Disposer d’une bonne connaissance client est la pierre angulaire d’une expérience client réussie. Il s’agit du premier facteur clé de succès de l’omnicanalitéque nous avions évoqué dans un précédent article.
L’omnicanalité place le client et ses points de contacts au centre de la stratégie d’expérience client. C’est à partir de la connaissance du client que se définit l’ambition de marque d’une entreprise orientée client. Les points de contact offerts sont alors conçus pour répondre à cette promesse de marque. L’orientation produit n’est aujourd’hui plus d’actualité ; l’orientation client remet le client au centre des premières préoccupations de l’entreprise. En outre, l’orientation client suppose naturellement de bien connaître son client.
Nous comprenons ainsi l’enjeu de disposer d’une connaissance client pertinente et complète.
Mais que signifie bien connaître son client ? Comment se construit cette connaissance client ?
La connaissance client est un vaste domaine que nous vous proposons d’explorer dans cet article.
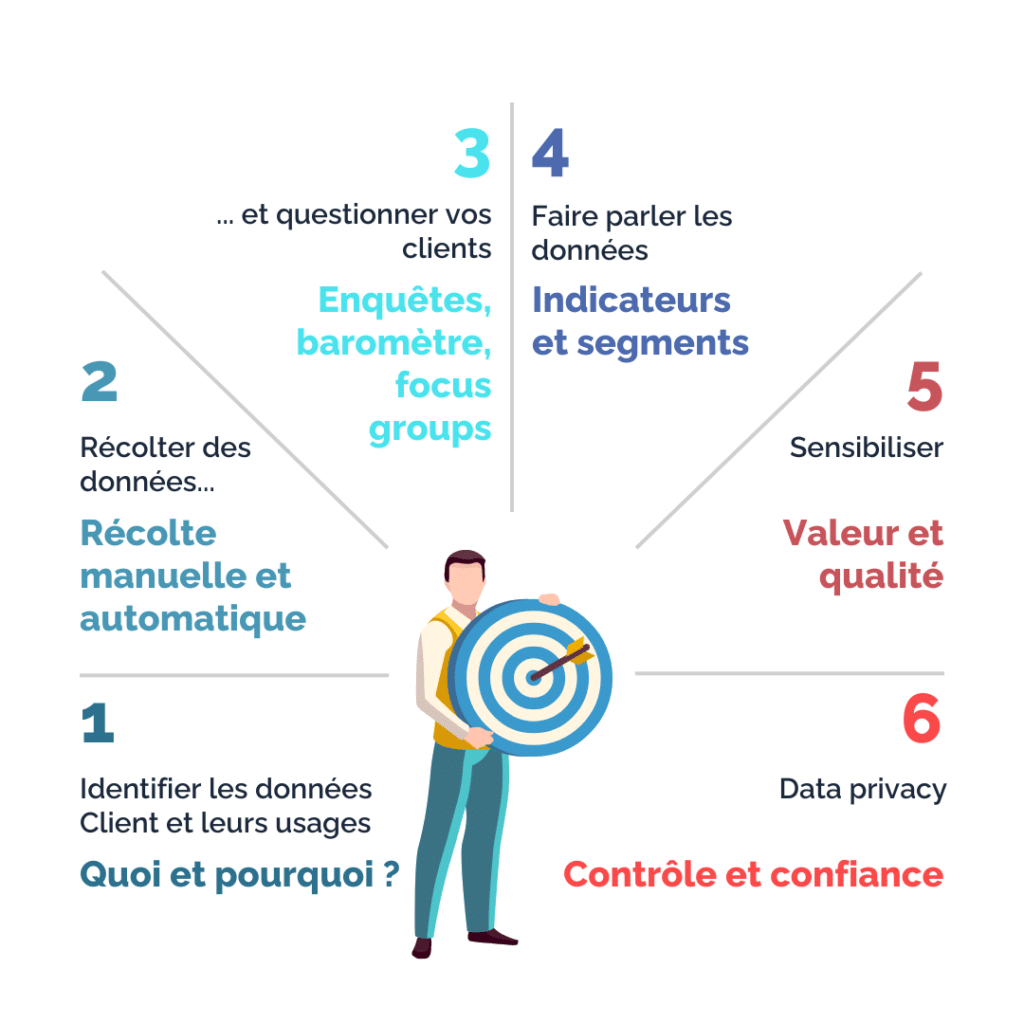
1. Identifier les données utiles et mettre en place des mesures de collecte ciblées
Les données client identifiées comme utiles peuvent couvrir un large éventail : données démographiques, de qualification, de consommation, de navigation, de sollicitation, de retours aux sollicitations, etc. Selon le secteur d’activité et la dimension du parc clients, ces données peuvent occuper un volume plus ou moins important. Dans l’ère du numérique durable et dans un souci d’efficacité opérationnelle, il devient aujourd’hui essentiel de bien sélectionner les données utiles qui permettent de répondre aux problématiques métier définies du marketing et du commerce. L’objectif est effectivement de cibler la « good Data », à la différence de la « full Data ».
Des mesures de collecte doivent ensuite être mises en place pour récupérer cette « good Data ». Ces données sont récupérées de deux manières : manuellement ou automatiquement. Les mesures de collecte manuelles adressent les collaborateurs amenés à interagir avec les clients. L’interaction avec le client est une opportunité à ne pas rater pour recueillir de l’information pertinente sur votre client : ses données de contact, ses centres d’intérêts, ses préférences de canal, etc. Les mesures de collecte automatique concernent les systèmes du front ou d’applications tierces, qui récupèrent automatiquement des données. Ces données sont par exemple issues du tunnel d’achat web ou d’une connexion d’un client sur son espace. Il peut s’agir de cookies (récoltés bien entendu avec consentement, à noter que l’utilisation des cookies tiers ne sera bientôt plus autorisée). Dans ce cas, les parcours doivent être réfléchis en amont pour identifier quelles données sont à récupérer et permettre par la suite cette récupération.
