Le fameux fonds de carte… Plusieurs « écoles » s’affrontent sur ce sujet car plusieurs possibilités existent qui permettent de positionner le SI et ses applications en fonction du message à faire passer
Le socle des processus ?
Il permet aux métiers de comprendre la couverture des applications / des technologies et donc l’importance qu’ils ont dans le SI (et sûrement aussi dans les budgets donc). Mais trop métier, les SI ne le comprennent pas et il n’est pas forcément pertinent pour mettre en avant les enjeux du SI. Ce socle des processus est parfois dur à construire car les processus existent déjà sous diverses formes au sein de l’entreprise (audit interne, procédures ISO 9001, etc.). Cette vision n’est pas partagée par tous et risque de porter de la confusion. L’avantage est que sur les processus on peut faire porter des stratégies et des enjeux métier. Par exemple l’ouverture vers d’autres société, des délais de réalisation ou de réponse…
Une (business) capability map ?
D’après le nom, cela ressemble fort au socle des processus. Oui mais pas forcément. Un de nos clients, grand groupe industriel, nous a récemment demandé de lui en créer une. Nous sommes partis d’un standard de son métier et nous l’avons complété avec ses spécialités. Le résultat a été une vue des grandes « activités » (donc sans chercher la transversalité comme avec les processus) de l’entreprise. Cette vue a été rapidement comprise par tous. Il est possible avec cette vue capacitaire de mettre aussi des ambitions sur des capacités : pouvoir donner une réponse à un crédit en moins de 24h, faire de la pré-acceptation de crédit dès le dossier complété…
Le plan d’urbanisation ou le pos
Toujours classique et efficace dans sa présentation. Parfois d’un niveau très fonctionnel, il nous est souvent demandé : des adaptations pour intégrer les dimensions applicatives et technologiques notamment. Suivant le niveau de détail, il peut vraiment servir à présenter le SI. Malheureusement il est maintenant surtout utilisé uniquement pour positionner les applications comme dans des boites et ne permet pas de « raconter une histoire » dans le SI. Il ne montre pas les échanges ni en interne ni avec l’extérieur. Cela limite son utilisation pour « raconter des histoires » et donner des ambitions.
Une vue des grands « domaines applicatifs »
Souvent basés sur un découpage organisationnel du SI donc en regard des responsabilités. Ce découpage peut être problématique. Quand il est bien fait, plusieurs clients ont apprécié cette présentation qui leur permet alors de montrer les échanges avec l’extérieur et entre les grands domaines puis de zoomer au fur et à mesure dans le détail de chaque domaine applicatif
Pour décrire le SI, nul doute que la vue des grands domaines applicatifs et des grands flux est un point d’entrée indispensable pour expliquer le SI et son fonctionnement. C’est souvent cette description qui manque.
Les autres vues peuvent être produites à moindre coût et son souvent la promesse des outils d’architecture d’entreprise orientés « data ».
Un fait est certain : les conflits font partie de la vie aussi bien parentale que celle de l’entreprise. Les relations évoluent et passent par différentes étapes. On a beau tout faire pour l’éviter, une crise survient inévitablement. Y a-t-il des signes annonciateurs ? Comment réagir quand certains projets ne veulent pas suivre les recommandations ? Comment faire si l’architecte fait preuve d’autoritarisme ? Comment gérer l’équilibre entre faire ses propres expériences et ne pas se mettre (trop) en danger ? Nous retrouvons à nouveau notre parallèle avec l’éducation parentale qui nous préoccupe tant.
De solution miracle, il n’est pas question ! Nous allons en revanche aborder différentes phases familières et voir ce qu’en dit la littérature et les spécialistes.
Mais qui est ce « Nous » ?
Chloé, architecte d’entreprise, interne d’une grande société qui se demande si son travail est un bullshit job (merci David Graeber). Elle est également jeune maman.
Olivier, architecte d’entreprise senior, consultant et ami de Chloé. Papa (divorcé/recomposé) de grands enfants.
Notes
Le discours s’appuie sur des raccourcis pour en faciliter la compréhension. Bien entendu, dans la réalité, aussi bien personnelle que professionnelle, c’est souvent plus complexe.
Toute ressemblance avec des projets ou des enfants existants ne serait bien entendu que fortuit.
Vous allez sûrement vous retrouver dans les lignes ci-dessous. N’hésitez pas à réagir et à nous faire parvenir vos commentaires, autant sur la forme que le fond, que nous fassions tourner la roue de l’amélioration continue ! Allez, fin du suspense, c’est parti.
En temps de crise, le sage construit des ponts, le fou construit des murs.
Introduction
Chaque crise a une raison spécifique et demande une solution adaptée. Ce que nous allons voir de nouveau dans ce chapitre, ce sont les crises qui débordent, les grandes crises, celles qui demandent un repositionnement du rôle du parent / de l’architecte.
En nous promenant le long de la vie d’une personne de 0 à 100 ans, nous trouverons des parallèles à notre vie en entreprise. Est-ce que ces réflexions vont nous conforter sur l’idée qu’un cadre est indispensable comme nous le préconisons dans le premier chapitre (L’Architecte est un parent comme les autres) ? Est-ce que la vie d’un architecte est toujours aussi simple (noter l’ironie) que celle d’un parent ?
Le rejet de l’autorité à 2 ans
Chloé : Je n’en peux plus ! J’écume toute la littérature sur la gestion de crise en ce moment. A 2 ans, c’est la mini adolescence ou « terrible two » comme on dit chez les spécialistes de la petite enfance. Je te partage ce que j’ai appris ?
Que se passe-t-il dans la vie d’un enfant pour que soudainement, vers 2 ans, l’enfant docile se rebelle ainsi ? Cette bascule surprend d’autant plus le parent que tout est paisible avant. Le premier refus interpelle donc. La raison est assez simple : l’enfant a besoin de s’affirmer. Il veut pouvoir décider. Voilà une des sources de crise : avoir besoin de plus de latitude. Il paraîtrait que c’est normal et même sain. Tu vois où je veux en venir ?
Olivier : Effectivement, je me rends compte d’avoir déjà vécu cette situation en entreprise. Il arrive qu’une personne ou une équipe réclame plus de liberté et rejette les préconisations d’architecture (et non l’architecte !). Alors que fais-tu pour y remédier ?
L’enfant comprend par la répétition les temps forts d’une journée et le rôle des personnes qui l’entourent. Le cadre, à ce moment-là, est strict et les choix sont faits à sa place. Afin de montrer à l’enfant que nous lui faisons plus confiance, car plus mature, la solution est de lui proposer plusieurs choix afin qu’il puisse exprimer sa volonté propre. Et ça fonctionne !
