A l’heure de l’omniprésence algorithmique dans une multitude de domaines de notre société, une commission européenne dédiée publiait, il y a un an déjà, un livre blanc mettant en lumière le concept d’IA de confiance. Si ce concept englobe une multitude de notions et d’axes de réflexion (prise en compte des biais, robustesse des algorithmes, respect de la privacy, …), nous nous intéresserons ici particulièrement à la transparence et l’explicabilité des systèmes d’IA. Dans cette optique et après un rappel des enjeux et challenges de l’explication des modèles, nous construirons un simple tableau de bord rassemblant les principales métriques d’explicabilité d’un modèle, à l’aide d’une librairie Python spécialisée : Explainer-Dashboard.
Vous avez dit “explicabilité” ?
L’IA Explicable est l’intelligence artificielle dans laquelle les résultats de la solution peuvent être compris par les humains. Cela contraste avec le concept de «boîte noire» où parfois même les concepteurs du modèle ne peuvent pas expliquer pourquoi il est arrivé à une prédiction spécifique.
Le besoin d’explicabilité de ces algorithmes peut être motivé par différents facteurs :
la confiance des utilisateurs et personnes concernées en leur justesse et en l’absence de biais ;
l’obligation réglementaire de pouvoir justifier et expliquer toute décision prise sur recommandation de l’algorithme : si le RGPD prévoit vaguement que toute décision prise par une IA doive être expliquée à la personne concernée sur demande, la loi française est bien plus précise. En prévoyant la mise à disposition d’informations concernant le degré et le mode de contribution du traitement algorithmique à la prise de décision, les données traitées et leurs sources, les paramètres de traitement et, le cas échéant, leur pondération, appliqués à la situation de l’intéressé et les différentes opérations effectuées par le traitement. Les secteurs bancaires et assurantiels sont particulièrement surveillés sur le sujet, notamment via l’action de l’ACPR.
Quand on adresse cette problématique, il convient de définir les différents termes (étroitement liés) que l’on peut retrouver :
La transparence donne à comprendre les décisions algorithmiques : elle traduit une possibilité d’accéder au code source des algorithmes, aux modèles qu’ils produisent. Dans le cas extrême d’une opacité totale, on qualifie l’algorithme de « boîte noire » ;
L’auditabilité caractérise la faisabilité pratique d’une évaluation analytique et empirique de l’algorithme, et vise plus largement à obtenir non seulement des explications sur ses prédictions, mais aussi à l’évaluer selon les autres critères indiqués précédemment (performance, stabilité, traitement des données) ;
L’explicabilité et l’interprétabilité, que l’on peut distinguer comme suit :
Si l’on considère des travaux de chimie au lycée, une interprétabilité de cette expérience serait “on constate un précipité rouge”. De son côté, l’explicabilité de l’expériencenécessitera de plonger dans les formules des différents composants chimiques.
Note : dans un souci de simplification, nous utiliserons largement le terme “explicabilité” dans la suite de cet article.
Via l’explication d’un modèle, nous allons chercher à répondre à des questions telles que :
Quelles sont les causes d’une décision ou prédiction donnée ?
Quelle est l’incertitude inhérente au modèle ?
Quelles informations supplémentaires sont disponibles pour la prise de décision finale ?
Les objectifs de ces explications sont multiples, car dépendants des parties prenantes :
faciliterles échanges itératifs avec les métiers, en imageant rapidement comment le modèle utilise les variables d’entrée pour répondre au problème posé ;
rassurerles experts métiers et les équipes en charge de la conformité sur l’absence de biais algorithmique ;
faciliter la validation du modèle par les équipes de conception et de validation ;
garantir la confiance des individus impactés par les décisions ou prédictions de l’algorithme.
Et concrètement ?
Le caractère “explicable” d’une IA donnée va principalement dépendre de la méthode d’apprentissage associée. Les méthodes d’apprentissage sont structurées en deux groupes conduisant, selon leur type, à un modèle explicite ou à une boîte noire :
Dans le cas d’un modèle explicite (linéaire, gaussien, binomial, arbres de décision,…), la décision qui en découle est nativement explicable. Sa complexité (principalement son nombre de paramètres) peut toutefois endommager son explicabilité ;
La plupart des autres méthodes et algorithmes d’apprentissage (réseaux neuronaux, agrégation de modèles, KNN, SVM,…) sont considérés comme des boîtes noires avec néanmoins la possibilité de construire des indicateurs d’importance des variables.
Lors du choix d’un modèle de Machine Learning, on parle alors du compromis Performance / Explicabilité.
Récupérer les données et entraîner un modèle simple
Pour cette démonstration, notre cas d’usage analytique sera de prédire, pour un individu donné, le risque d’occurrence d’une défaillance cardiaque en fonction de données de santé, genre, âge, vie professionnelle, …
Si cette problématique ne revêt pas spécifiquement d’aspect éthique relatif à la transparence de l’algorithme utilisé, nous pouvons toutefois bien percevoir l’utilité de l’explicabilité d’un diagnostic de risque assisté par IA : collaboration facilitée avec l’expert métier (en l’occurrence, le médecin) et information plus concrète du patient, entre autres bénéfices.
