Ces dernières années, lorsque nous parlons d’API, nous revenons, systématiquement, sur les concepts d’interfaces REST, un des paradigmes permettant de mettre en pratique une démarche API.
N’existe-t-il donc que des API REST ? Est-il indispensable, pour mener une politique d’API, de faire référence aux architectures REST ?
La réponse théorique et celle pratique différent, et pour cela nous vous proposons d’analyser les deux points de vue :
La théorie : bien sûr que non
Nous pouvons définir l’API comme un moyen d’échange permettant, par le biais de technologies web, d’exposer des services, apportant une réponse à son utilisateur d’une façon synchrone.
REST, quand à elle, est une architecture logicielle basée sur le HTTP et qui propose de concevoir et d’exposer des services, en exploitant pleinement le potentiel de ce protocole.
Donc nous avons bien le dualisme :
API est l’objectif, le QUOI
REST est le COMMENT, l’architecture logicielle sur laquelle nous pouvons nous appuyer
REST est ainsi un des socles sur lequel nous pouvons définir notre politique API mais qui ne se résume qu’à un moyen. Moyen qui n’est pas forcément exclusif.
La pratique: non mais…
La pratique est différente, pas forcément discordante mais arrondit les dissemblances entre les deux notions.
Le REST est, à ce jour, l’architecture logicielle qui satisfait le mieux les objectifs d’une démarche API, dont le principal est le rapprochement entre besoin client et informations nécessaires à le satisfaire. Nous allons alimenter cette hypothèse en utilisant la notion de DATA et donc élargir la description de l’API en prenant en considération son lien très intime avec la donnée.
Dans l’objectif de marier ce binôme, nous allons analyser, comme contre-exemple, le modèle SOAP. Sans vouloir rentrer dans l’éternel débat de SOAP vs REST, nous allons comparer ces deux concepts, en nous focalisant sur leur interaction avec la donnée.
Une interface SOAP est surtout conçue avec un objectif d’action, de méthode, alors qu’un service REST, si bien architecturé, effectue ses opérations sur une ressource. Le service REST manipule ainsi une entité métier définie. Bien que les deux concepts puissent être considérés comme étant similaires, la réalité est fortement différente. Prenons par exemple la réservation d’un voyage :
En SOAP nous créons une méthode appelée « reserverVoyage ». Ici nous ne savons pas comment va être formalisé, en termes de données, la réservation, nous savons uniquement que nous effectuons une action de réservation
En REST nous allons manipuler la ressource « réservation ». Ici nous modifions, avec un verbe de type PUT, une entité métier « réservation », qui est identifié en termes de données et d’attributs, deux concepts portés par l’API
Le choix de manipuler directement la donnée, au niveau de l’API REST, permet de mener une réflexion complète, qui descend jusqu’à la modélisation de la donnée, modélisation qui devient facilement lisible au niveau des APIs. Rappelons-nous ! Un système d’information est essentiellement un écosystème qui transforme de la donnée.
Théorie ou pratique ?
Une API doit être conçue en partant de son objectif primaire : manipuler la donnée, en ouvrant sur les possibles actions que l’utilisateur / l’application cliente peut effectuer pour tirer et / ou apporter de la valeur.
C’est là ou le REST et l’API se rejoignent et, à aujourd’hui, se lient dans un objectif commun.
Le REST est à ce jour la solution sur laquelle se base la stratégie API car ce paradigme architectural incarne complètement les concepts d’API, en attendant de voir si le GraphQL tiendra ses promesses…
IoT – Un marché à conquérir mais pour quels usages ?
IoT - Un marché à conquérir mais pour quels usages ?
En 2018, le marché de l’IoT comptait près de 35 milliards d’objets. En 2021, les cabinets et analystes stratégiques prévoient un marché de plus de 50 milliards d’objets, plus de 6 objets par individu pour un chiffre d’affaires dépassant les 1 900 milliards de dollars.
En 2018, le marché de l’IoT comptait près de 35 milliards d’objets. En 2021, les cabinets et analystes stratégiques prévoient un marché de plus de 50 milliards d’objets, plus de 6 objets par individu pour un chiffre d’affaires dépassant les 1 900 milliards de dollars. L’internet des objets (#IoT) est au sommet de sa #HypeCurve et la tendance va s’accélérer.
