Impulsées par l’avènement du Cloud et du DevOps, les mouvances “as Code” et “Software Defined X” ont grandement amélioré la gestion du cycle de vie des assets informatiques (infrastructure, middleware, serveur d’application, …) avec principalement :
L’Infrastructure as Code (IaC),
La Configuration as Code,
Nous détaillerons dans un futur article le positionnement de chacun et les grands paradigmes en présence (procédurale vs déclaratif), qui reposent sur une caractéristique commune: l’utilisation de template/playbook au format normalisé (HCL, YAML, …) décrivant l’état final à atteindre ou le moyen d’y aller.
Même si la syntaxe est Human Readable, il peut être fastidieux à l’échelle d’un SI enperpétuelle évolution d’écrire et de mettre à jour ces fichiers de description.
Bien qu’il existe de plus en plus de plateformes simplifiant la création de ceux-ci sur base de conception visuelle en LowCode/NoCode ou de schématisation…Que diriez-vous de troquer d’un point de vue utilisateur le ”as Code” par du ‘as Prompt” ?
#GenAI à la rescousse
Le terrain de jeux des Large Language Models (LLM) et de la GenAI ne cesse de croître, en n’oubliant pas au passage l’ingénierie logicielle.
Imaginez pouvoir simplement demander “Provisionne un cluster de VM EC2 avec NGINX en exposition publique ainsi qu’une base Elasticache” pour voir votre souhait exaucé instantanément.
D’ailleurs, n’imaginez plus, car l’Infrastructure as Prompt (IaP) est déjà proposée par Pulumi AI, et bien d’autres en cours (depX) ou à venir.
Ce positionnement et les avancées rapides et significatives dans ce domaine ne sont pas étonnantes car nous sommes en plein dans le domaine de prédilection des LLMs: les langages.
Qu’ils s’agissent de langages parlés (Français, Anglais, …), de langages de programmation (Python, JavaScript, Rust), de langage de description (HCL, YAML, …), ils ont tous deux concepts fondamentaux:
Un dictionnaire, un vocabulaire, une liste de mots avec une (plusieurs) signification(s) connue(s),
Une grammaire et des règles syntaxiques plus ou moins strictes donnant un sens particulier à la suite de mots d’une phrase ou d’une ligne de fichier de configuration.
Plus le dictionnaire et la grammaire d’un langage sont dépourvus d’ambiguïtés, plus le degré de maturité et la mise en application de la GenAI et des LLMs sur celui-ci peut-être rapide.
L’Infrastructure as Prompt n’est pas une rupture totale avec le “as Code”, simplement une modernisation de l’interface “Homme-Clavier”.
En effet, peu importe le moyen (création manuelle, auto-génération via prompt) l’aboutissement de cette première étape est la disponibilité du fichier de description.
Le cœur du réacteur, à savoir la traduction du <fichier de conf> en actions pour <provisionner et configurer les ressources>, est toujours nécessaire.
A l’avenir elle pourra se révéler un parfait assistant pour faire des recommandations et propositions d’ajustement vis-a-vis de la demande initiale pour optimiser l’architecture à déployer:
Prioriser les services managés,
Prioriser le serverless,
Etre compliant avec les best practices des frameworks d’architecture des Clouders (AWS Well Architected Framework, …),
Security By Design,
RIght sizing de l’infrastructure,
Opter pour des ressources ayant une empreinte carbone et environnementale optimisées.
#La confiance n’exclut pas le contrôle
Bien que la baguette magique qu’apporte cette surcouche soit alléchante, nous ne pouvons qu’abonder les paroles de Benjamin Bayard dans son interview Thinkerview Intelligence artificielle, bullsh*t, pipotron ? (25min) : “tous les systèmes de production de contenus si ce n’est pas à destination d’un spécialiste du domaine qui va relire le truc, c’est dangereux.” Dans un avenir proche l’Infrastructure as Prompt // la Configuration as Prompt n’est pas à mettre dans les mains de Madame Michu (que nous respectons par ailleurs) qui ne saura pas vérifier et corriger le contenu de Provisioning, de Configuration ou de Change qui a été automatiquement généré. Nous vous laissons imaginer les effets de bords potentiels en cas de mauvaise configuration (impact production, impact financier, …) dont le responsable ne serait autre que la Personne ayant validé le déploiement. Impossible de se dédouaner avec un sinistre “c’est de la faute du as Prompt”.
Vous l’avez compris, la déferlante LLM et GenAI continue de gagner du terrain dans l’IT, le potentiel est énorme mais ne remplace en rien la nécessité d’avoir des experts du domaine. Le “as Prompt” se révèle être un énorme accélérateur pour l’apprentissage du sujet, ou dans le quotidien de l’expert .. qui devra avoir une recrudescence de prudence quant aux configurations qui ont été automatiquement générées.
J’ai pu constater régulièrement que beaucoup de gens s’emmêlent les pinceaux quand il est question de définir et d’expliquer les différences entre Service Mesh, Event Mesh et Data Mesh.
Ces trois concepts, au-delà de l’utilisation du mot “Mesh”, n’ont pas grand chose de semblable. Quand d’un côté, nous avons :
Le Service Mesh qui est un pattern technique pour les microservices, qui se matérialise par la mise en place d’une plateforme qui aide les applications en ligne à mieux communiquer entre elles de manière fiable, sécurisée et efficace
L’Event Mesh, qui est un pattern technique d’échanges, afin de désiloter les différentes technologies de messaging
Et le Data Mesh qui lui, est un pattern général d’architecture de données, qui se matérialise par toute une série d’outils à mettre en place, et qui pousse le sujet de la productification de la donnée
On se dit déjà que comparer ces trois patterns ne fait pas sens ! Néanmoins, il y a peut-être un petit quelque chose, une évidence naturelle, qui peut découler de la comparaison.
Mais commençons donc d’abord par présenter nos trois protagonistes !
Le Service Mesh, ou la re-centralisation des fonctions régaliennes des microservices
Historiquement, l’approche microservice a été motivée, entre autres, par cette passion que nous autres informaticiens avons souvent, pour la décentralisation. Adieu horrible monolithe qui centralise tout, avec autant d’impacts que de nouvelles lignes de code, impossible à scaler en fonction des besoins fonctionnels réels. Sans compter qu’on peut quasiment avoir autant d’équipes de développement que de microservices ! A nous la scalabilité organisationnelle !
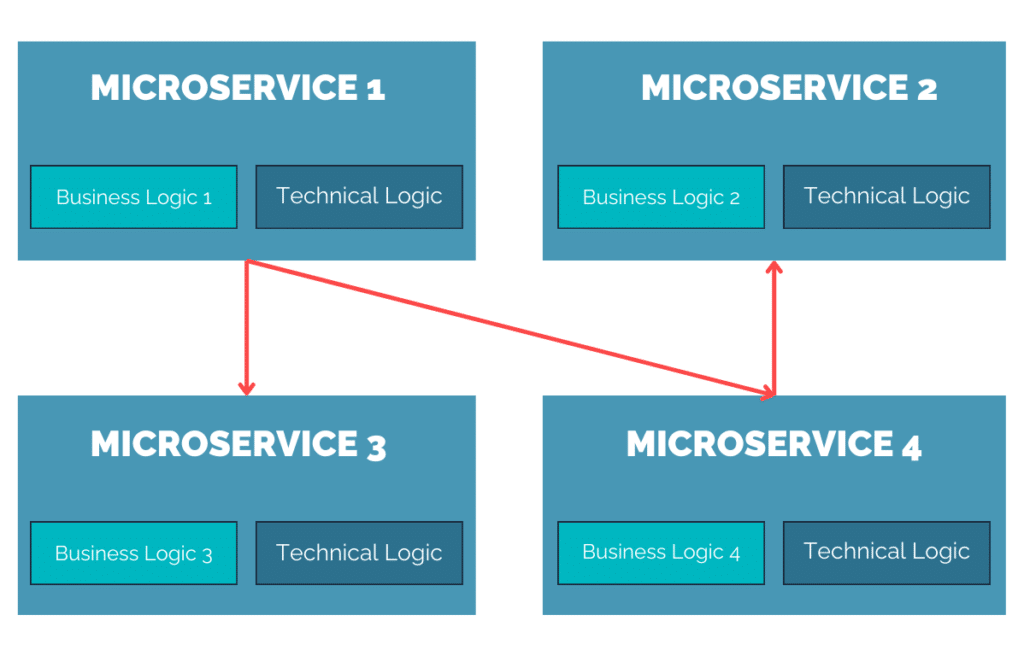
Cela a abouti, de manière simplifiée bien sûr, au schéma suivant :
Chaque microservice discute avec le micro service de son choix, indépendamment de toute considération. La liberté en somme ! Mais en y regardant de plus près, on voit bien une sous-brique qui est TRÈS commune à tous les microservices, ce que j’appelle ici la “Technical Logic”. Cette partie commune s’occupe des points suivants :
La découverte de services
La gestion du trafic
La gestion de tolérance aux pannes
La sécurité
Or quel intérêt à “exploser” cette partie en autant de microservices développés? Ne serait-ce pas plutôt une horreur à gérer en cas de mise à jour de cette partie? Et nous, les microserviciens (désolé pour le néologisme…), ne serions nous pas contradictoire dans nos souhaits de décentralisation? Oui! Car autant avoir une/des équipes dédiées à cette partie, qui travaillerait un peu de manière décentralisée, mais tout en centralisant sur elle-même ce point?
