DATA Lakehouse – Exploration d’une Architecture de plateforme de données innovante
DATA Lakehouse - Exploration d'une Architecture de plateforme de données innovante
22 octobre 2024
Architecture
Mohammed Bouchta
Consultant Senior Architecture
Après avoir introduit les concepts fondamentaux d’un lakehouse dans notre précédent article, plongeons maintenant dans les détails qui font du lakehouse une solution d’architecture alignée sur les principes d’une modern data plateform.
Nous allons explorer son fonctionnement interne et les technologies clés qui le soutiennent.
Source : Pexels – Tima Miroshnichenko
Fonctionnement d’un Lakehouse
L’architecture lakehouse représente une évolution significative dans le traitement et la gestion des données, cherchant à harmoniser les capacités de stockage d’un datalake avec les fonctionnalités analytiques et transactionnelles avancées d’un data warehouse. Cette convergence vise à créer une plateforme flexible, capable de gérer à la fois l’analyse de données historiques et les opérations transactionnelles, sans faire de compromis sur la performance, la sécurité, ou la qualité des données.
Rôle des métadonnées
Au cœur de cette innovation, l’usage stratégique des métadonnées joue un rôle prépondérant, orchestrant avec la gestion des schémas de données et leur évolution.
Les métadonnées, dans l’écosystème lakehouse, ne se limitent pas à la gouvernance et à la qualité des données, bien que ces aspects soient importants, notamment pour soutenir des transactions fiables. Elles permettent également d’indexer de manière efficiente les données susceptibles d’être requises, facilitant ainsi leur accès et leur analyse.
Cette architecture assure que, même au sein d’un stockage de données bruts et diversifiées, l’information pertinente peut être rapidement localisée et exploitée.
Système de stockage
Le lakehouse exploite les avantages économiques du stockage en DataLake, tel que le système de fichiers distribués HDFS ou les solutions de stockage objet dans le cloud, comme Amazon S3 et Azure Blob Storage. Ces plateformes de stockage, reconnues pour leur coût-efficacité, en grande partie grâce à la séparation du stockage et du calcul, sont complétées par une couche sémantique riche, pilotée par les métadonnées. Cette couche ne se contente pas de cataloguer les données; elle améliore aussi leur traitement et facilite leur accès, optimisant de ce fait l’efficacité générale de la plateforme.
Gestion transactionnelle des données
La fusion réussie de ces éléments au sein d’une architecture lakehouse repose sur l’intégration de principes transactionnels rigoureux, tels que l’atomicité, la cohérence, l’isolation, et la durabilité (ACID). Ces principes sont essentiels pour garantir la fiabilité et l’intégrité des données, permettant de s’appuyer sur le lakehouse pour des opérations critiques sans craindre de compromettre la qualité ou la sécurité des informations traitées.
Meilleure performance qu’un Datalake
Par ailleurs, pour ce qui est de l’amélioration des performances, le lakehouse intègre des mécanismes de mise en cache avancés. Ces systèmes sont conçus pour précharger en mémoire les données les plus sollicitées, accélérant ainsi significativement le temps d’accès et la réactivité de la plateforme.
Technologies Clés
La réalisation d’un lakehouse repose sur des technologies avancées qui permettent de surmonter les défis traditionnels posés par les datalakes et les data warehouses offrant une flexibilité, une fiabilité et des performances accrues pour la gestion et l’analyse des données à grande échelle.
Voici un aperçu de ces technologies clés :
Delta Lake
Delta Lake est une couche de stockage open source conçue pour apporter la gestion transactionnelle ACID aux datalakes. Cette technologie transforme un datalake en un système capable de gérer des opérations de lecture et d’écriture concurrentes, garantissant ainsi l’intégrité des données. Avec Delta Lake, les utilisateurs peuvent effectuer des mises à jour, des suppressions, des insertions, et même des merges (fusion de données) directement sur les données stockées dans un datalake, tout en maintenant un historique complet des modifications. Cela permet une gestion des données plus flexible et robuste, facilitant des cas d’utilisation comme le rollback pour corriger des erreurs ou auditer des modifications. De plus, Delta Lake optimise les requêtes en utilisant le « data skipping » (saut de données non pertinentes), améliorant ainsi la vitesse d’analyse des vastes ensembles de données.