« Veux-tu mettre ce vêtement-ci ou plutôt celui-là, sachant qu’il fait très froid aujourd’hui ? » « Veux-tu créer une API pour ton application ou préfères-tu déverser tes données dans le Datalake, avec tes connaissances maintenant bien ancrées ? ». Le cadre est toujours là (cf Chapitre 1), en revanche les choix possibles pour rester dans ce cadre augmentent. On conseille aussi de faire des câlins, c’est là que le rapprochement avec les collègues s’arrêtent ?
Olivier : Bravo avec ton enfant ! Il est vrai que l’architecte peut adapter son discours face aux équipes et selon la maturité, proposer plus d’options. Au risque de te déprimer, des crises, il va y en avoir beaucoup d’autres, ne serait-ce que l’adolescence. Au secours !
La maladie de l’adolescence est de ne pas savoir ce que l’on veut et de le vouloir cependant à tout prix.
Philippe Sollers
La crise de l’adolescence n’est pas une crise
Chloé : Cette période m’intéresse beaucoup. Mon entreprise en ce moment vit la plus grande transformation possible dans la vie d’une entreprise. Nous redéfinissons les rôles de chacun, la gouvernance, les méthodes et la façon de travailler, nos objectifs, nos relations à nos clients, TOUT, te dis-je !
L’adolescence, c’est exactement cela : une transformation totale. Chacun doit retrouver sa place dans le foyer et se créer de nouveaux repères. La difficulté est d’autant plus grande qu’elle est humaine : remise en cause, doute, perte de confiance envers soi et envers les dirigeants.
Le parent qui savait presque tout ne sait presque plus rien : « c’est toi qui sais ce que tu voudrais faire plus tard, toi qui sais qui tu aimes ou n’aimes pas, … ». C’est effrayant. Je vois les mêmes questionnements actuellement autour de moi. Les managers ne sont plus managers, ils deviennent des (servant) leaders. Les équipes sont responsabilisées : « c’est vous les experts qui prenez vos décisions en autonomie ». Encore plus effrayant.
Alors quelle est la place du parent ou de l’architecte dans cet ouragan ? Comment accompagner ces transformations ? Le risque est grand. Si nous supprimons le cadre (plus aucune règle, plus aucun interdit), nous exposons la famille / l’entreprise à de très grands risques. Si nous restons ancrés sur le cadre historique, alors nous n’avons pas su évoluer avec lui. Comment apporter alors des réponses attendues que nous n’avons pas ?
Un des maîtres-mots de notre transformation est « ensemble ». Si je n’ai pas la réponse et que toi non plus, peut-être qu’à plusieurs, nous allons la trouver. Travailler ensemble veut également dire partager la responsabilité. Nous abattons le mode « Silo » pour un mode plus coopératif.
Est-ce que nous sommes prêts à prendre des risques ensemble et si nous échouons, à trouver de nouveau ensemble des solutions ? Est-ce que nous, architectes, sommes prêts à admettre que le cadre se construit avec ceux que nous accompagnons ? Est-ce que les équipes sont prêtes à entendre que nous n’avons pas toutes les réponses et qu’ils devront également porter une partie des responsabilités en appliquant de nouvelles règles ?
Olivier : Effectivement, la gestion humaine au sein des entreprises est arrivée à la maturité de l’adolescence. Temps délicat pour les leaders et les RH. Personnellement, j’ajouterai : attention aux adolescents silencieux ! Il faut écouter tout le monde, au risque de passer à côté d’une difficulté cachée.
Je pensais que le pire dans la vie c’était de finir seul. Non. Le pire dans la vie est de finir avec quelqu’un qui nous donne l’impression d’être seul.
La crise de la quarantaine
Olivier : Si tu veux bien, on va finir sur la crise dite « de la quarantaine », autrement dit « j’ai envie de changement ». Cette angoisse soudaine qui se profile parce que tout à coup, on se voit vieillir en faisant tout de la même façon, avec les mêmes personnes.
Sur de nombreux sujets, lorsque tout va bien, nous sommes en mode « run ». Nous faisons le strict minimum pour que cela fonctionne au quotidien. Nous prenons le café au même bistrot, achetons la même marque de dentifrice, nous avons des automatismes tels que verrouiller la porte, « d’ailleurs, l’ai-je vraiment fermée ? Je vais revérifier, on ne sait jamais ».
En informatique, la relation MOA/MOE a fait ses preuves durant de nombreuses années : la MOA écoute le client et traduit en termes informatiques / la MOE réalise les demandes. Pourtant, nous nous apercevons que ce duo arrive au terme de son efficacité. Avec la rapidité grandissante des évolutions IT, le couple MOA/MOE nuit à l’innovation de l’IT, car il faut autant entendre la stratégie IT que celle du métier.
La MOE nous fait donc une crise de la quarantaine : je m’ennuie, je veux évoluer, être valorisé. Les spécialistes situent cette crise dans la quarantaine car c’est souvent à cette période que les enfants quittent le foyer (mettons de côté les rides et les cheveux blancs). Une personne qui a fait passer le travail, le couple, les enfants avant soi tel un robot se retrouve « seul » face à une nouvelle situation qui l’angoisse et qui lui permet en même temps de, enfin, se recentrer sur lui.
Les psychologues préconisent de profiter de cette remise en question pour faire un bilan. Qu’est-ce que je sais faire ? Qu’est-ce que je veux faire ? Comment et dans quel objectif ? C’est exactement la place de l’architecte d’entreprise dans l’actualité. Son rôle est d’épauler l’entreprise dans l’évaluation de son SI : par rapport aux nouveaux objectifs que se fixent le métier et l’IT, quels sont les périmètres obsolètes ?
Comment faire évoluer les applications afin d’apporter de nouvelles valeurs ? L’architecte doit être capable de comprendre la profondeur des changements et donc de reposer les bonnes bases pour le futur.
Conclusion
Olivier : si je résume, être architecte demande autant de souplesse qu’un parent. Il se tient à l’écoute de l’entreprise et selon sa maturité et ses besoins, adapte son accompagnement et son cadre. C’est exactement ce que défend TOGAF, et l’amélioration continue. Je pense que nous sommes plutôt raccord avec l’actualité. Rémi Cocula parle de l’évolution « d’Architecte à Métarchitecte » dans une conférence Devoxx. Pour aller plus loin, voir la littérature sur l’Emergent Architecture qui pose la place de l’architecte dans une organisation agile.