2. Demander directement à vos clients ce qu’ils souhaitent !
Si vous souhaitez connaître ce que pensent vos clients, leurs impressions, ou leurs attentes (en termes de produit, mais aussi d’expérience), il suffit parfois de leur demander ! Pour cela, plusieurs techniques existent.Au niveau du client, il est par exemple possible d’insérer sur son parcours web des questions bien choisies qui permettent ainsi de lui proposer les pages, les offres ou produits répondant à son besoin. Les réponses à ces questions sont par ailleurs enregistrées et pourront servir pour la prochaine visite. Attention bien entendu à ne pas alourdir le parcours. C’est une technique à utiliser avec parcimonie. Il est également recommandé d’envoyer un questionnaire de satisfaction après chaque interaction afin de récupérer le retour du client sur son expérience. Ce type d’enquête peut être qualifié de transactionnelle, car elle fait suite à une transaction entre le client et l’entreprise.
Au niveau de votre base de clients, une bonne pratique consiste à régulièrement la sonder, avec des enquêtes ou des baromètres. Ces enquêtes permettent d’avoir un avis général sur la marque et non sur un cas d’usage précis. Elles ne sont en outre pas nominatives. Il s’agit là d’enquêtes relationnelles. Les résultats sont globaux, ils donnent une température générale d’appréciation de votre marque. Les indicateurs les plus classiques issus de ce type d’enquête sont les taux de satisfaction et le NPS (Net Promoter Score). Ce type de données, marqueurs de la perception de vos clients, sont appelées des « Insights ».
Pour affiner vos produits ou parcours ou trouver des solutions à vos points de douleur, il reste enfin la possibilité de convier un échantillon représentatif de votre base clients pour un ou plusieurs ateliers de travail. Il s’agit là de Focus Groups. Les travaux en direct avec des clients sont très bénéfiques, car ils permettent de mettre en évidence des impressions ou intuitions faussées, parfois nourries au sein de l’entreprise en raison d’un manque de prise de recul.
3. Faire parler vos données client : calculs et rapprochements
Les nouvelles technologies ont évolué extrêmement vite ces dernières années, pour permettre aux entreprises de stocker et d’analyser des données dont le volume croît de manière exponentielle. C’est ainsi qu’est apparue la notion de « Big Data ». Les nouveaux usages, dont la digitalisation de parcours, sont entre autres à l’origine de ce volume grandissant. Ces données sont souvent éparpillées dans plusieurs systèmes (DMP, CRM, ERP, ITSM,…), ce qui nécessite un travail de centralisation et de traitement pour les rendre exploitables. Bien entendu, les modalités de stockage et de purge de ces données doivent être réfléchies pour répondre aux enjeux du numérique durable et aux contraintes RGDP qui sont abordées plus bas dans cet article. Ces données (bien choisies en amont) constituent tout de même une vraie mine d’or pour qui sait les faire parler.
Faire parler les données, c’est construire de nouvelles données à partir de données dites « brutes ». Il peut s’agir d’indicateurs (ex : panier moyen), de segments (ex : RFM – Récence, Fréquence, Montant), ou de simples calculs (ex : nombre de mois depuis le dernier achat). Le calcul de ce type de données fait suite à la réflexion des équipes du marketing client. Ce type de données vient ainsi soutenir leur stratégie client. L’analyse poussée de ces données de masse, opérée par des spécialistes tels que des Data Scientists, permet aussi d’identifier des rapprochements qui peuvent parfois être surprenants. Le cas d’école le plus connu est la mise en évidence du lien entre l’achat de couches pour bébé et de bières par les jeunes papas dans une grande surface américaine. L’analyse poussée de gros volumes de données permet donc de décrypter finement les comportements client, et déceler des clés de compréhension pour favoriser le cross-selling, l’up-selling ou simplement améliorer l’expérience client, et ainsi fidéliser.
4. Bien visualiser et communiquer vos données pour mieux décider
La mise en visualisation des données est une étape cruciale à ne pas négliger. Une fois les données client récoltées et travaillées pour mieux comprendre le comportement de vos clients et leurs attentes, il est nécessaire de pouvoir visualiser ces données régulièrement pour identifier les évolutions et ajuster votre stratégie de relation client. Pour cela, deux éléments clés sont à déterminer en amont : les indicateurs à afficher et les modalités de mise à disposition. Le suivi de ces indicateurs sera facilité par la simplicité d’accès et de lecture de ceux-ci.
Le suivi des données client est primordial pour l’aide à la décision sur les sujets orientés client. D’une part, il permet d’identifier l’impact des actions marketing sur la base clients et d’en évaluer les performances. D’autre part, il permet d’identifier les ajustements à réaliser dans le calcul des indicateurs, comme une évolution devenue nécessaire de la segmentation comportementale. Enfin, il est important de diffuser régulièrement certains indicateurs orientés client au sein de l’entreprise, afin de sensibiliser les collaborateurs sur la valeur de la donnée et son rôle dans l’amélioration de l’expérience client.
5. Sensibiliser l’ensemble des collaborateurs sur la valeur des données client
L’acculturation à la valeur des données client est nécessaire pour sécuriser, d’une part la récolte des données, et d’autre part le bon usage de ces données.
Les collaborateurs en interaction avec les clients doivent comprendre les enjeux de la récolte des données et de leur qualité. Comprendre ces enjeux favorise leur engagement et leur implication dans cette récolte dont ils sont les premiers acteurs. Ceci est d’autant plus vrai s’ils bénéficient eux-mêmes dans leur quotidien de l’utilisation de ces données pour optimiser leur interaction avec le client. Ainsi la compréhension des enjeux fait partie intégrante de ce processus d’acculturation à la valeur des données. Ce processus doit bien entendu comporter un volet sur la qualité des données, pour des raisons évidentes d’utilisabilité.
La sensibilisation au bon usage de la donnée est également un facteur clé essentiel d’une entreprise orientée client. Comme évoqué plus haut, l’orientation client place le client au centre de sa stratégie. Cela suppose de bien le connaître pour planifier les bonnes actions : il s’agit alors d’être « data-driven ». La direction joue bien entendu un rôle prépondérant dans cette acculturation. Elle doit insuffler au sein de son organisation cet état d’esprit au travers de principes établis qui permettent de poser le cadre, mais également au travers d’une organisation décloisonnée et de formations spécifiques.
