Il y a quelques temps, nous avons démarré une saga sur deux sujets qui nous semblaient décorrélés : outils d’Architecture d’Entreprise et Agilité. La question sous-jacente est bien de savoir comment l’outil d’Architecture d’Entreprise peut apporter de la valeur aux équipes opérationnelles, sans perdre pour autant sa simplicité d’utilisation et ses cas d’usage principaux.
De nouveaux acteurs dans le secteur des outils d’Architecture d’Entreprise ont axé leurs efforts sur la facilité de prise en main et la qualité des restitutions à la volée. Un outil facilitant ce travail de manière récurrente peut permettre d’embarquer des utilisateurs « non-architectes », dont l’activité quotidienne est déjà consacrée à 100% à des tâches opérationnelles.
Mais ces nouveaux outils signent-ils pour autant la fin des leaders historiques du marché ? Et surtout, cela signifie-t-il qu’ils doivent être utilisés à des fins plus opérationnelles par les équipes ?
La fin des dinosaures ?
Les outils historiques du marché de l’Architecture d’Entreprise ont été conçus par des experts pour des experts. Et qui en est pleinement satisfait aujourd’hui ? Étant donné leur inertie et la lourdeur de leur configuration, ces outils peuvent exclure les projets et les équipes agiles.
On reproche aux EAMS (Enterprise Architecture Modeling System) d’être des logiciels difficiles d’utilisation, obscurs pour les utilisateurs occasionnels et nécessitant une phase de formation non-négligeable avant utilisation. Trop souvent l’architecte d’entreprise est arrivé avec l’artillerie lourde pour imposer outils et process : c’est tout sauf agile !
Par ailleurs, l’intérêt de l’Agilité est d’apporter rapidement de la valeur au métier, grâce à aux interactions au sein d’équipes mixtes métier/IT. Formés à plusieurs domaines, les développeurs polyvalents sont capables de comprendre les besoins et d’interagir avec les experts pour prendre les meilleures décisions possibles. Cette interaction entre plusieurs disciplines favorise la montée en compétence et enrichit les échanges. De la même façon, des outils déployés par les architectes pour les architectes apportera moins de valeur que s’ils sont ouverts à d’autres domaines d’expertise et améliorés en fonction des enjeux de chacun.
Alors, architectes, puisons notre inspiration des opérationnels et de leurs outils !
Jeune outil deviendra grand
Face aux mastodontes historiques, de nouveaux acteurs ont émergé ces dernières années, jusqu’à devenir de sérieux concurrents. Serait-ce la réponse à l’incompatibilité apparente entre besoins de l’Architecture d’Entreprise et des équipes opérationnelles ?
Certains outils sont de simples modelers. Sans prérequis particuliers de prise en main, ils répondent directement aux besoins de modélisation des projets. Encore faut-il trouver le bon compromis entre la gestion centralisée d’un référentiel d’assets IT et de l’architecture mouvante des projets agiles.
D’autres outils, à peine plus complexes en apparence, gèrent même un référentiel : le principe est d’alimenter l’outil via l’import de données pour générer automatiquement des rapports. Interfacer un outil d’Architecture d’Entreprise et un outil de modélisation est même possible nativement chez certains éditeurs. Ou bien, sous réserve d’avoir quelques « techos » disponibles, une interface « maison » entre l’EAMS et l’outil de modélisation projet (tel Archi, ou autre) permet de dissocier la partie référentielle du projet et de ses changements. Tout cela pour un contenu toujours plus riche, mais structuré !
Nous pensons également aux éditeurs qui intègrent de manière « out-of-the-box » des outils utilisés par les projets, comme la suite Atlassian. En quelques clics sur Confluence, par exemple, il devient possible de partager au sein de l’équipe des diagrammes et roadmaps modélisés dans le logiciel d’AE, de manière dynamique et embarquée. La démarche se veut collaborative : cette interconnexion ferait-elle le pont entre les deux mondes pour finalement mettre tout le monde d’accord ?