Mais qu’en est-il réellement en 2019 sur le terrain ? Comment le marché de l’IoT est-il structuré ? Est-il mature ? Des modèles d’architecture se dégagent-ils ? Comment en tirer profit au maximum ? Comment assurer la gouvernance d’une telle transformation ?
Pour apporter des premiers éléments de réponse à ces interrogations, et plus encore, nous vous proposons une série de trois articles 360° de l’IoT vous permettant d’appréhender cette technologie qui fait tant parler d’elle.
Dans ce premier volet, nous allons démarrer en douceur avec une définition de l’IoT et une présentation des cas d’usages phares adressés.
L’IoT, c’est quoi ?
Commençons par un petit zeste de sémantique…
Un objet connecté est un dispositif muni :
d’un ou plusieurs capteurs qui lui permettent de récupérer des informations de son environnement,
d’un peu de puissance de calcul et de mémoire afin de traiter les données,
d’une connectivité afin de les transmettre.
L’IoT représente l’interaction de plusieurs objets connectés vers un emplacement commun qui traite et analyse les données afin de les restituer avec une valeur ajoutée. Cette brique technique est appelée #Plateforme IoT. Elle fait le lien entre le monde extérieur (objets connectés, réseaux) et le SI interne de l’entreprise.
Par définition, l’IoT permet de connecter les objets “traditionnels” du terrain et d’y ajouter des services innovants en surfant sur le développement fulgurant des composants (capteurs, puces…). Les objectifs principaux étant naturellement d’élargir son catalogue d’offres, de capter de nouveaux marchés et de développer ses sources de revenus.
La démocratisation des objets connectés…
production en masse des composants induisant une baisse de leur coût,
miniaturisation des composants permettant de les intégrer facilement dans les objets sans impacter le form factor (design, forme, dimension de l’objet),
développement des technologies de connectivités adaptées,
progrès importants sur l’autonomie des objets.
… et les progrès technologiques…
banalisation des architectures distribuées,
augmentation des capacités et diminution des coûts de stockage,
perfectionnement des traitements temps réel.
… ont rendu l’IoT accessible à tous !
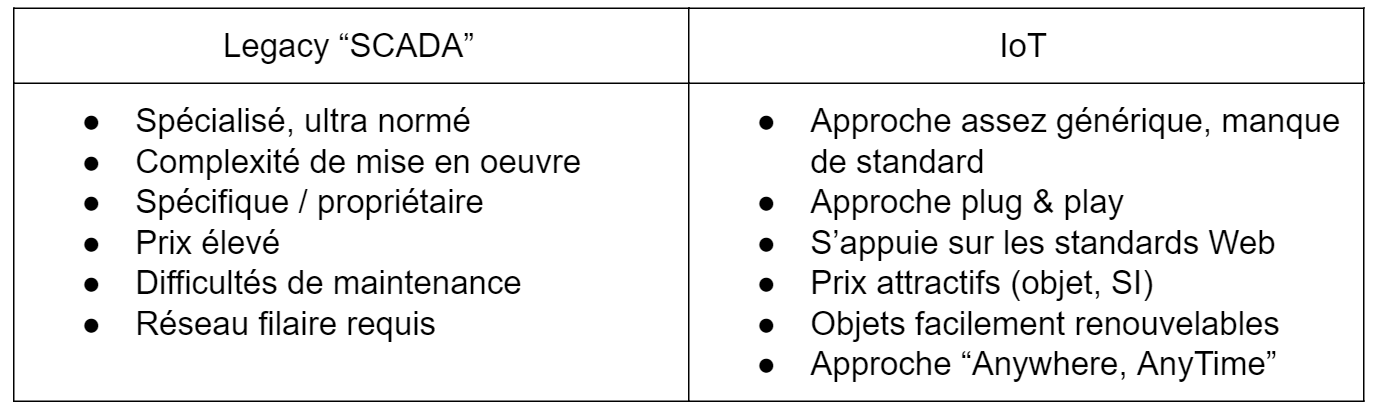
C’est très bien, je récolte des données de mon environnement que je transmets pour les traiter… rien de bien novateur jusque là me direz-vous “Je le fais depuis 50 ans dans mon système de maintenance industriel SCADA (Supervisory Control And Data Acquisition)” et vous auriez raison…
Enfin presque…
Bien qu’elle ne soit pas novatrice sur le principe, la récolte de données permise par l’IoT dispose de nombreux avantages qui rendent la technologie très intéressante comparée à son aînée :
La flexibilité offerte par l’IoT, tant sur les objets que sur les réseaux disponibles, lui permet d’être déployé sur un terrain de jeu bien plus vaste !