Apache Hudi
Apache Hudi (Hadoop Upserts Deletes and Incrementals) est une autre technologie open source qui révolutionne la gestion des données dans les datalakes. Elle permet des mises à jour et des suppressions rapides, ainsi que des insertions et des requêtes incrémentielles sur de grands ensembles de données. Apache Hudi introduit le concept de « views » (vues) de données, permettant aux utilisateurs de voir des snapshots des données à un moment choisi ou des changements sur une période, rendant ainsi possible la gestion de versions et le time travel (navigation temporelle dans les données). Cette capacité à gérer des modifications de données de manière efficace rend Hudi particulièrement adapté aux environnements où les données changent fréquemment, supportant des cas d’utilisation tels que la capture de données modifiées (Change Data Capture, CDC) et les pipelines de données en temps réel.
Apache Iceberg
Apache Iceberg est un format de table open source qui vise à améliorer la gestion et les performances des requêtes dans les datalakes.
Iceberg traite de nombreux problèmes rencontrés avec les formats de fichiers traditionnels et les modèles de métadonnées dans les datalakes, tels que la complexité de gestion des schémas évoluant dans le temps ou les problèmes de performance des requêtes sur de grandes tables.
Avec Iceberg, les tables sont traitées comme des entités de première classe, supportant des fonctionnalités avancées telles que les schémas évolutifs, les partitions cachées, et les transactions atomiques.
Le format est conçu pour être agnostique au moteur de calcul, permettant ainsi son utilisation avec diverses plateformes d’analyse de données, telles que Spark, Trino et Flink.
Iceberg optimise également les performances des requêtes en utilisant un indexation fine des données, ce qui réduit le volume de données scannées lors des analyses.
Conclusion
En conclusion, le lakehouse émerge comme une solution hautement performante et flexible qui étend la portée et les capacités d’un datalake en combinant le stockage économique des datalakes avec les capacités d’analyse et de gestion transactionnelle des data warehouses, tout en exploitant intelligemment les métadonnées pour la gouvernance, l’indexation, et l’optimisation des accès sans pour autant éclipser le rôle stratégique que peut jouer un datahub dans l’écosystème global de gestion des données au sein du système d’information.
Datalake, Datawarehouse, Datalakehouse… Le métier de la donnée a le don pour créer des noms assez simples à associer au sujet, mais qui peuvent rapidement devenir confusants. Ce billet vise à vulgariser ces 3 concepts, afin de vous permettre de tenir le fil de la discussion lors de vos discussions avec les experts data.
Les patterns historiques
Le Datawarehouse (entrepôt de données) est un pattern de base de données décisionnelles, datant de la fin des années 80 : il agrège des données sélectionnées, mises en qualité, structurées, et historisées afin de permettre de les exploiter dans le cadre de cas d’usage « décisionnels ». Ces données ne sont pas altérables, ce qui garantit qu’un même traitement donnera le même résultat peu importe le nombre de fois et le moment où il sera réalisé. Ce cadre de stockage permet de faire croiser des données issues de systèmes applicatifs distincts, afin de « casser » les silos de données, et permettre une vision transversale de l’entreprise, tout en permettant de comparer différentes périodes. L’inconvénient du Datawarehouse est principalement son coût de stockage élevé, du fait de toutes les étapes de « travail » autour de la donnée.
Le Datalake (lac de données) s’est construit afin de répondre aux faiblesses du Datawarehouse : c’ est un espace de stockage, agrégeant des données (non structurées, semi structurées et structurées), sous leur forme brute (pas de traitement de normalisation / mise en qualité à l’ingestion). L’objectif de cette brique applicative est de proposer un stockage à bas coûts, permettant de mettre à disposition un vaste volume de données, de manière agnostique au regard de leur exploitation future. Ce volume de données permet de nourrir différents types de cas d’usage : alimentation de bases de données spécialisées (par exemple décisionnelles, comme un Datawarehouse), ou exploitation dans le cadre de traitements nécessitant un volume important de données mise à disposition (Data Science, Machine Learning, Intelligence Artificielle…). Il n’a cependant pas ambition à agréger toutes les données de l’entreprise, ou de les stocker n’importe comment, et c’est justement un problème qui a tendance à se développer avec le temps, en l’absence d’un cadre définissant la gouvernance des données, et la politique de rétention de ces dernières. Et là, le Datalake devient le Dataswamp…ce qui rend l’exploitation des données compliquée voir impossible, tout en faisant augmenter les coûts…
Le nouveau venu
Le Data Lakehouse (maison lac… ne cherchez pas de traduction littérale !) est une hybridation de ces 2 composants applicatifs, visant à proposer le meilleur des deux mondes, tout en couvrant l’ensemble des cas d’usages sus mentionnés. Comme le Datalake, il permet d’agréger différents types de données (structurées, semi structurées ou non structurées). Cependant, grâce à l’exploitation d’une couche de métadonnées permettant de faire le lien avec les différentes données agrégées, les transactions ACID (atomicité, cohérence, isolation et durabilité) deviennent possibles. De même, l’ingestion de données en temps réel (streaming) devient possible, ce qui permet de répondre à de nouveaux cas d’usage (pilotage à chaud, exploitation des données IoT). C’est un pattern permettant de conserver un stockage à moindre coût propre au Datalake, ainsi que la capacité d’analyse d’un Datawarehouse.