Le jeu de données éducatif utilisé est fourni par l’OMS et peut être téléchargé sur la plateforme de data science Kaggle :
Il contient les données de 5110 personnes, réparties comme suit :
Données :
Age du sujet ;
Genre du sujet ;
A déjà souffert d’hypertension (oui / non)
A déjà souffert de maladies cardiaques (oui / non)
Statut marital
Type d’emploi
Type de résidence (citadin, rural)
Niveau moyen sanguin de glucose
IMC
Fumeur (oui / non)
Note : nous avons procédé à une simple préparation des données qu’il est possible de retrouver dans le notebook complet en bas de page.
Pour la partie modélisation, nous utiliserons un modèle « baseline » de Random Forest. Pour éviter que notre modèle ne reflète seulement que la distribution des classes (très déséquilibrée dans notre cas, 95-5), nous avons ajouté des données “synthétiques” à la classe la moins représentée (i.e. les patients victimes de crises cardiaques) en utilisant l’algorithme SMOTE, pour atteindre une répartition équilibrée (50-50) :
Notre modèle est prêt, nous pouvons à présent l’utiliser en input du dashboard !
Création du dashboard
Nous avons donc à disposition un modèle entraîné sur notre dataset et allons à présent construire notre tableau de bord d’interprétation de ce modèle.
Pour ce faire, nous utilisons la librairie explainer-dashboard, qui s’installe directement via le package installer pip :
pip install --upgrade explainerdashboard
Une fois la librairie installée, nous pouvons l’importer et créer simplement une instance “Explainer” à l’aide des lignes suivantes :
Plusieurs modes d’exécution sont possibles (directement dans le notebook, dans un onglet séparé hébergé sur une IP locale, …) (plus d’informations sur les différents paramètres de la librairie dans sa documentation).
Note : le dashboard nécessitera d’avoir installé la librairie de visualisation “Dash” pour fonctionner.
Interprétation des différents indicateurs
Le tableau de bord se présente sous la forme de différents onglets, qu’il est possible d’afficher / masquer via son paramétrage :
Features importance : impact des différents features du jeu de données sur les prédictions ;
Classification Stats : aperçu complet de la performance du modèle de classification utilisé (ici, Random Forest) ;
Individual Predictions & What if analysis : zoom sur les prédictions individuelles et influence des features sur ces dernières ;
Features dependance : visualisation de l’impact de couples de features sur les prédictions et corrélations entre features ;
Decision Trees : permet, pour les modèles à base d’arbres de décision, de visualiser les paramètres et cheminement de décisions de chacun de ces arbres.
Plongeons à présent dans les détails de chacun de ces onglets !
Features Importance
A l’instar de l’attribut feature_importances_ de notre modèle de Random Forest, cet onglet nous permet de visualiser, pour chaque colonne de notre dataset, le pouvoir de prédiction de chaque variable.
L’importance des features a ici été calculée selon la méthode des valeurs de SHAP (acronyme de SHapley Additive exPlanations). Nous n’approfondirons pas ce concept dans cet article (voir rubrique “aller plus loin”).
Ces scores d’importance peuvent permettre de :
Mieux comprendre les données à disposition et ainsi, avec l’aide d’un expert métier, détecter lesquelles seront les plus pertinentes pour notre modèle ;
Mieux comprendre notre modèle et son fonctionnement, puisque les scores d’importance peuvent varier en fonction du modèle choisi ;
En phase d’optimisation de celui-ci, diminuer son nombre de variables pour en réduire sa durée d’entraînement, en augmenter son explicabilité, faciliter son déploiement ou encore atténuer le phénomène d’over-fitting.
Dans l’exemple ci-dessous, on peut constater que :
l’âge, l’IMC et le niveau moyen de glucose dans le sang sont des prédicteurs forts du risque de crise cardiaque, ce qui correspond bien à une intuition commune ;
Toutefois, d’autres prédicteurs forts sortent du lot, comme le fait de ne jamais avoir été marié ou encore le fait d’habiter en zone rurale, qui ne sont pas évidents à première vue …
Classification Stats
Cet onglet nous permet de visualiser les différentes métriques de performance de notre modèle de classification : matrice de confusion, listing des différents scores, courbes AUC, … Il sera utile en phase de paramétrage / optimisation du modèle pour avoir un aperçu rapide et complet de sa performance :
Individual Predictions
Cet onglet va nous permettre, pour un individu donné, de visualiser les 2 indicateurs principaux relatifs à la décision prise par le modèle :
Le graphe des contributions :
La contribution d’un feature à une prédiction représente l’impact probabilistique sur la décision finale de la valeur de la donnée considérée.