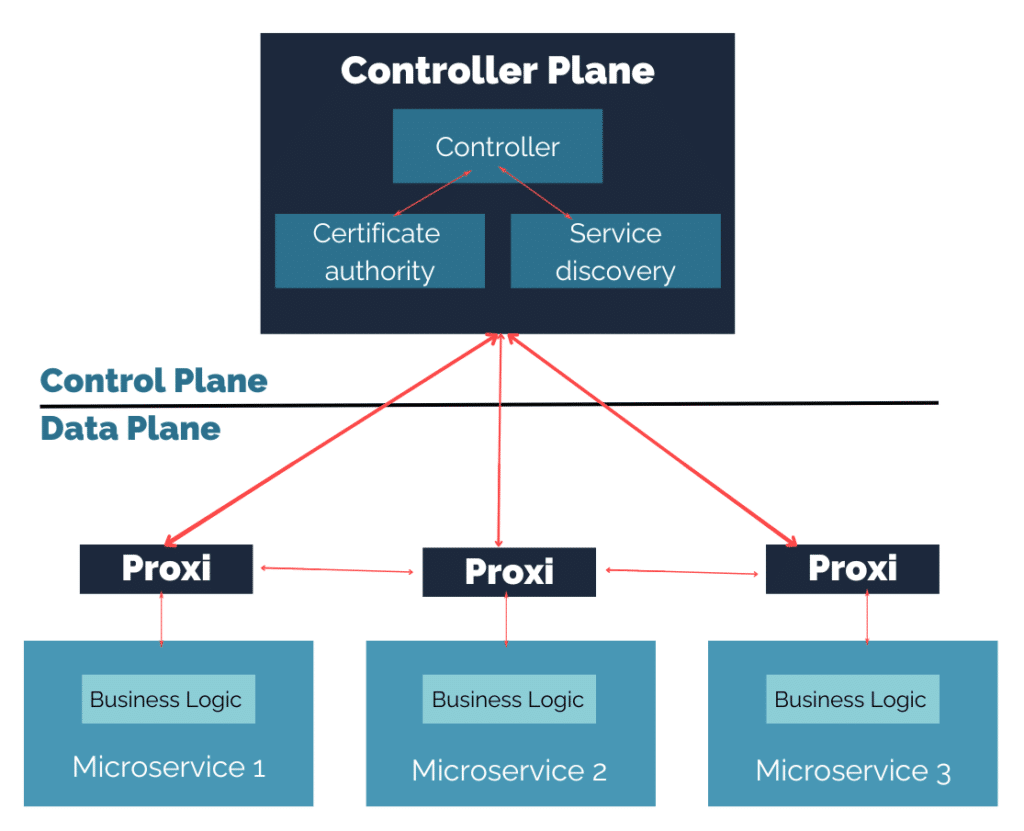
C’est ainsi qu’est apparu le pattern de Service Mesh, décrit dans le schéma suivant :
Dans ce pattern, les fonctions techniques sont définies de manière centralisée (Control Plane), mais déployées de manière décentralisée (Data Plane) afin de toujours plus découpler au final son architecture. Et cela se matérialise par des plateformes comme Consul ou Istio, mais aussi tout un tas d’autres plus ou moins compatibles avec votre clouder, voire propres à votre clouder.
Maintenant que nous avons apporté un premier niveau de définition pour le service mesh, allons donc voir du côté de l’Event Mesh !
L’Event Mesh, ou la re-centralisation pour désiloter
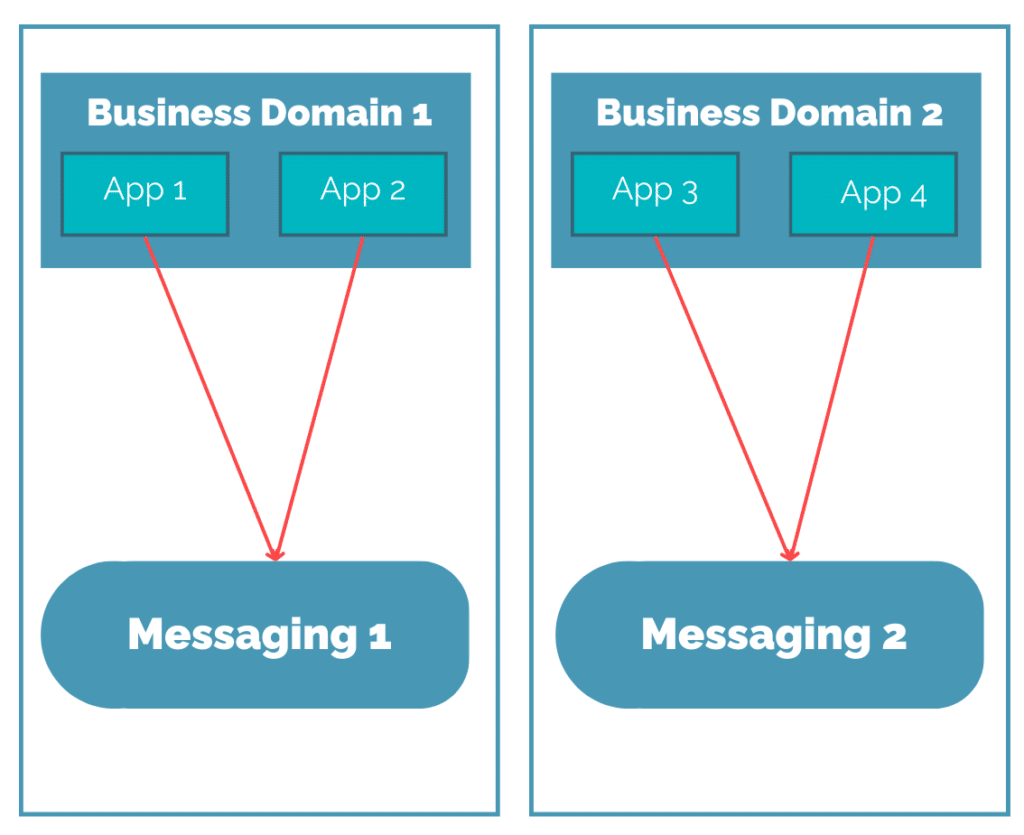
L’histoire informatique a eu l’occasion de voir tout un ensemble de solutions de messaging différentes, avec des origines différentes. Qu’on retourne à l’époque des mainframes, ou qu’on regarde de côté des technologies comme Kafka qui ont “nourri” les plateformes Big Data, les solutions se sont multipliées. Et c’est sans compter le fait de faire du messaging par dessus du http!
On obtient donc assez facilement des silos applicatifs qui sont freinés dans leur capacité à échanger, comme montré sur le schéma suivant :
Certes, les solutions de bridge existaient, mais elles permettaient souvent de faire le pont entre seulement deux technologies en même temps, le tout avec des difficultés à la configuration et l’exploitation.
Et si on rajoute le fait qu’un certain nombre d’entreprises se sont dit qu’il serait intéressant d’utiliser les technologies propriétaires de chacun de leurs clouders, on imagine bien les difficultés auxquelles elles font face.