Grâce à ces logiciels, il devient possible de centraliser toutes les informations importantes pour les projets et l’entreprise dans une vue unique et partagée. Si le but est de communiquer des informations clés, c’est suffisant. Architectes d’entreprise et équipes agiles échangent leurs connaissances (opérationnelles ou stratégiques, détaillées ou macroscopiques, délimitées ou transverses) pour mener les projets de transformation de l’entreprise au mieux.
L’outil d’AE, l’ouvrir aux opérationnels ou pas ?
Pour garantir la mise à jour régulière du référentiel d’architecture, l’implication des équipes opérationnelles (exploitation, projet, développement, intégration) est indispensable. Car ce sont eux, les « sachants » !
Or, si les équipes opérationnelles ont besoin de connaître l’historique des incidents et évolutions de l’application, ses certificats associés et ses contrats de support, les architectes souhaitent principalement visualiser l’existant et bénéficier d’analyse d’impacts exhaustives sur un périmètre précis.
Pour autant, faut-il que l’outil d’AE se plie aux besoins des équipes opérationnelles pour garantir sa mise à jour effective ?
La réponse à cette question réside dans le fait que pour faire fonctionner un logiciel d’architecture, il faut se focaliser d’abord sur un ou deux cas d’usage majeurs, avant d’en élargir l’utilisation au gré des opportunités et des besoins. Que ce soit un outil flexible succinct ou un imposant dino, il faut revoir à la baisse les attentes vis-à-vis d’un outil d’Architecture d’Entreprise.
L’enjeu est donc de bien cadrer le scope. Votre outil d’Architecture d’Entreprise peut très bien se contenter de renseigner les grands jalons et dates d’atterrissage, afin de donner de la visibilité au métier et à la Direction informatique sur les applications et projets qui vont impacter le Système d’Information.
Dans tous les cas, le niveau de granularité des informations à renseigner reste l’élément le plus structurant pour un tel outil. Savoir quoi renseigner, par qui, jusqu’à quelle maille et surtout à quel moment demeure la clé pour garantir un référentiel cohérent et mis à jour régulièrement.
L’Architecture d’Entreprise en libre-service
N’essayons pas de faire monter les projets sur nos vastes outils d’Architecture d’Entreprise. Soyons clairs, ils ne sont pas adaptés à la capacité et à la philosophie des équipes projets.
Avec un EAMS aussi simple qu’une appli de smartphone (à la navigation fluide, sans formation nécessaire et au contenu aisément partageable), les développeurs membres d’une équipe agile bénéficieraient des apports de l’AE et de sa connaissance du métier, de l’IT comme de l’entreprise dans son ensemble, sans alourdir leur charge.
Peut-être le secret réside-t-il dans la conception à deux entrées de l’outil d’AE : un grain précis et spécialisé pour les équipes opérationnelles et un grain macroscopique pour les responsables de pôle, les architectes et les directeurs (opérations, architecture, études, métier…), gérant les roadmaps et permettant l’alignement du SI sur les besoins du métier.
Architectes et équipes projets, qu’en pensez-vous ?
Edge computing vs cloud computing, deux modèles complémentaires ?
Edge computing versus cloud computing, deux modèles complémentaires?
2 septembre 2020
– 6 min de lecture
Architecture
Mohammed Bouchta
Consultant Senior Architecture
Pendant la dernière décennie, nous avons assisté à la montée en puissance du Cloud Computing dans les nouvelles conceptions d’architecture SI.
Sa flexibilité faisant abstraction de la complexité des infrastructures techniques sous-jacentes (IaaS, PaaS) et son mode de facturation à la consommation (Pay as you go) étaient des atouts suffisants pour convaincre les premiers clients. Mais c’est surtout le développement d’un nombre important de nouveaux services innovants avec une grande valeur ajoutée qui a mené la plupart des entreprises à adopter le Cloud. C’est ainsi par exemple que la grande majorité des entreprises ont pu expérimenter le Big Data, le Machine Learning et l’IA sans avoir à débourser des sommes astronomiques dans le matériel approprié en interne.
Le Cloud a facilité également le développement du secteur de l’IoT, ces objets connectés dotés de capteurs qui envoient leurs données régulièrement à un système central pour les analyser. En effet, le Cloud a fourni une panoplie de services pour absorber toutes les données collectées et une puissance de calcul importante pour les traiter et les analyser.
