J’ai analysé Pro Santé Connect, un service fort intéressant avec plein de potentiels, réalisé dans les règles de l’art et qui suit les standards actuels du domaine de l’authentification. Mon retour : j’adore ! (oui bon laissez-moi mes kiffes hein…).
Pro Santé Connect, c’est quoi ?
Il s’agit d’un service d’authentification et d’identification des professionnels de santé.
Ce service est construit sur les bases des standards du marché actuel : OAUTH2 pour l’authentification et, cerise sur le gâteau, de l’OpenID Connect pour avoir le complément d’information d’identification qui va bien : que pouvons-nous demander de plus ?
À quoi sert Pro Santé Connect ?
Ce service permet qu’un organisme d’état certifie :
La personne qui est en train de s’authentifier est bien celle qu’elle dit être, avec des preuves à l’appui ;
La personne qui accède à mon site dispose bien de certaines caractéristiques qui ne viennent pas d’une auto-déclaration mais d’informations recensées et vérifiées au niveau des organismes d’État ;
Ces informations sont transmises de façon sécurisée et non corruptibles (jetons JWT signés).
Pour être clair, il fonctionne un peu comme France Connect, mais son caractère médical, associé aux caractéristiques spécifiques de la profession, sécurisé et complété par l’OiDC, ouvre la possibilité d’exploiter beaucoup plus d’informations : quel est son lieu de travail ? dans quel établissement ? quelle spécialisation médicale le professionnel pratique ? et d’autres encore…
Pour finir, ces informations peuvent être propagées à des applications tierces, avec un simple transfert de jeton sécurisé, ce qui permet d’éviter les surcoûts et les efforts d’authentification à plusieurs niveaux.
Et alors, on en pense quoi de ce service d’authentification ?
J’adore. Je n’aurais pas fait mieux, ni pire… Techniquement ça a l’air de tenir la route et même plus.
L’utilisation de standards reconnus et plébiscités par le marché, alors que personnellement j’en ai ch…, pardon bavé… Veuillez m’excuser, j’ai eu un peu de mal dans le passé avec des standards d’interconnexion mal documentés, incompréhensibles… Ils étaient pondus par des organismes publics qui, dans un souci de sécurisation, avaient rédigé des documents illisibles et impossibles à utiliser. Bref, je pense qu’ils n’ont jamais rencontré de problèmes de sécurité, vu que personne n’a dû réussir à les implémenter…
Dans le cas de Pro Santé Connect, ceux qui ont déjà implémenté de l’OAUTH2 ou de l’OiDC, se retrouvent dans un cadre familier, clair, bien documenté, enfin un vrai plaisir (bon au moins de mon point de vue hein… laissez moi ce plaisir…). Pour les autres, ces standards sont tellement bien documentés que, avec un peu d’effort de lecture, on peut vite en comprendre les concepts.
Des informations certifiées, complètes, simples à lire ? Il est où le pépin ?
C’est beau tout ça, magnifique, dans ce monde parfait nous n’avons plus rien à craindre ! Plus de questions à se poser ! Nah…
Bon ce n’est pas forcément le cas, une alerte reste d’actualité et se base sur un concept cher à pas mal de DSI : la qualité des données traitées et leur fraîcheur.
Si le service a une chance de marcher tel qu’il est présenté, la collecte des informations devra se faire :
Dans des délais très courts, à partir du changement de situation du professionnel de santé ;
Avec une qualité irréprochable.
Or, la fusion de plusieurs référentiels dans un seul (le RPPS), en cours, plus l’effort que l’ANS semble mettre dans cette initiative, laissent présager des bons résultats.
En conclusion
La voie est la bonne, techniquement pas de surprise, une implémentation reconnue et éprouvée, un service qui nous plaît !
Et maintenant nous attendons le même service pour les personnes physiques, en lien avec Mon Espace Santé et les domaines associés !
Le 23 juin 2022, l’équipe Architecture a animé un événement dédié aux fondations digitales et data. C’était l’occasion de partager avec les participants les témoignages exceptionnels de Catherine Gapaillard (Groupama) et de Yannick Brahy (STIME – DSI du Groupement Les Mousquetaires).
Retour sur notre petit déjeuner événement
Nos intervenants ont pris le temps de partager leur contexte, leur expérience, les spécificités de leurs directions , ainsi que les leviers : organisation, gouvernance et outils mis en place pour soutenir leurs systèmes d’information
3 Temps forts ont rythmé cette matinée:
Comment Groupama se met en route vers une Entreprise Data Driven avec les socles data référentiels et data hub qui supportent la construction de leur domaine data par Catherine Gapaillard, Responsable de la division Urbanisme et Architecture.
Le partage de la Stime – DSI du groupement Les Mousquetaires, de la mise en place d’une stratégie de Data Intégration grâce à son Hybrid Integration Platform (HIP) par Yannick Brahy, Directeur de l’Architecture et de l’Urbanisme.
Les architectures de référence, qui associées à des principes directeurs de constructions du SI permettent de structurer des fondations digitales / data et définir une vision cible du SI et les trajectoires de transformation associées, par Damien Blandin, Directeur Associé de Rhapsodies Conseil
Téléchargez notre livre blanc Architecture SI – Nos modèles de référence
Revivez l’évènement en photo :
A propos de Rhapsodies Conseil
Créé en 2006, Rhapsodies Conseil est un cabinet indépendant de conseil en management. Sa vocation : accompagner les programmes de transformation de ses clients, depuis le cadrage jusqu’à leur mise en œuvre opérationnelle, sur 4 grands domaines d’expertise : Architecture & Transformation Data/ Digitale, Sourcing & Performance de la DSI, Paiements & Cash Management et enfin Agilité, Projets & Produits. Fort d’une centaine de consultants et d’une longue expérience de la transformation des processus et du SI, Rhapsodies Conseil intervient auprès des Grands Comptes et ETI de secteurs d’activité variés (Banque, Assurance, Services, Industrie, Luxe, e-commerce,…). Expertise, Indépendance, Engagement, Agilité, Partage, Innovation et Responsabilité sont les valeurs fondatrices du cainet et guident l’action de ses consultants au quotidien.
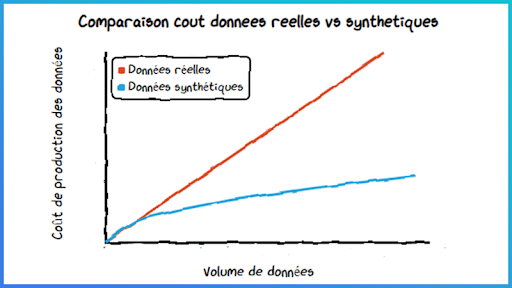
Dans un récent post de blog, le Gartner prévoit que d’ici 2030, 60% des données d’entrainement des modèles d’apprentissage seront générées artificiellement. Souvent considérées comme substituts de qualité moindre et uniquement utiles dans des contextes réglementaires forts ou en cas de volumétrie réduite ou déséquilibrée des datasets, les données synthétiques ont aujourd’hui un rôle fort à jouer dans les systèmes d’IA.
Nous dresserons donc dans cet article un portrait des données synthétiques, les différents usages gravitant autour de leur utilisation, leur histoire, les méthodologies et technologies de génération ainsi qu’un rapide overview des acteurs du marché.
Les données synthétiques, outil de performance et de confidentialité des modèles de machine learning
Vous avez dit données synthétiques ?