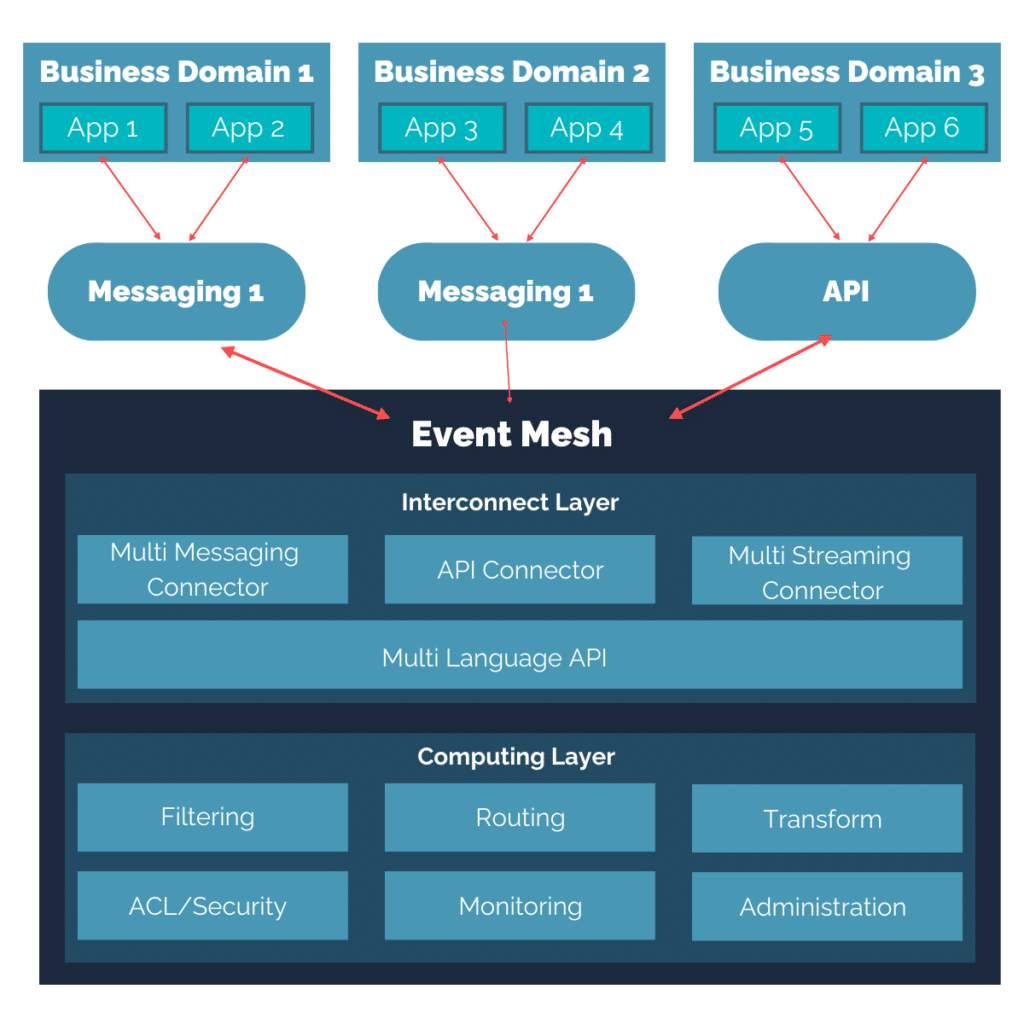
Est donc apparu le pattern Event Mesh, imaginé entre autre, implémenté et popularisé par l’éditeur Solace, qui permet de centraliser sur une solution unique, capable entre autres d’avoir des “agents” locaux aux SI (selon la zone réseau, le datacenter, le clouder, le domaine métier, etc…). Digression mise à part, on notera que le terme Event Mesh a été repris aussi bien par le Gartner que par des solutions open-source.
Indépendamment des architectures de déploiement, cela nous donne l’architecture simplifiée suivante :
Son intérêt vient qu’on peut ainsi relier tout le monde, y compris du Kafka avec du JMS, ou avec des API.
Le Data Mesh, décentralisation ou relocalisation des compétences ?
Le Data Mesh, de son côté, vient de son côté en réaction d’une précédente architecture très centralisée, faite de Data Lake, de Datawarehouse, de compétences BI, d’intégration via ETL ou messaging, le tout géré de manière très centralisée.
En effet, il était coutume de dire que c’est à une même équipe de gérer tous ces points, faisant d’eux des spécialistes de la data certes, mais surtout des grands généralistes de la connaissance de la data. Comment faire pour être un expert de la donnée client, de la donnée RH, de la donnée logistique, tout en étant un expert aussi en BI et en intégration de la donnée?
Ce paradigme d’une culture centralisatrice, a du coup amené un certain nombre de grosses équipes Data à splitter leur compétences, créant toujours plus de silos de compétences. De l’autre côté, les petites équipes pouvaient devenir très tributaires des connaissances des sachants métiers. Si cela vous rappelle les affres de la bureaucratie, ce serait évidemment pur hasard!
Ci-joint une représentation simplifiée de l’architecture dont nous avons pu hériter :
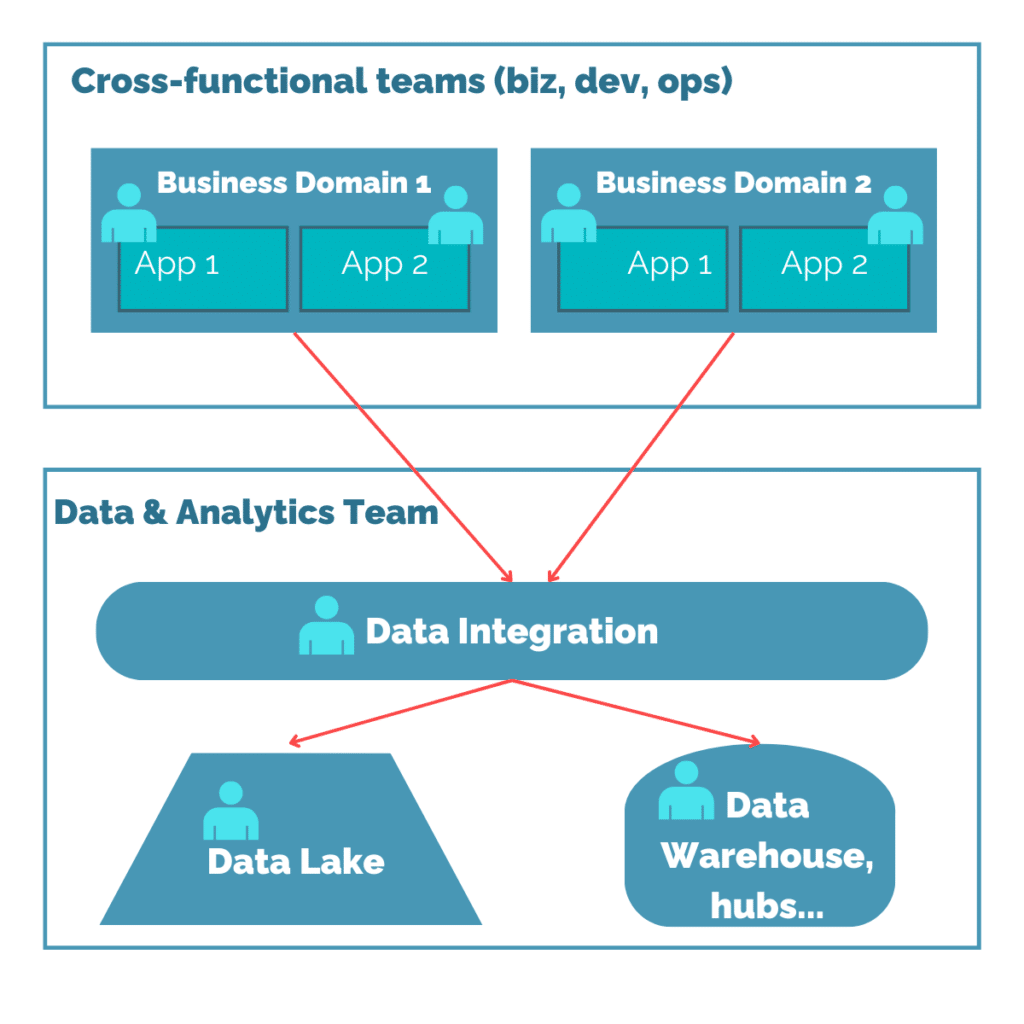
C’est ainsi qu’est apparu le pattern Data Mesh. Dans ce pattern, ce sont aux équipes Domaine de :
Collecter, stocker, qualifier et distribuer les données
Productifier la donnée pour qu’elle ait du sens à tous
Fédérer les données
Exposer des données de manière normée
Ce qui impose en l’occurrence de :
Mettre en place un self-service de données
Participer activement à la gouvernance globale
Et d’avoir un nouveau rôle de Data Engineer, qui doit mettre en place la plateforme de données pour justement faciliter techniquement, et proposer des outils.