Cependant, le besoin de prendre des décisions en temps réel sans être tributaire de la latence du Cloud et de la connectivité dans certains cas, donne du fil à retordre aux experts lorsque les sources de données commencent à devenir extrêmement nombreuses.
Ainsi, d’autres besoins beaucoup plus critiques ont émergé en lien avec l’utilisation des objets connectés qui nécessitent des performances importantes en temps réel, et ceci même en mode déconnecté. Nous pouvons le constater par exemple dans les plateformes pétrolières en mer, les chaînes logistiques ou les véhicules connectés qui nécessitent une prise de décision locale en temps réel alors que le partage des données sur le Cloud permettra de faire des analyses plus globales combinant les données reçues, mais sans exigence forte sur le temps de traitement.
Ce sont ces contraintes et d’autres encore comme la sécurité des transmissions et la gestion de l’autonomie, qui ont donné naissance à un nouveau paradigme d’architecture, celui du Edge Computing.
Gartner estime que d’ici 2025, 75% des données seront traitées en dehors du centre de données traditionnel ou du Cloud.¹
Que signifie le edge computing exactement ?
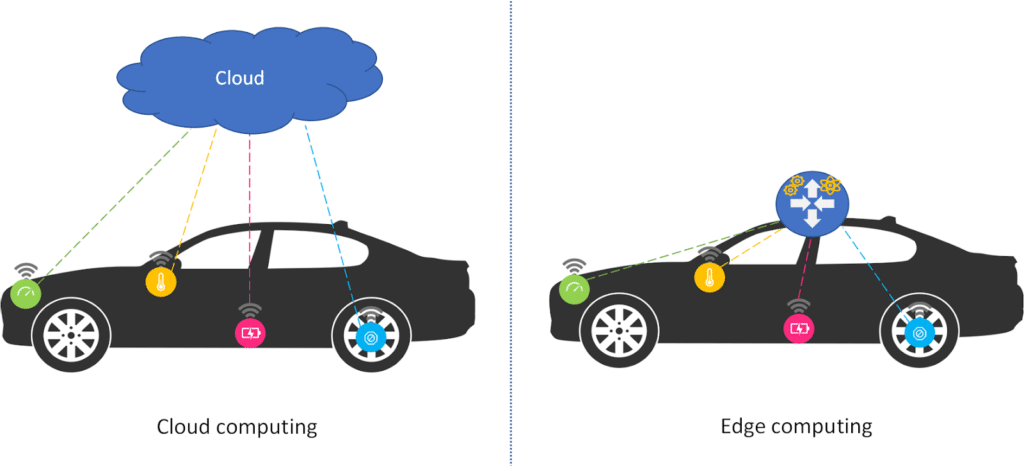
À l’opposé du Cloud Computing qui tend à déplacer tous les traitements dans le Cloud, le Edge Computing vise à rapprocher la puissance de calcul, le stockage et les applications de l’endroit où la donnée a été créée. Cela permet ainsi de pallier les problèmes de connectivité, de latence et les risques liés à la sécurité.
Avec le Edge Computing, l’analyse des données peut se faire directement sur le périphérique qui les a générés, comme par exemple les smartphones ou les objets connectés qui ont des ressources suffisantes. Si l’objet connecté est limité en ressources de calcul, de stockage, de connectivité ou d’énergie, comme dans la majorité des cas, alors c’est une passerelle IoT équipée de ces capacités, qui prend en charge la collecte, la transformation, l’analyse des données et la prise de décision / action.
Cette décentralisation du stockage et du traitement des données permet de répondre aux exigences de la prise de décision en temps réel.
Prenons l’exemple de la voiture autonome dans une situation de danger imminent, nous devons envoyer la globalité des données des capteurs sur un Cloud pour les analyser et attendre que le Cloud renvoie à la voiture les directives à suivre pour éviter l’accident. Même avec toute la puissance de calcul du Cloud, le temps de latence imposé par le réseau peut mener à la catastrophe. Alors qu’avec une analyse des données et une prise de décision locale, en temps réel, la voiture aura une chance d’éviter l’accident.