Restez connectés pour les prochains chapitres de « Dessine-moi un architecte » :
Si vous ne l’avez pas encore fait, découvrez les deux épisodes précédents : TOGAF IRL 1 ; TOGAF IRL 2.
La fin d’un monde sans contraintes
Ça y est, Vous avez collecté la liste des exigences ! Vous avez rencontré le métier, l’IT et la production de votre IT. Vous avez vérifié que vos exigences sont bien cohérentes les unes avec les autres, vous avez même probablement commencé à réfléchir à quoi ça pourrait ressembler, mais si vous vous dites que le reste devrait couler, vous vous trompez. Car c’est à partir de maintenant que vous allez vous confronter « au réel ».
Vous n’êtes pas le seul projet en cours (enfin normalement), les différents composants sur lesquels vous voulez apporter des modifications ont leur propre cycle de vie, leurs évolutions, leurs contraintes. Et puis votre projet également : le chef de projet a un budget, un délai et des objectifs à respecter. Alors il va falloir prendre tout cela en compte, sinon vous ne serez qu’un architecte de plus avec la réputation de « travailler dans une tour d’ivoire ».
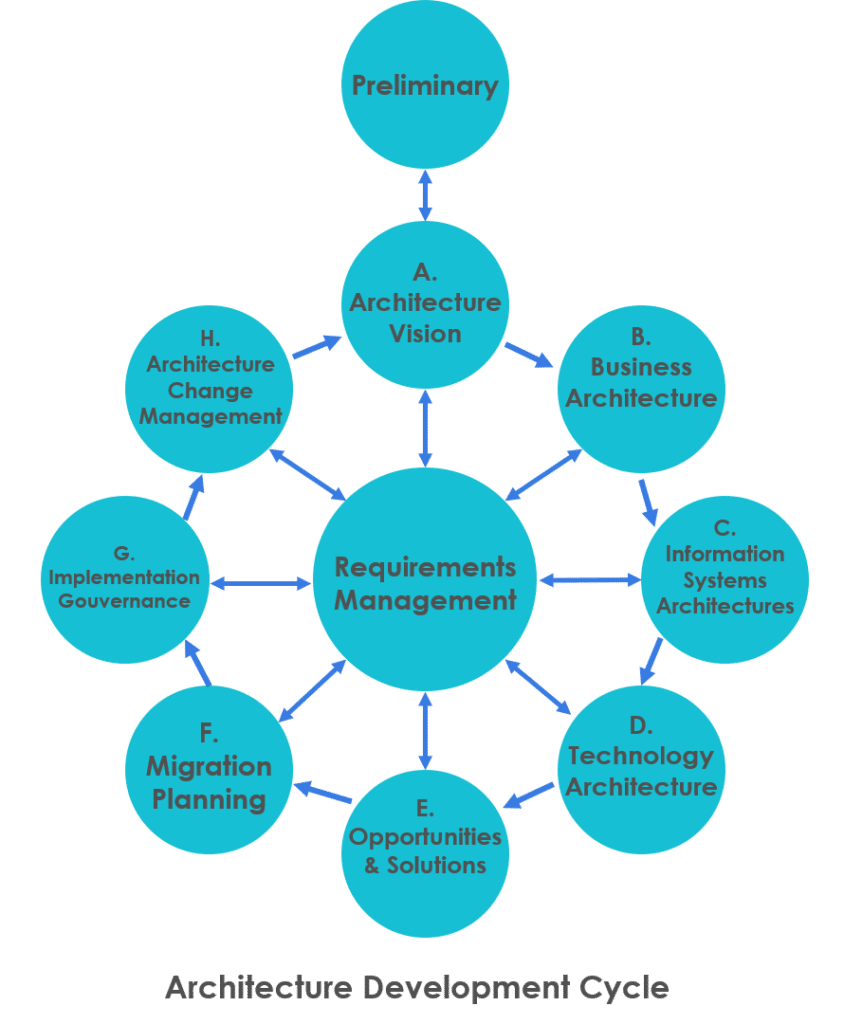
Nous allons donc continuer à parcourir ensemble la roue ADM et au final, nous pourrons nous poser la question : TOGAF, applicable In Real Life ou pas ?
Phase E : Opportunités et solutions
L’objectif de cette phase est de construire la phase initiale de la feuille de route de l’architecture de votre projet. C’est-à-dire que l’on va créer la vision AS-Is du périmètre projet, la cible ainsi que les différents lotissements.
Pour l’existant, vous pouvez commencer en vous basant sur le contenu du référentiel d’entreprise (s’il y en a un) et de la documentation existante mais vous devrez tout de même aller voir vos différents interlocuteurs. Cela vous permettra de vous assurer de la fraîcheur de l’information que vous avez. Profitez-en pour demander si ces composants ont déjà des évolutions de prévues et quand elles auront lieu. Cela vous servira d’entrée pour définir vos trajectoires.
Pour la cible, identifiez les changements et identifiez les exigences liées à ces changements. S’il y a des exigences sans changement associé, c’est que vous avez des oublis.
Maintenant que vous avez votre point de départ et votre cible, il reste à définir le chemin… ou plutôt les étapes de votre chemin (les états stables de votre trajectoire). Pour cela, il est nécessaire de négocier avec l’équipe projet. Il y a évidemment l’enchaînement logique des évolutions (par exemple, si vous devez consommer de nouvelles données clients, vous allez mettre à jour votre référentiel en même temps que l’application consommatrice et non après), mais il est important d’intégrer les contraintes du projet (coûts et priorités) pour définir vos étapes. De la même manière, si vos contraintes ne permettent pas d’atteindre votre cible, identifiez une étape intermédiaire qui pourra servir de cible projet tout en remplissant les exigences principales du métier.
Dès que l’on parle de modélisation en architecture, arrive très vite la question de l’outil de modélisation ou d’Architecture d’Entreprise. Nous n’allons pas parler ici de quel outil utiliser ou comment le faire car ce n’est pas le sujet de notre article, mais plutôt est-ce vraiment nécessaire. De mon point de vue la réponse est non, on peut très bien faire sans et power point est largement suffisant. Par contre si c’est le choix qui est fait, cela implique plusieurs choses :
Définir un modèle de document qui sera appliqué pour chaque projet
Définir un métamodèle et une légende commune
Avoir un outil de gestion documentaire pour éviter que toutes les connaissances acquises soient perdues.
J’ai personnellement travaillé dans des grands groupes bancaires, dans des entreprises de service ou industrielles qui avaient fait ce choix et cela permet d’éprouver la démarche sans avoir à faire des investissements qui peuvent parfois être lourds pour l’entreprise ou la DSI.