Nous avons donc en schéma d’architecture le suivant :
Mais alors quid des points communs ?
Et en réalité, le gros point commun de ces trois patterns, c’est leur histoire !
Les trois proviennent de cette même logique centralisatrice, et les trois cherchent à éviter les affres d’une décentralisation dogmatique. A quoi cela sert de décentraliser ce que tout le monde doit faire, qui est compliqué, et qui en vrai n’intéresse pas tout le monde?
Et à quoi cela sert de forcément tout vouloir centraliser, alors même que les compétences/appétences/expertises/spécialisations sont elles-même “explosées” en plusieurs personnes ?
Certes, la centralisation peut avoir comme intérêt de mettre tout le monde autour de la même table, ce qui peut être intéressant pour de gros projets qui ne vivront pas, ou quand on est dans des phases d’une maturité exploratoire…
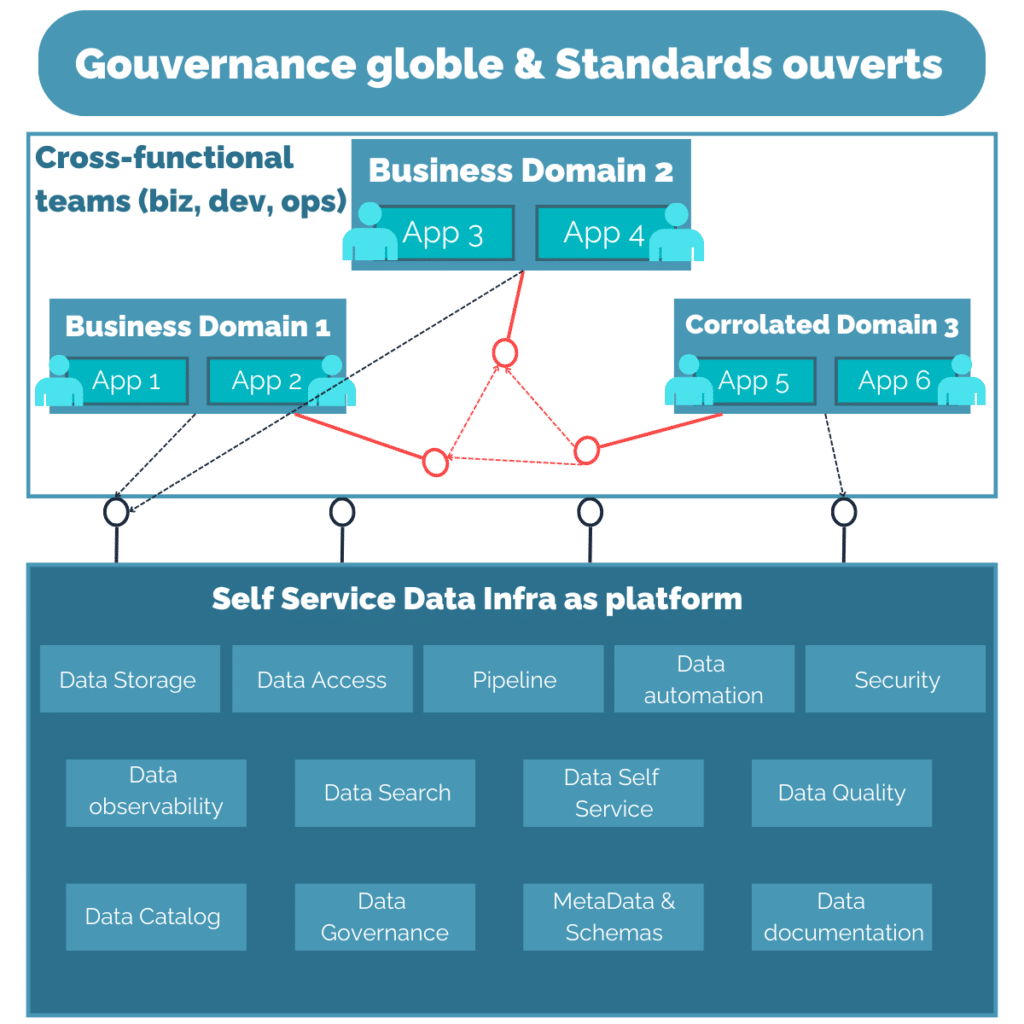
Et cela pousse tout un ensemble de principes, dont entre autre (liste non exhaustive):
Découvrabilité : Il faut pouvoir retrouver les services et les données simplement, en les exposants via des « registry » dédiés simples d’accès
Flexibilité et évolutivité : Il faut qu’une modification dans l’infrastructure ou dans un domaine puisse être accueilli sans douleur
Sécurité : Les politiques de sécurité sont propres aux champs d’actions de ces patterns, et sont donc inclus dans ces patterns
Distribution et autonomie : On distribue les responsabilités, les droits et les devoirs, afin de construire un système robuste organisationnellement
Alors oui, je vous entend marmonner “Et oui, c’est toujours la même chose! C’est comme ça”.
Mais en fait pas forcément ! En ayant en tête :
Ces éternels mouvements de yoyo,
Le Domain Driven Design qui est aussi un point commun au Data Mesh et à l’Event Mesh,
Cet article est le troisième d’une série présentant les évolutions des rôles des différents architectes dans la nouvelle version 6 du framework SAFe.
Après avoir étudié le System Architect et le Solution Architect, rencontrons l’Enterprise Architect ! Avant de rentrer dans le vif du sujet, nous souhaitions vous faire part de nos impressions quant aux évolutions du rôle de l’Enterprise Architect.
Dans les versions précédentes, le rôle de l’architecte d’entreprise n’était pas très détaillé. Il était clair que celui-ci intervenait dans la définition de la stratégie et aidait à mettre en adéquation les évolutions du système d’information avec celles du métier de l’entreprise, mais cela s’arrêtait là.
Dans cette nouvelle version, le framework contient beaucoup plus de détails sur les responsabilités de l’architecte d’entreprise. Celui-ci gagne ses lettres de noblesse et récupère dans sa bannette des sujets qu’il aurait toujours dû avoir (par exemple la rationalisation du portefeuille technologique). Son rôle n’est plus dans la pure stratégie décorrélée du terrain, il devient plus concret.
En revanche, il a aussi tout un lot d’activités nouvelles, que nous détaillerons dans la suite, et qui nous font dire qu’il faut avoir les épaules très larges pour occuper ce poste. L’architecte d’entreprise semble être partout à la fois, il est devenu une sorte de couteau-suisse ou d’architecte tout terrain si vous me passez l’expression.
Serait-il devenu l’architecte de l’entreprise ? Celui qui cumule bon nombre de responsabilités et qui collabore très largement avec l’ensemble de l’entreprise ? C’est ce que nous allons découvrir dans la suite !
De nouvelles responsabilités : De la définition de la stratégie, aux mains dans le code.
L’entreprise Architect s’est ainsi beaucoup musclé au passage de la version 5 vers la version 6 du framework Safe. Il est certes toujours responsable, au mot près, de la stratégie. Mais d’un rôle de facilitateur semi-passif (« Collaborating », « Assisting », « Helping », « Participating », etc…), il bascule vers un rôle de prescripteur. Un regard critique dirait qu’il retrouve ses prérogatives naturelles… Ainsi les différents (et nouveaux) rôles définis par le framework Safe sont :
Aligning Business and Technical Strategies
Coeur de métier de l’entreprise architect, son rôle est avant tout d’aligner l’architecture avec la stratégie IT, le tout en partageant ainsi sa vision et la stratégie business. Il identifie également les value streams à mettre en place, entretient ses relations avec les différentes équipes et va même jusqu’à participer aux démos.
Establish the Portfolio’s Intentional Architecture
Il s’agit là de définir une architecture cible avec des technologies cibles, des patterns d’architecture, le tout en synchronisant toutes les équipes ensemble. Fait marquant, l’apparition de la démarche inverse de Conway, consistant à définir une architecture, puis à calquer l’organisation sur cette architecture. Le contraire de ce qui est fait en général somme toute. L’architecte d’entreprise devient donc le responsable de la définition de l’organisation des équipes, ce qui en soit est un gros shift!