6. Prendre en compte les contraintes réglementaires et en faire une force !
Cet article évoque toutes les mesures nécessaires pour disposer d’une connaissance client complète et pertinente sur la base de données client. Mais qu’en est-il des contraintes réglementaires sur l’utilisation de ces données ?
Le RGPD (Règlement Général sur la Protection des Données), appliqué depuis 2018 en Union Européenne, pose un cadre sur la récolte et l’utilisation des données client. Ce règlement a vocation à permettre au citoyen européen de contrôler l’utilisation de ses données personnelles. Le RGPD entre ainsi en jeu dès la récolte des données client, puisque celle-ci est soumise au consentement du client. Le RGPD encadre par la suite l’utilisation de ces données et les finalités associées, ainsi que les modalités de conservation, de sécurité et les droits des personnes sur leurs données (ex : accès, rectification, suppression, portabilité). Ce règlement a donné naissance à une activité encore relativement récente au sein de l’entreprise : la Data Privacy.
Souvent perçus comme une contrainte par les acteurs du marketing client, les enjeux de la Data Privacy visent cependant la transparence sur les actions menées par les entreprises sur la base des données client. Le client est donc rassuré et la Data Privacy est ainsi transformé en véritable vecteur de confiance ! Pour cela, il est essentiel de maîtriser l’ensemble des modalités relatives à la Data Privacy, pour limiter les contraintes et interagir pertinemment avec les clients dont le consentement a été obtenu.
Vous avez maintenant toutes les clés pour bien connaître vos clients ! Vous l’aurez compris, bien connaître vos clients implique aussi d’une part de bien maîtriser votre portefeuille de données, et d’autre part de mettre en place une architecture qui optimise son usage. Pour en savoir plus sur le sujet, nous vous invitons à consulter nos expertises Transformation Data et Architectures.
Savez-vous que lancer les développements d’une solution sans modélisation de données, c’est comme construire une maison sans en avoir fait les plans ?
Si vous voulez avoir des solutions performantes et pérennes pour vos projets de transformation de vos SI, utilisez la modélisation de données, et en particulier la modélisation de données conceptuelle, comme un levier de performance.
Stocker des données n’est pas modéliser des données
Très souvent après avoir validé vos projets de transformation des SI pour atteindre les enjeux métier d’entreprise, l’objectif est de rapidement importer les premières données pour pouvoir les rendre ‘visibles’ et avoir des premiers résultats ‘concrets’.
Des développements sont donc lancés, sans l’étude préalable des données et des concepts nécessaires pour faire le lien avec le métier de l’entreprise. Ces développements conduisent à définir des tables et des jointures avec pour objectif de stocker des données. C’est la modélisation de données dite physique. L’objectif n’est pas le bon à ce stade. C’est une vision de solution court-termiste.
Une notion importante à appréhender est que le stockage des données et la structure de la base de données impactent directement la restitution, et donc l’usage des données. Cette structure est développée au travers du modèle de données physique.
Si vous mélangez les notions de modèle de données physique et de modèle de données conceptuel, et si vous ne comprenez pas bien les concepts fonctionnels manipulés, alors le modèle de données physiques ne répondra pas à tous les besoins adressés.
Toutes ces questions sont adressées au travers de la modélisation de données et en particulier la modélisation de données conceptuelle.
Dès lors, quels sont les objectifs de la modélisation de données ?
Nous avons vu que lorsque nous pensons modélisation de données, nous pensons tables, jointures, clefs étrangères. En réalité, cela revient à penser, tuyaux en PVC ou en cuivre, briques ou parpaings, avant même de savoir si nous souhaitons une maison de plain-pied ou à étages. La modélisation de données conceptuelle est donc une obligation.
Le modèle de données conceptuel conceptuel permet de définir des concepts (étonnant, non ?) transverses à l’entreprise, clairement définis entre les parties prenantes. Ces concepts sont liés pour répondre à un ensemble d’usages, qui lorsqu’ils sont regroupés dans des fonctions (définies au travers de l’architecture fonctionnelle), constitueront la solution informatique répondant aux besoins.
Le modèle de données conceptuel doit d’abord répondre à des usages propres au métier de l’entreprise. Prenons un modèle de données client par exemple. Il sera différent pour un assureur ou pour un industriel. Il sera également différent entre deux assureurs du fait de leur positionnement sur le marché. Le modèle conceptuel est donc basé sur l’utilisation des données qu’il contient : les usages valident le modèle.
La modélisation de données : une démarche à valeur ajoutée pour la DSI et surtout pour le métier
Le modèle de données conceptuel décrit les données stockées dans la solution de manière compréhensible par les métiers. D’autre part, il impose une démarche rigoureuse de conception concourant à la réussite du projet.
La modélisation de données doit ainsi commencer par lister les usages et les données sous-jacentes ou associées. S’entourer à la fois d’experts des données et d’experts métier est donc la clé. En effet, nous avons mis en évidence plus haut que le modèle de données conceptuel doit répondre aux deux enjeux à la fois :
Les experts des données sont responsables de découvrir et connaître les données, leur qualité réelle et leur utilisation réelle.
Les experts métiers sont responsables eux de décrire les usages actuels et cibles de ces données. Les usages étant les processus métiers de l’entreprise dans lesquels vont être utilisées ces données, mais aussi les contraintes liées à la mise à disposition de ces données (réglementaires, sécurité, etc.).
Construire et valider le modèle de données conceptuel est donc une démarche itérative afin d’échanger très régulièrement entre le métier, les experts de la donnée et la DSI.
Un modèle de données conceptuel performant est avant tout un modèle métier qui traduit des besoins métiers : on ne peut modéliser sans avoir une expression de besoin décrivant les usages.
La modélisation conceptuelle s’inscrit également dans une démarche de gouvernance des données. En effet, les premières questions posées naturellement quand le modèle de données se construit sont par exemple : quelle est la définition de ce concept ? dans quel cycle de vie s’inscrit-il ? etc. Les métiers définissent les concepts, les périmètres et les responsabilités avec le modèle de données conceptuel.
Avec cette démarche, en tant que DSI, vous minimisez les risques de choix court-termistes et de complexité de la solution développée. Vous bénéficierez ainsi d’une solution évolutive, maintenable, documentée et qui minimise également le shadow IT.