Suite à notre traitement du déséquilibre des classes, nous avons autant de sujets “sains” que de sujets “à risque” dans notre jeu de données d’apprentissage. Un estimateur aléatoire aura donc 50% de chances de trouver la bonne prédiction. Cette probabilité est donc la valeur “baseline” d’entrée dans notre graphe des contributions.
Ensuite, viennent s’ajouter en vert sur le visuel les contributions des features pour lesquelles la valeur a fait pencher la décision vers un sujet “à risque”. Ces features et leur contribution amènent la décision à une probabilité de ~60% de risque.
Puis, les features dont la contribution fait pencher la décision vers un sujet “sain” viennent s’ajouter (en rouge sur le graphe). On retrouve ici nos prédicteurs forts tels que l’âge ou encore l’IMC.
> Le sujet est proposé comme sain par l’algorithme
Le graphe des dépendances partielles :
Ce visuel nous permet de visualiser la probabilité de risque en fonction de la variation d’une des features, en conservant la valeur des autres constantes. Dans l’exemple ci-dessus, on peut voir que pour l’individu considéré, augmenter son âge aura pour effet d’augmenter sa probabilité d’être détecté comme “à risque”, ce qui correspond bien au sens commun.
What if Analysis
Dans l’optique de l’onglet précédent, l’analyse “what if” nous permet de renseigner nous mêmes les valeurs des différents features et de calculer l’output du modèle pour le profil de patient renseigné :
Il reprend par ailleurs les différents indicateurs présentés dans l’onglet précédent : graphe des contributions, dépendances partielles, …
Features Dependance
Cet onglet présente un graphe intéressant : la dépendance des features.
Il nous renseigne sur la relation entre les valeurs de features et les valeurs de SHAP. Il permet ainsi d’étudier la relation générale entre la valeur des features et l’impact sur la prédiction.
Dans notre exemple ci-dessus, le nuage de points nous apprend deux choses :
L’âge (abscisses) est un fort prédicteur pour notre cas d’usage car, pour chaque observation, les valeurs de SHAP (ordonnées) sont élevées (mais nous le savions déjà). On remarque une inversion de la tendance autour de l’âge de 50 ans, ce qui conforte notre intuition (i.e. les sujets plus jeunes sont moins enclins à être considérés comme “à risque”) : une valeur de SHAP “hautement négative” nous indique que la feature est un prédicteur fort d’un résultat associé à la classe nulle (ici, un individu désigné comme “sain”) – à l’inverse, une valeur de SHAP “hautement positive” indique que la feature est un prédicteur fort d’un résultat associé à la classe positive (ici, un individu désigné comme “à risque”).
L’âge est fortement corrélé au statut marital des individus observés (points rouges = individus célibataires). Cela est cohérent avec le sens commun mais nous renseigne également sur le pouvoir prédictif du statut marital qui ne serait finalement dû qu’à sa forte corrélation à l’âge, vrai prédicteur important de notre problématique. Dans une optique d’optimisation du modèle, cette feature pourrait potentiellement être retirée.
Decision Trees
Enfin, dans le cas où l’input du dashboard est un modèle à base d’arbres de décisions (gradient boosted trees, random forest, …), cet onglet sera utile pour visualiser le cheminement des décisions de la totalité des arbres du modèle.
Dans l’exemple ci-dessous, nous considérons le 2712ème individu du jeu de données pour lequel 50 arbres ont été calculés via l’algorithme de Random Forest. Nous visualisons la matrice de décision de l’arbre n°13 :
Ce tableau nous montre le cheminement de la décision, depuis une probabilité de ~50% (qui serait la prédiction d’un estimateur ne se basant que sur la moyenne observée sur le jeu de données). On peut constater que, pour cet individu et pour l’arbre de décision considéré :
La ruralité, l’occupation professionnelle et le statut marital (bien que démontré précédemment comme prédicteur faible) ont poussé la décision de cet arbre vers “individu à risque” ;
Les autres données de l’individu telles que son genre ou encore son âge ont fait basculer la décision finale de l’arbre à “individu sain” (probabilité de risque finale : 7.14%).
L’onglet nous propose également une fonctionnalité de visualisation des arbres via la librairie graphviz.
L’étude des différents indicateurs présentés dans les onglets du dashboard nous a permis :
De confirmer des premières intuitions sur les variables importantes de ce problème de modélisation : l’âge du patient, son IMC ou encore son taux moyen de glucose ;
A l’inverse, de conclure de la pertinence relativement moindre de variables telles que le statut marital (merci à la dépendance des features !), le statut professionnel, le lieu de résidence mais également les antécédents cardiaques (moins évident à priori…). On pourra alors se poser la question de conserver ou non ces variables dans une optique de simplification du modèle ;
De mesurer la performance globale du modèle et, derrière une accuracy honorable de ~0.80, de découvrir de pauvres recall et precision (respectivement 0.44 et 0.14) : notre modèle est donc plus performant pour détecter les Vrais Négatifs (les sujets “sains”) que les sujets réellement à risque. Il faudra travailler à l’optimiser autrement.