Dans un second article, nous allons faire un focus sur le Data Lakehouse, en soulevant le capot afin de mieux comprendre son fonctionnement.
Le NoCode Summit 2024 en a été la vitrine et s’est révélé fort intéressant par bien des aspects :
être dans l’ambiance, l’effervescence de cet écosystème qui innove très vite,
percevoir les solutions qui reviennent souvent dans les témoignages, identifier clairement les start-up, et les scale-up,
bénéficier de retours avisés de petits / grands comptes ayant d’ores et déjà adopté ces stacks en Production.
Si vous parlez de NoCode/LowCode…un vaccin des dernières tendances vous sera bénéfique.
NoCode, démarrant par une négation, n’est pas vendeur, braque les développeurs avec pour conséquence un frein à l’adoption de ces technologies…Alors même que le “NoCode” requiert des compétences fondamentales telles que la logique et l’algorithmie. Le “LowCode” quant à lui requiert parfois de coder concrètement pour couvrir le cas d’application souhaité.
Désormais, il conviendra de parler de :
Keyboard Programming – Développement traditionnel dans le langage qui vous plaira,
Visual Programming (ex NoCode / Low Code),
GenAI Programming.
Il s’agissait ici de la troisième édition du Summit, et une belle montée en maturité (Prod ready) des acteurs a été constatée, ne serait-ce que de part leur adoption par des Grands Comptes (ex : BRED, System U, BNPP, Docaposte, CDC, Europ Assistance, LCL, L’Oréal, BPI France) qui témoignent de retours d’expériences très positifs.
Vous constaterez sur les affichages de sponsoring du foisonnement de solutions. Nous assisterons avec quasi certitude à une consolidation de marché dans les années à venir car plusieurs solutions se concurrencent sur les mêmes positionnements, avec bien évidemment des particularités.
Voici un aperçu des différents positionnements constatés :
Solution de BDD avec UI/UX on top : AirTable, baserow
Solution de tests fonctionnels, techniques : MrSuricate
Solution pour développer des outils de productivité en interne (mini JIRA, mini CRM, …) : TimeTonic, DAMAaaS
Solution de monitoring : ncScale
…
Source : Kevin Ku – Pexels
Le choix de l’une ou l’autre des solutions doit se faire de façon éclairée avec une liste de critères / contraintes bien établie, dont voici un petit extrait :
Quels sont mes uses cases ?
Est-ce pour un usage interne ou pour du Customer Facing ?
Quels vont être les utilisateurs (IT ? Business ? Les deux ?) ?
Solution OpenSource ou propriétaire ?
Solution Française only ?
Hosting OnPrem ou Cloud ?
Respect des normes réglementaires ? sécurité ?
Quelle est la maturité et la pérennité de l’éditeur / la solution ?
Quelles sont les capacités de réversibilité ?
Quel est le niveau de couverture technico-fonctionnelle ?
Quel est l’effort pour se Up-Skill et l’utiliser ?
et sans oublier toutes les autres considérations: scalabilité, modèle financier, …
Des stacks commencent d’ores et déjà à se démarquer via les témoignages :
WeWeb en Front, cocorico, solution Française, génère du VueJS exportable,
Xano en Back-end truste le marché, le plus complet, le plus scalable, le plus sécurisé,
Make en orchestration API.
Se lancer dans l’aventure Visual Programming, c’est être conscient des problèmes que vous rencontrez et des bénéfices qu’ils peuvent vous apporter :
Réconcilier le Business et l’IT (Dev): enfin ils peuvent se comprendre de part l’aspect visuel et instantané du développement,
Être en Agilité par défaut,
Accélérer la phase de Build, tout en conservant ou en augmentant la qualité…
… et par conséquent améliorer le TimeToProd,
… et par conséquent diminuer les coûts projets,
Désengorger l’IT en décentralisant (gouvernance requise) certains projets dans les BU,
Redonner une bouffée d’oxygène au BUILD, qui se voit souvent écraser par le poids du RUN et de la gestion de l’obsolescence.
