Le phénomène d’API GraphQL est en progression, aujourd’hui sommes-nous prêts à abandonner à nouveau tout ce qui a été fait sur les API ces 15 dernières années et passer à un nouveau concept d’intégration ? Le GraphQL est-il une option viable pour remplacer l’API telle que nous l’avons définie jusqu’à aujourd’hui ?
Qu’est ce que le graphql ?
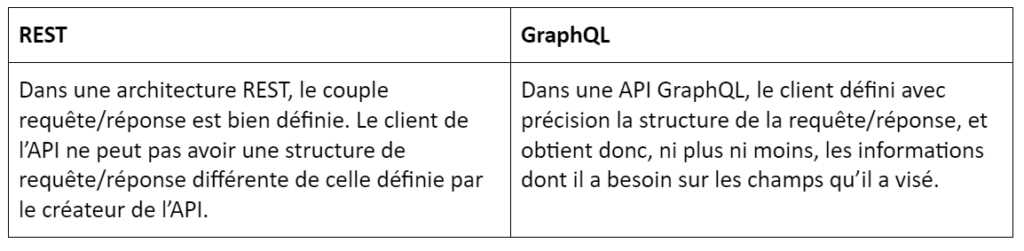
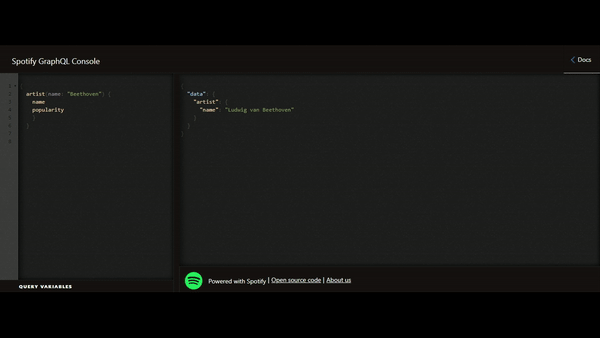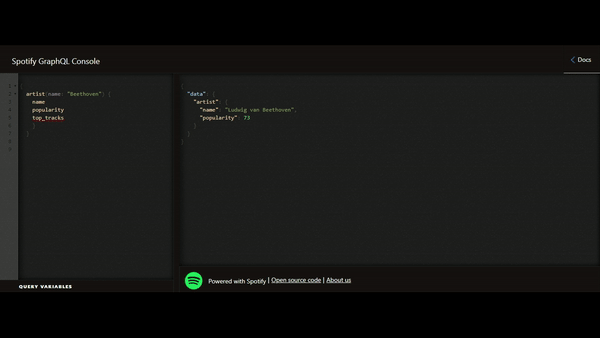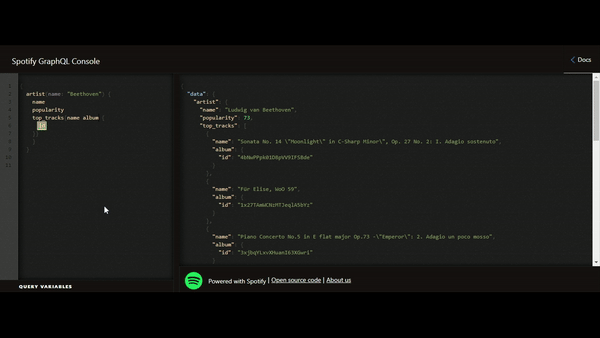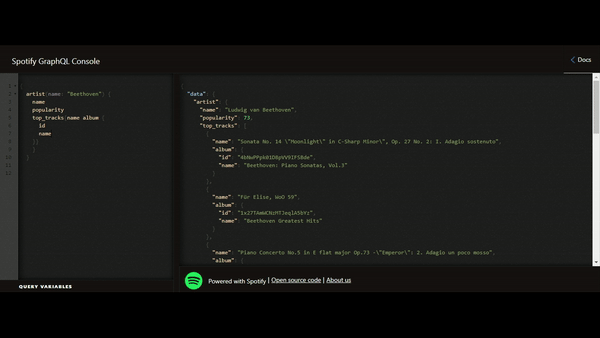
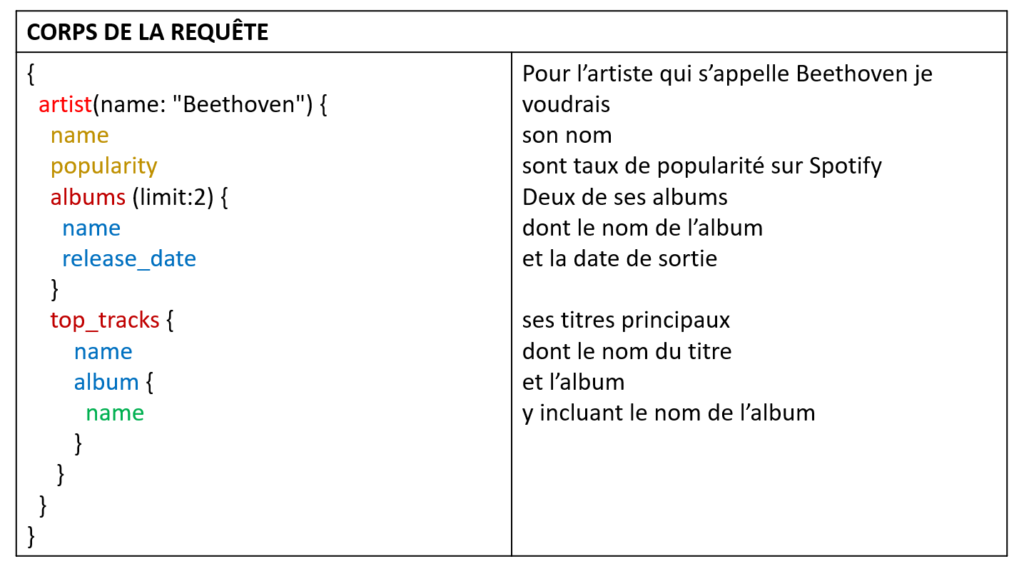
Le GraphQL se résume par la mise à disposition d’une interface de requêtage qui s’appuie sur les mêmes technologies d’intégration utilisées par les API REST. Nous allons toujours passer par le protocole HTTP et par un payload de retour, préférablement au format JSON, mais la différence pour le client repose sur le contrat d’interface.