De procéder à des analyses de risque et de comportement du modèle sur un patient donné via l’interface de l’onglet “What if…”.
L’étude de ces indicateurs doit être partie intégrante de tout projet d’IA actuel et futur
L’explicabilité des modèles de Machine Learning, aujourd’hui considéré comme l’un des piliers d’une IA éthique, responsable et de confiance, représente un challenge important pour accroître la confiance de la société envers les algorithmes et la transparence de leurs décisions, mais également la conformité réglementaire des traitements en résultant.
Dans notre cas d’étude, si la librairie explainer-dashboard est à l’initiative d’un particulier, on remarque une propension à l’éclosion de plusieurs frameworks et outils servant le mouvement “Fair AI”, dont plusieurs développés par des mastodontes du domaine. On peut citer le projet AIF360 lancé par IBM, une boîte à outils d’identification et de traitement des biais dans les jeux de données et algorithmes.
Cette librairie est utile en phase de développement et d’échanges avec le métier mais peut toutefois ne pas suffire en industrialisation. Alors un dashboard “maison” sera nécessaire. Elle a toutefois un potentiel élevé de personnalisation qui lui permettra de répondre à de nombreux usages.
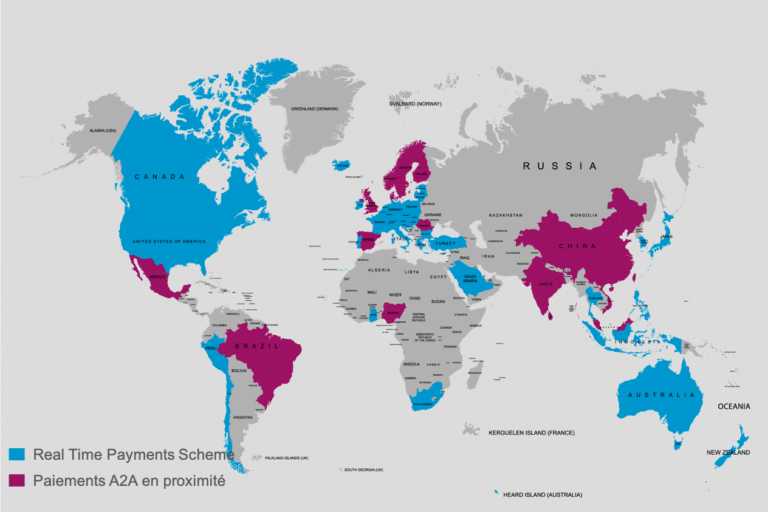
J’ai eu le plaisir d’introduire la table ronde « Le futur du paiement de proximité », organisée par le groupe de travail Perspectives & Innovations du France Payment Forum. J’ai présenté une synthèse des différents éléments qui pourraient favoriser la construction de nouveaux parcours utilisateurs en proximité, à commencer par l’émergence et le développement des schemes de Real Time Payment
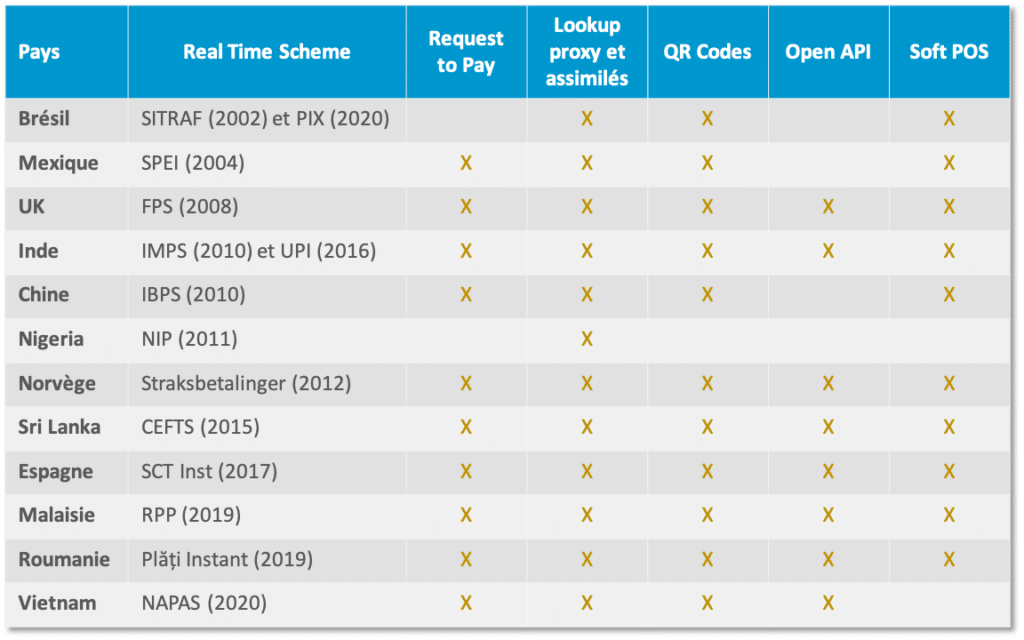
En effet, depuis le Zengin japonais lancé en 1973, les schemes de paiement en temps réel n’ont cessé de se développer et se généraliser avec une certaine accélération sur les dernières années. Les derniers en date étant le SCT Inst en Europe en 2017, la Malaisie et la Roumanie en 2019 et le Vietnam en 2020.