Le NoCode ne rime pas avec NoMethodology. Qu’il s’agisse d’une démarche tactique ou stratégique, il y a des clés de succès :
Associer les différents futurs profils utilisateurs au choix de la stack Visual Programming,
Les phases d’expression de besoin / cadrage / conception d’un projet en Visual Programming ne changent pas et une grande importance doit leur être accordée,
Une Gouvernance doit être définie en cohérence avec votre organisation (NoCode office centralisé? des référents dans les BU?),
Le Visual Programming ne permet pas de tout faire. Un cadre, un arbre d’éligibilité, des bonnes pratiques doivent être établis pour les utiliser à bon escient,
Think BIG, Act SMALL : démarrer petit, sur un scope favorable mais avec des points de douleurs identifiés et revendiqués. Démontrer le succès sur un premier scope attire les autres use cases et la quasi généralisation sur les périmètres éligibles,
Appliquer les mêmes bonnes pratiques que sur un projet de développement classique.
Toute rupture technologique, tout nouvel écosystème apporte avec lui son lot de freins et de réticences:
L’écosystème est assez jeune et la pérennité des solutions pose légitimement question,
Quid du fameux Vendor Lock-in et de la capacité de réversibilité. Pour les mitiger il faut être très mature et Responsable sur la phase de cadrage, conception, documentation de ce qui sera développé.
Le NoCode sacrifie-t-il la Sécurité ? Il faut s’assurer que la Sécurité n’est pas mise de côté et que la plateforme dispose des bonnes certifications (SOC2, ISO 27001, Hipaa, …) ainsi que des mécanismes maintenant bien connue sur la GRC (Governance, Risk, Compliance) de part le contrôle des accès, les permissions fines, les audits logs, la détection des incidents, …
Comment faire pour tester du NoCode quand les plateformes ne proposent pas intrinsèquement ces fonctionnalités ?
Les plateformes disposent-elles de mécanismes pour prévenir et éviter un Burn de facturation sur ce modèle très “as-a-service” ?
Actuellement, moins d’un pourcent de la population mondiale sait programmer. La démocratisation et l’accessibilité introduite par le Visual Programming a le bénéfice d’ouvrir la voie à toute une Diversité de personnes en quête de reconversion.
Mais … comme le souligne très justement Jean-Marc Jancovici également le net inconvénient et le risque majeur d’accentuer significativement une prolifération applicative avec des services digitaux futiles et inutiles. Sur notre planète à ressource finie, le numérique représente 4% des gaz à effet de serre (GES), cette débauche de moyens (énergétiques et intellectuels) sur ces sujets ne fait qu’accroître exponentiellement les usages digitaux… et leurs impacts.
Derrière mon clavier, je visual programme avec modération et sobriété. La consommation digitale excessive est dangereuse pour la planète, ceci est un message de Rhapsodies Conseil.
A la recherche d’un moyen pour automatiser vos processus, vous trouvez enfin la solution ! Des paillettes plein les yeux, vous découvrez le RPA et ses bienfaits.
Chez Rhapsodies Conseil, nous aimerions vous proposer une vision raisonnée du RPA.
Pour cela, nous vous proposons d’explorer les points suivants :
Quels sont les attraits du RPA ?
Qu’est-ce que le RPA ? Comment a-t-il évolué ?
Quand l’utiliser ?
Comment sécuriser le lancement d’une initiative RPA ?
Quelles sont les étapes indispensables du cadrage d’un cas d’usage ?
Quelles sont les perspectives futures ?
Les attraits du RPA
Le RPA (Robotic Process Automation) paraît attrayant par rapport à d’autres solutions d’automatisation.
Low code / no code : les solutions proposent souvent des facilités de création de scripts low code ou no code. Celles-ci sont adaptées à des utilisateurs dont le métier n’est pas le développement,
Faibles coûts : les coûts de mise en place sont moins élevés qu’un projet de refonte d’une application,
Rapidité de mise en œuvre : le délai de mise en œuvre, de l’ordre de quelques mois, est plus rapide que pour la plupart des projets.
Sur le papier, ça a l’air parfait pour vous !
Désolée de vous décevoir mais le RPA n’est pas une solution miracle.
Commençons par le début : qu’est-ce que le RPA ?
Revenons aux basiques : le RPA c’est quoi ?
Le RPA est un logiciel d’automatisation des processus métiers (ou IT d’ailleurs). Les scripts reproduisent l’interaction d’un humain avec les IHM des applications.
Le RPA est utilisé sur des processus stables basés sur des données structurées. Et dont le volume est important.