Ou l’exemple d’une machine dans une chaîne de production qui doit adapter sa vitesse d’action par rapport à plusieurs facteurs environnants qui proviennent des appareils de la chaîne. L’utilisation du Edge Computing au niveau de la Gateway IoT (passerelle) permet de récupérer les données nécessaires des périphériques locaux pour analyser et ajuster la vitesse de la machine en conséquence sans avoir à passer par le Cloud.
L’autre atout majeur du Edge Computing est sa résilience. Le système local peut continuer à fonctionner même s’il y a une défaillance majeure dans le Cloud, dans le réseau ou sur d’autre branche du système.
Toutefois, il ne faut pas croire qu’il est simple de mettre en place ce type d’architecture, bien au contraire. En effet, nous revenons à une architecture distribuée qui nécessite des appareils avec des ressources plus importantes (donc plus chères) et souvent avec des technologies hétérogènes qui doivent s’interfacer ensemble pour communiquer, ce qui complexifie l’administration et la maintenance. Aussi, en stockant les données en local, le problème de sécurité des données est déplacé vers les périphériques qui les stockent. Que ce soient les objets connectés ou la Gateway IoT, ces appareils peuvent être accessibles physiquement et sont donc plus vulnérables à un piratage. Ces périphériques devront se doter d’une politique de sécurité accrue pour s’en prémunir.
Ce changement d’approche a ouvert des opportunités pour les fournisseurs de télécommunications qui développent de nouveaux services liés à la 5G, à l’IoT et à d’autres technologies. Il a poussé les différents acteurs du marché à innover pour proposer des offres plus adaptées au Edge Computing. C’est ainsi que les leaders en matériel informatique comme Cisco, Dell EMC et HP par exemple ont tous mis sur le marché des produits dédiés à ce type d’architecture. Les géants du Cloud ont aussi réagi en force à cette tendance avec une palette de services qui peuvent s’étendre jusqu’aux périphériques connectés pour agir localement sur les données.
D’autre part, les avancées technologiques en matière de microcontrôleurs toujours plus miniaturisés, puissants et avec une consommation réduite de l’énergie, ont permis de faire de l’IA embarquée dans les objets connectés afin d’être plus rapide et efficace dans la prise de décision.
Vers la fin du cloud computing ?
Absolument pas ! Le Cloud a encore de belles années devant lui. En réalité, les deux solutions sont complémentaires et c’est le type de traitement nécessaire, le temps de réponse attendu et les exigences de sécurité qui vont déterminer ce qui doit être traité au niveau du Edge et ce qui doit être envoyé vers le Cloud.
Si nous reprenons le cas de voiture connectée, le Cloud va permettre d’agréger les données envoyées par toutes les voitures afin de les traiter, de les comparer et de faire des analyses approfondies pour optimiser les algorithmes de conduite et le modèle IA à déployer comme nouvelle version du programme embarqué dans les voitures connectées.
En combinant le potentiel de collecte et de l’analyse en temps réel des données du Edge Computing avec la capacité de stockage et la puissance de traitement du Cloud, les objets IoT peuvent être exploités de façon rapide et efficace sans sacrifier les précieuses données analytiques qui pourraient aider à améliorer les services et à stimuler l’innovation.
En conclusion
Il est peu probable que l’avenir de l’infrastructure réseau se situe uniquement dans le Edge ou dans le Cloud, mais plutôt quelque part entre les deux. Il est possible de tirer la meilleure partie de leurs avantages respectifs. Les avantages du Cloud Computing sont évidents, mais pour certaines applications, il est essentiel de rapprocher les données gourmandes en bande passante et les applications sensibles à la latence de l’utilisateur final et de déplacer les processus du Cloud vers le Edge. Cependant, l’adoption généralisée du Edge Computing prendra du temps, car le processus de mise en œuvre d’une telle architecture nécessite une expertise technique approfondie.
En fin de compte, vous devez toujours commencer par bien cibler les usages, les exigences et les contraintes de votre système pour choisir la bonne architecture.