Si nous essayons de vulgariser, les réponses apportées par le REST et le GraphQL à la même question sont fondamentalement différentes.
Analysons la question suivante : qui es-tu ?
Voici comment elle serait abordée par Rest et par le GraphQL
Le REST :
QUESTION : qui es-tu ?
REPONSE : voici ma pièce d’identité (ni plus, ni moins)
Le GraphQL
QUESTION : quels sont ton nom, prénom, date de naissance, adresse de résidence, lieu de travail et tes coordonnées personnelles ?
RÉPONSE : voici toutes ces informations ciblés (et tu peux avoir encore plus de détails si tu veux, en une seule fois)
On a affaire ici à un changement radical dans la manière d’aborder les requêtes.
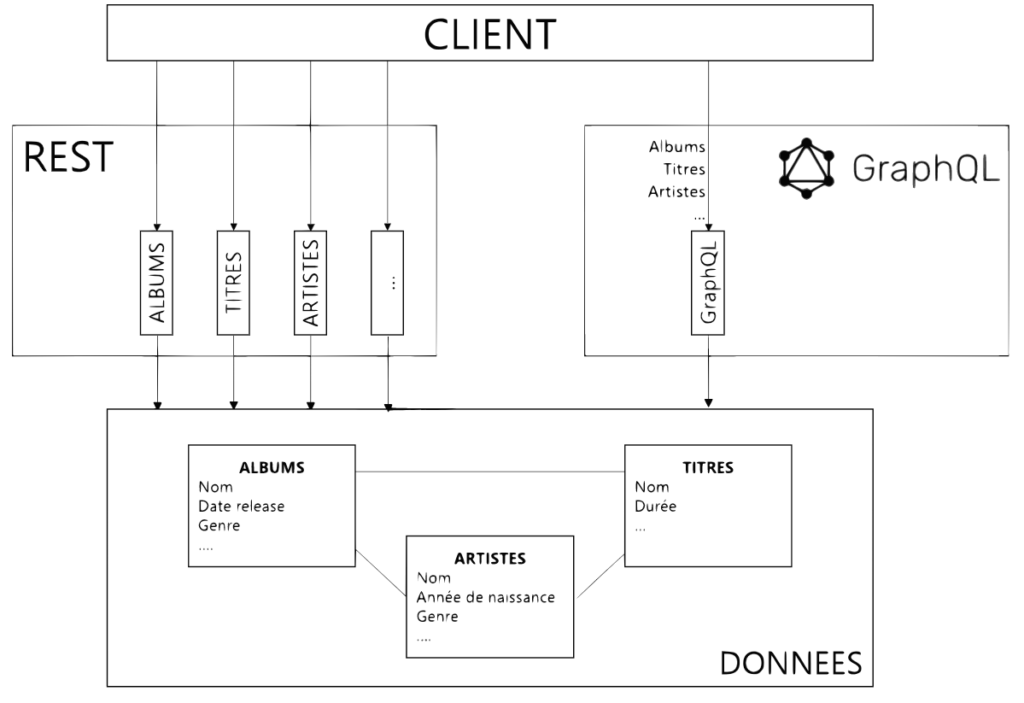
La DATA reste l’élément central de la réflexion autour du GraphQL. Sur ce point, nous pouvons voir l’héritage venant des paradigmes du REST, avec une focalisation sur la ressource. Alors que les pratiques précédentes, comme le SOAP, étaient plus axées “action”, le GraphQL est très axé sur la DATA, l’objectif primaire étant la manipulation de la donnée et pas l’exécution d’une opération.
Le concept de DATA est cependant présenté différemment. Elle n’est pas contrainte par une structure strictement définie à l’avance mais il est désormais possible de la naviguer par l’API GraphQL, ce qui change complètement le concept du contrat d’interface.
Il n’y a donc plus de contrat d’interface ?