Un environnement favorable
Parmi ces initiatives, les transferts de compte à compte en proximité constituent une partie significative des cas d’usage. Une analyse comparative fait apparaître des similitudes en termes d’écosystème. En effet, au-delà de l’existence d’un scheme de real time payment, nous remarquons la présence de catalyseurs tels que :
le Request to Pay sous toutes ses formes, du simple lien de paiement pré-renseigné au modèle 4 coins tel que celui développé par l’EPC
les alias afin de fluidifier la gestion des identités numériques ; pour simplifier l’expérience d’achat, les alias permettent de ne pas avoir à renseigner son IBAN ou bien celui du commerçant
les QR codes, qu’ils soient dynamiques ou non
Des API ouvertes qui favorisent les interactions entre les acteurs de l’écosystème et la construction d’expériences d’achat de plus en plus pertinentes pour des niches jusque-là non/mal servies
Les Soft POS qui démocratisent l’accès à l’expérience de paiement digital en proximité en permettant à de petits commerçants de transformer leurs smartphones ou tablettes en terminaux de paiement simplement en téléchargeant une application
Pour quels bénéfices ?
Toutefois, bien que ces catalyseurs favorisent indéniablement l’émergence de nouveaux usages, le véritable challenge reste celui de l’adhésion à la fois des consommateurs et des marchands. Pour cela, la nouvelle proposition de valeur devra résoudre un véritable pain point ou bien améliorer substantiellement un usage existant. Parmi les bénéfices attendus de la part des consommateurs, nous pouvons citer :
Régler de gros achats sans être limité par les plafonds de paiement de la carte
Améliorer la confidentialité et la sécurité des opérations en n’ayant plus à communiquer ni son PAN ni son IBAN
Disposer d’un mode de paiement alternatif pour répondre à des usages de niches
Bénéficier d’une expérience de paiement plus fluide…
Du côté des commerçants il sera important de :
Co-construire un modèle économique complémentaire qui prenne en compte les spécificités du nouveau cas d’usage et son panier moyen
Minimiser la fraude et les impayés liés aux autres moyens de paiement (chèques, carte…) et apporter une garantie d’irrévocabilité
Faciliter l’accès aux paiements digitaux à travers de nouveaux modèles d’acceptation qui minimisent les frais de mise en place
Faciliter l’automatisation de la réconciliation des paiements et le cas échéant fluidifier les opérations de remboursement…
Comment s’y prendre ?
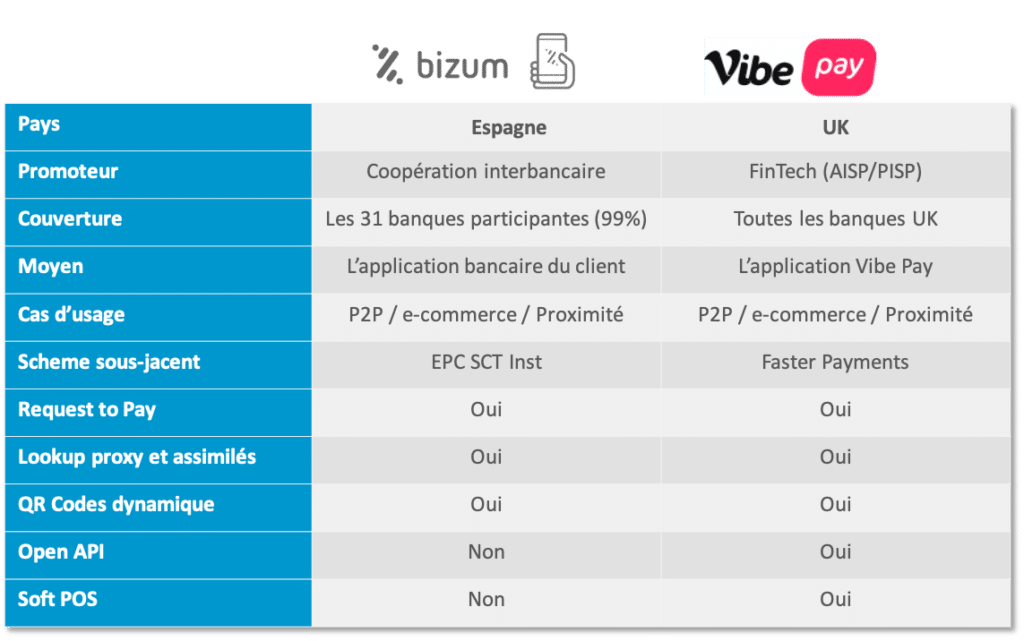
Face à cet objectif de fluidification de l’expérience utilisateur, plusieurs approches sont envisageables. A titre d’exemple, le tableau récapitulatif présenté ci-dessous fait le parallèle entre le modèle du consortium Bizum, fruit de la coopération de 31 banques espagnoles, et celui de la FinTech (AISP/PISP) Vibe Pay.