En tant que métier, cela vous permet d’être au plus proche des développements et vous comprenez grâce au modèle de données conceptuel, les données manipulées dans la solution. Vous minimisez ainsi les risques d’inadéquation avec les attentes métier.
En tant que responsable projet, product owner, ou responsable SI, imposez donc d’avoir une démarche de modélisation de données qui commence par un modèle conceptuel dans tous vos projets SI. Il est un facteur clef de réussite !
La modélisation de données : une compétence clé
La gestion du cycle de vie du modèle de données conceptuel et des impacts sur le stockage des données (base de données), doivent être suivis et validés par une personne experte en modélisation de données. Le cycle de vie du modèle de données est un processus lent dont les évolutions ne se voient pas forcément.
Une modélisation de données performante doit garantir une cohérence, une intégrité et une interopérabilité des données et des solutions. Une mauvaise modélisation de données crée ainsi lentement des blocages SI pour de futurs usages. Une illustration simple de cette mauvaise modélisation de données, est de laisser en attributs des données qui ont des cycles de vie différents de l’objet auquel ils sont rattachés. Multipliés par le nombre de données à l’échelle de l’entreprise et ajoutés à la complexité d’un modèle, ces problèmes de modélisation de données rendent le SI rigide.
La modélisation de données est donc une compétence spécifique. C’est une expertise qui s’acquiert au fur et à mesure des projets. Elle est nécessaire aux équipes de conception telles que les Business Analysts et les Architectes de données.
La modélisation de données, un facteur clef de succès de la transformation des SI
La modélisation des données est donc indispensable à un projet de développement de solution informatique. Comme évoqué précédemment, avec le modèle de données conceptuel, elle manipule des concepts métier de l’entreprise. Elle doit donc se projeter et anticiper les nouveaux concepts nécessaires aux nouvelles demandes client. Elle garantit ainsi l’agilité et l’évolutivité de votre solution face à la diversité des usages à adresser pour répondre aux demandes client en perpétuelle évolution.
Une question reste alors : la modélisation de données dépendant de la qualité des données des concepts métier, est-ce que les processus métier actuels de l’entreprise peuvent être modifiés pour fournir la qualité des données nécessaires aux nouvelles demandes client ?
Les projets d’API Management sont fondamentalement simples. Il s’agit de faire échanger des données d’un système A vers un système B. Mais c’est sans compter sur le fait qu’un projet d’API Management fait intervenir un grand nombre d’acteurs, ce qui engendre de la complexité.
Les acteurs de la gestion des API
Pour commencer, nous pouvons énumérer les acteurs typiques impliqués :
Le CxO qui a décidé que les API faisaient partie de la stratégie de l’entreprise, mais qui ne vous donne pas un parrainage très fort ;
Les autres CxOs qui ont d’autres priorités que les APIs ;
L’équipe A qui veut accéder à des données, mais qui n’a pas le temps de s’occuper de vous ;
L’équipe B qui est responsable de données exposées, mais qui n’a pas de temps à vous consacrer ;
Les développeurs de la solution qui veulent accéder aux données ;
Les développeurs de la solution qui exposent les données ;
Les membres de l’équipe de gestion de l’API ;
Et au moins un architecte, bien évidemment !
On voit bien qu’il y a une multiplicité d’acteurs, qui vont tous pousser dans leur propre direction. Et on perd rapidement toute forme de coordination si :
L’équipe de gestion de l’API ne joue pas un rôle de coordination constructif ;
Il n’y a pas de parrainage des membres du CxO.
Le défi de la complexité
Il est donc nécessaire de maîtriser la complexité de l’entreprise et la complexité due à ses interactions et à ses acteurs. En effet, selon la théorie des systèmes complexes, la complexité du système « entreprise » réside dans le nombre élevé d’acteurs et le nombre élevé d’interactions entre eux !
Ce qui est complexe, ce n’est pas de faire une API avec un acteur, mais de faire une API avec, par et pour de multiples acteurs.
Il est donc fondamental de :
Chercher à aligner tous les acteurs dans la même direction par une très bonne communication, des explications sur les bonnes pratiques, etc. ;
Faire de l’équipe de gestion des API un point d’échange central pour toute conversation sur les API ;
Infuser les connaissances dans toutes les équipes autant que possible.
A partir de là, on peut déduire deux prérequis :
Une gouvernance claire, simple et efficace est essentielle ;
Un sponsorship solide doit garantir l’alignement de l’entreprise sur un projet d’API.
Le mode d’organisation le plus souvent utilisé est le mode de gouvernance que j’appelle open source. L’équipe API encadre, guide, aide, soutient, mais surtout permet à chacun de contribuer facilement et efficacement.
De ces activités et défis ainsi énumérés, nous pouvons ainsi déduire deux types d’activités.
Deux typologies d’activités de l’équipe API
On peut ainsi diviser les activités d’une équipe API en deux types d’activités : les activités régaliennes et les activités étendues. En effet, la gouvernance d’une équipe de gestion d’API doit fixer un cadre dans lequel tous les acteurs impliqués dans les API doivent s’inscrire, afin que tous les acteurs puissent pleinement travailler.
Les activités régaliennes
Nous pouvons appeler activités régaliennes les activités pour lesquelles l’équipe de gestion des API a toute l’autorité et ne peut être supprimée. Dans ces activités, nous pouvons mettre :
La mise en œuvre et l’administration technique de la plateforme API Management.
La définition des meilleures pratiques de gestion d’API.
Les formats des ateliers de définition des API – pour passer de réunions interminables et contre-productives à des réunions efficaces et productives. J’ai personnellement réduit par 4 le nombre d’ateliers, juste en repensant la façon dont nous les animons !
L’organisation des ateliers API – Pour être le moteur des sujets API, mais libre à l’équipe API Management de laisser les équipes concernées s’organiser elles-mêmes si elles sont suffisamment autonomes.
La gestion de la formation et de la communication – Pour assurer l’adhésion des équipes, et pour démontrer la valeur ajoutée des équipes d’API Management.
