drawing of a computers and databases network. A pole with a French flag is located in the middle.
Étape 1 : Mise en gouvernance des données et des produits
La première étape du processus consiste à identifier les ensembles de données à publier, ou plutôt, vu que la règle est la publication, et l’exception est la rétention, identifier quelles données ne pas publier.
Cela suggère un prérequis important : Connaitre son patrimoine des données. Dans ce cas de figure, être capable de déterminer exhaustivement et explicitement quelles données possèdent des caractéristiques empêchant leur publication en open data (telles que des données personnelles ou des atteintes à la sûreté de l’État).
Un autre sujet important est celui de la connaissance et de la maitrise du cycle de vie des données. Où la donnée est-elle créée dans le Système d’Informations ? Où la récupérer dans son état le plus consolidé et certifié en termes de qualité ? A quelle fréquence la donnée devient-elle obsolète ?
Enfin, et sujet tout aussi majeur : quelle est la notion « Métier » (Ou « Réelle ») portée par cette donnée ? Quelle information interprétable et exploitable dans différents cas d’usages recouvre-t-elle ? En somme, quelle est sa définition ?
Afin d’arriver à cette connaissance et cette gestion systématique et qualitative des données, c’est toute une organisation qui doit être transformée, dotée de rôles et de processus adéquats. Et si l’Open Data est une bonne raison de se lancer dans une telle démarche, de nombreuses externalités positives (Par exemple, fiabilisation d’indicateurs, réduction du temps de traitement/recherches de données) sont à anticiper pour l’ensemble de ses usages basés sur les données, donc pour l’activité de la structure.
Enfin, un angle pertinent pour amorcer une transformation peut être de considérer le jeu de données à publier comme un « Data Product ». Même s’il n’y a pas de finalité financière directe attendue de la publication en open data, il est bénéfique de penser au jeu de données comme un produit. Responsabiliser des collaborateurs, tels que des Data Product Managers, autour de leur conception ou de leur suivi, au-delà des données qui les composent, permet d’aller vers une véritable gestion d’un portefeuille open data. La structure peut alors traiter les données comme un actif, et les produits qui en résultent permettent d’activer leur valeur.
Midjourney, prompt : An orchestra conductor in front of a computer assembly
Étape 2 : Préparer son jeu de données
Nous identifions les données, assurons leur qualité et déterminons leur point d’accès. C’est un bon début, mais il reste encore quelques étapes techniques avant de procéder au chargement des données.
Une des obligations légales de l’Open Data est de proposer un format exploitable par machine.
Data.gouv.fr détaille la liste des formats de fichier adéquats :
Formatage des Données : Les données doivent être formatées de manière à être facilement accessibles et exploitables par le public. Il est recommandé d’utiliser des formats ouverts et standardisés tels que CSV, JSON ou XML. Les données doivent également être bien structurées, avec des en-têtes explicites pour chaque information.
Documentation des Métadonnées : Nous devons accompagner chaque ensemble de données de métadonnées détaillées. Les métadonnées fournissent des informations essentielles sur les données, telles que la description de l’ensemble de données, la source, la fréquence de mise à jour, les licences d’utilisation, et les balises (tags). Ces informations, qui décrivent les données que l’on veut publier, permettent d’en assurer le suivi, la traçabilité, et de faciliter leur recherche, consultation, et réutilisation.
Organisation et Schémas de données : En parallèle de ces aspects techniques, les notions d’organisation et de schéma sont importantes à prendre en compte pour assurer une publication de qualité. L’organisation va permettre d’identifier un acteur (Une personne morale, une entreprise, un service de l’état), et de publier des jeux de données depuis plusieurs comptes « en son nom ».
La proposition et l’adoption d’une nomenclature particulière pour un type de données qui sera fréquemment mis à jour ou régulièrement complété par d’autres acteurs constituent le schéma de données. Par exemple, si des communes commencent à publier des jeux de données sur l’installation de défibrillateurs dans les lieux public, il existe un grand intérêt à converger vers un schéma de données commun afin de valoriser l’information.
