Pour répondre aux nouveaux besoins et usages des patients et des professionnels de santé, notre client a opéré une refonte organisationnelle et une révision de son modèle d’engagement client. Le but est de mettre en œuvre des parcours personnalisés et omnicanaux, et être ainsi « Customer Centric ».
Ces changements doivent être accompagnés par la mise en place d’un Programme d’Apprentissage et d’Expérimentation, appelé OmniReady, à destination des collaborateurs sur les thèmes de l’Omnicanalité, du Digital et de l’Expérience Client.
Missions
Co-construire le Programme d’Accompagnement OmniReady avec la taskforce interne : les ambitions, la feuille de route, les objectifs, les KPIs et le mode opératoire de déploiement
Déployer les différentes composantes d’accompagnement. Les maîtres mots sont l’expérimentation, des cas d’usages concrets et de l’inspiration de bonnes pratiques du marché
Formaliser les les modalités de gouvernance du programme et les indicateurs de pilotage de type OKR pour garantir la pérennité et la valeur d’OmniReady
Résultats & bénéfices
Co-construction : des ateliers collaboratifs avec la taskforce pour poser les fondations du Programme OmniReady : ambitions, KPIs, cibles, feuille de route, modalités d’assessment, etc.
Collaboration : des journées séminaires pour embarquer les leaders et la population du terrain reposant sur la vision, l’inspiration et l’expérimentation avec des cas d’usages concrets
Apprentissage personnalisé : des contenus et des modules d’apprentissage accessibles sur un GSite pour ancrer ses connaissances et savoir où (re)trouver la bonne information
Expérimentation : des vagues d’Expérimentations : ateliers en collectif autour de problématiques métiers, de manipulation d’outils et centrés sur les retours d’expérience de ses pairs
Inspiration : des communications mails envoyées à tous les collaborateurs sur des thèmes comme la Data, l’Expérience Client ou encore du Digital
Démarche agile : un déploiement avec une approche progressive et pragmatique en sprints pour accompagner le changement par paliers et progresser en amélioration continue
D’autres Success Stories qui pourraient vous intéresser
Notre client du secteur bancaire souhaite construire le socle d’un chantier de transformation Numérique Responsable au sein de sa DSI. Ce chantier s’inscrit également dans la labellisation NR de la filière SI Groupe qui rend le contexte d’autant plus favorable.Les enjeux de la mission se trouve dans l’alignement stratégique entre filière SI Groupe et filière SI BDT, la mobilisation des parties prenantes pour faciliter l’adoption des pratiques NR, des résultats tangibles pour montrer rapidement des impacts concrets, l’optimisation des ressources pour promouvoir l’écoconception comme un levier frugal tant sur le volet économique qu’écologique, et enfin, la structuration organisationnelle pour s’intégrer dans les processus et gouvernances existants afin de pérenniser l’initiative.
Missions
La mission se divise en 4 axes :
Axe 1 : Stratégie NR Construire les ambitions et les objectifs NR de la filière SI BDT et embarquer les parties prenantes clés dans la définition de ces ambitions
Axe 2 : Construction et déploiement du cadre d’éco-conception Élaborer un cadre d’éco-conception pragmatique adapté aux méthodologies actuelles et le tester puis l’affiner sur deux projets pilotes
Axe 3 : Sensibilisation & Formation Former les acteurs opérationnelles des projets pilotes aux bonnes pratiques d’éco-conception dans les projets IT
Axe 4 : Organisation & Gouvernance Intégrer l’éco-conception by-design dans les gouvernances existantes, proposer des principes organisationnels et mettre en place une gouvernance pour le suivi et la pérennisation des actions NR tout en suivant le chantier de labellisation NR de la filière SI Groupe.