Les cas d’usage phares adressés
Maintenant que nous sommes tous alignés sur les principes de la technologies IoT, parcourons quelques domaines d’activités dans lesquels l’IoT est et/ou sera déterminante.
IoT et industrie 4.0
Très consommateur en données IoT, le secteur industriel exploite cette technologie sur toutes les strates de son écosystème, en voici quelques exemples concrets.
Sur la chaîne de production tout d’abord où l’on retrouve des cas d’usages tels que l’optimisation de la synchronisation des chaînes d’assemblage, l’efficacité énergétique pour diminuer la consommation ou encore accentuer la productivité tout en réduisant les coûts.
Également, sur la logistique dans le but de faciliter la préparation des commandes en réduisant le délai de préparation de celles-ci, améliorer la traçabilité des produits, sécuriser le circuit fournisseurs…
Puis dans l’optimisation des processus et actes de maintenance avec une approche plus prédictive que curative, une réactivité accrue avec des interventions terrain plus ciblées et mieux préparées pour en réduire le coût ainsi que le temps d’interruption.
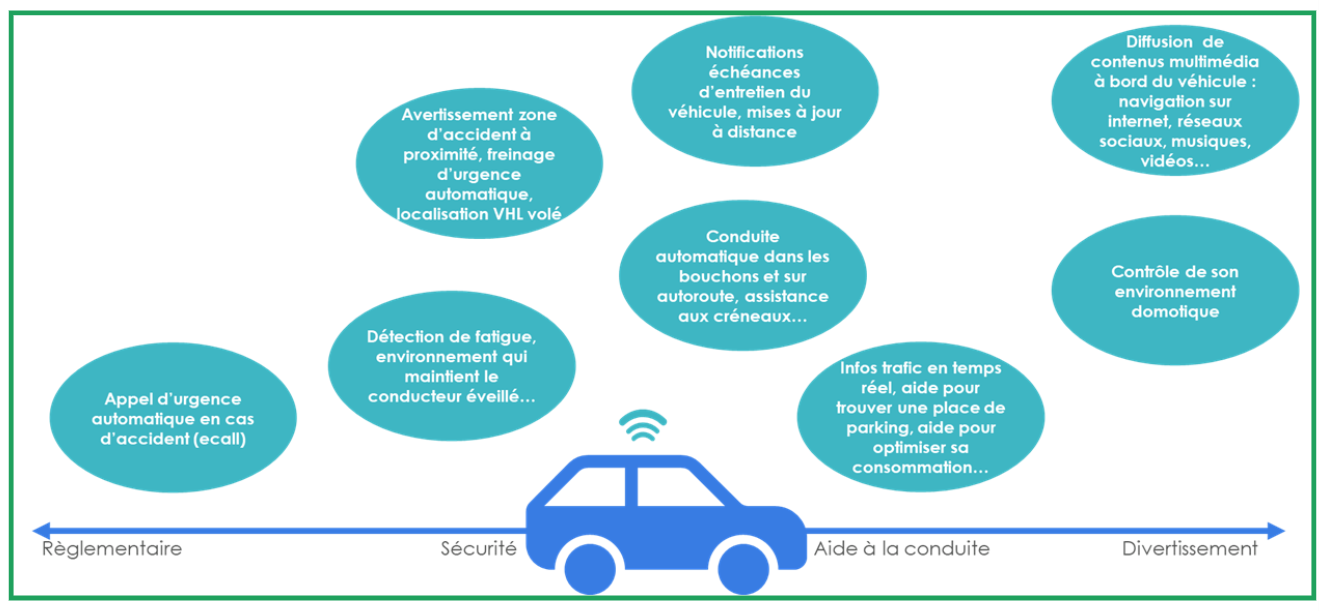
Véhicule connecté : en route vers la servicisation du véhicule
L’industrie automobile est un fervent défenseur de l’IoT avec en ligne de mire le développement du “véhicule tout autonome”. Les technologies IoT permettent d’adresser toutes les thématiques de la chaîne : du réglementaire, à la sécurité, l’aide à la conduite et jusqu’ au divertissement des utilisateurs :
Des infrastructures civiles toujours plus connectées #smartbuilding et #smartcity
Les possibilités offertes par la démocratisation de l’IoT l’invite tout naturellement dans notre quotidien. Nous sommes connectés via nos objets personnels, nos habitations et notre environnement (commerces, moyens de transports, lieux de travail, infrastructures publiques, etc.). Pouvoir associer, interconnecter et exploiter les données croisées de toutes ces sources est l’une des promesses du #SmartCity. Pour accompagner cette transition, les grands acteurs de l’immobilier se sont mobilisés, il est estimé par la #Smart Building Alliance que d’ici 2020 tous les immeubles seront a minima #R2C (Ready To Connect) voir #R2S (Ready To Services). Les promesses sont nombreuses en terme de sécurité des personnes et de l’environnement, efficience énergétique, fluidification du trafic…
Bien entendu, les domaines d’activités concernés par l’IoT sont bien plus nombreux.