Les activités étendues
Certaines activités doivent cependant être menées non pas sur un mode purement régalien mais sur un modèle beaucoup plus collaboratif, car après tout, il s’agit d’organiser les échanges entre au moins deux systèmes :
Définir et gérer le cycle de vie des API avec les projets et les architectes fonctionnels – Même si l’équipe API a le dernier mot, elle reste au service des projets et du métier ! Ne l’oubliez jamais !
Travailler avec les architectes sur l’alignement des besoins en API dans une feuille de route claire – Les architectes sont censés avoir une vision à moyen et long terme des besoins futurs, les équipes API sont censées s’aligner sur eux !
Outiller pour les développeurs afin d’apporter les bons outils et cadres de travail – Dire à un projet « allez-y et faites l’API » n’est pas suffisant ! Dites-le à un projet Legacy ! C’est aux équipes API de travailler avec les projets pour moderniser la base technique, la distribuer et la partager avec d’autres équipes de développement.
Contribuer à l’idéation avec les métiers pour trouver de nouvelles idées d’API – Le but étant de tirer le maximum de valeur des actifs de l’entreprise.
2 typologies de gouvernance, ou plutôt 2 “curseurs” de gouvernance
Enumérer une liste de tâches n’est pas pour autant équivalent à définir une gouvernance API.
De ces deux typologies d’activités, on remarque que le pattern “décentralisée” revient forcément.
En effet, le mode de gouvernance qu’on pourrait appeler “décentralisée” revient très souvent. Dans ce mode de gouvernance, l’équipe d’API Management a comme but principal de permettre à tout à chacun de contribuer facilement et efficacement. Ainsi, charge à l’équipe API Management de cadrer, orienter, aider, d’apporter du support, mais pas nécessairement d’implémenter et définir les APIs. C’est une logique de gouvernance qui cherche avant tout à permettre aux autres équipes de travailler de manière autonome.
Dans une logique totalement inverse, l’autre mode de gouvernance que l’on rencontre régulièrement est une gouvernance centralisée. Le centre de compétence d’API regroupe alors toutes les compétences nécessaires, et travaille de manière auto-suffisante.
Pour autant, rares sont les entreprises qui mettent en place une gouvernance aussi “marquée” par une de ces deux logiques. Toute la question est de pouvoir s’adapter à l’organisation de l’entreprise et de son SI, mais aussi de s’adapter à la maturité et à l’autonomie des équipes en place. Il faut toutefois bien chercher à autonomiser les équipes, sans quoi il vous sera impossible de “scaler” votre organisation autour des APIs, sans compter les effets de bord d’une logique de tour d’ivoire…
Le site internet est une vitrine de l’entreprise, celui qui vous permet de vous présenter à vos partenaires, candidats, clients, prospects… bref, à tout votre écosystème. Il est donc primordial qu’il donne confiance quant à la gestion des données de vos visiteurs, et qu’il soit conforme à la réglementation en vigueur. Un site conforme au RGPD, transparent sur l’utilisation qu’il fait des données que le visiteur lui fournit, offre une bonne première impression et évite de devoir expliquer à vos clients que vous n’êtes pas conforme RGPD si la CNIL décide d’auditer votre entreprise.
Le RGPD n’est pas l’unique règle qu’il faille appliquer pour considérer son site internet comme absolument conforme (règle EPrivacy, régle de régulation des mentions légales, …). Nous nous sommes principalement focalisés ici sur le RGPD.
Il n’est toutefois pas toujours aisé de démêler concrètement les impacts de la réglementation sur votre site et de savoir s’il est bien en phase avec celle-ci. Chez Rhapsodies Conseil, nous vous avons donc préparé une synthèse des quelques points clefs auxquels vous devez vous intéresser.
1. Les cookies
Première action du visiteur sur le site : le bandeau cookie
Un bandeau cookie, doit répondre à 3 obligations indispensables :
Acceptation, refus, paramétrage
Les boutons accepter tous les cookies et refuser tous les cookies sont obligatoires. L’interface ne doit pas avantager un choix plus qu’un autre, les deux boutons doivent, entre autre, avoir la même taille, la même forme et la même couleur.
Le bouton paramètrage n’a pas l’obligation d’être identique aux deux autres, et doit permettre de choisir quel type de cookie j’accepte et quel type de cookie je refuse.
Lors du paramètrage, lesopt-in doivent obligatoirement être désactivés par défaut. Accepter tel ou tel type de cookie doit résulter d’une action du visiteur.
Chaque type de cookie (Fonctionnel, Performance, Analytique, …) doit être décrit afin d’éclairer le visiteur dans son choix. Chaque choix doit se faire par finalité, c’est-à-dire que le visiteur peut refuser les cookies de Performance et de Publicité et accepter tous les autres sans que son parcours sur le site ne soit différent.
Tant que le visiteur n’a pas donné son accord explicite de dépôt de cookies (autre qu’obligatoire), aucun cookie ne doit être déposé.
L’utilisateur doit pouvoir revenir sur son choix dès qu’il le souhaite, il doit donc y avoir un moyen pour le visiteur de revenir sur le paramétrage des cookies afin de refuser/accepter les cookies.
Le bon fonctionnement du paramétrage des cookies & preuve de consentement
Il arrive souvent que, bien que le bandeau cookie permette de refuser le dépôt de certains cookies, celui-ci ne soit pas totalement fonctionnel. Il est donc primordial de vérifier régulièrement que l’outil de paramétrage est bien opérationnel.
Enfin, il est indispensable de pouvoir conserver la preuve du consentement (article 7 du RGPD).
Lien vers la charte des données ou charte des cookies
Le visiteur doit pouvoir accéder à la politique d’utilisation des cookies, rapidement et avant de faire son choix. Un lien vers la politique d’utilisation des cookies doit donc être présent sur le bandeau.
Cette Politique des cookies doit comprendre : une description de ce qu’est un cookie, une description de comment supprimer les cookies par navigateur, la finalité et la durée de conservation des cookies, le type de cookies et préciser (dans le cas d’un cookie tiers) le tiers en question et le lien vers sa propre politique de confidentialité ou de cookies. Contrairement aux idées reçues, la liste exhaustive des cookies n’est pas obligatoire.