Résultats et bénéfices
Mission en cours, livrables identifiés :
Axe 1 : Audit de l’existant, Ambitions & objectifs NR, supports de présentations et constitution d’une Core Team
Axe 2 : Cadre d’éco-conception, Expression de besoin pour de l’outillage transverse NR et synthèses d’ateliers de travail
Axe 3 : Séminaires NR, Sessions de formations (+ supports), Plan & Besoin de formation NR sur 2026
Axe 4 : Animations de COMOP, éléments NR intégrés au processus de gouvernance SI BDT, livrables de labellisation NR
Le pôle data accompagne une direction métier souhaitant s’équiper à courte échéance d’outils de BI dans l’intention de piloter son activité. Une équipe de 8 personnes est mobilisée. Différents profils constituent l’équipe (Project Manager, Business Data Analyst, Analytic Engineer) dont les niveaux d’expérience varient (apprentis, personnes en changement de poste récent, profils seniors et juniors).
La qualité des livrables attendue est élevée : l’ensemble de produits doivent être cohérents, en termes de design technique et design d’interface, et soutenus par une chaîne de valeur data robuste et réemployable par d’autres projets.
Qui plus est, les enjeux du projet sont centraux pour la stratégie de la direction métier.
Le Framework du projet BI&A élaboré par l’équipe Transformation Data a fourni une base de travail adaptable au contexte de ce projet. Les incontournables d’un projet de Business Intelligence y sont listés par ordre chronologique :
Analyse du besoin métier
Maquettage de la solution de datavisualisation
Conception de la solution data
Déploiement et Industrialisation de la solution
Amélioration continue
Une fois les grands principes du framework énoncés, nous avons déployé chez notre client une panoplie de pratiques et d’outils pour assurer la coordination de l’équipe projet aux compétences et expériences hétérogènes:
1. Un point d’équipe pour favoriser la circulation d’information, le partage de bonnes pratiques et la montée en compétence :
Une revue de espace de développement en séance
Une communication des data engineers
Un rappel et réajustement des objectifs de développement à moyen terme
Un suivi d’action transverse
La présentation d’un modèle de donnée par un des développeurs
La présentation par un membre volontaire d’un sujet au choix (technique de visualisation, culture informatique, organisation du travail, …)
2. Des communications internes projet et externes via des canaux dédiés pour impliquer les partenaires du projet (sponsors et utilisateurs)
via une landing page Sharepoint avec lien vers les contenus de ref (EB, Note de cadrage, …) pour les sponsors et parties prenantes métiers
via des Canal teams dédiés en fonction des types de communications (incidents et succès, mise à jour de rapports, questions à la communauté utilisateur)
3. Des supports pédagogiques pour vulgariser l’environnement technique et diffuser les bonnes pratiques de datavisualisation à tous les membres de l’équipe
4. Un stockage de la documentation projet avec des arborescences de dossier imposées et une nomenclature projet pour le nommage de fichier
Bénéfices
Le projet aboutit à la mise en production d’outils de pilotage de l’activité de la direction métier, et ce en respectant les délais et le budget annoncés pendant la phase de cadrage.
Les pratiques mises en place et adoptées au sein de l’équipe ont fortement contribué au succès de ce projet, et profitent au-delà de celui-ci. En effet, la communication projet interne et externe, ainsi que la structuration de la documentation ont permis de :
Faire foisonner les idées et ainsi proposer des produits complémentaires qui répondaient à d’autres besoins de la direction métier;
Accélérer le développement et d’améliorer la qualité des produits;
Assurer la transmission de l’ensemble des responsabilités de maintenance des outils en production sur un membre interne à l’organisation, et ce de manière naturelle ;
Garantir l’insertion des produits dans les processus existants.
De plus, on peut noter que les produits data et les documents projet ont pu être exploités par d’autres projets alors même que le projet n’était pas terminé.
Finalement, en fin de projet les alternants membres de l’équipe étaient autonomes pour interpréter un besoin métier et le retranscrire en un développement dans l’outil de datavisualisation.
Autres Success Stories qui pourraient vous intéresser
Nous vous accompagnons dans le pilotage de votre architecture
18 décembre 2024
– 3 minutes de lecture
Architecture
Olivier Constant
Senior Manager Architecture
Nous vous accompagnons dans le pilotage de votre architecture
Aujourd’hui, nous repartageons une success story de notre mission chez un acteur majeur du secteur bancaire. Olivier et ses équipes sont intervenus pour accompagner de façon globale ce client sur son architecture d’entreprise au travers d’un centre de services.