Rationalizing the Technology Portfolio
Le grand classique de l’architecture d’entreprise. On mutualise, on réduit les coûts, on réduit la complexité, etc…
Fostering Innovative Ideas and Technologies
Le titre est presque trompeur. Il s’agit surtout de permettre d’avoir un environnement technologique moderne et “propre”, en supprimant les technologies obsolètes, apporter du support aux environnements de développements, mais aussi en alignant les choix technologiques avec les business models pressentis.
Guiding Enabler Epics
Il est epic owner sur les initiatives d’architecture, et participe aux réunions safe pour s’assurer du bon alignement des équipes.
L’architecte d’entreprise reprend donc son rôle d’architecte d’entreprise, du métier aux développeurs, en passant par l’organisation des équipes. Par contre, son rôle est beaucoup plus étendu que dans la version 5, se retrouvant ainsi au milieu de nombreux acteurs.
Un accent mis sur la collaboration : D’une tour d’ivoire à un lean-agile leader
En effet, dans la version précédente de Safe, l’architecte d’entreprise était vu comme gravitant surtout dans les hautes sphères et ne collaborait qu’avec les autres architectes et des acteurs de haut niveau ou très transverses (Lean Portfolio Management, Agile Program Management Office, et le Lean-Agile Center of Excellence par exemple).
Il était supposé maintenir des relations avec les personnes de chaque Train mais ses activités quotidiennes ne s’y prêtaient guère. A présent que son périmètre s’étend considérablement, il sera amené à croiser des acteurs beaucoup plus nombreux. Il intervient comme proxy des acteurs business et doit être capable de porter la vision et la stratégie business auprès des différentes parties prenantes.
Il participe également à tous les événements en lien avec les enablers epics et aura donc l’occasion d’interagir avec les acteurs opérationnels des différents Trains.
Ses responsabilités étant également plus distinctes de celles des autres architectes, leur complémentarité est d’autant plus mise en évidence. Une collaboration efficace entre l’Entreprise Architect, le Solution Architect et le System Architect garantit l’alignement.
Enfin, l’Entreprise Architect doit incarner le Lead Agile Leader par excellence. Il mentore les équipes agiles, contribue à la mise en place de nouveaux modes de fonctionnement, et montre l’exemple en continuant à apprendre et à évoluer. Une forme de super héros inspirant tout le monde sur son passage, facile non ?
Si ces sujets vous intéressent…
Pour plus d’informations sur ces sujets et sur le rôle d’architecte dans un environnement agile, n’hésitez pas à aller voir notre série d’articles sur l’architecture et l’agilité.
Les articles 4 et 6 peuvent en particulier se révéler utiles :
Dans l’article 6, intitulé “Les 7 formations de l’Architecte Agile”, nous avions évoqué le besoin de formation SAFE pour l’architecte, et nous avions également parlé de la posture de coach de l’architecte via la process communication et la PNL.
Parmi la littérature conseillée par le framework Safe, on ne peut que vous conseiller le fameux livre “Team Topologies” qui évoque le rapprochement des équipes technologies et business :
“Application Integration” est un ajout récent au catalogue de services de la plateforme Cloud Google (GCP). Il s’agit d’une solution d’iPaaS (Integration Platform as a Service), composée par Google sur la base de ses Services Managés pour offrir des fonctionnalités que nous retrouvons traditionnellement dans les solutions d’intégration pure players (#Boomi #MulesoftAnypoint #Snaplogic, …) (bibliothèque de connecteurs techniques/applicatifs, environnement de développement, mappings, …).
Quelles sont les caractéristiques du service “Application Integration” ?
Sous quelle forme se présente le service et comment s’intègre-t-il avec les autres technologies de la plateforme GCP ?
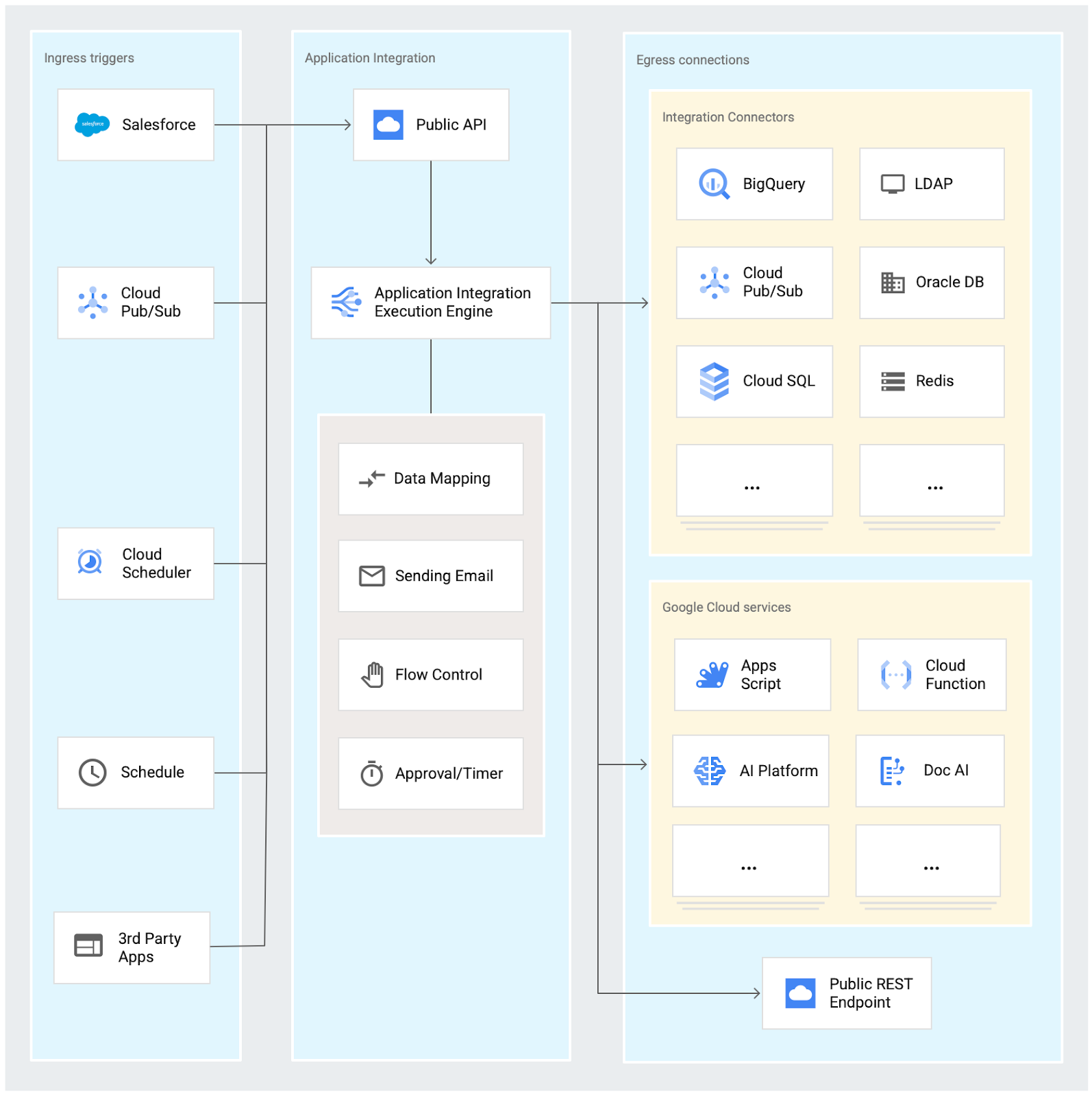
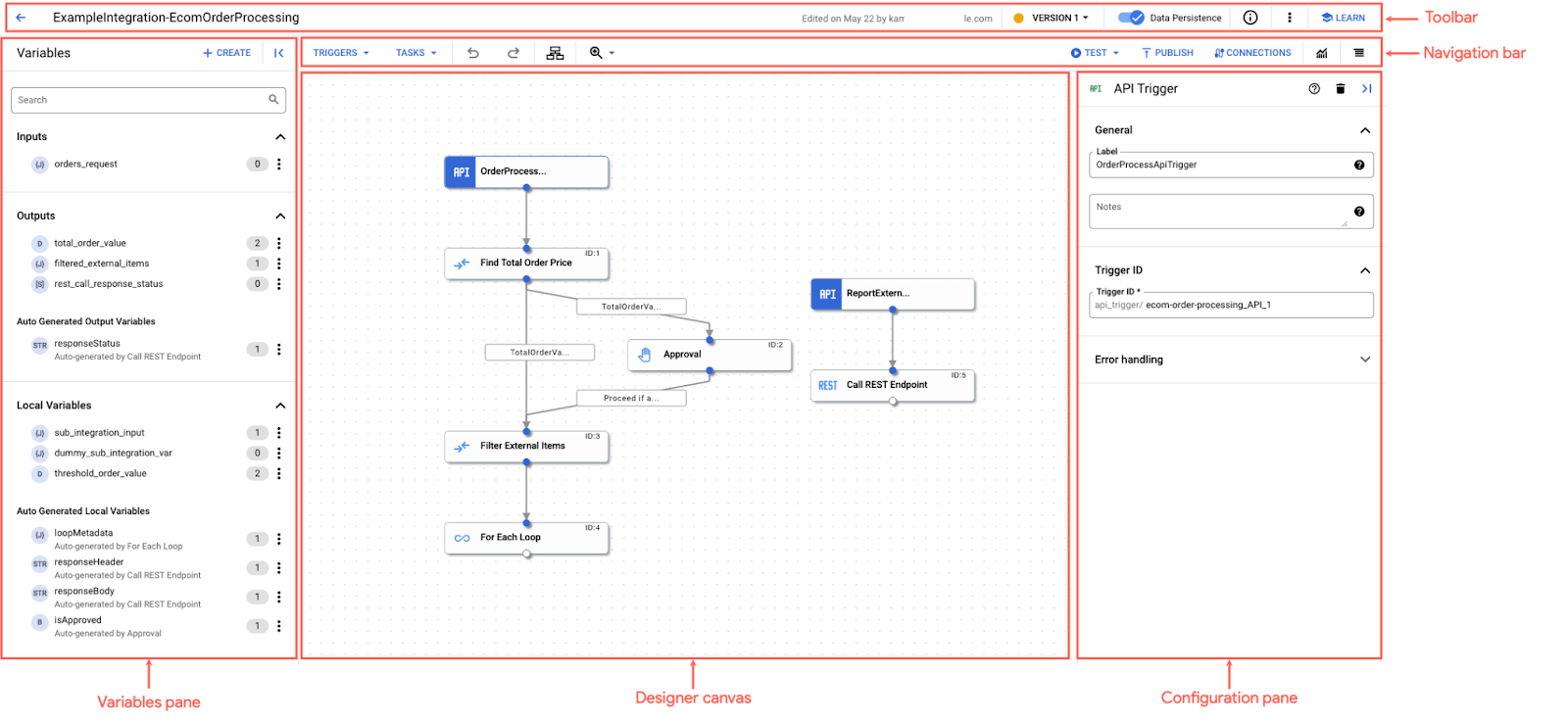
Interface de la plateforme et modèle de déploiement
La plateforme permet de concevoir graphiquement les flux d’intégration entre applications à l’aide :
des déclencheurs d’un traitement à effectuer (« triggers »),
des opérations de mapping et traitements techniques (« tasks »),
des conditions d’exécution de ces opérations et les contrôles d’embranchements conditionnels (« forks » et « joins »).
“Application Integration” est un service full managé de Google Cloud Platform. Pour l’heure un déploiement en mode hybride ou On-Prem n’est pas possible.
Modèle de facturation par typologies de connecteurs
Le service comprend une bibliothèque de connecteurs technologiques / applicatifs permettant de s’interfacer avec différentes applications, composants de l’écosystème Google ou tiers (progiciels du marché, bases de données open source, systèmes de messaging…).
Ces « Integration Connectors » fonctionnent sur un modèle de paiement à l’usage, selon différentes modalités. Ainsi la facturation s’effectue en fonction des éléments suivants :