Les secteurs du Transport ou de l’Énergie, non cités plus haut, se transforment également très activement autour des possibilités offertes par l’IoT.
Les cas d’usages IoT ne sont limités que par les barrières que nous leurs donnons. Laissez libre court à votre imagination pour identifier les solutions IoT qui font sens pour vous, avec à la clef, un nouveau marché vecteur de valeur.
Dans le prochain article, nous vous parlerons du marché de l’IoT à travers un panorama des forces en présence sur toute la chaîne de valeur, depuis l’objet jusqu’ à la plateforme.
Un dernier volet sera quand à lui consacré aux promesses de l’IoT mais aussi les principaux points d’attention à adresser pour le succès de cette transformation.
Et vous quels sont vos usages de l’IoT ?
Nous vous donnons rendez-vous très vite pour la suite de nos articles #IoT. Stay tuned !
Je découvre un article du 2 Juillet 2019 dans le journal le Parisien, un court article intitulé « L’architecte doit établir un budget juste ». Je n’ai pas pu m’empêcher d’établir le parallèle avec notre métier d’architectes d’entreprise.
« Si vous faites appel à un architecte pour une rénovation immobilière, il est tenu d’établir une prévision exacte du coût de l’opération. C’est ce que vient de déclarer la Cour de cassation dans une affaire où un architecte avait sous-évalué le projet. Il a « failli à son devoir de conseil », ont expliqué les juges. Précédemment, la cour d’appel avait déclaré qu’un dépassement « de l’ordre de 10 % » était admissible. Mais en l’espèce, l’architecte avait fixé un budget de rénovation inférieur de 15 à 25 % au coût habituel, « standard », c’est-à-dire qu’il avait prévu un coût de moins de 900 € par mètre carré au lieu du ratio standard qui est de 1?000 à 1?100 €.
De plus, cette estimation ne comprenait pas les finitions. Résultat : le coût total avait quasiment doublé le coût estimé. La justice a au contraire souligné la responsabilité de ce professionnel qui aurait dû se renseigner sur les souhaits et possibilités financières de ses clients pour faire une évaluation exacte.
Il a été condamné à prendre en charge le dépassement, à titre de dommages-intérêts pour ses clients. »
Stick to standards
Premier reproche à l’architecte : ne pas avoir respecté les standards connus d’évaluation de son métier. Dans les métiers de l’informatique, ce n’est pas l’architecte mais le chef de projet qui fait le devis. Et il existe aussi des méthodes d’estimation des projets (points de fonction etc.) qui sont utilisées dans les entreprises. Surtout dans nos métiers, la décision ne se prend jamais seul, les évaluations sont souvent challengées par plusieurs personnes pour arriver à des devis proches de la réalité. Et dans le doute, on se raccroche à des projets déjà réalisés ou des métriques connues. Doit on afficher ou faire connaitre les standards de nos métiers ?
Comply or explain
2ème reproche : si l’architecte s’écarte des standards il a le devoir de justifier cet écart. Un des principes de construction de l’IT est « comply or explain ». Si vous n’êtes pas conformes, vous allez devoir expliquer pourquoi. Ce n’est pas interdit de sortir du cadre fixé, mais il faut alors le justifier, ce qui a manqué à l’architecte mis en cause dans l’article. Le fait de travailler à plusieurs force les échanges et donc les explications.