Depuis quelques années nous observons une croissance rapide du marché Cloud Public. Les offres Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP) sont arrivées maintenant à maturité.
Une jeune entreprise ou startup qui cherche à déployer une nouvelle application métier ne va même plus considérer d’acheter ou d’opérer des serveurs dans son data center ou via un hébergeur plus traditionnel. Afin de répondre à la demande de certaines entreprises, ces trois leaders sur le marché du Cloud Public ont tous sorti ces dernières années une solution permettant le Cloud Hybride. Mais que valent aujourd’hui ces solutions ? A quels cas d’usage permettent-elles de répondre ? Nous allons tenter de répondre à ces quelques questions dans cet article.
Les différentes stratégies d’adoption ou de migration vers le cloud
Si, pour certaines entreprises, une stratégie Cloud-First basée sur un seul fournisseur peut paraître tentante, celle-ci n’est pas sans risque comme nous l’avons expliqué dans notre article : Les 5 mythes associés à une stratégie Cloud-First.
D’autres vont adopter une stratégie multi-Cloud, c’est-à-dire qu’elles vont retenir les services de plusieurs fournisseurs, qu’ils soient SaaS, PaaS ou IaaS, afin de ne pas mettre tous leurs œufs dans le même panier.
Enfin, certaines ont fait le choix d’adopter une stratégie Cloud Hybride, afin d’avoir la possibilité de déployer l’infrastructure : soit sur une plateforme Cloud Public soit sur leur data center On-Premise, soit sur un Cloud Privé.
Nous allons maintenant vous présenter chacune des solutions proposées par ces trois fournisseurs et vous expliquer leurs différences.
Azure stack
Azure Stack est un portfolio de produits qui existe depuis 2016 et décliné sous forme de 3 solutions : Hub, HCI, Edge.
Azure Stack Hub vous offre la possibilité de déployer vos applications modernes basées en particulier sur des microservices ou des containers On-Premise.
Azure Stack HCI permet de déployer des ressources compute et de stockage pour des bureaux ou des usines qui nécessitent d’avoir des ressources en locales.
Enfin, il existe aussi Azure Stack Edge pour répondre aux cas d’usages nécessitant des capacités d’intelligence Artificielle et de Machine Learning en local.
Chacune de ces solutions n’a pas tout à fait la même couverture fonctionnelle (et le modèle des prix est aussi différent) que les services Cloud associés. Ces offres viennent sans matériel et celui-ci devra être acheté en sus parmi une gamme certifiée par Microsoft.
AWS Outpost
AWS a annoncé la sortie de sa solution Cloud Hybride fin 2019. Cela permet d’exécuter les services EC2, EBS, EMR et bientôt S3 en local. La solution comprend l’infrastructure et est livrée sous la forme d’une appliance. A noter que la solution Outpost ne permet pas de déployer ses services sur les autres fournisseurs Cloud Public.
AWS Snowflake
A noter aussi, ce service qui dans sa version Snowball Edge Storage Optimized permet d’avoir au sein d’un boîtier du stockage par bloc ou objet, de la CPU et un accès à certains algorithmes de Machine Learning. Ceci peut être pratique notamment pour des professionnels dans le multimédia ou la santé ayant besoin de faire des recherches avancées sur le contenu de très large bibliothèques de vidéos ou de photos en local sans avoir à les partager sur des services grands publics sur internet.
Anthos
La solution de Google est basée sur Kubernetes et permet pour des CloudOps familiers avec cet outil de déployer leurs applications basées sur des microservices à la fois On-Premise et sur d’autres fournisseurs Cloud Public.
VMWare
Il ne faut pas oublier que, depuis quelques années, Azure, AWS et Google offrent également la possibilité aux clients utilisant la solution de virtualisation VMWare d’étendre leurs ressources sur le Cloud Public.
IOT
Des solutions IOT mixant des ressources en ligne, Edge et On-Premise sont également disponibles mais celles-ci seront l’objet d’un prochain article.
A quels cas d’usage ou problématiques peuvent répondre ces solutions ?