Le nombre de nœuds de connexion utilisés
Un connecteur provisionne un nœud à la création d’une connexion, ce dernier va traiter les transactions. Un accroissement du nombre de transactions entraînera ainsi une augmentation du nombre de nœuds provisionnés. Ceci en fonction du nombre de transactions traitées par seconde et de la bande passante réseau utilisée par la connexion
Le nombre de nœuds actifs mesuré par minute sera facturé, et un nœud est facturé pour au moins une minute.
La facturation liée à la provision de nœuds diffère selon 2 catégories de connecteurs :
Les connecteurs pour des services Google (BigQuery, Pub/Sub et Spanner…)
Les deux premiers nœuds de connexion provisionnés sont gratuits.
Chaque nœud suivant est facturé 0,35 $ par heure.
Les connecteurs pour l’interfaçage avec des applications tierces (ServiceNow, Salesforce…)
Chaque nœud est facturé 0,70 $ par heure.
Les quantités de données traitées par les connexions
Les quantité de données mesurées incluent les requêtes et les réponses
L’utilisation gratuite inclut 20 Go de données traités par les connexions par mois
Chaque Go supplémentaire est facturé à 10 $ par Go
La version de connecteur actuellement proposée
Les connecteurs en « Preview », ne comportant pas toutes les fonctionnalités prévues, n’étant pas rattachées à un assistance et un contrat de service, ne sont pas facturés
Les connecteurs en « disponibilité générale », couverts par un contrat de service et incluant une assistance sont facturés à l’usage.
A titre d’exemple, on peut donc distinguer les connecteurs suivants :
AlloyDB, BigQuery ou encore Pub/Sub – pour des services Google et en disponibilité générale
Cloud Storage et Cloud Spanner – pour des services Google et actuellement en Preview
MongoDB, Snowflake, ServiceNow, etc. – pour des applications autres et en disponibilité générale
Zendesk, Splunk ou encore ElasticSearch, etc. – pour des applications autres et en Preview
Intégration avec des outils/environnements de développement tiers
Comme évoqué précédemment, la plateforme fournit une interface graphique pour construire des flux d’intégration en Drag & Drop, mais il est également possible d’intégrer des traitements spécifiques supplémentaires.
Google Cloud Functions est un service de la plateforme GCP permettant de créer des fonctions déclenchées sur évènement.
La « Cloud Function Task » permet d’interagir avec des Cloud Functions crées sur GCP (seul l’environnement d’exécution Python est supporté par le service Application Integration pour l’implémentation des fonctions).
L’exécution de la Cloud Function sera intégrée à la séquence d’exécution du flux d’intégration sur Application Integration.
Automatisation de parties de workflow de développement de flux
Duet AI est un service Google proposant un assistant virtuel, intégré à l’interface d’”Application Integration”. L’assistant est ainsi intégré dans le workflow de développement du flux d’intégration, suggérant un mapping à l’aide d’inputs en langage naturel, sur l’intégration à implémenter :
Inputs : traitements à réaliser, applications source et cible, event qui déclenche une opération, etc.
Outputs :
Production d’un mapping par défaut,
Production de document de spécifications et de cas de test fonctionnels.
En point notable, nous remarquons qu’”Application Integration” est avant toute chose une solution full GCP. Pas d’hybridation, cette modalité d’instanciation à date n’est dévolue qu’à APIGEE dans le catalogue de GCP sur les briques d’intégration.
La solution Apigee est-elle pour autant le point d’entrée unique d’une architecture hybride ? C’est en tout cas l’impression que cela nous donne à date.
Néanmoins, nous saluons l’effort de Google d’aller sur le marché de l’iPaaS, sans offre équivalente sur le marché des clouders Azure / AWS. Ces derniers proposent à ce stade, à couverture fonctionnelle comparable en matière d’intégration, des services / modules distincts plutôt qu’un applicatif packagé (logic apps, lambda, step functions…).
“Application Integration” parviendra-t-il à détourner la clientèle des solutions iPaaS pure players ? Nul doute que les actuels clients GCP s’interrogeront.
La question peut paraître saugrenue, car nous sommes habitués à dire que ce sont les chinois qui nous copient, et qu’en termes de libertés individuelles la Chine n’est pas nécessairement un modèle souhaité en France. Néanmoins, la Chine pense sur le temps long, avec une accumulation de plans quinquennaux qui au final peuvent s’étaler sur plus de 10 ans. Et le sujet de leur souveraineté numérique au sens large en fait clairement partie.
Pour revenir au sujet du cloud souverain, il est clairement d’actualité, avec l’amendement du député Philippe Latombe qui a été accepté, obligeant les opérateurs d’importance vitale pour la France à utiliser du cloud souverain plutôt que non souverain.