Nous pourrions en déduire que le contrat d’interface, très cher aux démarches SOAP et REST, n’est plus d’actualité pour le GraphQL…
Notre vision se résume en une simple phrase : ”Le contrat d’interface change de forme. Il n’est plus centré sur la structure de l’information retournée par l’API mais s’intéresse au modèle de données lui-même”
Le contrat d’interface s’appuie sur le modèle de données qui devient encore plus crucial puisqu’il est maintenant directement exposé / connu par les clients de l’API. Pour rappel, nous avons défini le GraphQL comme un langage de requêtage qui s’appuie sur la structure de la donnée définie dans notre schéma de modélisation. Bien qu’une couche d’abstraction ne soit pas totalement à exclure, le modèle de données, défini dans nos bases de données et exposé aux clients (par introspection ou connaissance directe), devient le point de départ de toute requête.
Cela saute aux yeux, la flexibilité est le grand avantage apporté par le GraphQL. Nous ne sommes plus contraints par le retour de données défini par le fournisseur de l’API mais uniquement par la donnée qui nous est mise à disposition. Cela permet de réduire le phénomène de l’underfetching (obligation d’utiliser plusieurs appels car un seul ne permet pas de remonter la totalité des informations nécessaires) et de l’overfetching (récupération de plus de données par rapport au besoin réel), vrais casse-têtes lors de la conception des APIs.
L’autre vrai avantage est la rapidité de mise en œuvre. Sans vouloir rentrer dans la réalisation, la mise à disposition d’une API classique a toujours comporté des longues périodes de réflexion sur le périmètre, le découpage, la profondeur des données retournées. Ces phases de réflexion qui, sans un besoin clair en face, avaient tendance à se prolonger et à réduire le Time-To-Market des APIs. GraphQL permet de pallier ces problèmes :
En libérant le fournisseur de l’API de cette lourde tâche de conception,
En évitant la multiplication des APIs sur le même périmètre,
En facilitant le choix du périmètre de la part du consommateur, sans qu’il soit forcément obligé d’orchestrer plusieurs requêtes afin obtenir ce dont il a besoin, sans limites théoriques.
…mais aussi des contraintes
La liberté donnée au client de l’API est certainement un avantage pour les deux parties mais apporte également des contraintes de sécurisation et de gestion de la charge serveur.
La charge
Une API, REST ou SOAP, est globalement maîtrisée. Elle a un périmètre bien défini et donc la seule question à se poser porte sur la volumétrie et/ou la fréquence d’appel. Le GraphQL, par le fait que les requêtes sont variables, réduit la prévisibilité de la charge associée :
La non-prédictibilité des requêtes expose au risque de retours complexes et volumineux, sans pagination, ce qui pourrait mettre en difficulté une infrastructure mal dimensionnée ;
L’utilisation du cache est complètement révolutionnée / complexifiée, car la probabilité d’avoir la même requête de deux différents consommateurs est très faible et ne permet donc pas de s’appuyer complètement sur le cache pour décharger les machines.
La sécurité
Dans l’ancienne conception nous pouvions avoir des niveaux de sécurité induits par le périmètre restreint de l’API.
Le GraphQL, de par la liberté d’exploration des données, oblige à une réflexion plus profonde sur la question des habilitations et de l’accès aux informations. Cette sécurisation doit être garantie par une sorte de “douane” qui se définie comme la couche par laquelle nous devons transiter pour accéder aux données, et qui gère directement les droits d’accès par utilisateur.
Cette pratique n’est pas nouvelle, elle devrait accompagner toute démarche API, toutes technologies confondues. La couche de sécurisation et d’habilitations devrait toujours être indépendante de l’exposition de l’API. Parfois, un défaut de conception non identifié de cette couche de sécurité était pallié, tant bien que mal, par la limitation de périmètre imposé par l’API or cette limitation n’existe plus avec le GraphQL.
Conclusion
GraphQL représente la tentative la plus intéressante de “flexibiliser” la gestion des APIs et apporte une nouvelle dynamique à celle-ci, tout en respectant les contraintes induites par ce mode d’intégration.
Si l’objectif n’est pas forcément de “tout casser”, pour recommencer tout en GraphQL, cette approche devient une alternative concrète aux démarches API dites “classiques”.Exemple en est la mise en application de cette méthode d’intégration sur une plateforme de paiement, Braintree, filiale de Paypal.
Le marché du Serverless ou FaaS a bondi de manière importante en 2018, porté entre autres par la popularité grandissante de AWS Lambda, Azure Functions ou de Google Cloud Functions. Mais en quoi consiste une architecture Serverless ? Cela consiste à exécuter des fonctions sur le cloud sans se soucier de la conception de l’architecture technique et du provisionnement de serveurs. La facturation de ce type de service étant basée sur le temps que le traitement aura mis pour s’exécuter. Il y a donc toujours besoin de serveurs mais la conception et la gestion de ceux-ci sera réalisée à 100% par le fournisseur Cloud.