ATTENTION : les cookies collectent des données personnelles, ils ne peuvent donc pas être transférés vers des pays où la réglementation sur la protection des données personnelles n’est pas conforme au RGPD. Les Etats-Unis, par exemple, ne donnent pas une protection sur les données personnelles suffisante pour que les données y soient envoyées. L’utilisation des Cookies Google Analytics (_ga, _gat, …) n’est donc pas acceptée.
2. Les mentions d’informations et la charte des données personnelles
Les mentions d’informations sont les petits textes se trouvant sous les « points de collecte de données » (Newsletter, point de contact, inscription, …). Afin de pouvoir faciliter la compréhension, j’aime décrire les mentions d’informations comme une « charte des données personnelles spécifique au point de collecte »
Une mention d’information doit notamment contenir certaines informations que sont :
Un rappel des données personnelles qui sont collectées suivi par l’utilisation qui en est faite ;
Un lien vers la charte des données personnelles ;
La base légale sur lequel s’appuie le traitement ;
Le destinataire des données (préciser si un transfert des données hors de l’UE est effectué) ;
La durée de conservation des données (non-obligatoire si celles-ci sont présentes dans la charte des données personnelles) ;
Le rappel des droits ;
Le point de contact (DPO).
Toutes les informations peuvent se trouver dans un texte sous le point de collecte, il est possible de créer une page spécifique à la mention d’information accessible via un lien (cf. exemple ci-dessus). L’important est de respecter le principe de transparence qui implique que les informations soient présentées d’une forme claire. Il est conseillé que cela soit ludique et adapté aux interlocuteurs concernés.
La charte des données personnelles quant à elle est indispensable dès qu’une donnée personnelle est collectée sur le site. Cette charte doit comprendre les informations suivantes :
Le nom du responsable de traitement ;
Les finalités de traitement ;
Les bases légales sur lesquelles reposent les traitements (si un traitement repose sur le consentement, il faut préciser que celui-ci peut être retiré) ;
Les destinataires des données (avec précision si les données sont transférées hors de l’UE et les garantis quant au respect des règles de sécurités imposées par le RGPD (anonymisation, pseudonymisation, …)) ;
La durée de conservation des données personnelles ;
Le rappel des droits des personnes (accès, limitation, suppression, opposition, rectification et portabilité) ;
Le contact pour faire valoir ses droits (DPO) ;
Le droit de déposer une réclamation auprès de la CNIL ;
L’existence (ou non) d’une prise de décision automatisée ;
La source des données s’il existe une collecte indirecte.
La charte doit être mise à jour dès qu’un nouveau traitement est créé.
Il est possible que vous n’ayez pas besoin de créer de charte des données personnelles. C’est le cas si les mentions d’informations de tous les points de collecte de votre site internet contiennent des mentions d’informations spécifiques et complètes comprenant les informations obligatoires. Si vous répondez à ce cas de figure, il vous faudra cependant une charte des cookies.
3. CGU, CGV, mentions légales
Les CGU ne sont pas obligatoires mais apportent un cadre d’utilisation du site internet (droits et obligations respectives à l’éditeur et au visiteur). Si votre site internet n’est qu’une vitrine et qu’il ne permet pas la création d’un compte, un achat, le dépôt d’un commentaire, … il n’est pas obligatoire d’avoir des CGU.
Cependant, celles-ci sont indispensables dans les cas contraires. En effet, les CGU peuvent être considérées comme le “règlement intérieur du site”. Elles donnent les droits de l’utilisateur, ses responsabilités et également celles en cas de non-respect.
Les droits de l’utilisateur doivent être précisés, par exemple dans le cas de la création d’un espace personnel. Ces dispositions des conditions générales d’utilisation permettent d’engager la responsabilité de l’utilisateur en cas de dommage résultant du non-respect desdites obligations.
Francenum.gouv.fr
L’utilisateur du site doit accepter explicitement les CGU pour qu’elles puissent être considérées comme légales.
Contrairement aux CGU, les CGV sont obligatoires dès que le site propose un service de paiement, vente, livraison en ligne. Les CGV correspondent à la politique commerciale du site internet (modalité de paiement, délais de livraison, rétractation, …). Elles sont particulièrement utiles en cas de contentieux. Cependant, il n’est pas obligatoire de les avoir disponibles directement sur votre site internet, si vos clients sont professionnels (B2B). Elles le sont si vos clients sont des particuliers (obligation précontractuelle d’information du vendeur). Pour chaque vente, les CGV doivent être acceptées par le particulier (B2C).
Les mentions légales sont les informations permettant d’identifier facilement les responsables du site. Pour une personne physique, il faut inclure :
Le nom et le prénom ;
L’adresse du domicile ;
Le numéros de téléphone et l’adresse mail.
Pour une personne morale (une société), il faut inclure :
Le nom de l’entreprise et le numéro SIRET ;
La forme juridique de la société ;
Le montant de son capital social ;
L’adresse du siège social.
Il est aussi impératif de préciser les mentions relatives à la propriété intellectuelle :
La propriété intellectuelle des photos, images, illustrations, textes qui ne sont pas les vôtre (à minima la source des tactes).
En complément de ces informations, il est indispensable d’inclure :
Le nom de l’hébergeur et sa raison sociale ;
L’adresse de l’hébergeur ;
Le numéros de SIRET de l’hébergeur ;
Le numéro de téléphone de l’hébergeur.
Certaines activités impliquent d’ajouter certaines informations :
le numéro d’inscription au registre du commerce et des sociétés (RCS) (et numéro de TVA intercommunautaire, si vous en avez un) ;
le numéro d’immatriculation au répertoire des métiers (RM) ;
le nom du directeur/codirecteur ou responsable de la publication (si vous proposez des articles, des blogs, des informations, …) ;
le nom et l’adresse de l’autorité vous ayant délivré l’autorisation d’exercer (si votre activité est soumise à un régime d’autorisation).
4. Le principe de minimisation
Très souvent, on a tendance à vouloir collecter le plus de données possibles « au cas où », sans finalité précise. Cependant, depuis le RGPD, le principe de minimisation limite cette tendance.
Le principe de minimisation prévoit que les données à caractère personnel doivent être adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées.