Mais avant de se comparer à la Chine, revenons aux basiques en retournant à l’étymologie du mot « souveraineté ».
Source : Pexels – Kevin Paster
La souveraineté, une proposition de définition.
Étymologiquement, et dans son sens premier, est souverain celui qui est au-dessus, qui est d’une autorité suprême.
Cela s’applique ainsi logiquement à un État, qui lui-même est chargé de défendre les intérêts français, que l’on parle de citoyens mais aussi d’entreprises. Citoyens, qui expriment leur souveraineté populaire (au sens rousseauiste du terme) dans le cadre d’élections.
Mais appliquons cela à ce qu’on entend alors par “cloud souverain”.
Ainsi, en déclinant cette idée de souveraineté au cloud, dont les clients potentiels sont l’état, les entreprises, les individus, il s’agit de placer l’état en garant des intérêts des citoyens et des entreprises, qui se mettent sous la coupe des lois françaises, lois assumés par tous par le mécanisme de souveraineté populaire.
Source : Pixabay – The DigitalArtist
Le cloud souverain, une proposition de liste de principes.
Dis comme ça, cela reste flou. Alors soyons plus pratico-pratiques :
Ni l’état, ni les entreprises, ni les citoyens ne souhaitent se faire espionner par une force étrangère, ou par des intérêts privés. Bonjour Edward Snowden.
Tout le monde souhaite que ses données privées, le restent. Bonjour les GAFAM. Bonjour Edward Snowden.
L’état, les citoyens, les entreprises souhaitent que les comportements délictueux exercés en France soient jugés en France. Bonjour les GAFAM. Bonjour Edward Snowden. Bonjour l’état de droit.
L’état, les citoyens, les entreprises souhaitent pouvoir avoir un accès sans soucis à un cloud sécurisé. Bonjour la liberté.
Une réalité éloignée de ces principes
Or, un certain nombre de points ne correspondent pas avec les acteurs étrangers.
Espionnage : Le Patriot act et le FISA, sont très clairs à ce sujet. Si votre clouder est américain, le piratage est légal et assumé. J’omets le Cloud Act, qui à mes yeux relève du « blanchiment » juridique.
Confidentialité : De même, les données considérées comme “privées” peuvent ainsi être récupérées. Sans compter les cookies traceurs et https://www.lebigdata.fr/donnees-anonymes-cnil-data-brokers). Et si vous ajoutez le fait que les protocoles “Internet” qui n’ont pas été créés comme sécurisés. Des palliatifs existent comme par exemple pour le protocole DNS (Protocoles DOH et DOT, DnsCrypt). Néanmoins, l’utilisation de HTTPS ne vous cache pas. Si vous allez sur https://siteinavouable.com, l’information que vous vous y connecter passe en clair, lors du handshake SSL. Il faudrait pour éviter cela que l’extension TLS d’”Encrypted Client Hello” soit généralisée.
Souveraineté aux yeux de la loi : L’extra territorialité des lois américaines n’est plus à prouver. Demandez à Frédéric Pierucci son avis.
Sécurisation : Et si nous passons tous par des routeurs fabriqués par des entreprises américaines, avec des ordinateurs utilisant des processeurs américains, avec un bios contenant des binaires américains pour les craintes, et pour un premier aperçu des possibilités, et le tout sur un système d’exploitation américain, la probabilité que des failles et autres backdoors “connues” seulement des américains existent n’est pas nulle. Et passons sur le simple fait que le trafic internet de votre tante vivant à Nice, se connectant à un site web hébergé à Strasbourg, ne va pas nécessairement longer les frontières françaises tel le nuage de Tchernobyl, laissant ainsi des « portes » d’écoute.
Alors quelle est la réponse de la Chine face à ces enjeux?
Espionnage : Mise en place d’un Great Firewall, perfectible par rapport à ses objectifs mais qui ne facilite pas le travail d’un espion étranger. Ecosystème “Chinese Only”, où aucune société américaine n’opère directement en chine (Voir Salesforce, Azure, Aws), mais par des intermédiaires 100% chinois.
Confidentialité : Pas le soucis majeur des chinois. Vous n’avez rien à cacher à l’état chinois, pas même vos secrets intimes.
Souveraineté aux yeux de la loi : Le fait de devoir passer par un intermédiaire chinois bloque les lois extra-territoriales américaines. Par exemple la société chinoise 21Vianet achète les “logiciels Azure” de Microsoft, pour après revendre de l’Azure en chine. Et comme dans la pratique l’état chinois a accès à tous les serveurs, c’est tout de suite plus pratique pour faire appliquerdes lois, et un “REX” extra-territorial sur TikTok : REX que votre serviteur avait précédemment pressenti.
Sécurisation : Le great firewall aide, transforme l’Internet Chinois en un quasi Intranet, mais n’est pas le seul vecteur de sécurisation. Comme énuméré précédemment, les vecteurs d’attaques sont :
Système d’exploitation : Diverses distributions linux chinoises, existence d’un linux fait par alibaba cloud
Serveur : Lenovo qu’on ne présente plus. De toute manière les fabricants étrangers ne sont pas les bienvenus.
Une utopie réaliste
Par rapport à cette liste à la Prévert, je n’invite pas à restreindre les libertés publiques mais à avoir une politique numérique très ambitieuse. Impossible n’est pas français comme je l’entendais dire dans ma jeunesse, et oui, un autre modèle est imaginable :
Espionnage : Renforcement très fort de l’ANSSI, pour aider encore plus les entreprises à se sécuriser, mais aussi pour sensibiliser. Promotion voir obligation d’utilisation de protocoles et de systèmes sécurisés, Travaux de recherche pour une sécurisation pour tous. Sécurisation des réseaux, y compris télécom afin d’éviter d’être géo-localisable par n’importe quelle agence étatique
Confidentialité : Interdiction des cookies traceurs. Généralisation des protocoles sécurisés. Amendes plus fortes et prisons en cas de négligence de confidentialité, voir de sécurité
Souveraineté aux yeux de la loi : Promotion du SecNumCloud et challenge perpétuelle de sa définition (ce qui est déjà le cas au vu des versions). Aides aux entreprises souhaitant passer la certification. Obligation pour l’état et les organismes d’importance vitales de passer par des clouders de droit et d’actionnariat français (bonjour les OIV)
Sécurisation :
Réseau : Promotion des acteurs français comme Stormshield, certifications de sécurité pour les acteurs qui communiquent leurs codes sources qui seront audités
Processeurs :
Fabrication dans un premier temps de processeurs sous license ARM (contenant quand même des brevets américains https://www.phonandroid.com/huawei-annonce-son-independance-aux-technologies-americaines-pour-2021.html) par une entreprise de droit français ou européen (ST MicroElectronics)
Travaux de recherche sur les plateformes Open Source RISC-V et Open Power et fonds d’investissement pour des startups
Système d’exploitation : Promotion et investissement sur la distribution linux française CLIP-OS, développé par l’ANSSI
Serveur : En soit un serveur consiste en une simple intégration de composants, qu’OVH fait lui même. Concernant le bios, avec un processeur français le problème sera directement résolu. Enfin concevoir des cartes mères n’est pas la chose la plus complexe (Si un ingénieur est capable d’en concevoir en solo…
Plus qu’un cloud souverain, un Internet de la confiance
Comme on peut le voir, je prends le contre pied de la Chine sur la vie privée et la confidentialité, et je cherche à démontrer que l’effort technologique n’est pas un mur infranchissable.
L’effort pour les DSI, RSSI, architectes, consiste à sensibiliser, mais aussi à promouvoir l’usage de solutions et de clouders certifiés secNumCloud, qui soient bien de droit français. La liste est régulièrement mise à jour.
Et oui, il faut « franciser » son SI. Et/où l' »open-sourcer ».
Sur le sujet de la sécurisation pour tous, être contre c’est être pour que n’importe qui dans la vie réelle puisse écouter ce que vous dites. On me rétorquera que la collecte d’adresse IP est nécessaire pour la lutte contre le harcèlement en ligne par exemple… Alors renforçons les pouvoirs et les moyens de la CNIL. Exigeons de nouvelles certifications plus sévères et plus contraignantes. Ce sujet de collecte d’ip pour des crimes graves (https://twitter.com/laquadrature/status/1658012087447085056) peut être la limite acceptable et contrôlable de notre vie privée et de notre sécurité. Car être contre notre sécurité et notre vie privée c’est être contre la protection de nos intérêts vitaux et économiques (https://twitter.com/amnestyfrance/status/1658449051296186369). La liberté individuelle et la liberté d’entreprendre sont ici parfaitement compatibles, elles vont même de pair. Croire l’inverse, c’est laisser la porte ouverte à tous vents, aux inconnus, aux belligérants. Et nous devons tous comprendre qu’il en va de l’intérêt général.