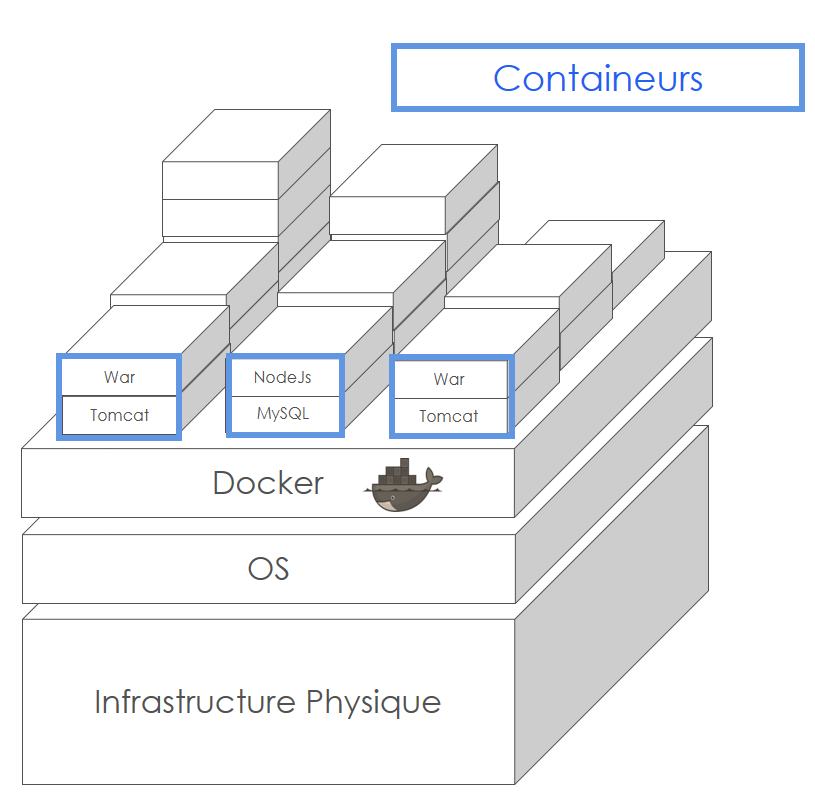
La différence avec une architecture basée sur des containers ?
La containérisation reprend les concepts de la virtualisation mais ajoute de la souplesse.
Un container est un sous-système pré-configuré par le biais d’une image. Celle-ci définit ce que le conteneur embarque à sa création (serveur d’application, application, etc.), normalement le minimum indispensable pour votre application (fonction ou micro-service).
Le Serverless est une architecture qui repose sur un concept simple : l’abstraction complète des ressources machine.
Il vous suffira par exemple d’avoir un compte AWS, cliquer “Create function” depuis la console, configurer quelques paramètres techniques comme la taille de la mémoire allouée et le temps de timeout maximum toléré, copier votre code et voilà !
Avantages et inconvénients
Le principal avantage de ce type d’architecture est le coût. Vous ne paierez que ce vous utiliserez basé sur des métriques à la seconde. Plus besoin de louer des ressources comme des machines virtuelles que vous n’utilisiez jamais à 100% ou de payer un nombre d’utilisateurs qui n’étaient pas connectés en permanence dans l’outil. Par exemple pour une fonction AWS Lambda à laquelle vous aurez attribué 128 Mo de mémoire et que vous prévoyez d’exécuter 30 millions de fois en un mois (pour une durée de 200 ms par exécution), vos frais ne seront que 10€/mois environ ! Si cela correspond à un pic saisonnier atteint en période de solde et que la moyenne d’exécution correspondra à la moitié de cette charge vous ne paierez que ce que vous aurez consommé. À titre de comparaison, un serveur virtuel de 1 coeur et 2 Go de RAM facturé au mois sera facturé 12€/mois, peu importe la charge. Et si un serveur de ce type ne suffisait pas, il faudra prévoir le coût d’une plus grosse instance ou d’une deuxième. Il est donc évident que le FaaS permet d’optimiser vos coûts par rapport à du IaaS ou du PaaS.
Le second avantage est qu’il n’y a pas besoin de gérer et maintenir l’infrastructure. Vous n’arrivez pas sur vos projets Agiles à anticiper vos besoins d’infrastructure ? Vous pensez qu’attendre 1 jour pour avoir une machine virtuelle c’est encore trop long ? Vous trouvez bien le principe des microservices mais vous trouvez compliqué de gérer une architecture technique distribuée ? Une architecture Serverless ou FaaS vous simplifiera la vie de ce point de vue.
Il y a cependant des désavantages. Les AWS Lambda et Azure Functions sont des technologies propriétaires qui vous rendront complètement dépendant de votre fournisseur. Si un jour vous désirez migrer sur une autre plateforme, il vous faudra revoir le code de votre application notamment si celui-ci fait appel à des services ou infrastructure propre à ce fournisseur (lire un fichier dans un container S3 par exemple ne sera pas de la même façon que de le lire sur un Azure Blob). L’autre point important aussi à surveiller est que ces services sont bridés en termes de ressources et ne conviendront donc pas pour des applications nécessitant des performances élevées.