CNIL
Ainsi, il n’est plus possible de collecter des données ne pouvant pas être justifiées par la finalité de traitement. Par exemple, demander le genre de la personne pour une inscription à une Newsletter n’est pas possible, sauf si on le justifie (par ex. le contenu de la Newsletter est différent selon que l’on est un homme ou une femme).
Ces quelques points vous donnent une première approche à avoir pour vérifier que votre site est bien conforme. La revue du site est aussi un bon moyen de faire une passe sur les données collectées et lancer une véritable mise en conformité de vos traitements de données (bases de données, contrats, CRM, …).
Chez Rhapsodies Conseil, nous nous appuyons sur des outils internes et externes qui ont fait leurs preuves et sur l’expertise de consultants expérimentés pour analyser la conformité de vos sites internet.
Il y a encore aujourd’hui de nombreuses entreprises qui ne misent pas encore sur les API et qui se demandent encore comment faire. Elles se retrouvent souvent bloquées par le grand nombre de questions qui se posent à elles, ne sachant pas comment aborder ce genre de projets. Elles se retrouvent rapidement bloquées. C’est pourquoi je préconise une démarche MVP.
L’approche MVP pour un projet d’API Management
Parler d’approche MVP pour d’aussi gros projets peut surprendre. En effet, les points à soulever sont nombreux, que l’on parle de sécurité, des solutions techniques, de l’organisation, de la roadmap API ou encore de la définition de bonnes pratiques.
Mais les avantages d’une démarche MVP pour un projet d’API Management sont nombreux :
Démontrer la valeur :
En mettant en place la première API en mode MVP, il est possible de communiquer plus rapidement aux métiers ce que l’on peut désormais faire grâce aux API.
Démontrer la faisabilité :
Dans le cas de systèmes Legacy complexes, encore plus s’ils sont cloisonnés, les raisons sont nombreuses de penser qu’il sera long et compliqué de mettre en place des API. Grâce à l’existence de nombreux modèles d’architecture d’intégration (comme le CQRS), il est plus facile qu’on ne le pense de faire sauter les verrous !
Obtenir des retours d’expérience :
Plutôt que les audits SI et autres audits de maturité, qui sont longs et pas toujours pertinents, rien de tel que des REX réguliers pour faire avancer un projet d’API Management.
Prioriser les initiatives :
Grâce aux premiers retours d’expérience, il est possible de savoir quelle initiative prioriser. La gouvernance doit-elle être étudiée ? La stratégie d’intégration ? La communication interne ?
Réduire les risques :
La démarche MVP permet d’adopter une approche totalement intégrée, avec des décisions de type Go/NoGo à chaque étape. Vous courrez donc un risque réduit à sa portion la plus congrue.
Cette approche MVP peut rapidement aboutir à une première API en un mois, certes imparfaite, mais utilisable. Est-ce qu’il y aura encore des questionnements après un mois ? La réponse est évidente : c’est oui ! Et vous serez même en mesure de classer ces questionnements par ordre de priorité !
Approche MVP et grandes étapes
Une approche MVP étalée sur quatre semaines est clairement réalisable, pour peu qu’on suive les grandes étapes suivantes :
Définition du périmètre (première semaine) :
Choix d’une API candidate :
Vous allez d’abord choisir une première API en fonction de sa facilité à être instanciée et de la valeur qu’elle apportera. Visez le gain rapide !
Lister les attendus :
Plusieurs contraintes techniques, fonctionnelles et autres sont susceptibles d’être émises par les parties prenantes, qu’ils soient métier ou IT. Collectez-les !
Visioning (deuxième semaine) :
Définition de l’architecture :
Vous devez ensuite définir l’architecture cible de votre gestionnaire d’API. Une solution sur site ? dans le nuage ? L’important est de le faire rapidement. Ce n’est pas compliqué de changer le gestionnaire d’API, vous aurez le temps de le changer plus tard. Visez vite et pas cher ! Et n’oubliez pas les sujets d’authentification.
Définition de l’API :
Il vous faut ensuite définir l’API. Un travail à faire de concert avec les métiers, les développeurs et les architectes.
Validation :
Partagez enfin votre API et votre architecture avec tout le monde, pour la valider.
Construction (troisième semaine) :
Installation des composants :
Il est donc temps d’installer votre gestionnaire d’API ! N’oubliez pas, dans le cas de solution cloud, de vérifier s’il n’y a pas de contraintes de sécurité à gérer !
Développements :
Rien n’est plus simple que d’instancier une API, avec son interface. Et n’oubliez pas les sujets d’authentification (bis repetita).
L’intégration et les tests avec les systèmes consommateurs :
Bien sûr vous devez tester. Avec toutes les parties prenantes disponibles, idéalement en même temps…
Rétrospective (quatrième semaine) :
REX technique et métier :
Faites des démonstrations de votre API, avec présentation de la plateforme d’API Management. Ce faisant, vous obtiendrez des retours techniques et métiers.
Initiatives à venir à prioriser :
C’est le bon moment pour lister les prochaines initiatives. Comme les retours d’expérience viennent d’être faits, il n’est pas question de tout arrêter. Continuez !
En respectant ces étapes, vous serez en mesure de poursuivre votre programme API grâce au travail des initiatives priorisées, mais surtout, de pouvoir continuer sur votre lancée ! Et n’oubliez pas que les projets d’API Management nécessitent beaucoup de communication et d’évangélisation !
Après la multicanalité* et la cross-canalité*, l’omnicanalité* s’est imposée comme le principe de référence de l’expérience client ces dernières années. L’accélération de la digitalisation et de l’évolution des usages n’a fait qu’amplifier l’importance de cette tendance.
L’omnicanalité est ainsi devenue un enjeu majeur pour les acteurs de l’expérience client.
Pour quelle raison ce concept s’est imposé ? Que se cache-t-il derrière cette notion d’omnicanalité ? Est-ce une utopie ou un idéal atteignable ?
L’omnicanalité s’est imposée suite à une prise de conscience simple : un client satisfait de son expérience avec une entreprise, aura plus tendance à rester fidèle à cette entreprise. En outre, la fidélisation est beaucoup moins coûteuse que l’acquisition de nouveaux clients. Il devient donc essentiel de répondre au plus près aux attentes des clients sur l’ensemble de ses interactions avec l’entreprise.