Quel périmètre pour évaluer le projet ?
3ème reproche : il avait oublié les finitions dans son évaluation. Ne pas bien évaluer le périmètre et ne pas l’expliciter fait bien partie des missions de l’architecte envers ses clients. L’architecte fait les plans de la transformation et doit donc bien expliquer son devis et ce qui est compris dedans ou pas. Dans nos métiers et projets, il s’agit de se mettre d’accord sur la reprise des données, la mise à jour des interfaces etc. Un credo : toujours expliquer ce qui va être fait mais aussi ce qui ne sera pas fait.
Le budget du client
Dans l’explication de la condamnation, le jugement précise que l’architecte aurait dû se renseigner sur les souhaits et possibilités financières de ces clients pour établir une évaluation exacte. Effectivement, c’est un créneau essentiel dans nos métiers. On peut rêver mais « nous avons toujours plus d’idées que de budget ou de capacité à faire ». Bien expliquer où doivent se concentrer les investissements et pourquoi. Quelle valeur va être retirée des investissements prévus.
Conclusion
Le jugement ne fait que reprendre des arguments qui relèvent du bon sens :
Justifier ses décisions et donc ses devis
Bien valider avec le client ses attentes et ses possibilités financières
Respecter les standards du métier ou expliquer les écarts
Bien décrire le périmètre du devis
Ne jamais être seul en charge des évaluations, toujours avoir quelqu’un avec qui partager / échanger
Gageons que ce rappel des bonnes pratiques ne concerne qu’une minorité de professionnels.
Tels des escadrons de cavaliers des temps modernes, les cellules PMO assistent les Dirigeants et directeurs comme le faisait en son temps les aides de camp de Napoléon et de ses maréchaux. Le contexte et les conditions ont évolué mais les exigences de visibilité et de coordination entre objectifs, ressources et contingences restent d’actualité.
De longue date, nous savons que les directions œuvrent à la transformation de l’entreprise en anticipant plus qu’en réagissant aux menaces et opportunités qu’elles rencontrent. Pour ce faire, elles gèrent leurs activités d’exploitation et d’investissement pour créer de la valeur. Les attentes sont distribuées dans toutes l’organisation (à la fois verticalement et horizontalement). Historiquement les directeurs de programmes dans les directions SI et plus récemment les directions métiers, ont mis en œuvre et développé les techniques et pratiques de Gestion de Portefeuille Projets. Chacun, à son niveau, y recherche des moyens d’optimiser ses ressources avec le souci d’obtenir la valeur et plus classiquement de satisfaire les intérêts de l’entreprise.
Un rôle déterminant pour les organisations
Plus aucun secteur d’activité économique n’est exempté de devoir gérer et maîtriser finement ses finances et l’utilisation de ses ressources. L’optimisation de l’allocation des investissements implique une attention toute particulière sur l’alignement stratégique du portefeuille de projets. Issue de ces investissements, le portefeuille de projets exige à son tour un pilotage pour évaluer son contenu. Ici, il n’est plus question de contraindre les chefs de projets à se conformer à un travail administratif, mais de leur fournir les outils à même de les aider à concrétiser la valeur du travail de leurs équipes et en apporter la visibilité à leurs responsables.
La responsabilité de la cellule PMO est à la fois d’analyser et de surveiller la matérialisation de la valeur des engagements pris par les projets. Il importe pour l’entreprise de la pérenniser en formalisant et en aidant la direction à décider à partir d’éléments factuels et qualitatifs via le pilotage dans le temps de la valeur du portefeuille des projets.
Quel que soit le niveau de rattachement de la cellule PMO, elle agit au cœur d’un réseau de relations humaines. Elle est à la croisée des préoccupations des différents responsables de l’entreprise. Son influence dans les relations est à la fois directive et collaborative, toujours dans le souci de servir la stratégie de l’entreprise. Chaque cellule occupe un positionnement transverse qui lui permet d’assurer une fonction qui cumule des responsabilités d’analyse, de gouvernance, et d’administration des données du portefeuille avec ou sans outils.