Phase F : Migration et planning
Vous connaissez la direction que vous voulez prendre ainsi que le chemin, mais il reste encore une chose à savoir : quand ? Le but de cette étape est de finaliser la feuille de route d’architecture et le plan de mise en œuvre de la transformation. Jusqu’à présent vous avez intégré les contraintes de votre projet mais vous ne vivez pas seul sur une île déserte. D’autres projets touchent peut-être les mêmes composants que vous et peut-être sont-ils plus prioritaires que vous.
Dans ce cas, TOGAF préconise de voir le chef de projet ainsi que le responsable du portefeuille de projet. Il faut faire attention tout de même, certains chefs de projets, emportés par la volonté de mener à bien leurs travaux, ont tendance à minimiser les impacts de leurs collègues et les responsables de portefeuille n’ont pas toujours la vision exhaustive des impacts de tous les projets qu’ils suivent. A titre personnel, je vais toujours faire le tour de l’équipe d’architecture en plus, mais je vais également voir les responsables d’application car ce sont ceux qui ont une vue complète des évolutions à venir.
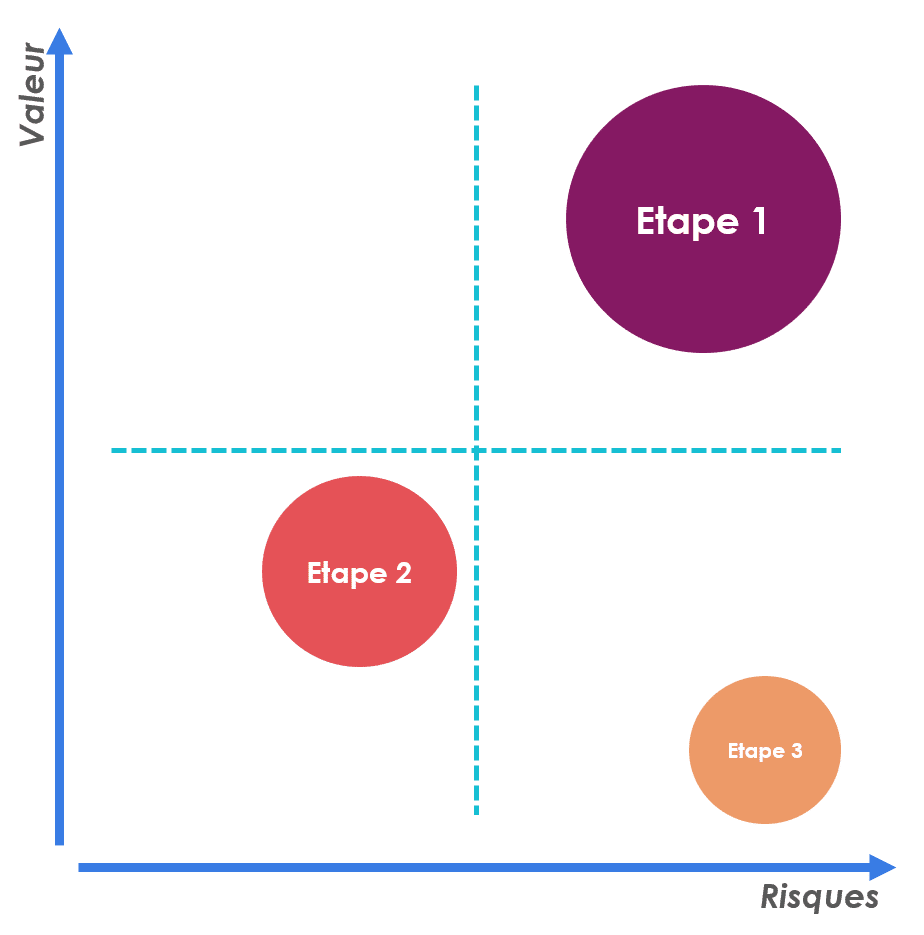
A présent votre feuille de route est terminée. pensez à bien mettre en évidence la valeur ajoutée pour le métier de chaque incrément car, quand vous communiquerez sur le déroulé de votre projet, ce sera le critère clé pour votre client : le métier. Si cela est possible, mettez cela en balance avec le risque lié à chaque étape dans un diagramme comme celui-ci :
Phase G : Implémentation et gouvernance
L’objectif de cette phase de la roue ADM est de s’assurer que les mises en œuvre sont bien conformes aux spécifications de l’architecture cible, en d’autres termes : faire le suivi de l’architecture du projet.
Cette phase est très souvent négligée par les équipes d’architecture. Cela nécessite d’investir beaucoup de temps et la valeur est souvent sous-estimée. Or, il est dommage de définir une architecture répondant au mieux aux attentes du métier, si derrière l’implémentation ne correspond pas.
Idéalement, il faudrait pouvoir faire des revues de code régulières, mais malheureusement cela est très chronophage. En réalité, il est souvent suffisant de participer aux comités projets pour les projets « en V » et d’y identifier les futurs travaux ou de relire la Sprint Back log pour les projets agiles. En toute logique, il est préférable d’intervenir avant que la réalisation commence, car il est très rare de voir un projet faire marche arrière.
Phase H : La gestion du changement
Ce n’est pas parce que le projet a démarré qu’il n’y a pas de nouveaux besoins. Dans cette phase, vous êtes censés vérifier 2 choses :
Si les nouveaux besoins collectés nécessitent de redémarrer un nouveau cycle (bref un nouveau projet) ou juste une mise à jour de l’actuel.
Si le projet est conforme ou non et si ce n’est pas le cas, si une dérogation peut être accordée ou non.
Pour les nouveaux besoins, il faut évaluer les impacts sur l’architecture et pour cela vous pouvez utiliser quelques critères tels que :
Le changement touche un ou plusieurs composants ?
Cela remet-il en cause l’architecture actuelle ?
Cela nécessite-t-il la mise en place de nouveaux flux ? De déployer de nouveaux composants ?
Pour vous donner un exemple, j’interviens actuellement sur la mise en place d’un ERP chez un client. Ce client a deux nouveaux besoins qui sont apparus. Dans un cas, il a été nécessaire de déployer un nouveau composant et cela a entraîné le lancement d’un nouveau sous-projet. Dans l’autre cas, il a fallu également déployer un nouveau composant, mais cela n’a pas nécessité de nouveau projet, car il s’agissait d’un ISV (achat du composant sur une market place de l’éditeur de l’ERP). En réalité il s’agit d’une décision collégiale entre le chef de projet et le sponsor et vous ne pouvez qu’apporter un avis.