Bien que sensiblement différents en termes de scheme sous-jacent, de stratégie de couverture et de moyen, il est à noter que les deux modèles adressent les mêmes cas d’usage, à savoir le P2P, l’e-commerce et le paiement en proximité. De ce fait, le dernier challenge à relever, et non des moindres, sera de construire une expérience d’achat unifiée sans coutures.
Pour atteindre cet objectif, il est essentiel d’intégrer le paiement bien en amont lors de la conception de l’expérience utilisateur afin qu’il se fonde dans le parcours d’achat et non pas être un nième moyen de paiement qui arriverait en bout de chaîne.
Outre l’offre bancaire classique, la France compte plus de 600 FinTechs, dont pas moins de 150 PayTechs. Bonne nouvelle au niveau de l’offre, mais comment s’y retrouver au moment du choix de solution de paiement, que l’on soit commerçant, marketplace, fournisseur de service en ligne, association…
Les critères à prendre en compte sont multiples dans le choix de son PSP. Concentrons-nous ici sur le critère économique, autour de 7 questions visant à :
Evaluer les coûts des solutions de paiement
Et s’assurer que la comparaison s’applique à des prestations comparables…
1. Quel est le positionnement du PSP ?
Derrière le check-out ou plus généralement l’ordre client, nombreux sont les intervenants dans la chaîne de paiement. Les stratégies fournisseurs varient largement :
De l’orientation one-stop-shop, intégrant des partenaires pour apporter une solution plus complète au client,
A un positionnement de spécialiste, sur un maillon de la chaîne…
Le couplage Acceptation / Acquisition illustre cette problématique de périmètre, avec ses conséquences directes sur l’analyse des coûts :
Acceptation ET Acquisition (one-stop-shop) Certains PSP proposent une prestation intégrant acceptation et acquisition. Ils s’appuient sur leurs partenaires pour l’acquisition, sélectionnés pour raisons d’appartenance au même groupe financier ou dans le cadre de négociations tarifaires massifiées.
Acceptation seule D’autres permettent au client de choisir son acquéreur. La solution de paiement intervient dans ce cas en tant que passerelle technique, routant les flux vers l’acquéreur retenu par le client. Cette configuration permet au client de conserver / renforcer sa relation avec son acquéreur, auquel il peut avoir confié d’autres prestations et négocié des conditions particulières, notamment sur les transactions On-Us…
2. Quelle est votre maîtrise de vos volumes d’opérations de paiement ?
« La prévision est difficile surtout lorsqu’elle concerne l’avenir… ». Au moment du choix d’une solution de paiement, il peut être difficile d’évaluer les volumes d’opérations, leur répartition par moyen de paiement…
S’ils sont bien maîtrisés, les propositions plus détaillées (jusqu’à 25 paramètres recensés dans notre grille d’analyse) pourront permettre d’optimiser les coûts, au prix d’un engagement dans la durée, de minima de volumes, de conditions de modification et de sortie….
Dans l’autre cas, les propositions plus flexibles et plus intégrées seront plus adaptées à un modèle économique à prouver.
3. Quelle palette de moyens de paiement ?
Les nouveaux PSP se sont d’abord développés sur le modèle de la carte, en tant que moyen de paiement privilégié des clients, en ligne et en magasin.
Les autres moyens de paiement (Virement, Prélèvement…) ont depuis commencé à percer, notamment pour des raisons de coût à la transaction.
Le Virement Instantané va contribuer à élargir cette palette, en concurrence directe avec la carte, à la fois au niveau des coûts, mais aussi pour des paiements supérieurs aux plafonds cartes.
Au niveau de la comparaison des coûts, les PSP proposant ces différents moyens de paiement bénéficieront de coûts moyens inférieurs aux pure-players de la carte.
4. Faut-il prévoir des coûts complémentaires pour les retries, rejets, chargebacks, reporting… ?
Au-delà du traitement nominal des opérations, il est important d’intégrer aussi les cas d’exception (trop nombreux d’ailleurs, pour être qualifiés d’exceptions…).
Là encore, les PSP se distinguent entre :
Ceux qui considèrent ces services comme indissociables du paiement ; dans une logique de cas d’usage (vision client) familière aux FinTechs, il est naturel d’intégrer ces services dans l’offre globale, sans surcoût / option spécifique ;
Ceux qui les considèrent comme des services supplémentaires, dans une vision orientée fournisseur, considérant la rentabilité de chaque service qu’il propose et les coûts externes (interbancaire, schemes…) générés par chacun.