N’hésitez pas à nous contacter pour plus d’informations ! 💬
Les autres sucess story qui peuvent vous intéresser
Envie d’intégrer l’intelligence artificielle à vos processus métiers ?
Envie d'intégrer l'intelligence artificielle à vos processus métiers ?
L’intelligence artificielle à vos processus métiers
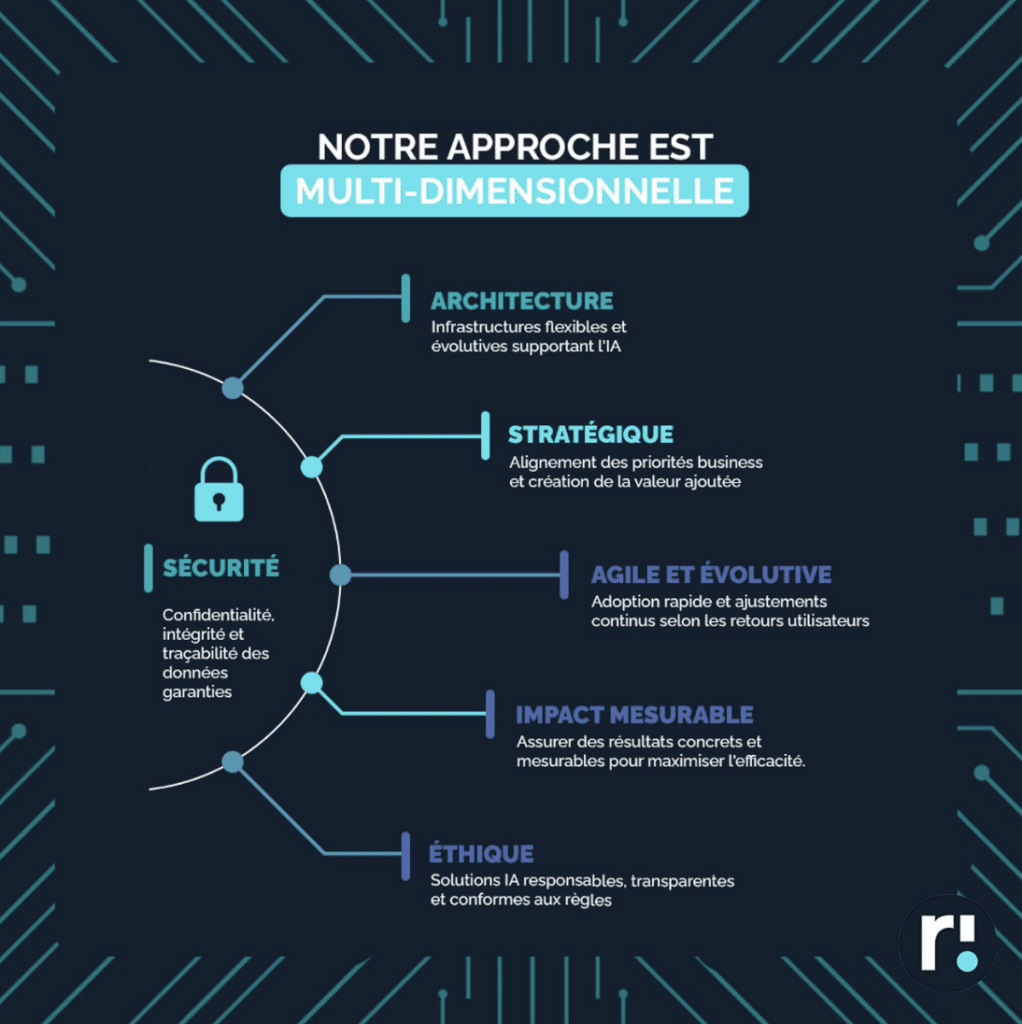
Chez Rhapsodies Conseil, nous vous accompagnons à chaque étape pour maximiser votre potentiel IA.