Elles ont pour rôle de planifier, créer, évaluer, soumettre à arbitrage les projets/programmes dans le portefeuille et de communiquer sur les priorités du portefeuille et les informations d’état des investissements en cours. Ce positionnement vise à l’obtention de la valeur des projets. Essentiellement active dans les instances et travaux de consolidation, elles font face à des exercices d’influence qui peuvent s’apparenter à du lobbying pour maximiser les affectations des directions et ce parfois au détriment des objectifs stratégiques.
Un dispositif garantissant la bonne conduite des projets
La conduite des activités PMO comprenant la planification, le contrôle et le pilotage du portefeuille implique du responsable qu’il définisse le dispositif d’évaluation en continu de son portefeuille. Elle inclue d’Accompagner les managers et les opérationnels des projets de transformation dont ces derniers ont la responsabilité. Ces activités visent à développer les capacités de l’organisation à garantir la maîtrise des projets tout au long de leur déroulement. Ces capacités sont essentielles pour porter une vision consolidée et ordonnée du portefeuille qui permet à la fois à la direction d’agir et réagir de façon approprié, mais aussi d’atteindre un meilleur alignement stratégique avec les métiers et fonctions transverses de l’entreprise.
La cellule PMO porte également une responsabilité de performance du portefeuille face à la complexité des projets à conduire. En effet, les besoins, les contraintes, contingences et dépendances émergent de toutes parts touchant tout autant le patrimoine organisationnel que le portefeuille IT. Pour cela, il lui incombe de produire une représentation de la performance du dispositif, toujours dans la perspective de concrétiser la valeur attendue des projets. Ce travail de formalisation des pratiques à mettre en œuvre et des données à analyser participe à la rationalisation des prises de décision.
Enfin dans certaines circonstances, le dispositif peut inclure la coordination Fonctionnelle/Technique des adhérences et des dépendances qui apparaissent entre les projets.
En complément, face à la multiplication des sources de données et de leur traitement en masse, la cellule PMO dispose d’un référentiel de données stratégiques pour l’entreprise. Les solutions PPM sur le marché répondent toutes à deux enjeux que sont l’amélioration de l’efficience opérationnelle recherchée (allègement du coût d’exploitation des applications et aide à la prise de décision documentée) et l’amélioration de l’efficacité organisationnelle (partage de l’information entre les entités et directions). L’apport initial de ces solutions reste l’industrialisation des activités de gestion de projet essentiel à l’amélioration de l’engagement des projets à mener. Ces solutions ouvertes sont à même de couvrir les exigences de complétude, de qualité, de cohérence et de disponibilité des données quel que soit le modèle organisationnel mis en œuvre.
Un maillon majeur pour gérer incertitude et complexité
Dernière prérogative de la cellule PMO, œuvrer à réduire le niveau d’incertitude attaché aux projets qui compose le portefeuille. Pour cela, son positionnement transverse dans l’organisation en fait le relais idéal du développement d’une culture de la gestion des risques. Toutes les activités évoquées dans le champ de la Gestion Portefeuille Projets visent à appréhender les différentes formes d’incertitude et de complexité auxquelles les programmes et directions peuvent se trouver confrontées. Réduire l’incertitude implique à tous les acteurs de poser et d’accepter de reprendre les hypothèses pour les adapter aux circonstances rencontrées.
De son côté la complexité croissante des enjeux à servir est source de contradictions au sein de l’entreprise. Elle impose à la cellule PMO de rompre les silos organisationnels et de faire preuve d’empathie envers ses parties prenantes pour parvenir à tisser des liens entre acteurs, entités, et disciplines. C’est à elle qu’il revient de multiplier les points de vue à même de relier les idées nécessaires aux décideurs.
Après plusieurs années d’accompagnement sur ces sujets, nous avons forgé des convictions fortes dans ce domaine d’intervention :
Qu’elle rende la Gestion de Portefeuille de Projet, levier de création de valeur au service de la stratégie des entreprises.
Qu’elle soit reconnue comme un relais d’information au sein du réseau d’acteurs des directions métiers et fonctions supports de l’entreprise.
Qu’elle tienne un rôle d’acteur catalyseur des capacités de l’organisation à mener à bien ses projets et activités récurrentes dans un cadre de travail connu de tous.
Qu’elle devienne le référent de l’expérience des projets métiers et technique en ce qui concerne la masse de données issues de sources multiples à traiter pour piloter les projets.