5. Quel impact sur la fraude et les charges internes ?
La fraude intervient dans la comparaison économique des PSP à 2 niveaux :
D’abord dans l’efficacité de la gestion du risque que le PSP peut proposer, avec une performance à évaluer en matière de faux positifs / négatifs et dans la gestion de l’authentification forte (mode frictionless…). L’enjeu se mesure directement dans la perte de Chiffre d’Affaires et le montant des impayés.
Ensuite, dans les moyens mis en œuvre pour la gestion des litiges et la relance pour impayé. Le service peut être proposé par le PSP ou assuré en interne par le Client, à prendre en compte dans la comparaison des coûts.
Outre la fraude, d’autres postes de charge interne sont touchés par le choix du PSP :
Réconciliation & Reporting : les ressources dédiées au rapprochement des commandes et des règlements dépendent fortement de la qualité du reporting fourni par le PSP ;
Traçabilité : la capacité offerte par un PSP d’accéder directement au statut d’un paiement dans la chaîne de traitement permet d’éviter les multiples échanges téléphoniques… ;
Gestion des retries : la délégation au PSP de la représentation des paiements en échec peut libérer des ressources au sein de l’entreprise. Au-delà de l’existant, les opportunités d’optimisation ne manquent pas, dans la digitalisation des processus internes, comme la gestion des factures fournisseurs, la gestion des salaires… les fournisseurs spécialisés se développent en complément des éditeurs de solutions de comptabilité, paie… Le choix du PSP peut impacter ce potentiel d’optimisation, selon sa capacité à s’interfacer avec ces solutions, via ses API et les partenariats noués avec ces fournisseurs spécialisés.
6. Encaissement direct ou reversement ?
Au-delà des coûts de transaction, les offres des PSP peuvent aussi impacter la trésorerie. Deux modèles coexistent :
Encaissement direct : Le client reçoit directement les fonds sur son compte ;
Reversement : Les fonds sont collectés par le PSP, qui les reverse au Client selon des conditions de fréquence, montant minimum…, avec des délais jusqu’à 30 jours…
7. Quels coûts de mise en œuvre de la solution de paiement ?
Au-delà des coûts de fonctionnement traités plus haut, les coûts de mise en œuvre peuvent aussi varier :
Les principales solutions du marché (CMS e-commerce) proposent des extensions ou plug-ins, à télécharger par le client, avec un support léger pour le paramétrage. Les coûts de projet sont négligeables dans ce cas.
Dans d’autres cas, le déploiement donne lieu à un véritable projet, avec les ressources mobilisées côté client, auxquelles peuvent éventuellement s’ajouter des frais d’installation (set-up) facturés par le PSP.
En conclusion, la multiplication des PSP a apporté une plus grande richesse des services de paiement. Elle a aussi rendu plus complexe la comparaison des offres, au moment du choix du Prestataire de Services de Paiement.
Rien que sur le critère des coûts, la comparaison nécessite de prendre en compte le modèle économique du PSP, sa position dans la chaîne de bout en bout, la palette de moyens de paiement supportés, la fraude, les optimisations possibles sur les charges internes et les opportunités des solutions de digitalisation dans l’entreprise…
En rappelant toutefois que l’équation économique repose avant tout sur le taux de transformation client et que la fluidité du parcours de paiement proposé par le PSP précède la question du coût !
Alors, rendez-vous sur nos prochains articles sur le choix des solutions de paiement pour éclairer l’ensemble de ces critères.
Vision cible du si dans un contexte mondial avec filiales, erp, industrie 4.0 et référentiels
Contexte
Un grand groupe industriel mondial possédant des dizaines de filiales est en pleine évolution de son SI sur plusieurs aspects : digital, référentiels, industrie 4.0, ERP, etc. Le groupe a besoin d’avoir de la visibilité sur son futur, la cible de son SI et les moyens d’y parvenir.
Solutions
Mettre en place un cadre de référence pour les métiers et poser une vision globale de l’entreprise à partir d’une Carte des capacités métiers
Poser une vision globale de l’évolution du SI à 5 ans et notamment le périmètre de l’ERP
Identifier les périmètres nécessitant des études complémentaires autour de l’ERP
Poser les scénarios d’évolution des référentiels SI
Cartographier l’ensemble des applications du SI et les principaux flux
Choisir un outil de cartographie et le déployer
Mettre en place la gouvernance de l’architecture d’entreprise : livrables, outils, comitologie
Bénéfices
Vue d’ensemble du SI et des évolutions prévues avec un partage au plus haut niveau de l’entreprise
Cartographie partagée de l’ensemble du SI
Vision cible des échanges du SI
Pérennisation de l’activité d’Architecture d’Entreprise
Les aurtes success stories qui peuvent vous intéresser
Au sein de la Direction Innovation Digital Data (iD²) et de la Direction de l’Architecture, accompagnement, lors des phases d’opportunité, de cadrage et de mise en place, du programme connaissance Client (Référentiel & V360) :
Missions
Evangélisation aux concepts de gestion, de qualité et d’architecture des données de référence
Introduction au modèle objet et cycle de vie Client (Tiers)
Formalisation des architectures applicatives existantes et mise en exergue des « pains »
Définition du périmètre fonctionnel, des grands principes d’architecture et de l’architecture applicative de la Cible (Référentiel Client & V360)
Définition du périmètre fonctionnel, des grands principes d’architecture et de l’architecture applicative des différents états stables de la trajectoire sur 2018 & 2019
Cadrage (recueil et analyse) et formalisation des besoins des différentes directions métier (Relation Client, Commerce, Digital et Marketing opérationnel)
Accompagnement sur le RFP pour le choix de la solution disruptive MarkLogic (base sémantique NoSQL, métadonnées, moteur d’indexation et de recherche, sécurisation complète des données) et de l’intégrateur
Définition de la Product Backlog (création des User Stories, pondération et priorisation métier, découpage par granularité uniforme, …)
Product Ownership du projet
Accompagnement Architecture sur le projet de mise en place de la solution dans une vision SI global avec les adhérences projets
Bénéfices
Une approche pragmatique, basée sur une expertise fonctionnelle, méthodologique et technologique du SI Data Centric, éprouvée sur des contextes clients similaires et alignée sur les exigences de résultat rapide du DSI et des directions métier de Malakoff Médéric.