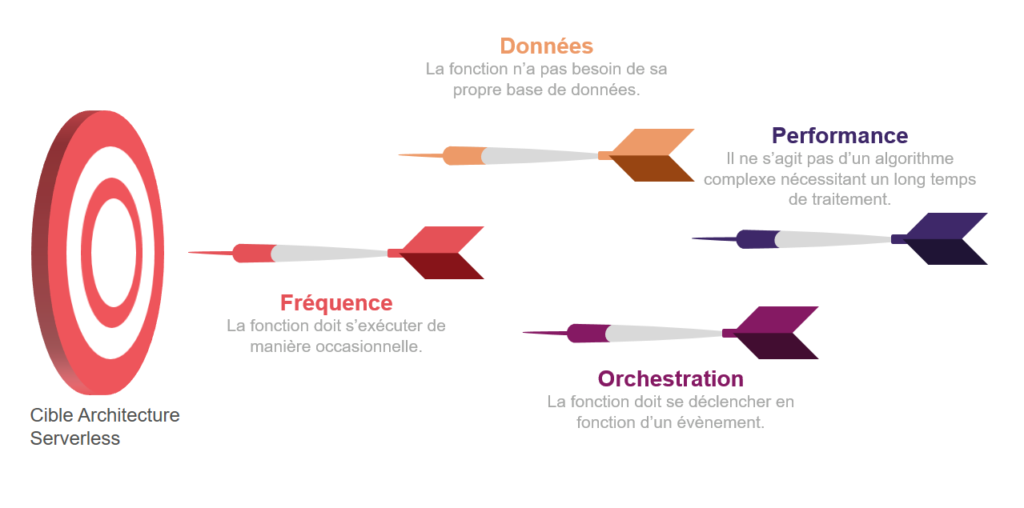
Pour quels cas d’usage ?
Une architecture Serverless peut convenir lorsque les critères suivants sont réunis :
Cela peut être par exemple :
Le lancement d’une requête comme l’appel d’une API pour récupérer les données de météo et les déposer dans la base de données utilisée par une application mobile.
L’envoi de notification par messagerie pour prévenir un groupe d’utilisateurs d’un événement.
Le transfert et la vérification du format de fichiers multimédias pour un site permettant à des photographes de partager leur travail.
En résumé, il s’agit d’une nouvelle façon de concevoir votre architecture solution, pouvant vous permettre de réaliser des économies importantes mais qui vous rendra plus dépendant du fournisseur Cloud que vous aurez retenu.
En cette période de crise épidémiologique et de confinement, les approches PPM apportent chacune leurs qualités pour affronter les risques. Mais comment se distinguent-elles ?
Risque, incertitude, responsabilité : des visions distinctes selon deux approches
Les circonstances de la crise sanitaire actuelle, sont une occasion pour nous, professionnels des projets, d’être interpellés sur la dimension gestion des risques qui nous est essentielle. Comment est-elle appréhendée selon les approches Traditionnelle et Agile de gestion de produits, de projets et de portefeuilles ? En quoi ces approches sont différentes l’une de l’autre ?
Que l’on fasse cette observation au niveau opérationnel des projets ou au niveau de la supervision du portefeuille des projets, on constate que leurs notions « d’incertitude », de « risque », et de « responsabilité » les déterminent et les distinguent à la fois.
Que l’on parle d’une approche cycle en V, Cascade ou Stage/Gate applicable aux projets elles sont rattachées à une vision traditionnelle de la gestion qui se caractérise par une forte exigence d’anticipation des événements par la planification et le contrôle. A contrario, l’approche Agile est par définition une réponse à l’incertitude grandissante à laquelle font face les projets et portefeuilles de projets. Pour y parvenir, parmi les principes inscrits dans le manifeste Agile, on retrouve l’adaptation par rapport au plan et l’autonomie de décision. Cette posture d’adaptation aux circonstances implique celle de l’aptitude à agir en réaction aux événements et changements qui surviennent dans le déroulement des projets et des produits. Mais, face à la crise sanitaire du Covid-19 et à ses implications à la fois économiques, politiques et sociales que proposeraient ces approches en termes de traitement des risques ? La probabilité de la mise à l’arrêt de la société civile est allée grandissante en moins de deux mois, jusqu’à devenir une réalité aujourd’hui.
Un modèle du risque proactif ou réactif pour y remédier
Si nous sommes tous familiers avec la définition et les modalités classiques de gestion des risques, ce sont les divergences de considération de ce processus de gestion selon ces deux approches qu’il est intéressant d’analyser.
Classiquement, avec l’approche traditionnelle, l’identification, la qualification et la réduction des risques participent de la planification et du pilotage des projets et portefeuilles. Il est essentiel de s’appuyer sur une base de risques déjà identifiée et d’une taxonomie des risques la plus ouverte possible tout en étant spécifique à l’activité de l’entreprise. L’expérience vécue par la Chine et observée pendant les premières semaines de l’année a pu servir de référence à de nombreux chefs de projets pour deux raisons. Elle a relevé progressivement la probabilité de l’épidémie à son niveau maximum pour devenir la réalité que l’on connait. Mais, elle a aussi servi de modèle pour figurer et projeter les impacts de son expansion à un point que personne n’avait encore imaginé. La maturité de chacun face aux risques a donc permis d’atténuer les effets de la criticité de ceux identifiés à mesure que l’épidémie prenait place. Les plans de charge des projets et des portefeuilles ont été révisés et les calendriers aussi.
Pour ce qui est de l’approche Agile, la notion de risque est plus difficile à isoler, puisque son esprit pousse à la réactivité face aux événements. Sans intention d’anticipation dans les projets et les portefeuilles et la continuité de services des équipes produits, le parti pris est celui de traiter des problèmes par l’adaptation des méthodes et des livrables au fil des itérations sans que cela n’en dégrade la qualité, qui constitue son principal levier de décision. En l’absence de culture du risque, les acteurs des équipes Agile s’en remettent plus à l’intuition du groupe qu’à la raison des experts. Qu’en est-il lorsque un à un les membres de l’équipe deviennent indisponibles pour raison médicale ou privée ? Enfin les pratiques rigoureuses de cette approche se retrouvent mises à mal par la perte de l’unité de lieu des acteurs imposée par le confinement et le recours au télétravail. Le leitmotiv du « time to market » pour satisfaire le client est momentanément inaccessible.