Qu’en est-il aujourd’hui, le GraphQL est-il réellement une alternative concrète aux APIs standard ?
Mais déjà, qu’est-ce que le GraphQL ?
Le GraphQL se définit par la mise à disposition d’une interface de “requêtage” qui s’appuie sur les mêmes technologies d’intégration / les mêmes protocoles utilisée par les API REST.
Ici, nous restons sur le protocole HTTP et par un payload de retour (préférablement au format JSON) mais la différence principale du GraphQL, pour le client, repose sur le contrat d’interface.
Le contrat d’interface façon GraphQL devient variable, tout comme la réponse. En effet, dans la requête nous pouvons spécifier ce que nous souhaitons recevoir exactement dans la réponse.
Nous mettons ainsi le doigt sur un gros avantage de cette interface GraphQL qui, par essence, va grandement diminuer le “overfetching et le “underfetching” (comprendre ici le fait de récupérer trop peu ou au contraire trop d’informations jugées inutiles dans le contexte) d’API
Autre avantage, ce besoin en données spécifiques pourra être différent à chaque appel et donc permettre une grande flexibilité d’usages à moindre effort.
Le GraphQL s’est fait sa place !
A l’époque de l’écriture de notre premier article, le GraphQL commençait à s’introduire dans certains cas d’usage, très souvent en mode POC et découverte, avec un concept attrayant mais sans preuve réelle de plus value.
Aujourd’hui nous observons une vraie adhésion à ce nouveau mode d’interfaçage, bien que nous en constatons encore des points d’amélioration.
Ce qui est intéressant à remarquer est qu’il se développe sur des métiers très variés. Non seulement au niveau des éditeurs de logiciels mais également dans le cadre de développements spécifiques, de plateformes dédiées.
Les usages à date : quelques exemples
Netflix, qui utilise le GraphQL pour unifier les accès aux différentes APIs.
Dans le retail, Zalando, pour récupérer les informations sur les différents produits et pour gérer les consentements.
MonEspaceSanté, le service lancé par l’ANS en début d’année, et qui effectue de requêtes GraphQL à partir du navigateur.
Le GraphQL comme réponse à un besoin d’uniformisation ?
Avant la naissance du GraphQL, le besoin d’uniformisation de ce type d’interaction était dans la ligne de mire de certains acteurs. Aujourd’hui le GraphQL peut apporter une réponse concrète et standardisée à ces problématiques.
Deux exemples d’envergure :
Microsoft : Microsoft a par le passé essayé de fournir des APIs “flexibles” pour adresser certains cas d’usage. Cette tentative s’est matérialisée par la création de l’OData et de l’API Microsoft Graph.
Ne vous trompez pas, l’objectif reste similaire mais l’approche est, à ce stade, différente. Dans une logique d’uniformisation et standardisation, nous voyons difficilement Microsoft s’affranchir d’une réflexion autour du GraphQL pour atteindre ces objectifs.
Salesforce : Salesforce propose également depuis plusieurs années, une API bas niveau qui pourrait, par ses caractéristiques et son besoin de flexibilité, être adaptée à la technologie GraphQL.
Constat actuel sur les usages du GraphQL
Quand nous regardons les cas d’utilisation de GraphQL, nous pouvons constater qu’il est majoritairement utilisé côté Front-end.
En lien avec ce cas d’utilisation, nous observons également que le GraphQL est souvent vu comme un agrégateur d’API, et pas comme un moyen de requêtage directement lié à une vision pure données.
Mais pourquoi ce type d’usage ?
Nous listons trois arguments principaux pour expliquer la prédominance de ce type de cas d’usage.
La restitution de format est très adaptée au monde du web : une réponse simple, toujours vraie et personnalisable ; le protocole HTTP et des concepts proches des APIs REST, le GraphQL s’adapte très bien aux couches front.
Chaque API derrière GraphQL gère son propre périmètre, si nous faisons la correspondance avec les architectures DDD (Domain-Driven Design), nous pouvons affirmer que l’API bas niveau adresse un domaine particulier, alors que le GraphQL est là pour pouvoir “mixer” ces différents concepts et donner une vision un peu plus flexible et adaptée à chaque cas d’usage. Dans ce cas nous allons faire de l’overfetching sur les couches bas niveaux, et faire un focus utilisation au niveau de la partie frontale.
Le cache, éternelle question autour du GraphQL. Dans ce cas d’usage le cache reste possible au niveau des APIs de bas niveau, qui iront donc moins solliciter les bases de données, alors que sur la couche GraphQL, de par sa variabilité de réponse, nous en avons peut-être moins besoin. Pour rappel, le cache sur une requête GraphQL, bien que possible, devient naturellement plus complexe à gérer et donc perd un peu de son intérêt.
Pourquoi ne faut-il pas limiter le GraphQL à ces usages ?
Pour nous, c’est notre conviction, le GraphQL a de nombreux atouts et doit se développer sur ces usages de prédilection, mais pas que !
UN ARGUMENTAIRE FORT : L’ACCÉLÉRATION DE LA CONCEPTION !
Un des grands atouts de la mise en place d’une API GraphQL reste le côté, si vous m’autorisez le terme, “parfois pénible” de la définition des API Rest : des discussions infinies entre le métier et l’informatique pour définir ce dont nous avons besoin, le découpage, etc.
Une API GraphQL par définition n’a pas une structure ou un périmètre de données définis, mais s’adapte à son utilisateur.
Le GraphQL comme moyen d’accélérer les développements ?
Une évolution de l’API bas niveau n’est plus nécessaire pour satisfaire le front
Un accès unifié aux données par un seul endpoint, sans forcément aller chercher dans les différentes APIs / applications
Tout en exploitant la logique de cache car le front end ne change pas
Et en plus des évolutions dans la gestion des caches permettent aujourd’hui de mettre en cache les données GraphQL
UNE DISTINCTION CLAIRE : ATTENTION AUX CAS D’USAGE !
Nous ne visons certainement pas tous les cas d’usages, mais l’objectif ici est de casser un peu certains mythes.
Si utiliser des mutations (en gros l’équivalent de l’écriture) intriquées, nous l’avouons, peut être très complexe, dans les cas de requêtage de bases de données ayant comme objectif principal l’exposition en consultation, nous disons “pourquoi pas !”.
Vous auriez probablement reconnu le pattern CQRS, avec, par exemple, une Vision 360 Client qui expose les informations avec une API GraphQL.
CÔTÉ TECHNIQUE
Les améliorations dans la gestion des caches, ces dernières années, permettent de gérer ce sujet, tout en restant plus complexe qu’avec une API REST standard.
Attention aux autorisations
Nous n’allons pas nous attarder sur ce sujet, que nous avons déjà traité dans notre précédent article (que nous vous invitons à parcourir ici), mais nous souhaitons le rappeler car il est crucial et extrêmement critique.
Si nous souhaitons traiter les sujets d’accès à la donnée avec une API GraphQL, une logique RBAC avec rôles et droits définis au niveau de la donnée (matrice d’habilitations rôles / droits proche de la donnée elle même) nous semble à ce stade la meilleure solution : N’AUTORISONS PAS L’ACCÈS UNIQUEMENT AU NIVEAU DE L’API, MAIS ALLONS AU NIVEAU DATA !
Conclusion
La technologie continue de s’affirmer, un standard semble se définir et s’étoffe de plus en plus. Dans un monde API qui se complexifie de jour en jour, les enjeux autour de la rationalisation et de l’optimisation des usages API restent au cœur des débats sans pour autant trouver de solution directe et efficace via la technologie REST. Et c’est encore plus vrai quand le besoin de base n’est pas clairement défini…
Le dynamisme apporté par le GraphQL, dans certains cas de figure, permet de simplifier ces discussions en apportant des réponses cohérentes avec le besoin.
Ce n’est pas une solution magique faite pour tous les usages, mais une réelle alternative à considérer dans les conceptions API.
Et vous ? Avez-vous pris en considération cette alternative pour vos réflexions API ?
Ne vous en faites pas, il n’est pas trop tard, parlons-en, ce qui ressortira de nos discussions pourrait vous surprendre.