Ces différentes solutions permettant de faire du Cloud Hybride peuvent être intéressantes pour certains cas d’usage. A titre d’exemples, nous pouvons citer :
Tirer parti de ressources compute, stockage et d’analyse sur des sites ayant besoin de croiser des données avec des systèmes de gestion hébergés en local.
Certains sites ou bureaux (ex : des points de vente) ont besoin d’exécuter des traitements critiques nécessitant des temps de réponses presque immédiats. Cela peut aussi être des transactions qui ne tolèrent pas les problèmes réseaux (ex : encaissement des achats clients).
Dans le cas précis d’Anthos ou d’Azure Stack, cela permet de capitaliser sur vos compétences internes et de pouvoir avoir une seule usine logicielle CI/CD pouvant être déployée sur plusieurs plateformes.
Enfin toutes ces solutions peuvent aussi servir comme option pour les applications nécessitant un Plan de Reprise d’Activité (PRA), pour faciliter vos migrations sur le Cloud Public ou pour faire du débordement pour absorber des pics de charge saisonnier à moindre coût.
Le revers de la médaille de ces solutions est que souvent seuls les services de base (IaaS, CaaS, certaines briques PaaS) sont proposés. Chaque année, les fournisseurs déploient des centaines, voire même des milliers d’innovations sur leurs propres data centers, dont vous ne pourrez pas bénéficier au fil de l’eau sur votre Stack Cloud OnPremise. Les plateformes Big Data ou e-Commerce ayant le plus besoin d’élasticité et de ressources quasi illimitées ne seront pas de bons candidats pour ce mode de déploiement.
Il ne faut pas se tromper, si Microsoft, Google et AWS disposent tous d’une solution pour faire du Cloud Hybride, c’est bien parce qu’il y a une forte demande même si cela permet de répondre à des cas d’usages bien précis. En 2017, la taille du marché pour le Cloud Hybride était estimée à 36 milliards $. Les analystes prévoient que celui-ci atteindra 171 milliards d’ici 2025 ! Alors qui gagnera la course pour dominer ce marché ?
La Data a le vent en poupe. Le monde du digital vous impose de travailler à partir de vos données et il devient de plus en plus exigeant avec celles-ci. Vous avez donc besoin d’augmenter* la valeur propre de vos données (niveau de qualité, accessibilité, connaissance…) afin d’optimiser des usages existants, ou pour répondre à de nouveaux usages et gagner les opportunités business qui assureront le développement de votre entreprise.
La data, un vaste sujet
La direction a décidé que la Data était prioritaire : la grand-messe Data est lancée. Maintenant il faut construire et des sujets clefs commencent à apparaître : modélisation, gouvernance, dictionnaire de données, reprise des données, qualité de données, architecture fonctionnelle, architecture de données, échanges de données.
Des sujets clefs trop souvent sous-estimés : pourquoi ?
Parce que bien souvent, la première idée qui nous vient en tête est qu’une solution du marché existe et répondra à tous ces sujets. Le projet data devient un projet d’intégration SI et bien souvent ce projet est un échec.
Ensuite, parce qu’on ne voit pas à très court terme l’impact de ces sujets sur la maintenance des applications, les performances, la productivité, le time to market, la satisfaction client et les possibilités offertes par vos SI.
C’est la transversalité de la data et les nouveaux usages qui rendent complexes la conception des solutions pour répondre aux besoins adressés par les métiers.
Prenons l’exemple de la modélisation de données
Si vous mélangez le modèle physique et le modèle conceptuel, ou si vous ne comprenez pas bien les concepts fonctionnels manipulés lors des processus métiers, alors votre modèle de données ne répondra pas à tous les besoins adressés.
Et si en plus, les modifications de ce modèle au fur et à mesure des nouveaux besoins adressés ne sont pas suivies et validées de manière transverse par un architecte de données expérimenté, petit à petit, le SI que vous construisez tendra à devenir moins flexible et moins agile face aux besoins qui se multiplient et où vous avez besoin d’aller vite.
Une conséquence est que la conception des portails qui vont utiliser vos données sera plus complexe et pourra avoir des impacts forts sur les performances. Une autre est que vous ne serez pas capable d’absorber les données d’autres SI à l’échelle de l’entreprise (futures acquisitions, futurs décommissionnements pour obsolescence, changement d’architectures, etc.).