La gestion du risque : extension de la responsabilité
La gestion des risques se définit par son exigence d’anticipation des événements pouvant faire obstacle aux objectifs visés. Pour ce faire, il faut convenir d‘hypothèses de réduction de son occurrence et de ses effets qui peuvent prendre la forme de contingences retranscrites dans la planification. Tout le travail des responsables tient à identifier, qualifier et envisager ces mesures de réduction en adéquation avec les moyens à leur disposition.
Dans le cas de l’approche classique, la responsabilité de la culture du risque est portée par la ligne managériale, puisque par délégation, il est du ressort du chef de projet de concevoir et d’animer la trajectoire du projet qui vise le résultat dans les termes annoncés au client. Cette forme de déclinaison de la prospective à l’exercice de la planification s’appuie sur la production de scénarios liés à des opportunités et à des risques auxquels des hypothèses de « survenue » sont associées. Lorsque cet exercice est entretenu tout au long des projets, il implique à son tour une révision régulière pour ajuster les hypothèses en privilégiant le levier de pilotage dominant : le temps, le budget, la valeur client. Reste qu’une telle démarche est très consommatrice de temps et se retrouve, dans les faits, incompatible avec l’accumulation des fonctions des chefs de projet. Néanmoins, dans les circonstances actuelles, la coordination des différentes activités et des prises de décisions, de plus en plus souvent réalisée à distance, ne souffre pas de la mise en place du télétravail comme solution de continuité des activités même si les contingences déterminées à l’engagement des travaux ne seront pas suffisantes.
A l’inverse, dans le cas de l’approche agile, la responsabilité est collectivisée au niveau de l’équipe. Les membres de l’équipe mis en situation d’autonomie basée sur la confiance, se retrouvent porteur chacun d’une part de responsabilité. Cette dernière intègre les considérations de l’incertitude, des évolutions de l’environnement interne et dans une moindre mesure externe. Cependant pour exercer cette responsabilité, c’est par leurs interactions en face à face que leur crédo « on fait avec et la vie continue » leur permet d’assumer et de résoudre les problèmes rencontrés. Dans les circonstances actuelles, le mode projet agile résiste bien de par sa capacité à gérer le chaos, au moins tant qu’il n’est pas rendu inopérant par trop de bouleversements.
Les 2 approches résistent à la crise
En fin de compte, aucun des deux modèles n’est pris en défaut. Si l’un privilégie l’anticipation des opportunités et obstacles à la planification en se donnant les moyens de les réduire, et si l’autre est focalisé sur la capacité à délivrer quelques soient les circonstances sans se préoccuper de prévoir des contingences. Ces deux modèles sont à même de faire face à des événements imprévus.
De son côté le Bureau des Projets compose son propre modèle de gestion de produits, de projets et de portefeuille. Historiquement géré en approche traditionnelle, il adopte quelques éléments des pratiques agiles « façon puzzle » (comme l’effort de développer l’autonomie ou la capacité à innover). Sans reprendre suffisamment les principes des approches dont il s’inspire, pour causes de manque de moyens, de temps, de conviction ou d’appui de la Direction, le bureau projet se contente de mettre en place quelques rôles, artefacts et cérémonies. Mais dans ces conditions sa transformation échoue à interpréter le changement de paradigme qu’elle recherche. Parce que, l’interprétation du traitement des risques dans toutes ses dimensions n’en deviendra ni cohérente ni complète. A qui la faute ?
Globalement, on peut donc être rassuré. Ces deux approches de gestion de projets et portefeuille projets peuvent faire face chacune à leur manière à la crise actuelle, comme les Etats le démontrent à leur niveau. La Chine a pris le parti de la planification de mesures jusqu’à effet complet. Tandis qu’en Europe et notamment en France, la résolution est préférée en réactivité aux constats avec des consignes révisées au fil des itérations de plus en plus rapide à mesure que les faits s’accélèrent.
Dans ces conditions, quel que soit l’approche choisie, il faut convenir qu’il est essentiel de développer collectivement et individuellement une culture du risque aussi légitime que le sont celles de la qualité ou de la valeur client. Elle est indispensable face à l’incertitude grandissante de nos sociétés qui perd jours après jours son insouciance.