Pour les réserves et les dérogations, on peut utiliser les mêmes critères et comme pour les nouveaux besoins, la décision se prendra entre le chef de projet et le sponsor.
Alors TOGAF, applicable IRL ou pas ?
Parmi tous les reproches que l’on entend au sujet de TOGAF, celui qui revient le plus souvent est celui de la rigidité. Reconnaissez que c’est un reproche étonnant car ce que l’on attend d’un framework : c’est un cadre, et un cadre est rarement souple.
Alors comme disent nos amis anglais : « first learn the rules then break them ». La valeur de cette démarche et qu’elle permet de comprendre les interconnexions entre toutes les décisions durant un projet et leurs impacts sur le résultat final. Une fois que l’on a compris cela, il suffit juste d’adapter TOGAF à son environnement comme nous l’avons fait lors de ces trois articles.
A titre personnel, il arrive que ma démarche soit encore plus éloignée des règles TOGAF. Il arrive même que je me passe de certaines phases de la roue mais cela est toujours propre à l’environnement dans lequel je travaille.
TOGAF in real life : sans doute pas, mais TOGAF in your own life : sans aucun doute.
Question subsidiaire : la certification, utile ou pas ?
Vous m’auriez posé la question il y a quelques années, je vous aurais dit que cela est utile, surtout si vous travailliez comme consultant. Aujourd’hui (nous sommes en 2020), cela me parait beaucoup moins nécessaire. Je suis consultant depuis bientôt 15 ans. Je suis intervenu chez une trentaine de clients et le dernier à m’avoir posé la question, c’était il y a 3 ans et c’était pour me dire que lui venait de le passer. En fait, TOGAF a irrigué beaucoup de services d’architecture. Beaucoup de gens en font sans le savoir et finalement ce n’est plus un facteur différenciant. Alors si on vous le propose, dites oui mais vérifiez que cela ne va pas être juste du bachotage, car la formation a plus de valeur que le coup de tampon.
Après quelques retours d’expérience sur des outils d’Architecture d’Entreprise, une question s’est rapidement imposée à moi : pourquoi prendre un EAMS (Enterprise Architecture Modeling System) et quel intérêt peut-il apporter aux équipes projets agiles ?
Certes, ces outils d’Architecture d’Entreprise disposent d’une base de données d’assets variés sur les business capabilities, les applications, les processus, l’infra… Une fois croisées, ces informations représentent une vraie mine d’or, permettant un reporting opérationnel instantané. Pour prendre deux exemples, piloter les coûts directs ou la roadmap d’obsolescence des applications devient un jeu d’enfant grâce à la mise à disposition d’informations de qualité, accessibles sans délai. La prise de décision est plus efficace.
Une fois les données mises en qualité et chargées dans l’outil, il contient nombre d’informations utiles pour les projets. Pour conduire une étude de faisabilité ou d’impacts, l’EAMS fournit la cartographie des interfaces entre applications, voire même les projections (to be) de grands programmes ou projets. Les équipes projets disposeraient instantanément d’informations à forte valeur ajoutée, comme la cartographie globale des flux, des processus métiers de l’entreprise… Sur le papier, l’utilisation d’un outil d’Architecture d’Entreprise pour modéliser les projets présente donc un intérêt certain.
Or, avec la généralisation des projets menés en mode agile, l’outil d’Architecture d’Entreprise correspond-t-il vraiment au besoin des équipes projets ? L’effort de documentation semble lourd et inadapté au cycle de production des équipes agiles. Fonctionnant par itération ou incrément, la vision du produit final évolue en permanence. La documentation complète d’un projet agile risquerait de ne plus coller au besoin, pour finalement ne jamais servir.
Le contenu de l’outil d’Architecture d’Entreprise peut évoluer au même rythme ? L’équation effort fourni-utilisabilité-ROI est-elle avantageuse ?
En somme, l’Agilité sonne-t-elle la fin des outils d’Architecture d’Entreprise ?
L’outil d’architecture d’entreprise : un bon élève comme un autre
Un outil d’Architecture d’Entreprise vise à modéliser l’entreprise dans son ensemble : ses processus métier, ses applications, ses flux de données… A ce titre, plus il est rempli, mieux c’est. Encore faut-il trouver la bonne granularité à décrire. Car plus l’outil est fourni, plus il risque de perdre ses contributeurs, donc de ne pas être tenu à jour et de ne servir à personne.
Ainsi, l’outil d’Architecture d’Entreprise doit contenir assez d’informations pertinentes et de qualité pour intéresser les contributeurs (responsables de domaine, responsables d’application, équipes projets…), mais également pour leur donner envie de compléter ces informations en leur proposant, par exemple, des dashboards et rapports intéressants, des vues synthétiques de l’intégration des applications entre elle, de la couverture fonctionnelle…
Les utilisateurs, et plus particulièrement ceux qui sont contributeurs occasionnels, ne doivent pas perdre un temps fou à trouver une information. L’outil doit être intuitif et simple d’utilisation. Par exemple, si mon projet, mené en mode agile, ne touche que le domaine marketing, je m’intéresserai en priorité aux informations impactant ce domaine. Les informations liées à d’autres métiers ou contextes ne m’intéresseront pas directement. En revanche, bénéficier de référentiels et de toutes les informations liées au contexte de mon projet m’apportera une vraie valeur ajoutée.
Avec du recul, être le meilleur élève de la classe auprès des équipes projets, c’est restituer efficacement l’information auprès des différentes parties prenantes. La valeur ajoutée d’un tel outil n’est pas d’agréger le plus d’informations possible sur tout et n’importe quoi, mais bien d’identifier les informations utiles, les acteurs qui peuvent la fournir et le meilleur moyen de la restituer.
Partir du cas d’usage
Pour éviter un rendez-vous raté entre équipes agiles et outils d’AE, il faut savoir se poser les bonnes questions pour évaluer les bons critères. A quoi mon outil d’Architecture d’Entreprise doit-il me servir ? Qui seront mes utilisateurs ? Quels seront mes principaux cas d’usage ? Optimiser mes processus, rationaliser mon portefeuille applicatif, réduire les coûts IT, préparer un audit du SI, vérifier que je suis en conformité avec la RGPD ?
En tant qu’Architecte d’Entreprise, j’aurai besoin d’une vision globale de mon entreprise, pour mener des analyses croisées, des études d’impacts et orienter les décisions stratégiques.