Le travail sur les données d’entrainement lors du développement d’un modèle de Machine Learning est une étape d’amélioration de ses performances parfois négligée, au profit d’un fine-tuning itératif et laborieux des hyperparamètres. Volumétrie trop faible, déséquilibre des classes, échantillons biaisés, sous-représentativité ou encore mauvaise qualité sont tout autant de problématiques à adresser. Cette attention portée aux données comme unique outil d’amélioration des performances a d’ailleurs été mis à l’honneur dans une récente compétition organisée par Andrew Ng, la Data-centric AI competition.
Également, le renforcement des différentes réglementations sur les données personnelles et la prise de conscience des particuliers sur la valeur de leurs données et la nécessité de les protéger imposent aujourd’hui aux entreprises de faire évoluer leurs pratiques analytiques. Fini « l’open bar » et les partages et transferts bruts, il est aujourd’hui indispensable de mettre en place des protections de l’asset données personnelles.
C’est ainsi qu’entre en jeu un outil bien pratique quand il s’agit d’adresser de front ces deux contraintes : les données synthétiques.
Par opposition aux données « traditionnelles » générées par des événements concrets et retranscrivant le fonctionnement de systèmes de la vie réelle, elles sont générées artificiellement par des algorithmes qui ingèrent des données réelles, s’entraînent sur les modèles de comportement, puis produisent des données entièrement artificielles qui conservent les caractéristiques statistiques de l’ensemble de données d’origine.
D’un point de vue utilisabilité data on peut alors adresser des situations où :
La donnée est coûteuse à collecter ou à produire – certains usages nécessitent par exemple l’acquisition de jeux de données auprès de data brokers. Ici, la génération et l’utilisation de données synthétiques permettent de diminuer les coûts d’acquisition et favorisent ainsi une économie d’échelle pour l’usage data considéré.
Le volume de données existant n’est pas suffisant pour l’application souhaitée – on peut citer les cas d’usage de détection de fraude ou de classification d’imagerie médicale, où les situations « d’anomalie » sont souvent bien moins représentées dans les jeux d’apprentissage. Dans certains cas, la donnée n’existe simplement pas et le phénomène que l’on souhaite modéliser n’est pas présent dans les datasets collectés. Dans ce cas d’usage, la génération de données synthétiques est toutefois à différencier des méthodes de « data augmentation », technique consistant à altérer une donnée existante pour en créer une nouvelle. Dans le cas d’une base d’images par exemple, ce processus d’augmentation pourra passer par des rotations, des colorisations, l’ajout de bruits… l’objectif étant d’aboutir à différentes versions de l’image de départ.
Il n’est pas nécessaire d’utiliser des données réelles, comme lors du développement d’un pipeline d’alimentation en données. Dans ces situations, un dataset synthétique peut être largement suffisant pour pouvoir itérer rapidement sur la mise en place de l’usage, sans se préoccuper de l’alimentation en données réelles en amont.
Mais comme vu précédemment, ces données synthétiques permettent aussi d’adresser certaines problématiques de confidentialité des données personnelles. En raison de leur nature synthétique, elles ne sont pas régies par les mêmes réglementations puisque non représentatives d’individus réels. Les data scientists peuvent donc utiliser en toute confiance ces données synthétiques pour leurs analyses et modélisations, sachant qu’elles se comporteront de la même manière que les données réelles. Cela protège simultanément la confidentialité des clients et atténue les risques (sécuritaires, concurrentiels, …) pour les entreprises qui en tirent parti, tout en levant les barrières de conformité imposées par le RGPD…
Parmi les bénéfices réglementaires de cette pratique :
Les cyber-attaques par techniques de ré-identification sont, par essence, inefficaces sur des jeux de données synthétiques, à la différence de datasets anonymisés : les données synthétiques n’étant pas issues du monde réel, le risque de ré-identification est ainsi nul.
La réglementation limite la durée pendant laquelle une entreprise peut conserver des données personnelles, ce qui peut rendre difficile la réalisation d’analyses à plus long terme, comme lorsqu’il s’agit de détecter une saisonnalité sur plusieurs années. Ici, les données synthétiques s’avèrent pratiques puisque non identifiantes : les entreprises ont ainsi le droit de conserver leurs données synthétiques aussi longtemps qu’elles le souhaitent. Ces données pourront être réutilisées à tout moment dans le futur pour effectuer de nouvelles analyses qui n’étaient pas menées auparavant ou même technologiquement irréalisables au moment de la collecte des données.
L’utilisation de services tiers (ex : ressources de stockage / calcul dans le cloud) nécessitent la transmission de données (parfois personnelles et sensibles) vers ce service. Il en va de même pour le partage de données avec des tiers pour réalisation d’analyses externes. En plus du casse-tête habituel de la conformité, cela peut (et devrait) être une préoccupation importante pour les entreprises, car une faille de sécurité peut rendre vulnérables à la fois leurs clients et leur réputation. Dans ce cas, utiliser des données synthétiques permet de réduire les risques liés aux transferts de données (vers des tiers, des fournisseurs de cloud, des prestataires ou encore des entités hors UE pour les entreprises européennes).
Un peu d’histoire…
L’idée de mettre en place des techniques de préservation de la confidentialité des données via les données synthétiques date d’une trentaine d’années, période à laquelle le US Census Bureau (organisme de recensement américain) décida de partager plus largement les données collectées dans le cadre de son activité. A l’époque, Donald B. Rubin, professeur de statistiques à Harvard, aide le gouvernement américain à régler des problèmes tels que le sous-dénombrement, en particulier des pauvres, dans un recensement, lorsqu’il a eu une idée, décrite dans un article de 1993 .
« J’ai utilisé le terme ‘données synthétiques’ dans cet article en référence à plusieurs ensembles de données simulées. Chacun semble avoir pu être créé par le même processus qui a créé l’ensemble de données réel, mais aucun des ensembles de données ne révèle de données réelles – cela présente un énorme avantage lors de l’étude d’ensembles de données personnels et confidentiels. »
Les données synthétiques sont nées.
Par la suite, on retrouvera des données synthétiques dans le concours ImageNet de 2012 et, en 2018, elles font l’objet d’un défi d’innovation lancé par le National Institute of Standards and Technology des États-Unis sur la thématique des techniques de confidentialité. En 2019, Deloitte et l’équipe du Forum économique mondial ont publié une étude soulignant le potentiel des technologies améliorant la confidentialité, y compris les données synthétiques, dans l’avenir des services financiers. Depuis, ces données artificielles ont infiltré le monde professionnel et servent aujourd’hui des usages analytiques multiples.
Méthodologies de génération de données synthétiques
Pour un dataset réel donné, on peut distinguer 3 types d’approche quant à la génération et l’utilisation de données synthétiques :
Données entièrement synthétiques – Ces données sont purement synthétiques et ne contiennent rien des données d’origine.
Données partiellement synthétiques – Ces données remplacent uniquement les valeurs de certaines caractéristiques sensibles sélectionnées par les valeurs synthétiques. Les valeurs réelles, dans ce cas, ne sont remplacées que si elles comportent un risque élevé de divulgation. Ceci est fait pour préserver la confidentialité des données nouvellement générées. Il est également possible d’utiliser des données synthétiques pour adresser les valeurs manquantes de certaines lignes pour une colonne donnée, soit par méthode déterministe (exemple : compléter un âge manquant avec la moyenne des âges du dataset) ou statistique (exemple : entraîner un modèle qui déterminerait l’âge de la personne en fonction d’autres données – niveau d’emploi, statut marital, …).
Données synthétiques hybrides – Ces données sont générées à l’aide de données réelles et synthétiques. Pour chaque enregistrement aléatoire de données réelles, un enregistrement proche dans les données synthétiques est choisi, puis les deux sont combinés pour former des données hybrides. Il est prisé pour fournir une bonne préservation de la vie privée avec une grande utilité par rapport aux deux autres, mais avec un inconvénient de plus de mémoire et de temps de traitement.