Enfin, qu’elle est un agent responsabilisant les acteurs de l’organisation dans la gestion des risques à même de réduire l’incertitude intrinsèque à toutes activités entrepreneuriales et de transformation.
Son crédo en somme : « Bien faire le travail pour faire du bon travail ».
Les transformations de l’entreprise impliquent rapidement un nombre importants de directions, une multitude de collaborateurs, internes ou externes. Les dépendances entre tous ses acteurs vont croissant et sont changeantes. Comme du temps des épopées Napoléoniennes, lorsque les aides de camp sur le champ de bataille avaient un rôle déterminant dans la victoire, la GPP, est aujourd’hui une activité essentielle pour toute direction moderne.
Dans ce troisième et dernier volet de notre parcours 360° de l’IoT, nous vous proposons de porter notre regard sur les promesses de l’IoT et de nous intéresser par la même occasion aux grandes problématiques techniques et organisationnelles à adresser lors, notamment, du passage à l’industrialisation de vos expérimentations IoT.
Les promesses de L’IoT
Nous l’avons vu lors des deux précédents volets de nos publications, l’IoT est rendu accessible à tous, dans tous les secteurs d’activités et pour des cas d’usages très variés. Cependant, que puis-je en attendre? Voici quelques éléments de réponse.
Moi, entreprise
Développer des services innovants pour fidéliser mes clients et en capter de nouveaux
Générer de nouvelles sources de revenus
Me démarquer de la concurrence
Utiliser les données pour tendre vers le service sur mesure et anticiper le besoin client
Optimiser ma productivité et mes processus
Réduire mes coûts à tous les niveaux
Moi, employé
Faciliter mon travail au quotidien
Augmenter la sécurité et diminuer la pénibilité
M’aider à avoir des insights opérationnels précis
Et ainsi m’aider à me focaliser sur les activités à valeur
Réaliser du prévisionnel pour anticiper les défaillances
Me faciliter les prises de décisions
Moi, utilisateur final
Disposer d’un environnement de vie conforme à mes habitudes
Sécuriser mes biens personnels et mon mode de vie
Réaliser des économies en fonction de mes propres usages
…Et ses démons !
Un potentiel énorme, de nombreuses promesses mais des problématiques tout aussi nombreuses à prendre en considération sur l’ensemble de la chaîne de valeur IoT.
Parcourons ensemble cinq éléments clés pour la bonne réussite des transformations IoT :
L’interopérabilité au centre des enjeux
Multiplicité des acteurs et des technologies sur l’ensemble des maillons de la chaîne IoT,
Complexité liée au contexte mouvant du marché de l’IoT et le manque certain de standardisation.
Ainsi, les choix technologiques et techniques (applicatifs et infrastructures) doivent être fait avec la vision d’un écosystème global, interconnecté et interopérable.
La sécurité, une problématique globale à maîtriser
Une multitude d’objets éparpillés sur le terrain et accessibles.
De nouvelles briques techniques et autant de portes d’entrée vers le SI.
Le sujet de la sécurité est prédominant dans les problématiques IoT actuelles du fait de l’industrialisation des projets. Il convient d’aborder le spectre de la sécurité sur toutes les phases de construction (approche Security By Design) de la chaîne de valeur IoT.
La protection des données personnelles
Les nouvelles législations autour de la GDPR, des projets de lois de protection des données de Santé, etc. sont autant de freins à la valorisation de l’IoT qui a pour but premier de collecter facilement et massivement des données du terrain.
Les modèles de traitement, d’analyse, de stockage et d’exposition des données doivent tenir compte des évolutions réglementaires et être adaptés en conséquence.
Le traitement des données
L’IoT doit être considéré comme une source de données du Big Data. La flotte d’objets (hétérogènes) génère au fil de l’eau un important volume de données, à grande vitesse et avec des formats variés.
Pour donner une valeur business forte à ces données, il est nécessaire de réaliser des corrélations avec le reste du patrimoine data de l’Entreprise.
Cette dernière doit donc avoir entamée une transformation autour de la Gouvernance Data et adoptée un SI Data Centric.