Étape 3 : Publication des Données sur Data.gouv.fr et suivi
En fonction du type de données, de leur taille, de la fréquence de mise à jour de l’informations, il existe plusieurs possibilités pour les publier.
Du dépôt manuel de données à la mise à disposition par API , ou à l’import automatique en moissonnage, ces différents itinéraires techniques sont à examiner pour chaque situation, avec possibilité de consulter les collaborateurs administrateurs de datagouv.fr
En première partie, nous avons vu que dès les premières réflexions et bien en amont de la première publication, il est essentiel de penser à l’aspect « pérenne » d’un jeu de données, en commençant par une démarche de gouvernance des données. Il existe cependant un suivi possible à postériori, sur l’utilisation et la réutilisation des jeux de données. Là encore la plateforme datagouv.fr permet aux organisations d’accéder à des statistiques sur l’exploitation des données qu’elles mettent en Open Data.
Midjourney, prompt : A golden and shiny computer
Encore récent, et pour l’instant souvent « contraint », le sujet de l’Open Data pourrait voir un basculement de paradigme dans les années à venir. L’ensemble des acteurs socio-économiques pourraient s’engager à partager des connaissances, ce qui pourrait être inscrit comme un objectif RSE. Et au-delà de penser l’open data comme un centre de coût du fait de l’activité nécessaire à la mise à disposition des jeux de données, les acteurs économiques légalement contraints à la publication pourraient également en faire un centre de profit en tant que ré-utilisateurs.
“as Prompt” va-t-il devenir la norme ?
“as Prompt” va-t-il devenir la norme ?
15 avril 2024
Architecture d’entreprise
Clément Lefranc
Senior Manager Architecture
Impulsées par l’avènement du Cloud et du DevOps, les mouvances “as Code” et “Software Defined X” ont grandement amélioré la gestion du cycle de vie des assets informatiques (infrastructure, middleware, serveur d’application, …) avec principalement :
L’Infrastructure as Code (IaC),
La Configuration as Code,
Nous détaillerons dans un futur article le positionnement de chacun et les grands paradigmes en présence (procédurale vs déclaratif), qui reposent sur une caractéristique commune: l’utilisation de template/playbook au format normalisé (HCL, YAML, …) décrivant l’état final à atteindre ou le moyen d’y aller.
Même si la syntaxe est Human Readable, il peut être fastidieux à l’échelle d’un SI enperpétuelle évolution d’écrire et de mettre à jour ces fichiers de description.
Bien qu’il existe de plus en plus de plateformes simplifiant la création de ceux-ci sur base de conception visuelle en LowCode/NoCode ou de schématisation…Que diriez-vous de troquer d’un point de vue utilisateur le ”as Code” par du ‘as Prompt” ?
#GenAI à la rescousse
Le terrain de jeux des Large Language Models (LLM) et de la GenAI ne cesse de croître, en n’oubliant pas au passage l’ingénierie logicielle.
Imaginez pouvoir simplement demander “Provisionne un cluster de VM EC2 avec NGINX en exposition publique ainsi qu’une base Elasticache” pour voir votre souhait exaucé instantanément.
D’ailleurs, n’imaginez plus, car l’Infrastructure as Prompt (IaP) est déjà proposée par Pulumi AI, et bien d’autres en cours (depX) ou à venir.
Ce positionnement et les avancées rapides et significatives dans ce domaine ne sont pas étonnantes car nous sommes en plein dans le domaine de prédilection des LLMs: les langages.
Qu’ils s’agissent de langages parlés (Français, Anglais, …), de langages de programmation (Python, JavaScript, Rust), de langage de description (HCL, YAML, …), ils ont tous deux concepts fondamentaux:
Un dictionnaire, un vocabulaire, une liste de mots avec une (plusieurs) signification(s) connue(s),
Une grammaire et des règles syntaxiques plus ou moins strictes donnant un sens particulier à la suite de mots d’une phrase ou d’une ligne de fichier de configuration.