GAN ?
Certaines des solutions de génération de données synthétiques utilisent des réseaux de neurones dits « GAN » pour « Generative Adversarial Networks » (ou Réseaux Antagonistes Génératifs).
Vous connaissez le jeu du menteur ? Cette technologie combine deux joueurs, les « antagonistes » : un générateur (le menteur) et un discriminant (le « devineur »). Ils interagissent selon la dynamique suivante :
Le générateur ment : il essaie de créer une observation de dataset censée ressembler à une observation du dataset réel, qui peut être une image, du texte ou simplement des données tabulaires.
Le discriminateur – devineur essaie de distinguer l’observation générée de l’observation réelle.
Le menteur marque un point si le devineur n’est pas capable de faire la distinction entre le contenu réel et généré. Le devineur marque un point s’il détecte le mensonge.
Plus le jeu avance, plus le menteur devient performant et marquera de points. Ces « points » gagnés se retrouveront modélisés sous la forme de poids dans un réseau de neurones génératif.
L’objectif final est que le générateur soit capable de produire des données qui semblent si proches des données réelles que le discriminateur ne puisse plus éviter la tromperie.
Pour une lecture plus approfondie sur le sujet des GANs, il en existe une excellente et détaillée dans un article du blog Google Developers.
Un marché dynamique pour les solutions de génération de données synthétiques
Plusieurs approches sont aujourd’hui envisageables, selon que l’on souhaite s’équiper d’une solution dédiée ou bien prendre soi-même en charge la génération de ces jeux de données artificielles.
Parmi les solutions Open Source, on peut citer les quelques librairies Python suivantes :
Mais des éditeurs ont également mis sur le marché des solutions packagées de génération de données artificielles. Aux Etats-Unis, notamment, les éditeurs spécialisés se multiplient. Parmi eux figurent Tonic.ai, Mostly AI, Latice ou encore Gretel.ai, qui affichent de fortes croissances et qui ont toutes récemment bouclé d’importantes levées de fond
Un outil puissant, mais…
Même si l’on doit être optimiste et confiant quant à l’avenir des données synthétiques pour, entre autres, les projets de Machine Learning, il existe quelques limites, techniques ou business, à cette technologie.
De nombreux utilisateurs peuvent ne pas accepter que des données synthétiques, « artificielles », non issues du monde réel, … soient valides et permettent des applications analytiques pertinentes. Il convient alors de mener des initiatives de sensibilisation auprès des parties prenantes business afin de les rassurer sur les avantages à utiliser de telles données et d’instaurer une confiance en la pertinence de l’usage. Pour asseoir cette confiance :
Bien que de nombreux progrès soient réalisés dans ce domaine, un défi qui persiste est de garantir l’exactitude des données synthétiques. Il faut s’assurer que les propriétés statistiques des données synthétiques correspondent aux propriétés des données d’origine et mettre en place une supervision sur le long terme de ce matching. Mais ce qui fait également la complexité d’un jeu de données réelles, c’est qu’il capture les micro-spécificités et les cas hyper particuliers d’un cas d’usage donné, et ces « outliers » sont parfois autant voire plus important que les données plus traditionnelles. La génération de données synthétiques ne permettra pas d’adresser ni de générer ce genre de cas particuliers à valeur.
Également, une attention particulière est à porter sur les performances des modèles entrainés, partiellement ou complètement, avec des données synthétiques. Si un modèle performe moins bien en utilisant des données synthétiques, il convient de mettre cette sous-performance en regard du gain de confidentialité et d’arbitrer la perte de performance que l’on peut accepter. Dans le cas contraire où un modèle venait à mieux performer quand entrainé avec des données synthétiques, cela peut lever des inquiétudes quand à sa généralisation future sur des vraies données : un monitoring est donc nécessaire pour suivre les performances dans le temps et empêcher toute dérive du modèle, qu’elle soit de concept ou de données.
Aussi, si les données synthétiques permettent d’adresser des problématiques de confidentialité, elles ne protègent naturellement pas des biais présents dans les jeux de données initiaux et ils seront statistiquement répliqués si une attention n’y est pas portée. Elles sont cependant un outil puissant pour les réduire, en permettant par exemple de « peupler » d’observations synthétiques des classes sous-représentées dans un jeu de données déséquilibré. Un moteur de classification des CV des candidats développé chez Amazon est un exemple de modèle comportant un biais sexiste du fait de la sous représentativité des individus de sexe féminin dans le dataset d’apprentissage. Il aurait pu être corrigé via l’injection de données synthétiques représentant des CV féminins.
On conclura sur un triptyque synthétique imageant bien la puissance des sus-cités réseaux GAN, utilisés dans ce cas là pour générer des visages humains synthétiques, d’un réalisme frappant.
Il est à noter que c’est également cette technologie qui est à l’origine des deepfakes, vidéos mettant en scène des personnalités publiques ou politiques tenant des propos qu’ils n’ont en réalité jamais déclarés (un exemple récent est celui de Volodymyr Zelensky, président Ukrainien, victime d’un deepfake diffusé sur une chaine de télévision d’information).
A lire les projections de plusieurs cabinets de conseil et éditeurs de solution à travers le monde et à écouter les communautés de pratique les plus dynamiques, plusieurs macro-tendances émergent en Gestion de Portefeuille de projets pour 2022.
Alors que les organisations cherchent à passer de la phase de relance à celle de retour à la prospérité, les attentes s’accumulent autour des activités de gestion de portefeuille de projets. Les équipes de direction veulent davantage progresser sur leurs capacités à aligner la stratégie, à hiérarchiser les priorités, à équilibrer les scénarios de leur portefeuille de projets et à constater les effets de leur transformation sur leur business.
À mesure que les objectifs de votre entreprise changent, de nouvelles méthodes de travail et de nouvelles tendances dans le domaine de la gestion de portefeuille de transformation émergent, et vous devrez en tenir compte pour que votre organisation s’y adapte et demeure concurrentielle sur son marché.
L’important n’est pas que vous connaissiez toutes les tendances, ou que vous les appliquiez toutes en même temps. Vous devriez évaluer, en fonction des ambitions et de la maturité de votre organisation, lesquelles de ces tendances vous apporteront des effets significatifs sur votre performance quotidienne et future. Bien sûr, il est également important d’avoir des outils suffisamment souples et adaptables pour vous permettre de mettre en œuvre ces nouvelles tendances.
Que pensez-vous de ces tendances 2022 que nous avons rassemblées pour vous ?
La gouvernance des portefeuilles de projets doit être pragmatique
La réduction constante de l’horizon de la vision stratégique induit des changements de logique et de rythme pour la gouvernance des portefeuilles de projets.
Le resserrement des budgets en 2022 voit émerger plus encore qu’avant le besoin de vendre des idées d’affaire pour convaincre d’accorder des financements d’investissement. L’alignement du portefeuille sur les objectifs stratégiques est le défi majeur des entreprises d’aujourd’hui. Un portefeuille qui, par conséquent, doit être axé sur la livraison continue de valeur, à la fois pour l’organisation et pour ses clients et utilisateurs. Cette gestion des investissements défendue appelle à une attitude beaucoup plus entrepreneuriale. Elle est plus exigeante en données fiables de la part de ses commanditaires pour discuter avec les décideurs sur la valeur des projets et l’affectation des capacités de l’organisation. L’établissement des priorités pour obtenir des résultats optimaux requiert une attention plus forte à l’énoncé des bénéfices et menaces à court et à long terme, ainsi qu’un dispositif de surveillance continue à mettre en place avec le développement de la gestion de la réalisation des bénéfices.