La gouvernance IoT, un réel facteur clé de succès
L’IoT transforme en profondeur les métiers et les offres traditionnelles. Les changements à effectuer sont complexes et transverses nécessitant une proximité forte entre des équipes métiers et DSI, après tout, l’IoT a avant tout une finalité business !
Il convient donc à chaque entreprise, pour réussir sa transformation IoT, de définir et mettre en place une gouvernance associée qui portera les messages, réalisera la mise en oeuvre et assurera que les métiers sont formés et outillés pour exploiter ces nouveaux gisements de valeur.
Comment la définir ? quels sont ses missions concrètes ? Quels sont les bonnes pratiques ? Comment et quand intégrer le métier ? Comment…
Tous ces différents points seront étudiés, illustrés dans un article dédié à la #Gouvernance IoT.
Sur cette belle lancée, restez avec-nous 🙂
Dans quelques jours, nous vous présenterons notre approche et les clefs pour répondre rapidement et efficacement aux initiatives IoT de vos métiers.
Et vous quelles problématiques IoT rencontrez-vous ?
Nous vous donnons rendez-vous très vite pour la suite de nos articles #IoT.
Une révolution est en cours dans nos cités. Les utilisateurs délaissent les moyens mis à leurs dispositions par les conseils régionaux et les mairies pour des solutions écologiques, innovantes, souples, facturées à l’usage et dont le bénéfice est immédiat.
Toutefois, bien que pratique, cette nouvelle mode urbaine génère du stress également, comment s’adapter à ces nouveaux usages ? Certaines municipalité ont tenté de les interdire, d’autres se posent la question de la réglementation, quel est le risque pour l’usager et pour les autres usagers, doit on permettre à ces utilisateurs de consommer ces services alors que nous ne l’avions pas prévu ?
Les infrastructures actuelles ne sont pas compatibles avec ces nouveaux usages, la pression des utilisateurs est telle qu’il faut trouver des solutions palliatives pour leur permettre de les utiliser en toute sécurité.
Ces précurseurs bousculent l’ordre établi qui se voit devancé sur les problématiques de développement durable et de transport.
Quel cadre proposer pour que tout le monde y trouve son compte sans pour autant bloquer ceux qui suivent le modèle historique mais que l’on aimerait réussir à convertir aux nouveaux usages ?
Ces réflexions sont en cours à Lyon, à Bordeaux, à Paris, ainsi que dans la majorité des métropoles régionales, et les villes rurales réfléchissent à offrir ces services même si la pression et l’impact sont moins importants.
Ces questions autour des vélos et des trottinettes en libre service ont peu de rapport avec l’IT ou avec nos DSI mais elles rappellent un sujet qui revient depuis plusieurs années : le Shadow IT.
Les utilisateurs consomment des services informatiques sans en informer leur DSI, les contraintes de sécurité sont ignorées, les fournisseurs multiples, la même solution peut être consommée plusieurs fois sans qu’il n’y ait d’optimisation des coûts.
Faut-il l’interdire ? Est-ce que l’entreprise acceptera de retarder son plan de transformation, la sortie d’un nouveau produit ou pire de dégrader la satisfaction client pour respecter les exigences de l’IT ?
Les problématiques se ressemblent, les solutions sont tout aussi éclectiques et dépendent à chaque fois de l’environnement, du cadre et des besoins. L’entreprise doit aujourd’hui permettre à ses utilisateurs, à ses clients internes d’utiliser des solutions compétitives au time-to-market imbattable et correspondant à leurs besoins. Mais l’entreprise doit aussi garantir la sécurité de son SI, de ses données et de son activité.
Ces nouvelles solutions ont généralement des attributs communs, elles sont hébergées dans le cloud, ne nécessite pas d’installation et la configuration est à la portée de tous.
L’enjeu pour les sociétés, quelle que soit leur taille, est de permettre la consommation de ces nouveaux services, de faciliter leur usage dans le respect des normes de sécurité en gardant la maîtrise des coûts qu’ils induisent.
L’entreprise se voit donc imposer une transformation vers le cloud par ses clients internes, ses employés, qui se demandent pourquoi les outils qu’ils utilisent au travail sont moins performants et conviviaux que ceux qu’ils utilisent à la maison.
Quels sont les bénéfices que l’entreprise tirera de cette transformation ?
Quelles sont les étapes à respecter ?
Ce sont les thèmes que nous développerons dans nos prochains articles.