L’omnicanalité place le client et les points de contact au centre de la stratégie de relation client. Elle consiste à offrir une expérience client optimale, qui met en œuvre plusieurs canaux fonctionnant en synergie. Elle permet de déployer des parcours fluides et sans couture, répondant aux attentes du client.
Et concrètement, comment mettre cela en musique ?
Nous vous donnons les facteurs clés de succès pour faire de l’omnicanalité une réalité dans votre entreprise.
1. Travailler sur la connaissance client et clarifier vos ambitions sur chaque profil
Les éléments permettant de mieux connaître le client sont multiples : analyse des données client récoltées, enquêtes de satisfaction, recueil d’insights, d’informations ou construction de persona. Ils permettent d’enrichir la connaissance client et de construire la vision client 360. Cette vision unifiée doit être partagée avec l’ensemble des collaborateurs de l’entreprise. Différents profils peuvent être identifiés, parce qu’ils sont adressés différemment. Les ambitions en termes d’expérience doivent être clarifiées pour chaque profil par les directions marketing et expérience client. Ces ambitions répondent aux besoins de chaque profil (exemple : autonomie vs disponibilité).
2. Définir les parcours cibles à partir de votre client et non du canal à déployer
Un parcours cible correspond à la combinaison optimale : profil client / cas d’usage / canal / expérience client. Les travaux sur ces combinaisons ont vocation à aligner les parcours sur les ambitions définies pour chaque profil de client. Il s’agit d’aller là où le client se trouve. Une attention particulière doit être apportée aux points d’interaction entre le client et l’entreprise. Les parcours doivent être simples, intuitifs et doivent nécessiter un minimum d’effort pour le client. Les touch points deviennent ainsi des vecteurs fondamentaux de la promesse de marque de l’entreprise.
3. D’une organisation en silo vers une organisation unifiée et Customer Centric
Les directions Expérience Client ont émergé ces dernières années pour répondre aux enjeux de l’omnicanalité. Terminée la concurrence entre les canaux, l’expérience client doit être traitée dans sa globalité, sur l’ensemble des canaux. Pour exceller dans l’expérience client et l’omnicanalité, la culture Client doit infuser dans l’entreprise : satisfaire le client, notamment en supprimant les points de douleur (ou “pain points”), devient l’objectif prioritaire de l’entreprise. L’entreprise évolue ainsi pour prendre en compte ses attentes de manière continue. Cette évolution s’accompagne souvent d’une restructuration des modes de fonctionnement pour permettre le ruissellement des retours client dans l’entreprise. Il ne s’agit pas d’impliquer uniquement les collaborateurs en interface avec le client, mais d’impliquer tout un écosystème qui contribue de près ou de loin à optimiser l’expérience client. Une entreprise Customer Centric place le client au centre de ses enjeux et se différencie de ses concurrents en orientant ses décisions en regard des attentes des clients. Elle crée de la valeur en rendant le client fidèle et promoteur de la marque.
4. Se doter des bons outils pour répondre à vos enjeux sur l’ensemble des leviers de la relation client
CRM ventes / service client, marketing automation, plateformes conversationnelles, gestion des réseaux sociaux, gestion des sites internet, chatbot, etc : les outils permettant de mettre en place des parcours omnicanaux sont multiples. Ils adressent tout le cycle de vie du client : acquisition, fidélisation, rétention et reconquête. A ces outils s’ajoutent ceux qui permettent de gérer et structurer en amont les données client : Référentiel Client, Customer Data Platform, Data Quality Management, Référentiel des consentements, etc.
Avant de décider de la mise en place d’un outil orienté Client, il est nécessaire d’avoir une vision claire sur les ambitions et les objectifs fixés. L’élaboration d’une stratégie Client claire simplifie le choix des outils et plus généralement de l’architecture à mettre en place. Ce choix nécessite une bonne connaissance de ces outils et de leurs finalités. Tous les leviers de la relation client et les outils associés concourent à la mise en place de l’omnicanalité !
5. Tester et mesurer pour s’améliorer en continue et maintenir une veille
Il n’existe pas un modèle unique d’omnicanalité. De ce fait, une démarche pas à pas est à privilégier pour réussir son projet d’évolution vers l’omnicanalité. Un déploiement progressif permet de s’assurer de la pertinence des choix faits en amont. Réaliser des tests est également nécessaire pour s’assurer de la bonne direction des évolutions. Plus spécifiquement, la technique d’A/B testing est intéressante pour évaluer différentes variantes et choisir la meilleure. Ces expérimentations ne doivent pas être limitées aux canaux digitaux. Il est également possible de tester de nouvelles approches sur les canaux “traditionnels”. Pour cela faites preuve de créativité et d’innovation !
Il est enfin indispensable d’opérer une veille pour rester aligné sur les attentes des clients, voire les anticiper. De nouveaux usages émergent régulièrement, notamment grâce à de nouvelles technologies. Les nouvelles tendances s’accélèrent et il est important de rapidement prendre le train en marche pour s’adapter aux nouvelles pratiques. Analyser et s’inspirer de ce que font les champions de l’expérience client, quel que soit le secteur d’activité, est aussi nécessaire pour s’améliorer en continue et exceller à son tour.
A ces cinq facteurs clés de succès, s’ajoute bien entendu l’aspect architecture de vos systèmes qui doit permettre la mise en œuvre de l’omnicanalité. Pour en savoir plus sur le sujet, nous vous invitons à consulter l’expertise Architectures innovantes proposée par Rhapsodies Conseil.
Pour concrétiser votre projet et en savoir plus sur chacune de ces clés de réussite, nos experts de la Transformation Digitale et de l’Expérience Client vous accompagnent sur une démarche bout en bout, de la stratégie à la mise en œuvre. Contactez-nous !
*Multicanalité : variété des canaux de contact, indépendants les uns des autres. *Cross-canalité : variété des canaux de contacts, parfois complémentaires les uns des autres. *Omnicanalité : synergie entre les canaux de contact, au service d’une expérience client optimale.