Dans le contexte actuel, la logique de planifier les coûts, les ressources ou les budgets un an à l’avance ne convient plus. L’ère Digitale et surtout la pandémie de COVID-19 a entraîné une réduction constante des cycles de vie des projets, produits et services. Les entreprises se doivent de réagir de manière agile aux tendances changeantes de leurs utilisateurs et de leurs clients. Pour ne pas perdre en compétitivité sur leurs marchés, les entreprises sont dès maintenant obligées de revoir leurs objectifs stratégiques dans des cycles de plus en plus courts. Elles sont également contraintes d’ajuster en conséquence les aspects clés de la planification stratégique du portefeuille, tels que l’affectation et la gestion des ressources, les coûts et la priorisation des produits livrables.
Cette logique adaptative appliquée aux portefeuilles des transformations nécessite déjà des révisions tous les trois à six mois qui vont devenir de plus en plus impactantes. Cela signifiera aussi, prendre le temps de renoncer à un certain contrôle et de fournir un moyen de livraison qui sera simple, pragmatique, qui pourra être fait de loin et selon un processus que tout le monde comprendra.
L’organisation devient hybride dans toutes ses dimensions
L’installation dans la durée du contexte actuel impose d’appliquer le meilleur des modèles de travail et des méthodes de gestion des projets connues.
La pandémie de COVID-19 a bouleversé durablement le paysage professionnel et apporté aussi de nouveaux défis dans la gestion et l’exécution du portefeuille de l’organisation. De nouveaux canaux de communication, de nouvelles pratiques de travail collaboratives et de nouveaux rapports à l’information avec toutes les parties prenantes, remplacent les repères et références antérieures.
Avec l’introduction du télétravail, la réunion en face à face n’est plus le canal dominant. Il existe maintenant, de nombreux outils en ligne que vous utilisez au quotidien pour communiquer avec les responsables de domaines, les chefs de projets, les membres du comité exécutif, les responsables de produits, Scrum Masters, etc. Si tous ont pu remplacer temporairement toutes les rencontres en physique, ils prennent progressivement une place intermédiaire avec les rencontres dites hybrides (présentiel et distanciel), maintenant que le télétravail est durablement pratiqué. Avec l’émergence d’un si grand nombre d’outils de collaboration, le plus grand défi lié au travail hybride souvent cité, porte sur l’établissement des relations. Dans ce mouvement pendulaire, certains intervenants ne sont pas suffisamment informés de l’avancement de certaines initiatives du portefeuille. La diminution des échanges informels ne permettant plus la communication implicite. L’adaptation à ces nouvelles exigences relationnelles se confronte à la façon dont nous adaptons cette culture, cet esprit d’équipe et cette collaboration lorsque les équipes sont fondamentalement dispersées.
De plus en plus d’entreprises comprennent que leur compétitivité sur les marchés dépend de leur capacité à s’adapter à l’environnement en constante évolution dans lequel nous vivons. Et cela signifie adopter des modèles qui prennent le meilleur des approches de gestion plus traditionnelles et des nouvelles comme l’Agilité à l’échelle. Alors que les approches traditionnelles mettent l’accent sur la réalisation de projets, de plus en plus d’organisations vont adopter des modèles de prestation plus axés sur les produits afin d’améliorer l’agilité et de mettre l’accent sur la valeur. L’avenir du travail sera hybride selon trois dimensions : géographique, collaborative et méthodologique.
En conséquence directe, il y aura un nombre grandissant de changements pour permettre aux initiatives clés de se dérouler simultanément et d’en substituer certaines par d’autres, car les sponsors feront plus fréquemment les arbitrages itératifs nécessaires de priorisation. Face à ce phénomène, le PMO devra progressivement faire preuve de maturité en matière de sens des affaires et de gestion des parties prenantes pour apporter des données et des capacités de gestion des transformations sous-jacentes essentielles à cette évolution.
Le PMO acteur du développement des talents
Le PMO est en passe de devenir un acteur du recrutement des talents projets et un animateur essentiel de la gestion en mode hybride des transformations.
Le rôle du PMO commence à devenir crucial pour attirer et retenir les meilleurs talents. 2022 verra une discussion beaucoup plus réfléchie et ciblée dans l’exploration de ce dont les collaborateurs ont besoin pour bien performer et de ce qu’ils doivent avoir à disposition pour vouloir rester. Le mandat du PMO se trouve maintenant élargi dans ce domaine. Il existe déjà des équipes dans lesquelles le PMO d’un portefeuille, est invité à participer à des entretiens de recrutement pour aider à l’évaluation de l’adéquation culturelle de futurs arrivants et voir même pour gérer de façon centralisée le recrutement des chefs de projets. Cela découle de la reconnaissance de la place idéale qu’occupent les PMO dans la structure organisationnelle. C’est ainsi qu’ils sont de plus en plus associés au recrutement et mis en capacité de faire une différence dans ce domaine.
Un autre thème que l’on s’attend également à voir gagner du terrain en 2022 concerne le développement personnel du PMO. Ils y seront encouragés au sein de communautés de PMO qui leur assurent d’identifier et d’acquérir les comportements nécessaires à l’exercice de leur rôle. Ils sont nombreux dans ces collectifs à chercher des façons de se renouveler et de perfectionner leurs compétences dans des domaines comme la création d’équipes très performantes, la résolution de conflits, le renforcement de la confiance, la motivation, la productivité et la stratégie de communication. Les PMO ont de plus en plus l’occasion d’activer un ensemble de « softskills » au sein des équipes et de proposer du coaching et des conseils.
Enfin, sous sa forme traditionnelle, l’activité de formation est au cœur de l’industrie de la gestion de projet. Cependant, depuis le début de la pandémie, c’est la formation virtuelle qui prend l’ascendant. Cette forme d’apprentissage numérique ne disparaîtra pas de sitôt et il faut donc s’y adapter. Du point de vue de l’organisation et de l’équipe, cette approche comporte plusieurs défis qui doivent être pris en compte, comme (et surtout) la qualité du contenu et du format interactif des cours en ligne. La formation en ligne implique des compromis comme l’aspect réseautage et l’interactivité. Mais elle s’accompagne aussi d’avantages inattendus tels que la capacité à rassembler les équipes mondiales et la réduction de l’empreinte carbone.
Valoriser les données de gouvernance en progressant vers l’AI
La progression technologique des outils de gestion de portefeuille de transformations dessine une suite d’étapes vers une capacité de gouvernance dynamique.
Les progrès technologiques au cours des prochaines années, appliqués aux outils de gestion de portefeuille de projets, ouvrent déjà des perspectives de services avec une incidence qui sera significative sur le contenu et la charge de travail des acteurs de la gestion de projets. Il est évident que les PMO vont participer à chacune des étapes de remise en question des façons actuelles de travailler. La première étape pour de nombreuses organisations, relève de l’intégration des divers outils utilisés pour consigner et gérer différents aspects de leur portefeuille de projets (Tableaux Kanban, feuilles de temps, graphiques de Gantt, Microsoft Excel, courriel, Jira…). Avec une solution logicielle PPM facile à mettre en œuvre reprenant toutes les fonctionnalités nécessaires dans une seule interface, vous serez en mesure de gérer la planification et l’exécution de la stratégie. Cela avec une flexibilité qui s’adapte aux différents besoins, méthodologies et systèmes de gouvernance qui peuvent coexister dans votre organisation. Aux avantages de cette intégration, s’ajoutent la standardisation des processus, l’automatisation de tâches et la création automatique de rapports.