L’idée était de débarrasser les utilisateurs des tâches répétitives et à faible valeur ajoutée. Fini les tâches où nous reproduisons toujours les mêmes clics jusqu’à en devenir fou. Et dont la répétition favorise le risque d’erreur à la longue.
Voici quelques exemples de cas d’usage sur lesquels le RPA peut être utilisé :
vérifier des documents avant de les envoyer à un client,
activer le prélèvement automatique une fois le mandat signé,
mettre à jour des données client…
Le RPA peut être utilisé sur tous types de processus et dans tous les secteurs d’activité.
Vous vous demandez sûrement pourquoi il n’a pas envahi le marché tout de suite ? À cause de ses modalités d’intégration.
Vers davantage de modalités d’intégration
La première limite du RPA était évidemment la fréquence d’évolution du processus métier et des IHM. Par exemple, le bouton “valider” change de place et votre robot est bon pour la casse.
C’est le cas avec les applications maison qui évoluent fréquemment pour répondre à la demande des métiers. Ou les applications SaaS dont la roadmap éditeur n’est pas maîtrisée.
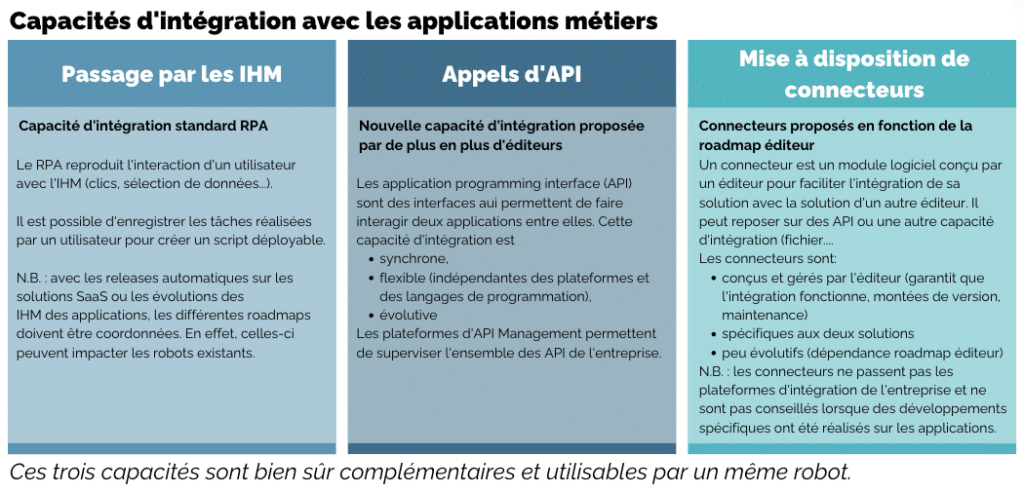
Le RPA a donc évolué pour dépasser cette limite. Les éditeurs se sont mis à proposer de nouvelles capacités d’intégration.
Deux nouvelles capacités ont vu le jour :
intégration grâce des API,
mise à disposition de connecteurs par les éditeurs.
Ces capacités d’intégration sont bien entendu complémentaires avec l’intégration par les IHM. Elles peuvent être utilisées par le même robot.
Cela permet d’étendre le périmètre d’intervention du RPA à de nouveaux processus. Il n’est plus limité à des processus manuels basés sur des applications dont les IHM évoluent peu.
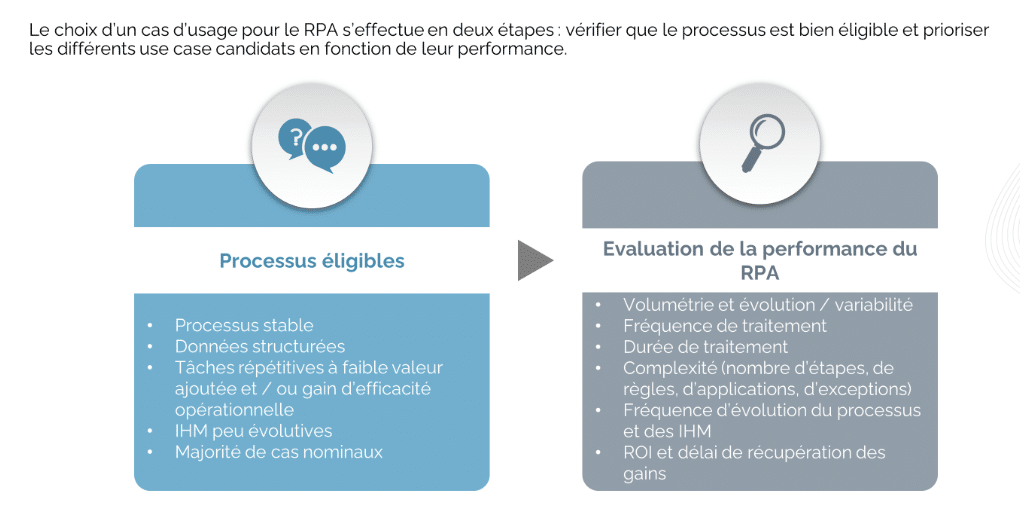
Maintenant que cette limite originelle est dépassée, qu’est-ce qui freine pour l’adopter ? Il reste nécessaire de bien choisir les cas d’usage sur lesquels appliquer du RPA.