Plus le dictionnaire et la grammaire d’un langage sont dépourvus d’ambiguïtés, plus le degré de maturité et la mise en application de la GenAI et des LLMs sur celui-ci peut-être rapide.
L’Infrastructure as Prompt n’est pas une rupture totale avec le “as Code”, simplement une modernisation de l’interface “Homme-Clavier”.
En effet, peu importe le moyen (création manuelle, auto-génération via prompt) l’aboutissement de cette première étape est la disponibilité du fichier de description.
Le cœur du réacteur, à savoir la traduction du <fichier de conf> en actions pour <provisionner et configurer les ressources>, est toujours nécessaire.
A l’avenir elle pourra se révéler un parfait assistant pour faire des recommandations et propositions d’ajustement vis-a-vis de la demande initiale pour optimiser l’architecture à déployer:
Prioriser les services managés,
Prioriser le serverless,
Etre compliant avec les best practices des frameworks d’architecture des Clouders (AWS Well Architected Framework, …),
Security By Design,
RIght sizing de l’infrastructure,
Opter pour des ressources ayant une empreinte carbone et environnementale optimisées.
#La confiance n’exclut pas le contrôle
Bien que la baguette magique qu’apporte cette surcouche soit alléchante, nous ne pouvons qu’abonder les paroles de Benjamin Bayard dans son interview Thinkerview Intelligence artificielle, bullsh*t, pipotron ? (25min) : “tous les systèmes de production de contenus si ce n’est pas à destination d’un spécialiste du domaine qui va relire le truc, c’est dangereux.” Dans un avenir proche l’Infrastructure as Prompt // la Configuration as Prompt n’est pas à mettre dans les mains de Madame Michu (que nous respectons par ailleurs) qui ne saura pas vérifier et corriger le contenu de Provisioning, de Configuration ou de Change qui a été automatiquement généré. Nous vous laissons imaginer les effets de bords potentiels en cas de mauvaise configuration (impact production, impact financier, …) dont le responsable ne serait autre que la Personne ayant validé le déploiement. Impossible de se dédouaner avec un sinistre “c’est de la faute du as Prompt”.
Vous l’avez compris, la déferlante LLM et GenAI continue de gagner du terrain dans l’IT, le potentiel est énorme mais ne remplace en rien la nécessité d’avoir des experts du domaine. Le “as Prompt” se révèle être un énorme accélérateur pour l’apprentissage du sujet, ou dans le quotidien de l’expert .. qui devra avoir une recrudescence de prudence quant aux configurations qui ont été automatiquement générées.
Au cours des dernières décennies, l’évolution de la technologie a vu émerger une culture et une philosophie qui ont profondément influencé la manière dont nous développons, partageons et utilisons les logiciels et les données. Cette culture repose sur des principes fondamentaux de transparence, de collaboration et de partage. Pour faire suite à notre premier article, explicitant ce qu’était l’Open Data, nous aborderons ici l’histoire de la Culture Open Source et expliquerons en quoi l’open data en découle naturellement.
Qu’est-ce que la Culture Open Source ?