C’est le même raisonnement qui doit guider l’apport de valeur aux équipes agiles. De quoi ont-elles besoin pour mieux travailler ? Qu’est-ce qui leur manque aujourd’hui ? Concentrées sur leur projet, il leur manque souvent une vision globale et complète, de l’entreprise comme des autres projets.
Le rôle de l’architecture d’entreprise face à l’agilité : l’enabler
Cette vision globale, l’Architecte d’Entreprise en est le garant. Il bâtit une roadmap des projets en cours et à venir, ainsi que de leurs interdépendances. Avec l’Agilité, l’architecte anime la vision de cette roadmap. Il construit et maintient l’architecture cible qui doit résulter de ses projets. Comme la cible évolue en permanence, car les besoins changent en cours de route, il n’est pas envisageable de reconstruire perpétuellement le chemin. L’Architecture d’Entreprise doit savamment doser entre apporter de la visibilité au projet, indiquer la direction et les étapes obligatoires, sans produire une trajectoire trop précise qui ne servira plus dès le premier changement de cap.
Ici, le rôle de l’Architecture d’Entreprise sera de dire au projet dans quel cadre s’insérer, sans leur prescrire une solution que les équipes agiles trouveront d’elles-mêmes. L’Architecture d’Entreprise, rendue accessible grâce à l’EAMS, indiquera par exemple dans quel quartier la maison, c’est-à-dire le projet, doit se trouver, sans pour autant dire à quoi elle va ressembler.
C’est le rôle de l’équipe agile de coller au plus près au besoin du métier et d’y être réactive. Par conséquent, l’outil d’AE ne devra pas représenter un frein à l’Agilité, mais un accélérateur. Dans ce cas précis, nous pourrions parler de facilitateur, ou encore d’ »enabler« , c’est-à-dire que l’outil d’AE, et a fortiori l’Architecture d’Entreprise en elle-même, devient un facilitateur de l’Agilité.
« J’ai les moyens de vous faire parler »
Finalement, l’EAMS sert à rendre accessible au plus grand nombre les bénéfices de l’AE, c’est-à-dire la connaissance accumulée sur l’entreprise et les informations croisées. L’enjeu est bien de faire parler l’outil, de rendre l’information utile et communicante. Pour ce faire, il faut avoir défini les cas d’usage de l’outil. Car, sans savoir ce que je veux, je peux avoir le meilleur outil du monde, jamais je n’arriverai à le faire parler, ni à prouver sa valeur.
Maintenant, il se trouve que les équipes agiles savent se débrouiller pour s’informer. Et qu’elles possèdent leur propre langage. Elles utilisent des outils agiles de type Confluence, Jira, Visio, des sites web, Wiki… Dans son domaine, chacun produit ses modèles et les met à disposition pour aller plus vite.
Ces dernières années, les outils et les formats de restitution se sont multipliés. Historiquement, PowerPoint emportait largement la bataille du support de communication. Or, aujourd’hui, on ne travaille plus de la même manière grâce aux nouvelles méthodes, voire à la nouvelle philosophie, apportées par l’Agilité. Il n’est plus pensable de se contenter d’un PowerPoint ou d’un fichier Excel : les supports sont dynamiques, calculés en temps réel et facilement exploitables, à l’instar des sites collaboratifs, tel SharePoint, qui proposent même d’incorporer des iframes à partir de domaines externes.
Si l’on y réfléchit quelques instants, le dénominateur commun des équipes est de bénéficier d’un outil de communication collaboratif et facile d’utilisation. A ce niveau, une question serait pertinente pour chatouiller les EAMS : l’outil d’Architecture d’Entreprise me permet-il de communiquer rapidement ? De fournir les livrables (études de faisabilité, dossier d’Architecture, roadmap d’obsolescence…) dont j’ai besoin ?
Si certains outils hautement configurables peuvent fournir presque toutes les formes de reporting possibles et imaginables, on peut rarement avoir le beurre et l’argent du beurre. Ainsi, des études de faisabilités, certaines cartographies et autres dossiers d’architecture, ne sont pas d’emblée exploitables et reproductibles dans un outil, une difficulté souvent inhérente au formalisme propriétaire et à la prise en main de l’outil.
On ne peut plus prescrire, alors adoptons un architecte d’entreprise
Pour des raisons de rationalisation des coûts, l’outil d’Architecture d’Entreprise est souvent imposé, sans consultation de ses futurs contributeurs. Or, cela entre en contradiction avec la philosophie des équipes agiles : communication, partage, transversalité… Du fait de leur autonomie, elles sont pleinement capables de choisir les outils qui les aideront à être plus performantes. Pour délivrer de manière continue, elles choisissent les outils qui supportent efficacement leurs méthodes de travail, tout en leur laissant flexibilité et marge de manœuvre.
En revanche, ces outils vivent le temps du projet, négligeant ainsi le collectif et la capitalisation. L’outil d’Architecture d’Entreprise reste la solution privilégiée pour capitaliser sur la connaissance et la cartographie du SI. Certes, l’EAMS ne peut pas être imposé aux équipes projets : il doit être adopté. Mais sa facilité de prise en main, son apport d’informations intéressantes et ses qualités de restitution achèveront de prouver sa valeur.
C’est le parti pris de nouveaux acteurs dans le secteur des outils d’Architecture d’Entreprise et nous nous intéresserons à cette question dans un futur article. La suite dans le prochain épisode !
Comment une demande utilisateur déclenche une crise à la DSI ?
Lors de la pause café du CODIR, le DRH a présenté le nouvel outil qu’il souhaite déployer pour la gestion des notes de frais : depuis une application smartphone, le salarié prend en photo son ticket de caisse, la note de frais est ensuite automatiquement saisie et envoyée en validation. L’ensemble du CODIR a immédiatement adhéré (la réduction d’effectifs des assistantes de direction ne semble pas être étranger à la décision). Il a été demandé au responsable informatique de mettre en place l’outil dans les plus brefs délais : la solution pourra être paramétrée par un prestataire pour répondre aux besoins de l’entreprise en moins d’une semaine. Pour tenir les délais, le CODIR demande à la DSI de faire fi des processus habituels et de s’appuyer sur le Cloud. Les délais de mise en oeuvre de technologies type serverless sont jugés beaucoup plus acceptables que les mois historiquement nécessaires pour acheter et configurer des nouveaux serveurs. Idée géniale ! Tout content, le DSI repart avec ce projet voir ses équipes… Mais très rapidement la tâche paraît bien plus importante que prévue :
L’application sera déployée dans le Cloud, une première pour cette entreprise, et cela nécessitera la mise en oeuvre d’une zone pouvant échanger avec le SI legacy. Comment inclure ce nouveau “datacenter virtuel” de manière sécurisée au sein du SI ?