L’étape suivante après la maîtrise des considérations techniques, financières et d’évolutivité des logiciels PPM, concerne l’intégration avec le SI financier avant celui des développements. Grâce à la montée en puissance du Strategic Execution Management, vous pourrez bientôt faire le lien entre la gouvernance du plan stratégique et le pilotage des portefeuilles et projets au cœur de la chaîne de valeur. On l’a vu plus haut, il n’est pas question d’utiliser l’automatisation pour prédire ce qui s’en vient. Les organisations qui peuvent prévoir et diagnostiquer ces changements à l’avance et préparer d’autres feuilles de route, auront un avantage concurrentiel incontestable par rapport à leurs concurrents.
La dernière étape répond à la pression de satisfaire au besoin de la direction en matière de données de gouvernance en temps réel. Cela afin de permettre une surveillance continue et d’aider à planifier de nombreux points de décision de lancement et d’arbitrage pour offrir le maximum de souplesse en matière de livraisons axées sur la valeur. Il est prévisible que le volume des données générées par le portefeuille de projets pourra devenir encore plus une activité fastidieuse et insoluble. Se tourner vers une application du marché d’analyse intelligente des données vous permettra d’intégrer et d’automatiser, à la fois la collecte et la synchronisation de ces données dans des tableaux de bord, et aussi des rapports contenant les informations pertinentes de votre portefeuille.
La maturité du processus de gestion des risques
Développer l’attitude et les moyens d’analyse des données de contexte pour se prémunir des risques et se préparer aux opportunités.
Si très peu d’organisations avaient la COVID-19 dans leur registre des risques stratégiques ou liés aux projets, c’est que la plupart des organisations ne considéraient pas que son impact ou sa probabilité était suffisamment élevé pour être sérieux. Et puis, du jour au lendemain, tout le monde a été touché. Ce biais collectif du comportement face aux risques est représentatif de la maturité du processus de gestion des risques à tous les niveaux des organisations de toutes formes, tailles et industries. Après 2 ans de crise en « Stop & Go », les organisations les plus éprouvées sont montées en puissance en développant la formation et le processus de gestion des risques pour s’assurer que leurs équipes sont prêtes pour une autre calamité.
Pour les PMO et acteurs du pilotage des projets et produits, le développement de la culture du risque dans la prise de décision est à associer au développement de son attitude entrepreneuriale. Si l’application des principes agiles facilite l’adaptation de l’organisation face à l’incertitude, la gestion des risques interroge et prépare celle-ci aux possibles à court et moyen termes et constitue ainsi un levier d’action sur ses contraintes. Au lieu de planifier (à n’importe quel niveau), puis de faire de la gestion des risques, il faut retourner la logique et permettre à la gestion des risques d’éclairer votre planification. Si cela avait été considéré comme tel avant la Covid-19, la transition pour les organisations et les employés aurait pu être moins douloureuse et onéreuse.
L’autre aspect de la gestion des risques en émergence pour le PMO, repose sur l’analyse intelligente des données internesde pilotage avec celles des contingences externes. Lorsqu’il en aura les moyens, il reviendra à lui d’en exploiter les résultats pour atténuer l’impact ou la probabilité qu’un risque se matérialise et impacte les objectifs portés par son portefeuille de projets/ produits.
De plus en plus les Responsables de la gestion de portefeuille de projets œuvrent à maximiser la « Valeur » des projets inscrits dans leur portefeuille. Ils disposent depuis la montée en force de l’agilité à l’échelle, de plusieurs techniques issues des approches Lean et Agile. Dans ce nouvel épisode, il s’agit d’associer certaines de ces modalités aux différents facteurs de la gestion des transformations à même de faciliter la création de valeur des projets à mener.
Précédemment nous avons parcouru les différentes acceptions attachées à la notion de « Valeur » rencontrées dans l’entreprise. Puis nous avons tenté de reconnaître les dimensions de la « création de valeur » considérées en gestion des transformations que les professionnels des projets ont à charge de maximiser. Cette fois, continuons l’exercice de clarification en nous intéressant aux leviers de la valeur à la main des PMOs en charge de portefeuille de projets.
En préambule, il est bon de rappeler les domaines de la sphère d’influence du PMO quel que soit son niveau d’intervention dans l’organisation :
L’alignement stratégique des projets : « FAIRE LES BONS PROJETS »
Assurer l’intégration des projets au portefeuille avec la stratégie, mais aussi avec son exécution ;
L’aide à la sélection des projets, sur la base de critères métiers à documenter ;
L’aide à l’équilibrage des contraintes et ressources et à l’ordonnancement des projets.
La maximisation des résultats des projets : « BIEN FAIRE LES PROJETS »
Assurer la réussite des projets en veillant à la circulation des données d’avancement, de risques, d’adhérences à même de la compromettre ;
La comptabilisation des bénéfices issues des résultats des projets, qui se mesurent périodiquement par des indicateurs implantés dans les services utilisateurs ;
L’assistance à la réduction des risques et aux dépendances entre les projets au portefeuille.
L’optimisation de l’usage des ressources engagées : « LES BONS MOYENS POUR FAIRE LES PROJETS »
La définition et animation du cadre intégré de gestion du portefeuille au service de ses parties prenantes ;
L’amélioration de la gestion de projet, qui doit englober les aspects métiers et informatiques ;
L’implantation de comités permettant aux Directions métiers de décider conjointement avec la DSI, de l’avenir des activités tout en respectant le cadre régalien du SI.
Pour ce faire, les PMOs peuvent puiser dans différentes approches, démarches et référentiels de pratiques qui permettent d’impacter les organisations autant sur la valeur qu’elles apportent à leurs clients que sur les moyens par lesquels elles fournissent cette valeur. Parmi elles, l’agilité connue pour apporter aux organisations des capacités à générer plus de valeur en plaçant la satisfaction du client au centre des préoccupations, tout en faisant en sorte de s’adapter aux changements de son environnement. Nous allons voir comment cette approche est en mesure de faciliter l’action des PMOs.
A l’international plus qu’en France, il est reconnu que le PMO n’est pas qu’un comptable de la valeur qui résulte des portefeuilles de projets mais celui attendu pour impacter positivement l’organisation dans la création de valeur issue des transformations sous sa responsabilité. Il dispose pour cela, de plusieurs leviers pour y parvenir qu’il met en œuvre au travers de son dispositif de gouvernance et de pilotage des transformations de l’entreprise. Dans ce domaine de gestion, la confusion actuelle provient de la multitude d’actions possibles face aux différents leviers de la valeur des transformations sur lesquelles agir.
La valeur des transformations par la gestion des flux de valeur pour un meilleur alignement stratégique du portefeuille
La performance ne peut se réduire au seul plan économique. Elle se définit comme la mise en perspective de la valeur produite par rapport à toutes les ressources consommées, y compris celle du temps. Aussi la valeur qui en est déduite, n’est pas l’ultime indicateur de la réussite d’un projet. Car même si son potentiel est créé tout au long du projet, c’est plus souvent bien après l’achèvement du projet qu’elle est constatée. En conséquence, l’essentiel de la valeur des projets provient de leur bon alignement stratégique, comme levier d’impacts sur les nouvelles capacités organisationnelles à mettre en place pour accroître la valeur commerciale ou opérationnelle de l’entreprise. On entend fréquemment que l’alignement stratégique recouvre plusieurs dimensions de mise en cohérence regroupées selon deux axes.
Les dimensions de la mise en cohérence verticale couvrent la déclinaison de la stratégie dans l’entreprise :
La stratégie de l’entreprise ;
La conception de l’organisation ;
La stratégie de développement technologique ;
L’infrastructure et le processus des systèmes d’information.