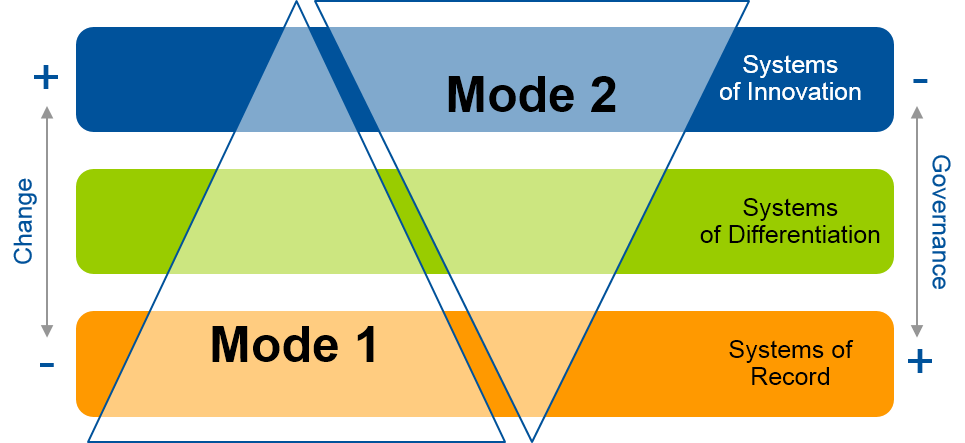
La transformation digitale mène les entreprises à rechercher un modèle de gestion de leurs portefeuilles de projets capable d’appréhender les projets « Marathon » (cycle long, cycle en V) autant que les « Sprint » (cycle court, Agile, Lean, Kanban). L’approche « Bimodal IT », introduite par le Gartner, n’a pas fini d’apporter ses réponses aux appels à l’aide des équipes de développement Agile face à un management encore traditionnel.
L’approche « Bimodal IT » pour structurer les projets marathon et les sprint …
En 2014, le Gartner avait identifié avec précision une tension cruciale provenant de la prolifération des demandes IT. Aujourd’hui plus qu’hier, les métiers ont besoin de personnalisations, d’évolutivité et d’efficacité et pas seulement de logiciels et d’applications monolithiques. Pour y répondre, le Gartner, soutien que son approche « Bimodal IT » favorise l’innovation, la transformation digitale des métiers et l’amélioration. En cela, il postule que les organisations informatiques de l’avenir œuvreront selon deux modes distincts. Le mode 1 lié à l’informatique traditionnelle, est axé sur la stabilité et l’efficacité, tandis que le mode 2 qui tient de l’organisation agile est axé sur le time-to-market, l’évolution rapide des applications et, en particulier, l’alignement étroit avec les lignes métiers. Notons que bien souvent l’organisation agile demeure expérimentale pour beaucoup d’entreprises.
… mais comment gouverner un portefeuille constitué de projets si différents ?
En cinq ans, le monde anglosaxon de la gestion de projet a donc résolu la cohabitation des approches cycle en V et cycle agile avec le concept de Bimodal IT. Cependant, l’extension de l’approche à la gestion de programme et de portefeuille de projets est très peu débattue. Est-ce par méconnaissance ou refus de la nouveauté ? Ou parce que cette cohabitation des modèles marathon et sprint est déjà pleinement résolue dans les organisations ? Je vous invite à corriger cette lacune en vous livrant ce qu’il faut en connaitre.
Avec la Transformation Numérique nous sommes entrés dans une période transitoire qui nous conduit à gérer des portefeuilles de projets hybrides (IT traditionnelle / IT digitale). Si de plus en plus les projets IT sont animés en équipes Agile, il n’en est rien des programmes et des portefeuilles de projets toujours gérés selon le modèle classique de pilotage. Aujourd’hui ce modèle n’est plus en capacité de répondre au phénomène d’hybridation des portefeuilles de projets. L’objet et le rythme des activités de transformation des SI n’est plus conciliable avec les pratiques conventionnelles de gestion de portefeuille de projets. Cette course en avant vers toujours plus de flexibilité dans la transformation des organisations face aux innovations des concurrents et aux injonctions réglementaires pousse vers ce concept bimodal qui reprend les meilleures pratiques des deux mondes pour concilier stabilité et flexibilité. Il introduit néanmoins le risque d’exacerber les tensions résultantes d’une cohabitation de deux organisations en silo qui se disputent les ressources et l’influence des investissements.
A défaut, les gestionnaires de projets se retrouvent à faire le grand écart entre pilotage traditionnel de leur portefeuille par les délais et les coûts versus pilotage par la valeur et la qualité. Une équation à la fois organisationnelle, managériale et opérationnelle souvent difficiles à résoudre, d’autant plus lorsque les acteurs sont peu aptes au dialogue. A défaut encore, des Directions métiers décident de créer leurs propres équipes numériques, ce qui se traduit par de nouveaux silos et l’émergence d’une « shadow IT » qui n’est pas sans conséquence (impact sécurité, économique et pérennité de l’IT -désurbanisation du SI et dette technique-).
Un retard de mise en œuvre préjudiciable
L’extension de l’approche bimodale aux programmes et portefeuilles de projets apporterait in fine la capacité de faire travailler les équipes de l’entreprise en étroite collaboration pour atteindre la croissance et la transformation dans le monde numérique qui se dessine.
Les solutions éditeurs, les cadres méthodologiques sont à disposition mais difficilement mis en œuvre dans les organisations. En France personne n’en parle. A qui la faute ? Est-ce dû à la résistance au changement au sein des directions ? Aux lacunes conceptuelles consécutives aux castings des consultants appelés en renforts ? Ou encore à la lenteur à faire le pas vers l’introduction de pratiques agiles au sein des cellules PMO ?