L’application doit s’interfacer avec la RH et la paie. Ces systèmes étaient traditionnellement hébergés sur un réseau dédié, isolé d’internet. Le serveur hébergeant ces applications n’a pas été mis à jour depuis plusieurs années. La mise à jour de ce serveur impliquerait la mise à jour du SIRH. Si ce dernier devait être réinstallé, cela induirait un projet long et coûteux. Comment exposer et récupérer les données indispensables au bon fonctionnement du service, sans mettre en péril les données personnelles des salariés ? Outre la question de l’obsolescence, se pose la question des échanges sécurisés.
Les accès internet de l’entreprise ne sont pas dimensionnés pour que les employés travaillent sur des serveurs hébergés en dehors de celle-ci. Les accès internet ne sont pas non plus dimensionnés pour permettre l’échange sécurisé d’informations avec des partenaires tiers hébergés sur internet. Au delà de la taille des tuyaux, les problématiques d’échanges de données avec les applications partenaires doivent être adressées.
Les impacts si majeurs conséquents à cette demande du métier
Derrière une réponse en apparence simple d’un point de vue de l’utilisateur, (i.e. installer une application de gestion des notes de frais), se cache une transformation profonde du SI. Pour devenir Cloud Ready, la DSI doit ainsi adresser 4 chantiers majeurs :
La mise en place d’un cloud public
Quels sont les services qui devront être instanciés dans le Cloud ?
Comment mettre à disposition les services de la DSI dans le Cloud ?
Comment résoudre l’équation du respect des bonnes pratiques de sécurité avec le respect du budget de la DSI ?
Comment garantir l’exploitabilité des applications qui seront déployées dans le Cloud ?
Comment mettre une politique FinOps qui permette d’aligner les coûts relatifs au Cloud avec les gains métiers attendus ?
Comment permettre l’accès des utilisateurs depuis n’importe où aux applications déployées dans le Cloud ?
Comment optimiser les coûts de possession des applications ?
Comment garantir leur compatibilité avec les technologies Cloud ?
La gestion des échanges de données
Quelle stratégie à mettre en oeuvre pour les échanges de données entre les applications du SI et celles dans le Cloud ?
Avec les applications des partenaires externes ?
Est-ce qu’une politique d’API doit être poussée ?
Comment gérer les échanges avec les applications historiques du SI ?
Est-ce que l’évolution de l’ESB ou de l’ETL est suffisante ou est-ce que la mise en place d’un iPaaS doit être envisagée ?
La sécurité “by design” du SI
Quels sont les services de sécurité à mettre en service pour permettre une sécurisation de bout en bout ?
Quels sont les composants à instancier afin de garantir l’accès sécurisé aux applications ?
Quelles sont les règles à imposer aux applications afin de garantir la sécurité du SI ?
Est-ce que l’entreprise doit envisager la mise en place d’un SIEM (Security Information and Event Management) afin de détecter les éventuelles attaques ?
Dans certains cas, ces quatre chantiers seront suffisants. Dans d’autres cas, il faudra compléter avec :
La refonte de l’environnement de travail et les problématiques du BYOD (Bring Your Own Device), les problématiques liées à la conformité du poste de travail, la sécurisation des accès à privilèges.
La mise à disposition des services de la DSI via un portail de service.
La mise en place d’une chaîne DevOps permettant d’industrialiser le déploiement des applicatifs dans le Cloud (ou On-Premise).
L’étude de mise en oeuvre de plateforme (Blockchain, BigData ou IOT) pouvant accueillir des applications métiers afin d’anticiper leurs impacts sur le SI historique.
(Re-)mise en perspective d’une transformation vers le cloud
Beaucoup d’entreprises initient ces transformations en ayant uniquement un objectif économique. Il est important de noter que dans la plupart des organisations, les économies espérées ne seront pas générées par la transformation technologique, mais par la transformation des processus qui les consomment. Un service technologique sera rentable dans le Cloud à condition qu’il soit dimensionné et disponible en fonction de la demande des métiers. Par exemple, les serveurs de développements peuvent être éteints la nuit, et certains services de Production re-dimensionnés la nuit lorsqu’il y a peu d’utilisateurs. La transformation vers le Cloud permettra à la DSI et aux métiers d’être plus réactifs dans la mise à disposition de nouveaux produits et services. Les investissements pourront être limités car proportionnels aux revenus ou économies générés par leur consommation. Pour approfondir le sujet, nous vous conseillons de consulter les 5 mythes associés à une stratégie cloud first :
La réduction systématique des coûts
Toutes les applications sont éligibles au cloud
Il ne faut conserver qu’un seul fournisseur
La migration vers le cloud rendra mon application résiliente
Une fois dans le cloud je n’aurais plus besoin d’architecte
En conclusion
L’utilisation du Cloud ne s’improvise pas, la transformation doit être planifiée afin de respecter les exigences métiers. Il faut aussi veiller à ce que les métiers s’approprient les nouveaux services au fil de l’eau. Les organisations qui sont parvenues à se transformer ont pris le contrôle de leur transformation en formant massivement leurs acteurs aux technologies Cloud, et en se faisant accompagner par des sociétés expertes sur les différentes problématiques. Il n’existe pas de recette préformatée permettant de répondre à ces problématiques. Même si de bonnes pratiques ont été éprouvées sur des projets majeurs, la feuille de route devra être adaptée au contexte de l’entreprise et à sa maturité. Le succès de la transformation du SI sera atteint à condition de replacer les enjeux métiers au centre de la transformation.
Avec 30 milliards en 2020 alors qu’ils n’étaient encore que 5 milliards hier, les objets connectés deviennent omniprésents dans les entreprises. Ils impactent la relation client, permettent de créer de nouveaux usages et introduisent de nouveaux modèles de business.
Cependant, de nombreuses organisations se trouvent mal préparées pour faire face à la profondeur et à l’ampleur d’un tel changement. Heureusement, ces mêmes entreprises disposent déjà en interne d’une expertise pouvant faciliter la transformation à plusieurs niveaux : l’architecture d’entreprise.
Quelles sont les grands familles d’architectures autour de l’IoT ?
Avant de parler du rôle des facilitateurs, intéressons-nous aux types d’architectures autour des objets connectés que nous pouvons regrouper synthétiquement en 4 grandes familles :
Device to Device (appelée aussi machine to machine M2M) : Les objets connectés, au sein d’un même réseau local, se connectent généralement à l’aide de protocoles sans fil (Bluetooth, WIFI, …) ou via des connexions physiques.