La modélisation n’est qu’un exemple
C’est un processus lent et qui ne se voit pas. Face au marché qui ne vous attendra pas, vous serez alors plus lent que les nouvelles demandes qui apparaissent, et vous ne serez pas en mesure de les anticiper. Mal modéliser c’est lentement se créer des blocages SI quand il faudra répondre à de futurs besoins. Adressez donc le sujet modélisation à une personne experte dans votre organisation.
La modélisation est un exemple, mais la gouvernance, la qualité des données, les habilitations sur les données ont des impacts tout aussi similaires.
Exigez le savoir-faire
Donc non tout le monde ne peut pas se décréter Modélisateur, Analyste de données ou Chief Data Officer. Ne lancez pas des projets Data si vous n’avez aucune expérience sur le sujet, ni les compétences nécessaires. Sachez les identifier. L’enjeu se joue au niveau de chaque data utile à un usage. Chaque data manipulée, modélisée, mappée, extraite et exposée sur lesquelles travaillent chacune des personnes qui vont construire votre SI.
Comme pour la modélisation, est-ce que les équipes de vos projets ont l’expérience nécessaire pour visualiser l’impact de leur microdécision à chaque phase de la conception ? Je vous garantis que non !
Des compétences et de l’expérience sont absolument nécessaires pour prendre du recul et traiter le projet selon les exigences spécifiques liées à la data, en plus des besoins des métiers et des exigences SI.
Alors entourez-vous, recrutez les profils qui l’ont déjà fait et cherchez les acteurs du marché** qui sont au fait des dernières technologies, car c’est votre survie digitale qui en dépend !
* Comment valoriser vos données ? Le livre blanc ‘Augmentez la valeur de vos données’ Rhapsodies Conseil est là pour répondre à vos interrogations.
Rhapsodies Conseil accompagne les Chiefs Data Officer ou toute personne ayant une responsabilité sur les données à tirer parti de cet actif stratégique.
Les dimensions et les activités à traiter pour augmenter la valeur des données sont nombreuses : usages, culture data, maîtrise et gouvernance des données, amélioration des compétences, technologies data… Indispensable pour une organisation qui veut gérer ses données comme des actifs stratégiques, le rôle de CDO est encore récent dans de nombreuses organisations, où il faut trouver la meilleure articulation avec les Métiers, la DSI, mais aussi la Direction Générale.
Nos collaborations avec différents CDO ont motivé la formalisation d’un cadre complet et opérationnel au service de la transformation data : “Le Framework du CDO”. Les fiches pratiques de notre Framework pose le cadre qui structure la mise en œuvre de la transformation data d’une organisation avec l’ambition d’être un guide et un accélérateur de cette transformation au quotidien.
Celui, ou celle, que l’on appelait avant Architecte Fonctionnel et que l’on appelle à présent Architecte d’Entreprise (AE), a vu son domaine d’intervention être siloté avec une approche qui a privilégié les processus souvent au détriment des données.
La notion d’Architecte Data a donc vu le jour sur le marché, ou même Data Architect pour lui donner une aura internationale. A la manière des architectes SI ou techniques qui sont complémentaires aux AE, Est-ce la cas pour l’Architecte Data ? L’est-il ou fait-il exactement la même chose que l’AE sur les données ?
Mais pourquoi tout le monde veut ma place ?
De mon point de vue, l’architecte d’entreprise subit les conséquences d’une posture qui a fini par lui porter préjudice. Le fameux « architecte dans sa tour qui ne comprend pas les contraintes des gens qui font vraiment de l’informatique », réputation contre laquelle nous luttons tous les jours mais qui, nous devons bien nous l’avouer, existe encore parfois.
Un autre problème est lié au vocabulaire que nous utilisons. Un but de notre métier consiste à savoir si tel ou tel développement doit être fait dans telle ou telle application, et pour cela nous travaillons avec les fonctions. Alors une fonction, tout le monde pense savoir de quoi il s’agit mais ce n’est souvent pas le cas, et cela est moins parlant qu’une « Donnée ». De plus, les justifications pour regrouper des fonctions sont floues : cohérents, logiques,… sont des mots à bannir de notre vocabulaire.