Les dimensions de la mise en cohérence horizontale traitent son intégration à la fois stratégique et fonctionnelle entre les domaines internes, à chaque niveau de la déclinaison de la stratégie et leurs adhérences externes :
L’intégration stratégique qui correspond à l’alignement entre les domaines externes et les domaines internes ;
L’intégration fonctionnellequi correspond à l’impératif d’intégrer le domaine de l’entreprise et le domaine des technologies de l’information à deux niveaux.
La mise en place de la cohérence entre la stratégie générale et la stratégie de développement technologique se pose aussi de façon dynamique. Il est maintenant fréquent que la stratégie d’une organisation change et que le système d’information et son portefeuille de projets ne se retrouvent plus alignés. C’est pour cette raison qu’un modèle d’alignement stratégique dynamique est devenu nécessaire. L’approche agile appliquée à la gestion de portefeuille de projets y apporte plusieurs éléments de réponse.
Tout d’abord, elle détermine l’alignement stratégique à travers la gestion des flux de valeur. Chacun correspondant généralement à une ligne métier, et tend à répondre à cet impératif de livraison de la valeur client.
Elle permet de cadencer les mises en cohérence avec l’utilisation des « Objective Key Results – OKR ». A chaque niveau de déclinaison de la stratégie, pour chacun des flux de valeur, des Objectifs sont déterminés selon une périodicité propre au niveau et des Résultats Clés à atteindre sont convenus. Ces OKRs sont alors partagés pour s’assurer de la transparence des priorités du travail approuvé et de l’engagement des ressources associées pour la période.
Enfin, la gestion des flux de valeur participe à la cohérence stratégique et fonctionnelle par le pilotage de la capacité de travail utile aux chaînes de valeur.
L’articulation entre la stratégie et l’exécution des travaux ainsi obtenue, permet de livrer le meilleur compromis de résultats attendus pour la période, dans la limite des moyens accordés aux flux de valeur. L’un des effets connexes du traitement systémique de la valeur est de rompre les silos organisationnels en résolvant des frictions entre équipes et des gâchis de ressources mal affectées.
La valeur des transformations par le pilotage des indicateurs pour une visibilité accrue sur les impacts des transformations
Dans le contexte du modèle de gestion traditionnelle de portefeuille de projets, la valeur est évaluée à l’achèvement des projets à travers le respect des engagements pris. Elle est déterminée selon des pratiques de calculs centrées sur le Triangle d’or de la gestion de projets (Coût, Qualité, Délais). Ici, la Valeur tend à provenir de la conformité de la progression du projet vis-à-vis de sa planification. La raison en est que l’accord de financement du projet présuppose l’acquisition de sa valeur. C’est ce postulat qui focalise tous les acteurs des projets à vouloir rester en conformité avec les engagements pris et ses livrables. Cette conception de mesure de la valeur des projets est en fin de compte un trompe l’œil, puisqu’elle s’appuie sur des mesures à postériori qui ne sont pas comparées aux résultats effectivement délivrés aux clients et usagers. Qui d’entre vous n’a pas été témoin d’une célébration de fin de projet dont les fonctionnalités n’ont pas été ou que partiellement utilisées sans satisfaire ses utilisateurs ?
Il est nécessaire de revisiter les mesures et la responsabilisation des contributeurs impliqués dans la création de valeur des projets d’un portefeuille. La progression de la réalisation des bénéfices effectivement obtenus par l’entreprise dépend d’un changement de référentiel d’observation et des métriques utilisées qui passent par :
L’extension de la période de constat de réalisation des bénéfices et de ses effets connexes ;
L’orientation plus prédictive des métriques de la création de valeur dans ses différentes dimensions ;
L’évolution des indicateurs financiers (Croissance des revenus, Revenus par client, Marge bénéficiaire, Taux de rétention des clients, Satisfaction de la clientèle) qui ne conviennent plus. Ils sont à compléter par plusieurs autres plus ouverts à la satisfaction voir à l’expérience client au travers de feedbacks (ex. : Délais de mise sur le marché, …).
Pour y parvenir, la pensée Lean propose plutôt de se focaliser sur la progression du travail en référence à la Théorie des Contraintes. Pour les PMOs cela signifie d’observer la fluidité des travaux pour s’assurer du flux continue des livraisons, apportant ainsi une contribution plus soutenue de valeur pour les métiers, les équipes projets et l’organisation dans son ensemble. L’analyse de ces flux permet aux équipes de comprendre leurs limites de capacité, faciliter l’identification des problèmes, et aider à se focaliser sur la remise à flot du travail. Pour ce faire, une économie autour des résultats métiers apportés par les projets doit être interrogée :
Les délais et temps de cycles pour comprendre le temps nécessaire à la traversée du système de réalisation des projets jusqu’à la création de revenu. Les variations de leur mesure dans le temps informent sur l’influence des changements sur les prévisions des travaux futurs.
Le suivi de leurs délais de développement mais aussi des charges liées aux reprises de travaux et d’amélioration de la qualité.
La quantité des travaux engagés en cours à confronter aux capacités à les délivrer (notion de Work In Progress – WIP).
La file d’attente au sein des travaux en cours à rapprocher du WIP pour révéler les blocages et rechercher les solutions pour rétablir le flux.
Les gâchis de ressources pour alimenter les travaux d’amélioration continue et valoriser les gains apportés par ces travaux annexes.
Tous ces éléments associés à la notion de flux de valeur aident les PMOs à engager les actions propres à stabiliser, accroître, accélérer le flux des travaux. Ils touchent à la fois à des aspects opérationnels, processus et performances. Ils servent aussi de support d’évaluation de leur impact selon trois perspectives.
Quelle valeur a été générée sur la période en comparaison de la précédente ?
Quelle quantité par nature de ressource a été consommée pour générer cette valeur en comparaison à la précédente période ?
Quelle sont les opportunités d’amélioration des personnes, processus et système pour améliorer la valeur délivrée aux clients au regard des ressources consommées ?
La valeur des transformations par la qualité des livrables et la maximisation de la valeur d’usage dans la conception des produits et services
Par construction, la gestion du portefeuille nécessite l’approbation de l’engagement des travaux par les principales parties prenantes de l’organisation. La demande de travail proposée est ainsi ouverte à un examen minutieux des résultats annoncés, car les chefs de projet savent que tout travail approuvé dans un domaine, supprime le financement d’un travail potentiel dans un autre domaine. La Direction, en tant que responsable de l’équilibre des contraintes (budget, calendrier, ressources, risques) au sein de son Domaine, a la responsabilité d’approuver et de faire exécuter le travail ayant le compromis Priorité (Time to Market – Valeur – Risque) le plus favorable. Le PMO est là pour l’assister dans la préparation de ces décisions. Il agit à la fois en facilitant l’obtention des résultats attachés aux engagements pris par les tandems sponsor – chef de projets et en étant vigilant sur les dispositions nécessaires à la réalisation des bénéfices qui en découlent.
L’approche agile propose parmi ces apports, deux concepts d’incrémentation des livraisons aux métiers, qui constituent un facteur essentiel à la réduction du risque d’échec des projets au sens de la création de la valeur métiers.
Si Frank Robinson a introduit en 2001 le concept du MVP (Minimum Viable Product) considéré comme le résultat du processus du développement en parallèle du produit et des clients. Il reste réservé à la création de produits et de services. Il assure que 20% des fonctionnalités permettent d’atteindre 80% de la satisfaction des clients comme une adaptation du principe de Pareto qui se base sur la loi suivante : 80 % des effets sont le produit de 20 % des causes.