La difficulté à produire une feuille de route IT/Métier et le portefeuille de projets correspondant
Historiquement, la gestion de portefeuille de projets (réalisée par la cellule PPM), est un « lieu » où la stratégie rencontre l’exécution : elle vise à transformer les « ambitions » en « plan d’action » réaliste tout en gérant les investissements et le travail. Avec l’avènement des organisations agiles, de nouvelles frictions sont apparues : cela se traduit par un manque d’harmonisation de la stratégie et de l’exécution, par des décisions d’investissement sous-optimales, par des retards à l’adoption de l’agilité, et finalement par un manque de visibilité pour tous les acteurs.
Dans l’idéal la vocation d’une cellule PPM est de produire de la visibilité sur la contribution de la DSI à la performance de l’entreprise, via l’activité projet. Les métiers étant bien souvent peu enclins à anticiper leurs transformations, c’est souvent un casse-tête pour la DSI de produire une feuille de route pour l’année à venir, un tant soit peu crédible. Pourtant, les métiers devront prochainement reconsidérer leurs relations avec la DSI en devenant responsable de la création de valeur face aux facteurs qui s’imposent (changement de l’économie, évolution des usages et des clients, consumérisation de l’informatique, accélération de la numérisation, nouveaux Business models, raccourcissement des cycles, …). Les entreprises qui réussissent le mieux à franchir le cap sont celles où un dialogue réel métier/IT existe pour l’élaboration de la feuille de route. Il n’y a pas de bons et mauvais élèves, mais l’équilibre qui rend possible le dialogue est si fragile, qu’il ne permet pas souvent de pérenniser l’approche.
En réponse à la problématique de la « bimodalité », les éditeurs ont apporté des réponses dans leurs solutions de Gestion de Portefeuille Projet, mais celles des adaptations organisationnelles et managériales doivent encore être adressées pour que les acteurs sachent utiliser au mieux les outils déployés. Car bien entendu, l’adage « un outil ne résout rien tout seul » se vérifie ici aussi. D’autant que du point de vue méthodologique, plusieurs modèles coexistent au sein des équipes. Modèles, pour lesquels l’assimilation des principes à tous les niveaux de l’organisation nécessite encore des efforts.
3 bonnes pratiques
Trois bonnes pratiques d’intégration prescrites par le Gartner peuvent atténuer les frictions et habiliter l’organisation à innover, prioriser ses investissements et délivrer plus rapidement :
La première concerne la capacité à choisir à partir d’une approche simple le modèle qui convient, basé sur la nature des projets à mener, en combinant stabilité des pratiques et flexibilité des activités. L’astuce, ici, est de préserver un mode de travail pour la recherche de différenciation et d’innovation, et un autre pour la gestion courante des projets. Pour y parvenir, mettre l’accent sur l’enjeu de création de valeur des projets est un début.
La deuxième vise à définir des objectifs d’industrialisation. Ainsi, l’organisation peut intégrer des méthodes Agile avec des méthodes traditionnelles sans sacrifier la visibilité pour les décideurs et la communication des métriques malgré les disparités d’unités de mesure. Pour ce faire, il faut déterminer des métriques précises (objectifs et résultats clés attendus), puis se focaliser sur des points très spécifiques et suivre leur amélioration au fil du temps. En effet, il ne peut y avoir d’amélioration sans mesure régulière.
Enfin, la troisièmepratiqueimplique de séparer clairement les collaborateurs en deux groupes distincts : l’un capable d’effectuer les changements au niveau de la gestion de projet ; l’autre qui sache prendre des décisions transverses à l’ensemble du portefeuille de l’entreprise. Cette distinction apporte une clarification des attributions des intervenants tout en réduisant la dépendance liée aux individus. Il s’agit, ici, de conjuguer délégation et subsidiarité dans un même environnement.
Développer une gestion de portefeuille de projet qui pilote aussi les opportunités
Pour relever ces nouveaux défis, les cellule PPM trouvent dans l’approche bimodale, un cadre de gestion du portefeuille de projets actualisé qui intègre des pratiques agiles, fournit des précisions aux équipes de projet sur la façon de communiquer l’avancement du projet, et apporte à la direction générale la prévisibilité et la responsabilisation des intervenants. C’est ainsi que l’approche bimodale est à même d’encadrer les interactions des acteurs pour éviter de compromettre tous les processus d’évolution des métiers par la cohabitation de deux organisations l’une centrée sur le client tandis que l’autre est axé sur la planification et le reporting. Cette forme de gestion du portefeuille met donc l’accent sur les opportunités (opportunités IT autant que métiers), pour tout ou partie des activités de l’entreprise, indépendamment du mode de livraison (traditionnel, agile ou hybride). Ainsi elle facilite les prises de décisions décentralisées, les analyses de rentabilité, les planning itératifs avec des objectifs décentralisés, et utilise des mesures factuelles et des jalons. Enfin autant que possible, les opportunités seront portées par des équipes agiles permanentes (squads).
En résumé, l’approche bimodale permet de résoudre les effets néfastes de la cohabitation des modèles, sans risquer de perdre la stabilité et la flexibilité qui leurs sont chère. Le mode 1 « Marathonien » leur permettra de conserver cette stabilité en faisant évoluer l’infrastructure existante de manière pérenne. Le mode 2 « Sprinter » leur permettra de développer rapidement de nouvelles solutions grâce à sa flexibilité. La transformation de l’organisation pourra être conduite en profondeur sur cette base. Elle passe avant tout par un changement culturel au sein de l’entreprise.