Dans quels cas l’utilisation du RPA est-elle pertinente ?
Le RPA est particulièrement pertinent pour :
– des applications qui sont arrivées à maturité, évoluent peu et dont l’intégration avec le Système d’Information ne pourra pas prendre en charge les automatisations souhaitées,
– des petites migrations de données entre deux applications par exemple.
Vos premiers cas d’usage sélectionnés et priorisés, vous trépignez d’impatience !
Pas si vite, nous vous invitons d’abord à prêter attention aux points suivants.
Comment sécuriser le lancement d’une initiative RPA ?
Nous avons relevé trois points d’attention majeurs à considérer :
Réduction des coûts en passant à l’échelle : les coûts du RPA se réduisent lors du passage à l’échelle. C’est-à-dire quand plein de petits robots travaillent de concert au service de votre entreprise. Certes, les premiers cas d’usage sont faciles à trouver. Mais le potentiel n’est pas illimité. En particulier le nombre de cas d’usage avec un fort ROI.
Scalabilité en cas d’évolution de la volumétrie : il faut prendre en compte les évolutions de la volumétrie. Cela permet de dimensionner correctement les robots. La scalabilité verticale est clé dans le cas de processus saisonniers. Sinon, il faudra ajouter d’autres robots pour le même processus. Et cela a un impact non négligeable sur le ROI.
Confidentialité des données : quel niveau de confidentialité en fonction des données manipulées ? Cela conditionne le choix d’hébergement du RPA. En effet, de nombreux éditeurs proposent désormais des solutions Cloud.
Ces points d’attention considérés, foncez sur votre premier cas d’usage ! Nous avons encore quelques conseils dans notre manche, rassurez-vous.
Les étapes indispensables lors du cadrage d’un cas d’usage
De notre point de vue d’architecte (et expert en transformation digitale), plusieurs sujets sont à étudier :
Décrire le processus : pour mettre en place du RPA, le processus doit être décrit finement. Cette description est appelée “pas à pas”. Celle-ci peut être obtenue en documentant le processus. Ou avec l’aide d’un outil de task mining, aussi appelé process discovery. C’est-à-dire l’enregistrement des tâches d’un utilisateur sur son poste de travail. Le task mining est basé sur de l’OCR (Optical Character Recognition), du traitement du langage naturel et du machine learning.
Optimiser le processus : un projet d’automatisation est une opportunité de revoir en profondeur le processus. L’étape dont l’automatisation coûte le moins est celle qu’on supprime.
Ecosystème applicatif : l’identification de l’environnement applicatif du RPA est également crucial. Avec quelles applications doit-il s’interfacer ? Comment peut-il s’interfacer avec chacune d’entre elles ?
Comparer différents scénarios : il faut comparer le RPA à d’autres solutions d’automatisation. Par exemple les plateformes d’intégration industrielles déjà présentes dans votre entreprise. Parfois une bonne vieille API fait très correctement le travail. Elle peut coûter moins cher qu’une démarche RPA. Surtout s’il y a une brique d’API management dans l’entreprise. Et que les équipes sont habituées à manipuler des API. Le RPA, malgré la possibilité d’appeler des API, ne remplace pas une plateforme d’intégration industrielle.
Définir les responsabilités pour le RUN : l’équipe gérant le RUN des robots est souvent celle qui les a mis en place. Il est crucial qu’elle soit au courant quand les applications impliquées évoluent. Et qu’elle puisse faire évoluer les robots en fonction. Sinon, les robots ne fonctionnent plus et elle ne sait pas pourquoi. Elle doit donc être en lien avec les autres équipes au quotidien.
Voilà, vous savez tout ! Le RPA est une solution d’automatisation frugale des processus. Vous l’avez compris, c’est une solution et non une fin en soi.
Cette solution est adaptée si l’entreprise ne dispose pas de plateformes d’intermédiation industrielles. Et qu’il n’y a pas d’autres possibilités d’automatisation au vu des applications concernées. Comme nous l’avons vu, les cas d’usage doivent être rigoureusement sélectionnés et priorisés.