Al Shalloway pour sa part, a introduit presque dans le même temps, le concept du MBI (Minimum Business Increment). L’incrément de valeur commerciale minimal est utilisé dans le cas où les clients ou le produit existent déjà et que l’on souhaite améliorer l’offre existante. Le MBI définit ainsi, une ligne directrice et une orientation commune au sein de toutes les équipes de l’entreprise. Les travaux de définition, d’implémentation et de mise en service sont concentrés sur la livraison d’un incrément à forte valeur ajoutée, dans un temps donné. Il permet ainsi de séquencer la liste des travaux en se basant sur la réalisation de valeur comme critère de base. Il n’est plus question de priorisation des besoins selon l’importance aux yeux du client final, mais de la priorisation des projets dans le « pipe » selon leur valeur. A l’instar d’un besoin, un projet peut être accéléré, mis à l’écart, voire même abandonné. Ceci n’est pas obligatoirement un signe d’échec, et permet au contraire d’éviter le gaspillage des ressources ou certains projets déficitaires/en retards.
En surveillant la cohérence des MVP et MBI, le PMO participe à l’augmentation de la valeur des résultats délivrés par les projets et produits au portefeuille. Il peut être celui qui introduit la mise en œuvre de ces pratiques de sélection des travaux, celui qui sécurise la réalisation des bénéfices attendus des métiers et en communique les éléments aux acteurs concernés. La double temporalité des processus de planification et de livraison du portefeuille lui fournit des critères suffisants d’une évaluation cohérente de la valeur des travaux. Ceci simplifie la comparaison du travail sur une base plus juste et permet aussi de s’assurer que le travail autorisé est valorisé, aligné et équilibré au sein du portefeuille des projets.
La valeur des transformations par l’adéquation entre les besoins en compétences et le développement des collaborateurs
Les compétences mobilisées sur les projets ont toujours été tirées par une recherche d’adéquation des effectifs d’après leur disponibilité et profil plus que par leur implication. Au fil du temps les notions d’engagement, de responsabilité, de performance collective et de leadership sont devenues des facteurs parmi les plus importants dans la réussite des projets. Les directions ont encore pour habitude de perpétuer à leur façon, culture et éthique héritées des spécificités de leurs activités et de leur histoire, sans identifier si elles reposent sur des « softskills » qu’ils leur faut faire évoluer. L’un des effets de ce manque de considération, s’observe chez les collaborateurs en perte de sens individuelle qui résulte à la fois d’un ressenti de manque de visibilité sur la finalité des travaux, d’autonomie dans l’organisation du travail (répartition, planification), d’expériences mobilisées et de perspectives d’évolution dans ses métiers.
Sans être en responsabilité envers les parties prenantes du portefeuille, Les PMOs d’une direction ou d’un domaine occupent un rôle central de facilitateur et de mise en relation des personnes. Avec ce positionnement, ils sont devenus les mieux placés pour développer l’état d’esprit (mindset) et les comportements propices à l’engagement nécessaire au sein de leur organisation. Ils peuvent y contribuer en libérant les freins aux actions transversales, en réduisant les obstacles par la promotion de la transparence et le partage des retours d’expérience utiles. Pour les y aider, les principes du management 3.0 définis par Jurgen Appelo dans son livre Management for Happiness, apportent des outils propres à maintenir les collaborateurs créatifs et motivés. Parmi les effets reconnus on trouve :
Dynamiser les personnes ;
Responsabiliser les équipes ;
Aligner les contraintes ;
Développer les compétences ;
Développer les structures ;
Améliorer le tout. (ou comment articuler changements et amélioration continue)
Les PM Officers agissent directement sur le modèle Matriciel pour en faire une organisation plus organique, vecteur d’autonomie dans le choix des compétences nécessaires au développement des profils. En intervenant transversalement par un ensemble de pratiques et leur cohérence, ils développent l’unité, la complémentarité pour fluidifier les échanges et les prises de décisions éclairées (risques à réduire, adhérences entre projets, maturité de l’organisation des équipes, gestion du temps). Le décloisonnement des équipes au sein de leur direction et de l’entreprise a pour effet de diminuer les coûts systémiques qui relèvent de la coordination. Les équipes bénéficient d’une dynamique de responsabilisation. Laquelle apporte aux projets la mobilisation des ressources individuelles les plus adéquates (cognitives, comportementales, managériales) dans un collectif focalisé sur les résultats visés par les projets.
La valeur des transformations par les capacités organisationnelles propre à faciliter l’adaptation de l’organisation et des projets
Les pratiques de gestion prédictive auxquelles nous sommes habitués sont devenues impuissantes devant l’amplification de l’incertitude sur la planification des projets qui augmente toujours plus le risque agrégé des portefeuilles. Les dispositifs et pratiques de gouvernance, de travail et des technologies à disposition sont pour cela caractéristiques du modèle d’organisation hiérarchique, fonctionnel et prédictif qui prédomine. Ce modèle n’est plus en mesure de faire progresser la maturité de l’entreprise face aux nouveaux déterminants de sa création de valeur. Ceux dont nous sommes les plus familiers touchent aux Conditions du marché, au Cadre réglementaire, aux Avancés de la recherche académique et aux standards industriels. Tandis que ceux propres à l’organisation relèvent des considérations financières, sociales et culturelles, de l’environnement physique de travail et du maintien des capacités opérationnelles.
Parmi les acteurs des directions intermédiaires en charge de faire face à ces déterminants internes, il revient au PMO à travers les projets au portefeuille de favoriser la création de la bonne valeur, au bon moment, pour le bon public. A lui d’agir sur les facteurs organisationnels à même de faciliter les flux de valeur issus de ses activités, touchant à la sélection des travaux à mener, à l’engagement des ressources au sens large et à fédérer les équipes autour d’objectifs communs.
Pour arriver à progresser de nouveau, les approches agiles et leurs dérivés apportent beaucoup d’éléments prompts à faciliter la création de valeur organisationnelle en question. Cependant, celles-ci exigent d’appréhender tout ou partie d’un nouveau système de gestion qui se traduit entre autres par des changements vers un environnement plus transparent (nous l’avons évoqué précédemment), et la mentalité du « tester, apprendre et s’adapter ». Que l’on évolue vers une approche hybride comme le promeut le modèle Discipline Agile de Scott W Ambler, ou une autre d’Agilité à l’échelle inspirée du modèle SAFe de Dean Leffingwell, ils comportent tous un ensemble d’exigences applicables à la gestion de portefeuille Agile dont certaines ont déjà été abordées :
Adopter une gouvernance agile pour comprendre et se concentrer sur les attentes des clients et s’adapter au changement de leurs besoins ;
Apprendre continuellement de ses expériences pour établir un cycle d’apprentissage et former les parties prenantes aux nouvelles activités et outils d’aide mis à disposition ;
Assurer une transparence via une communication ajustée des projets et de la gouvernance pour nourrir un écosystème de services interdépendants et d’équipes autonomes ;
Proposer des solutions incrémentales pour prendre des décisions rapides et régulières ;
Réduire le cycle de « Feedback » pour créer un flux d’information ;
Animer la synchronisation et développer la flexibilité des équipes œuvrant sur des produits et ou des projets pour cadencer des travaux du portefeuille ;
Rationaliser les efforts de création et de transition pour répondre aux besoins particuliers d’un projet donné ;
Améliorer en continu les données pour rendre prévisible l’équilibre entre demandes et capacités ;
Synchroniser les fonctions support traditionnelles en interface avec les processus dynamiques du portefeuille des transformations pour résoudre les obstacles aux flux de valeur des transformations, type goulet d’étranglement ;
Et plus récemment conjuguer les modalités de travail à distance et en face à face.