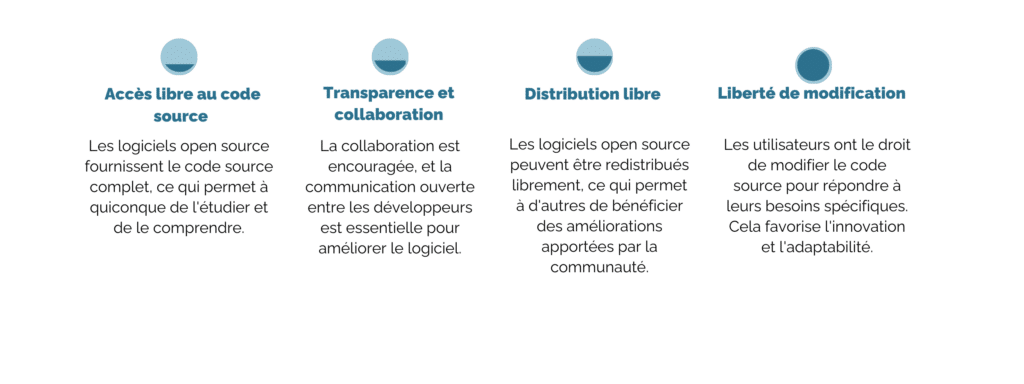
La culture open source est un mouvement qui promeut l’accès ouvert et le partage de logiciels et de ressources, permettant à quiconque de consulter, d’utiliser, de modifier et de distribuer ces ressources. Cela contraste avec le modèle de développement de logiciels propriétaires, où les entreprises gardent le code source secret et limitent les droits de modification et de distribution. Bien que le terme « open source » ait été popularisé au début des années 2000, les principes qui le sous-tendent remontent beaucoup plus loin dans l’histoire de l’informatique.
La Culture Open Source repose sur plusieurs principes clés :
Longtemps considérée comme une culture ne renfermant que des geek et informaticiens, l’Open Source s’est démocratisée et se retrouve dans de nombreux outils que nous utilisons tous (VLC, Mozilla Firefox, la suite LibreOffice, 7Zip…). Le partage des logiciels Open Source est favorisé par des plateformes de centralisation dont la plus connue est GitHub. Malgré une réputation de visuel dépassé et d’une utilisation parfois laborieuse et incomplète, le logiciel Open Source est souvent considéré comme plus sûr car ses failles sont rapidement identifiées, les mises à jour disponibles et l’adaptabilité favorisé (on n’est pas obligé de mettre à jour constamment son logiciel si on ne le souhaite pas, gardant ainsi la possibilité ou non d’ajouter des fonctionnalités).
Image générée par Midjourney: A picture of an orange firefox wrapped around an orange and silver traffic cone
L’Histoire de la Culture Open Source
L’histoire de la culture open source remonte aux débuts de l’informatique moderne. En effet, dans les années 1950 et 1960, les chercheurs construisaient souvent les premiers ordinateurs en tant que projets collaboratifs, et ils partageaient librement des informations sur la conception et le fonctionnement de ces machines, considérant le partage d’informations comme essentiel pour faire progresser la technologie.
L’une des premières incarnations de la culture open source telle que nous la connaissons aujourd’hui est le mouvement du logiciel libre, lancé par Richard Stallman dans les années 1980. Stallman a fondé la Free Software Foundation (FSF) et a développé la licence GNU General Public License (GPL), qui garantit que les logiciels libres restent accessibles à tous, permettant la modification et la redistribution. Cette licence a joué un rôle crucial dans la création d’une communauté de développeurs engagés dans le partage de logiciels.
Dans les années 1990, le développement de Linux, un système d’exploitation open source, a été un événement majeur. Linus Torvalds, son créateur, a adopté la philosophie du logiciel libre et a permis à des milliers de développeurs du monde entier de contribuer au projet. Linux est devenu un exemple emblématique de la puissance de la collaboration open source et a prouvé que des logiciels de haute qualité pouvaient être produits sans les restrictions du modèle propriétaire.
Plus récemment, le sujet de l’open source apparait comme un marqueur majeur de différenciation entre les différents acteurs AI :
Si l’on regarde du côté de l’entrainement de différents moteurs, une majorité des acteurs de l’IA utilise des données publiques issues d’espace de stockagedisponible tels que CommonCrawl, WebText, C4, BookCorpus, ou encore les plus structurés Red Pajama et OSCAR.C’est lorsque l’on observe l’usage et la publication des résultats que plusieurs stratégies s’opposent.