Pour commencer : qu’est-ce qu’une fonction ?
Si on demande à Larousse, la définition d’une fonction est la suivante : « Ensemble d’instructions constituant un sous-programme identifié par un nom, qui se trouve implanté en mémoire morte ou dans un programme ». Personnellement, j’en ai une autre : une fonction est une instruction visant à modifier une caractéristique d’un objet.
La raison pour laquelle je préfère ma définition est que le mot objet permet de faire le lien avec un des éléments qui permettent de construire l’architecture fonctionnelle de votre SI.
Comment construisez-vous votre plan fonctionnel ?
Lorsque notre ami architecte d’entreprise définit un plan d’urbanisme fonctionnelde son système d’information, c’est qu’il veut mettre en évidence les fonctions nécessaires aux métiers. Mais quels sont les critères de regroupement ?
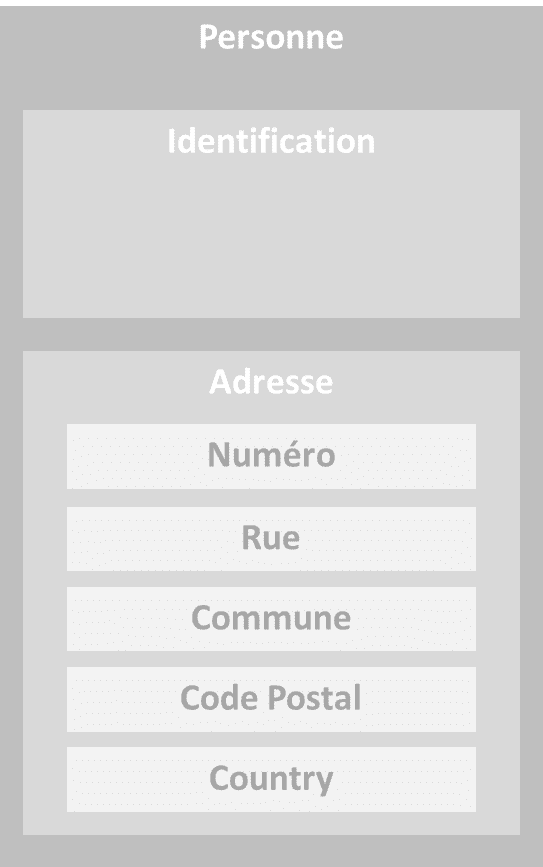
Le principal critère de regroupement, c’est la donnée. Pour bien comprendre, prenons l’exemple de l’objet, et donc de la donnée, « Personne » dans le cadre simplifié d’un site de distribution. Toutes les fonctions de l’objet « Personne » sont donc rangées dans le bloc Personne. Prenons ensuite les fonctions rangées dans le quartier Adresse. Ce sont des fonctions qui sont appelées, et donc des données qui sont modifiées, dans un même cas d’usage. Quand une personne déménage, les données liées aux fonctions dans le quartier Adresse sont modifiées. Enfin dans un ilot, vous allez retrouver toutes les fonctions qui peuvent modifier une information particulière : Modifier la rue, modifier le numéro, modifier la ville.
Cet exemple est concentré sur l’objet « Personne » mais cela est vrai pour la globalité de l’entreprise. Le modèle de donnée de l’entreprise est donc nécessaire pour construire un plan fonctionnel global de l’entreprise.
Mais comment parler avec les projets ?
Il faut arrêter de parler de fonctions avec vos projets, ne dites pas « quelles sont les fonctions que vous voulez ajouter » mais « quelles sont les données que vous allez impacter ». Charge à l’architecte d’identifier ensuite les fonctions. Il faut parler le même langage que lui, lui faire comprendre la valeur qu’on lui apporte et ce sera gagné.
L’Architecte Data est un architecte comme les autres. C’est son approche par les données qui met en avant les problèmes de gouvernance auxquels l’architecte fonctionnel était déjà confronté auparavant, alors « Reprenons notre dû, reprenons les data ! »