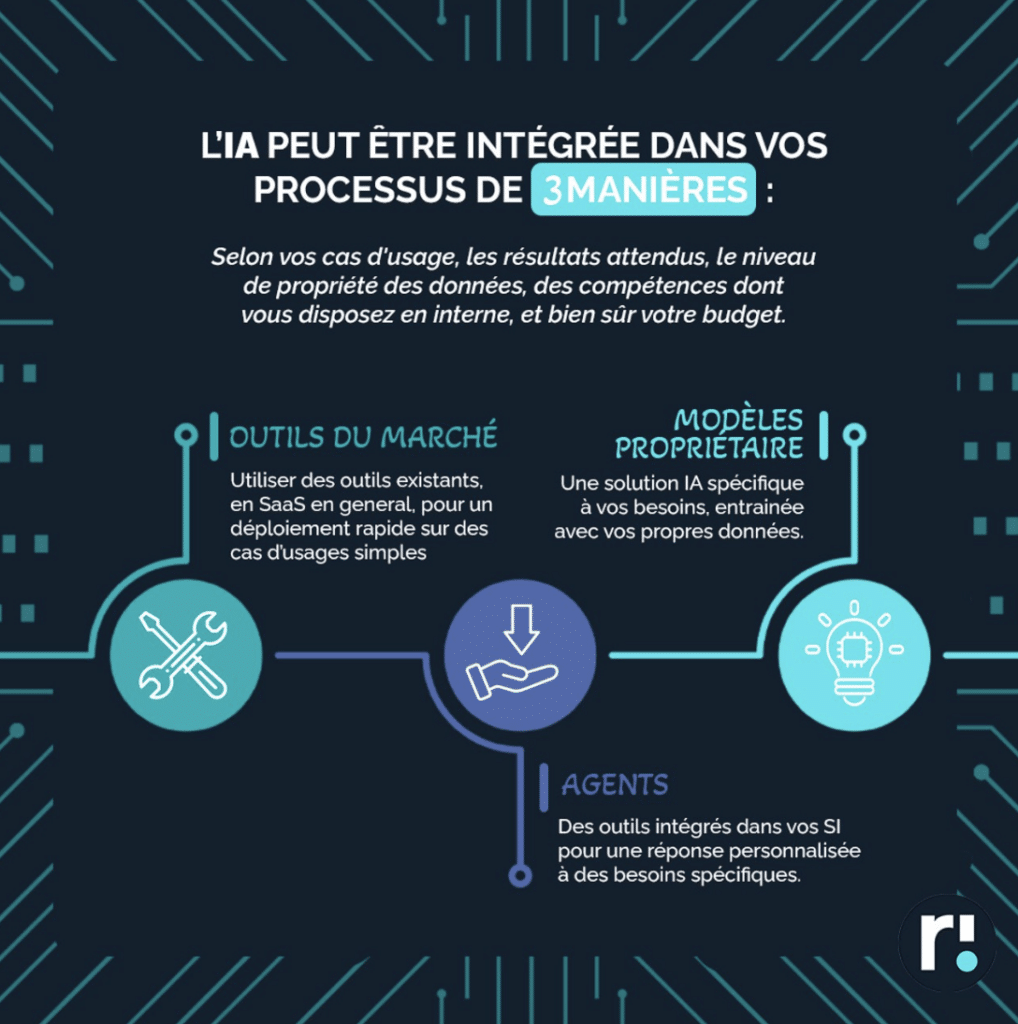
Notre expertise vous propose trois approches pour tirer parti de l’IA : des outils préexistants, des agents personnalisés ou des modèles sur mesure. Chaque solution s’adapte à vos besoins, budget et ressources internes.
Vous souhaitez en savoir plus ? 🔍
Parlons de votre projet IA et découvrez comment Rhapsodies Conseil peut transformer vos idées en actions concrètes.
D’autres sujets d’expertise qui pourraient vous intéresser
10 février 2025
Pilotage & Performance Opérationnelle et Contractuelle