Le leader de l’IA générative Open AI a un positionnement “restrictif” dans la publication de ses avancées, au motif de protéger l’humanité de publications trop libre de sa création. Cela a par ailleurs contribué au feuilleton médiatique récent qui a secoué la direction de la structure.De l’autre côté du spectre, nous avons Mistral AI, que nous avons eu l’occasion de présenter auprès des journalistes de Libération et du site internet d’Europe 1. En effet, celle-ci propose l’ouverture totale de l’ensemble des données, modèles et moteurs, dans une orientation typiquement Européenne (Data Act).
Les données ouvertes dans l’histoire
Le développement de cette culture open source, par le développement des outils informatiques, marque le vingtième siècle. Mais l’humanité n’a pas attendu ces progrès technologiques pour se poser des questions sur la libre diffusion des connaissances.
Au premier siècle avant JC, Rome édifie une bibliothèque publique au sein de l’Atrium Libertatis, ouverte aux citoyens.
De plus, si le moyen-âge marque une restriction des accès aux livres pour la population, de nombreux ouvrages restent accessibles à la lecture, mais pas encore à l’emprunt ! Les livres sont attachés aux tables par des chaînes, et l’on trouve dans certaines bibliothèques des avertissements assez clairs : « Desciré soit de truyes et porceaulx / Et puys son corps trayné en leaue du Rin / le cueur fendu decoupé par morceaulx / Qui ces heures prendra par larcin » (voir plus)
Enfin, plus récemment, la révolution française provoque des évolutions significatives dans la diffusion des connaissances, et cette ouverture à tous des données: la loi fixe maintenant l’obligation de rédiger et de diffuser au public les comptes rendus des séances d’assemblées.
Qu’il s’agisse de processus de démocratisation, ou simplement d’outil de rayonnement culturel, on voit donc que la question du libre accès à l’information ne date pas de l’ère de l’informatique.
Image générée par Midjourney: A picture of an antic roman library, with people dressed in toga. There is several modern objects like computers and screens on tables.
L’Open Data : Une Conséquence Logique
L’open data est une extension naturelle de la culture open source. Cependant, comme nous l’avons déjà présenté dans notre premier article, l’Open Data est un concept qui repose sur la mise à disposition libre et gratuite de données, afin de permettre leur consultation, leur réutilisation, leur partage. Elle repose sur des principes similaires à ceux de l’open source, à savoir la transparence, la collaboration et le partage.
L’open data présente de nombreux avantages. Il favorise la transparence gouvernementale en rendant les données gouvernementales accessibles au public. Cela renforce la responsabilité des gouvernements envers leurs citoyens. De plus, l’open data stimule l’innovation en permettant aux entreprises et aux développeurs de créer de nouvelles applications et solutions basées sur ces données.
Par exemple, de nombreuses villes publient des données ouvertes sur les transports en commun. Cela a permis le développement d’applications de suivi des horaires de bus en temps réel et d’autres outils qui améliorent la vie quotidienne des citoyens.
En conclusion, la culture de l’Open Source repose sur des principes de transparence, de collaboration et de partage. Tout cela a permis la création de logiciels de haute qualité et l’innovation continue. L’open data, en tant qu’extension de cette culture, renforce la transparence, l’innovation et la responsabilité gouvernementale en permettant un accès libre aux données publiques et privées. Ensemble, l’open source et l’open data façonnent un monde numérique plus ouvert, collaboratif. Par conséquent, cette culture est quasi omniprésente de nos jours, en 2022, selon un rapport Red Hat. 82 % sont plus susceptibles de sélectionner un fournisseur qui contribue à la communauté open source. De plus, 80 % prévoient d’augmenter leur utilisation de logiciels open source d’entreprise pour les technologies émergentes.
Merci d’avoir pris le temps de lire ce second article de notre trilogie consacrée à l’open data. Retrouvez-nous prochainement pour le dernier tome, consacré aux modes opératoires et aux bonnes pratiques de la publication de données en open data.