Les PMOs ont pour terrain de jeu celui de la conduite des transformations. Si cet espace est à la mesure des impacts qu’ils peuvent y faire ; c’est le résultat de leurs actions de gestion qui permet d’aboutir au constat que le portefeuille des projets crée plus de valeur que la somme de ses éléments. Leur travail sur les facteurs de valeur organisationnels contribue à faciliter l’adaptabilité, la flexibilité, l’intégration, la communication, et le traitement des données des projets. Ils participent au développement de nouvelles capacités organisationnelles qui résultent d’une rigueur dans l’amélioration continue des pratiques. C‘est ainsi que le PMI (Project Management Institute) reconnais plusieurs de ces apports :
Le système de management focalisé sur les besoins métiers et l’optimisation des moyens ;
Les processus en renouvelant les activités, les rôles, les pratiques et outils pour atteindre les objectifs globaux ;
La structure organisationnelle décloisonnée des équipes pour des prises de décision adaptées ;
La culture et les comportements incarnés à tous les niveaux de l’organisation ;
L’information appropriée au contexte, au bon moment, dans les bonnes mains pour prendre les bonnes décisions ;
Les services et infrastructures à disposition des parties prenantes des transformations en support aux travaux de gestion à mener ;
Les personnels et compétences à mettre en œuvre sur les travaux de transformation.
Pour résumer ce long propos, nous savons maintenant comment un PMO devient progressivement l’acteur des organisations, apte à accroître la valeur des transformations. Il peut s’appuyer sur les approches Lean-Agile et ce à plus d’un titre :
Pour assurer la cohérence du portefeuille avec la stratégie, il est en relation avec des interlocuteurs dans toute l’organisation, qu’il focalise sur les travaux à forte valeur avec la mise en œuvre d’OKR.
Pour aider aux prises de décision, il a accès à toutes les données et informations de gouvernance et de pilotage des projets, qu’il valorise en s’appuyant sur les indicateurs d’inspiration Lean, propres à fluidifier les travaux inscrits au portefeuille.
Pour maximiser la réalisation des bénéfices, il challenge la satisfaction des besoins métiers avant d’engager des ressources et participe au cadencement des incréments de valeur.
Pour renouveler la culture et développer le mindset propre à l’engagement des équipes, il contribue à la diffusion des principes du management 3.0, auprès des managers et équipiers.
Pour faciliter l’adaptation des capacités organisationnelles de transformation, il se réfère à un modèle d’hybridation du travail et des rôles dans l’organisation en tant que vecteur d’adoption des valeurs et principes agiles, avant même les pratiques applicables à la gestion de portefeuille.
Les Leviers de création de valeur de la gestion des transformations
Le thème du prochain et dernier épisode de cette série sur la valeur des transformations, sera l’opportunité de comprendre : comment se définit la valeur d’un portefeuille au regard des enjeux de la société au sens large ? Comment s’articulent les priorités des transformations au travers des flux de ressources étendus aux champs écologique et social ? Et enfin, comment envisager de piloter la valeur des transformations au travers du prisme de la performance globale ?
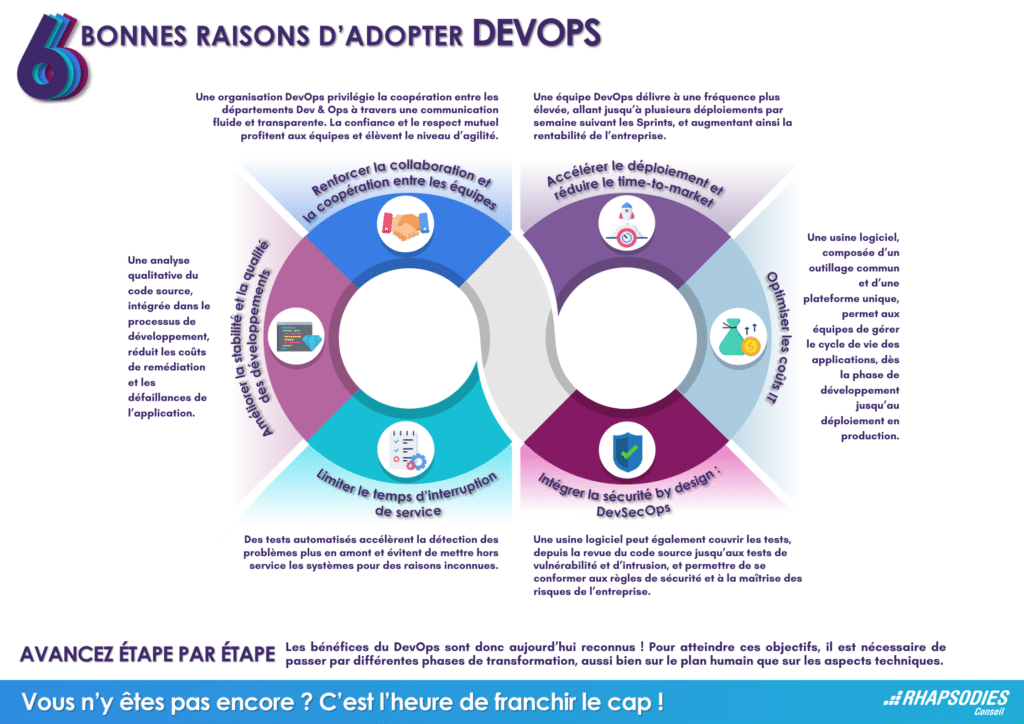
1. Renforcer la collaboration et la coopération entre les départements Dev & Ops
Une organisation DevOps amène les équipes en place à adopter des changements positifs et à partager un objectif commun, à travers une communication fluide et transparente. La coopération, la confiance et le respect mutuel profitent aux équipes et permettent d’atteindre le niveau d’agilité exigé.
2. Améliorer la qualité des développements applicatifs et la stabilité de l’application
L’analyse qualitative du code source intégrée dans le processus de développement, voire implémentée dans la phase d’intégration continue, permet de réduire les coûts de remédiation et de prévenir les défaillances de l’application.
3. Accélérer le déploiement, réduire les risques opérationnels et renforcer le time to market
Un management agile reposant sur le DevOps permet de délivrer à une fréquence plus importante, pouvant aller à plusieurs déploiements chaque semaine suivant les Sprints, et réduisant ainsi le time to market.
4. Diminuer les coûts IT
Les équipes Devs et Ops adoptent un outillage commun et une plateforme unique: l’Usine Logiciel, pour gérer le cycle de vie des applications, dès la phase de développement jusqu’au déploiement en Production.
5. Limiter le temps d’interruption de service
L’ensemble des tests automatisés permettent à l’entreprise de détecter en amont et plus rapidement les problèmes, évitant ainsi de mettre hors service leurs systèmes pour des raisons inconnues.
6. Intégrer la sécurité by design : DevSecOps
Intégrés à l’usine logicielle, les outils dédiés à cet usage permettent de se conformer aux règles de sécurité de l’entreprise et de maîtriser les risques. L’analyse se fait de bout en bout et couvre tous les aspects de sécurité, depuis la revue du code source jusqu’aux tests de vulnérabilité et d’intrusion.
Pour conclure : avancer étape par étape
Les bénéfices du DevOps sont donc aujourd’hui reconnus ! Pour atteindre ces objectifs, il est nécessaire de passer par différentes phases de transformation, aussi bien sur le plan humain que sur les aspects techniques.
Etes-vous prêts à franchir le cap et passer au DevOps ?