Avant de filer, nous avons un dernier sujet à explorer. L’IA qui révolutionne le marché de l’IT, ne peut-elle pas aider le RPA ? Si, bien sûr, et nous allons voir comment.
Quelles perspectives pour le futur ?
Le RPA bénéficie des apports de l’IA. Il peut interagir avec d’autres technologies, par exemple :
Intelligent Document Processing,
Task mining,
Traitement du langage naturel,
Vision par ordinateur.
On parle dans ce cas d’hyper automatisation. La promesse est la suivante : automatiser des processus moins structurés que ceux concernés par le RPA “classique”.
Cet ensemble de solutions propose des fonctionnalités intéressantes. Cela va permettre d’étendre le périmètre d’intervention du RPA.
D’après le Gartner, d’ici 2025, 90% des éditeurs de RPA proposeront de l’automatisation assistée par de l’IA générative.
En revanche, la mise en place d’une plateforme d’hyper automatisation va clairement au-delà d’un projet classique de RPA. A la fois en termes de coûts et de compétences.
Vous commencez à nous connaître, nous vous conseillons d’en faire une utilisation… Raisonnée.
L’inclusion est un concept fondamental dans la société contemporaine, particulièrement dans le domaine social et professionnel. C’est une philosophie qui vise à garantir que tous les individus, quelles que soient leurs origines, leurs capacités, leurs identités ou leurs croyances, se sentent respectés, valorisés et intégrés au sein d’un groupe, d’une organisation ou d’une communauté.
Au cœur de l’inclusion se trouve la reconnaissance de la diversité humaine sous toutes ses formes. Cela englobe non seulement la diversité visible, telle que l’origine ethnique, le genre, l’âge ou le handicap, mais aussi la diversité invisible, comme les expériences de vie, les compétences, les perspectives et les opinions.
L’inclusion va au-delà de simplement tolérer la différence. Elle implique de créer des environnements où chacun peut pleinement participer, contribuer et s’épanouir. Cela nécessite souvent des ajustements dans les politiques, les pratiques et les attitudes pour éliminer les barrières qui peuvent exclure certains individus.
Dans un contexte professionnel, par exemple, promouvoir l’inclusion peut signifier mettre en place des politiques de recrutement qui encouragent la diversité, offrir des formations sur la sensibilisation à la diversité et à l’inclusion, et créer un climat de travail où chacun se sent libre de s’exprimer sans crainte de discrimination ou de jugement.
Enfin, l’inclusion est également cruciale dans la sphère sociale, où elle favorise la création de communautés dynamiques et résiliantes, où chacun peut trouver un sentiment d’appartenance et de soutien.
Et chez Rhapsodies Conseil ?
Chez Rhapsodies Conseil, l’inclusion est un pilier fondamental de notre culture et de notre mission. Nous croyons fermement que l’égalité des chances et le respect de la diversité sont essentiels pour créer un environnement de travail dynamique et innovant. En particulier sur les thèmes de l’égalité femme/homme, des droits de diversité sexuelle et de genre ainsi que de l’inclusion des personnes en situation de handicap (visible ou non).
Chez Rhapsodies Conseil, les femmes représentent 35% de l’effectif total contre 30% en moyenne dans le secteur du numérique. Nous nous engageons à promouvoir une culture où chaque individu, quel que soit son genre, a les mêmes opportunités de progression et de développement. Cet engagement se traduit par des politiques de recrutement et de promotion équitables (+33% de la population managériale sont des femmes) ainsi que par des initiatives de formation (Leadership au féminin) et de sensibilisation (une rubrique dédiée dans notre newsletter, semaine de la QVT…) pour lutter contre les stéréotypes de genre et les discriminations. Il est aussi important de noter que Rhapsodies Conseil fait partie des Best Workplace for Women, ce qui témoigne de notre engagement en matière d’égalité professionnelle.
L’inclusion des personnes en situation de handicap est une autre dimension essentielle de notre engagement. Nous croyons en l’importance de créer un environnement accessible et adapté à tous. En outre, nous encourageons activement l’embauche de personnes en situation de handicap (nous sommes à 50% de notre objectif légal) et veillons à leur offrir les mêmes opportunités de carrière et de développement professionnel que leurs collègues. De plus, nous travaillons avec un ESAT (établissement qui permet aux personnes en situation de handicap d’exercer une activité professionnelle tout en bénéficiant d’un soutien médico-social et éducatif dans un milieu protégé) qui nous livre les paniers de fruits.