Device to cloud : les objets connectés se connectent directement au cloud, généralement à travers le réseau longue portée (réseau mobile classique, réseau dédiée aux objets connectés, …). Les données sont ensuite analysées et mises en valeur.
Device to Plateform : les objets connectés transfèrent les données vers le cloud via une plateforme. Cette dernière recueille, centralise et communique les données au cloud par le biais d’une connectivité réseau supplémentaire (réseau mobile, WIFI, réseau filaire, …)
Cloud to cloud : cette architecture est axée sur un processus de cloud décentralisé. Chaque structure possède son cloud privé de gestion des données mais aussi partage ses données dans un cloud central accessible par des tiers. Prenons l’exemple d’un bâtiment intelligent qui reçoit des données provenant de thermostats intelligents et d’ampoules électriques intelligentes. Les données sont stockées dans un cloud privé à ce bâtiment. Ensuite, Les données peuvent être transférées dans un cloud public plus important (à l’échelle de la ville) pour permettre des analyses plus globales.
L’architecture d’entreprise comme vecteur de la transformation…
Aujourd’hui et plus que jamais, il devient impératif pour les entreprises de briser les cloisonnements organisationnels afin de maximiser la valeur produite de bout en bout dans l’ensemble de l’entreprise et le service rendu aux clients.
Dans cette optique, l’architecture d’entreprise a pour rôle d’aider les entreprises à tirer bénéfice de la transformation induite par le déploiement des objets connectés. Réussir cet accompagnement passera, pour l’architecture d’entreprise et les parties prenantes, par des réflexions autour de (liste non exhaustive) :
La gestion des données massives : les premiers déploiements autour des objets connectés à grande échelle au sein des organisations, produisent des données qui sont souvent cloisonnées et fragmentées (souvent au reflet de l’organisation), ne permettant pas de fournir le niveau d’information nécessaire pour justifier de lourds investissements. Sans structure appropriée, la quantité de données s’avère écrasante et les informations les plus utiles seront noyées. Pour maximiser la valeur produite par ces données, l’architecture d’entreprise contribuera à la stratégie et l’opérationnalisation des données provenant des dispositifs connectés au sein de l’organisation. L’architecture d’entreprise peut également aider à identifier les données les plus pertinentes, les responsables de ces données et les responsables de la sécurité pour structurer ces données de manière à atténuer les risques liés à leur exploitation.
L’interconnexion et l’interopérabilité des composants : Pour tirer le meilleur parti des objets connectés, les interconnexions entre les appareils doivent être identifiées et les murs qui les séparent démontés. C’est là que l’architecture d’entreprise entre en jeu. Cette dernière peut tirer parti de l’interconnectivité des dispositifs intelligents, en les regroupant pour mesurer l’impact potentiel ou pour former de nouveaux cas d’usage. Plus globalement, l’architecture d’entreprise peut utiliser le vecteur des objets connectés pour insuffler une nouvelle dynamique organisationnelle dans l’entreprise.
Les nouveaux cas d’usage et la création de valeur : L’architecture d’entreprise aura pour rôle de comprendre les caractéristiques d’une technologie IoT spécifique et d’accompagner les parties prenantes de l’entreprise à identifier les opportunités commerciales que les IOT offrent. L’architecture d’entreprise sera alors en mesure de fournir une vision et des cas d’usage bien plus qu’une simple liste d’idées technologiques « dans l’ère du temps ». Par exemple, elle pourrait fournir une compréhension générale de l’impact des technologies sur les entreprises, des informations qu’elles exposent et la valeur ajoutée de ces informations.
Sans oublier de renforcer la gestion des risques technologiques…
Face à la diversité des objets connectés et à l’interconnexion avec le legacy, la gestion des risques est devenue un sujet majeur pour l’architecture d’entreprise. En partenariat avec des spécialistes de l’intégration, des experts fonctionnels et des fournisseurs, l’architecture d’entreprise aura à planifier et à participer à la mise en œuvre d’une gestion des risques des plus rigoureuses. Une liste des risques à gérer couvrant notamment :
La cybersécurité : De plus en plus d’attaques se concentrent sur les objets connectés (Kaspersky a recensé 105 millions d’attaques contre des objets connectés au premier semestre 2019) à travers des attaques DDOS ou par botnet. Par conséquent, la vision traditionnelle de la sécurité axée sur une approche de la sécurité de l’information devra évoluer vers une approche de gestion des risques de sécurité. La cybersécurité et les plans de reprise des activités devront devenir des piliers de la stratégie IT de l’entreprise pour, d’une part, sécuriser la valeur produite et, d’autre part, pour maintenir et/ou rehausser l’image de l’entreprise auprès de ses clients.
La gestion de l’information : la masse des données produite est susceptible de mettre à mal l’infrastructure existante. Un vrai plan de gouvernance et un cycle de vie des données sera impérativement à définir. Par exemple, l’architecture d’entreprise aura à travailler avec toutes les parties prenantes afin de définir, entre autres, la plage de temps pour laquelle une donnée est encore utilisable ou encore les données à archiver.
La gestion des fournisseurs et des sources d’approvisionnement : Il s’agit de coordonner les anciens et les nouveaux fournisseurs et partenaires technologiques afin de créer un système d’information le plus homogène possible dans le but d’améliorer l’efficacité financière du SI mais aussi afin de faciliter son évolution.
La gestion de l’interconnexion avec le système legacy : En place depuis des années, les systèmes legacy jouent un rôle opérationnel central dans les entreprises. La cohabitation des deux types de systèmes (le legacy ayant un cycle de vie plus long et les objets connectés avec des cycles de vie plus courts) sera un défi de taille pour l’entreprise. Pour faciliter cette interconnexion, l’architecture d’entreprise sera notamment en charge de la gestion de la coordination des différents acteurs et de la gestion de l’intégration afin que cette cohabitation soit en mesure d’apporter les bénéfices attendus mais aussi de continuer à garantir la continuité du business.
Avec pour seul but de réussir sa transformation…
Pour conclure, en combinant des technologies innovantes (notamment les objets connectés), des modèles de business innovants et une volonté forte de toutes les parties prenantes, Il est possible de créer un effet « disruptif » dans le modèle organisationnel et dans le business de l’entreprise. Dans cette dynamique, l’architecture d’entreprise doit être au centre de la stratégie de l’entreprise et être un des principaux accélérateurs (et moteurs !) de la transformation.