Le respect et la reconnaissance des droits des personnes LGBTQIA+ sont également au cœur de notre démarche d’inclusion. Nous sommes convaincus que chaque personne doit pouvoir être elle-même au travail sans craindre la discrimination ou l’exclusion. Pour cela, Rhapsodies Conseil met en place des mesures visant à garantir un environnement inclusif et respectueux avec la semaine de la Qualité de Vie au Travail ou la fresque de la diversité. En valorisant la diversité dans sa globalité, nous enrichissons notre culture d’entreprise et favorisons une plus grande créativité et innovation.
Soucieux du bien-être et de l’appartenance de nos collaborateurs, nous prenons le pouls de nos équipes tous les mois pour nous améliorer en continu. Cela fait plus d’un an que nous avons intégré à notre questionnaire mensuel une partie dédiée à l’inclusion. Recueillir le feedback de nos équipes est essentiel pour nous permettre de continuer à améliorer notre environnement de travail et à créer une culture où chacun se sent à sa place.
En résumé, l’inclusion est un principe essentiel qui promeut le respect, la diversité et l’égalité des chances. En embrassant l’inclusion dans tous les aspects de la vie, nous construisons des sociétés plus justes, plus harmonieuses et plus prospères pour tous. En embrassant la diversité sous toutes ses formes, nous construisons une entreprise plus forte, plus créative et plus résiliente. Nous sommes convaincus que c’est en valorisant chaque individu, en respectant leurs différences et en garantissant l’égalité des chances et une safeplace pour toutes et tous que nous pourrons véritablement exceller et innover dans notre domaine. L’inclusion est donc non seulement une valeur essentielle, mais aussi une stratégie gagnante pour l’avenir de Rhapsodies Conseil.
Événement Sobriété Numérique
Événement Sobriété Numérique
Participez à notre événement Sobriété Numérique avec Axa et la STIME
Suite aux travaux que nous avons menés dans notre livre blanc “Continuum de la sobriété numérique”, nous vous invitons à une table ronde exceptionnelle pour parler sobriété avec des intervenants engagés sur ces sujets. Ces derniers seront invités à partager et à débattre autour de ces questions essentielles :
Quel est le rôle de la sensibilisation et de la formation?
Comment mettre le “marketing” et ses techniques au service de la sobriété ?
Peut-on vraiment réussir sa transformation “Numérique Durable et Responsable” sans imposer des vraies contraintes (sur les volumes de données, les consommations, quotas…) ?
Comment sortir de l’impasse d’un système numérique en accélération permanente (5G, 6G, NG, GenAI, Metaverse, ….) ?
Et à l’inverse, comment percevoir les signes positifs apparents en ce moment (Montée en puissance des fresques du numérique, CSRD, …).
Sont-ils suffisants pour marquer le début d’une bascule ?
Quelles actions concrètes dans les organisations pour accélérer la sobriété du système d’information ?
Rhapsodies Conseil vous invite le mardi 24 septembre à 8h30 à un événement éco-conçu, engagé et responsable au centvingtseptbypixelis avec le traiteur meetmymama.
Notre table ronde sera animée par Rémy Marrone, Journaliste Indépendant en Marketing et Numérique Responsable, en présence d’invités exceptionnels :
Alexandra Bouet-Rochard, Responsable ESG – IT & Opérations Services au sein de Crédit Agricole – CIB
Céline Lescop, Lead Digital Sustainability & Data Architect au sein de AXA Group et Membre du groupe de travail à The Shift Project
Emmanuelle Bravard‑Sarraz, Directrice Communication et RSE à la STIME – DSI Les Mousquetaires
Gilles Juan, auteur indépendant de livres et documentaires, consultant en ingénierie pédagogique,
Mathieu Bourgeois Avocat associé – Immatériel & Numérique chez Klein & Wenner et Membre fondateur du Cercle de la Donnée
Jean-Baptiste Piccirillo, Senior Manager en charge de l’expertise Numérique Durable au sein de Rhapsodies Conseil, auteur de “Continuum de la sobriété”
Olivier Marchand, Team Leader Numérique Durable chez Rhapsodies Conseil
Rythmée, cette table ronde sera l’occasion pour nos intervenants de vous faire part de leurs retours d’expériences, de partager leur vision et leurs questionnements, et enfin d’aborder les actions concrètes qu’ils ont mis en place dans leurs organisations autour de ces enjeux.
A cette occasion, nous vous remettrons un exemplaire du livre-blanc « Continuum de la sobriété numérique ». Merci de confirmer votre participation pour que nous puissions assurer votre place !