Les autres success stories qui peuvent vous intéresser
A l’heure où la Data transforme le métier de l’assurance, ce leader de l’assurance et des services financiers, s’appuie sur la méthodologie de Rhapsodies Conseil, cabinet indépendant de conseil en management. Cette méthodologie est utilisée au sein des filiales de l’assureur dans une optique de valorisation des données visant le cadrage des investissements. Elle permet d’identifier les domaines de Data les plus opportuns pour générer des bénéfices mais aussi mettre en perspective les lacunes.
La stratégie de valorisation de la donnée
Parce que la transformation digitale est une lame de fond, ce leader européen de l’assurance y investit toutes les ressources nécessaires et accorde une place hautement stratégique aux sujets Data. Valoriser la donnée s’impose ainsi comme un enjeu clé pour analyser et prioriser ce qui va générer du bénéfice. C’est à ce titre qu’est utilisée « Augmentez la valeur de vos données ! », la méthodologie de Rhapsodies Conseil qui vise à orienter la stratégie Data et à définir les investissements nécessaires à la conduite des travaux de qualité de données. L’objectif : faire de la valeur de la Data le fil directeur stratégique pour répondre aux usages métier et apporter une forte valeur ajoutée à l’entreprise. Cette valeur ajoutée peut notamment permettre de d’accélérer la croissance commerciale, d’améliorer les profits, de faire des économies ou encore d’améliorer la productivité des équipes.
De cette méthodologie, notre groupe tire à ce jour de nombreux bénéfices notamment en matière d’efficacité, à commencer par l’amélioration des processus ou encore la gestion des sinistres. Tout particulièrement sur nos marchés émergents, nous constatons que la maîtrise de la donnée améliore considérablement la relation client et in fine la fidélisation des clients. Cela permet d’ailleurs de faire le lien entre la donnée et la valorisation financière. En somme, c’est sur l’ensemble de ses sujets ‘core business’ que ce travail sur la donnée prend tout son sens.
Chief Data Officer d’une des filiales de cet assureur
Voir notre méthode appliquée au sein d’un groupe tel que ce leader européen de l’assurance est une réelle fierté et la preuve tangible que notre vision de la valorisation Data trouve écho et résonne chez nos clients. C’est également révélateur d’une transformation digitale en ordre de marche où la Data est intrinsèquement devenue un acteur central de notre quotidien et de celui des entreprises et organisations.
Albert Bendayan
Application de la méthodologie data de rhapsodies conseil au sein du groupe européen d’assurance
Le groupe est organisé en différents marchés : la France, l’Europe, l’Asie et l’International New Market et chacun dispose de sa propre gouvernance. La méthodologie Data de Rhapsodies Conseil est adaptée aux besoins de chaque pays et au degré de maturité des différents marchés, qu’ils soient émergents ou matures, et qu’elles que soient les problématiques, les budgets, les contextes et les challenges. Rhapsodies Conseil intervient aux côtés du groupe sur plusieurs thématiques Data afin de définir des approches, des principes et des bonnes pratiques, agissant comme accélérateurs pour aider les différentes filiales du groupe. Les dirigeants locaux sont donc les premiers utilisateurs de la méthodologie qui est aujourd’hui particulièrement employée au Mexique, en Colombie et dans plusieurs pays du Golfe Persique.
Dans les entités émergentes les dirigeants locaux font face à des défis de taille : générer de la profitabilité dans des marchés complexes, où ils n’ont pas tout le temps, la latitude budgétaire et les capacités technologiques pour pouvoir être réactifs. Ils doivent donc effectuer des investissements mesurés sur le digital, la Data, l’IT,… et assurer un ROI rapide et important ?
Chief Data Officer
Ce leader européen de l’assurance a orienté son approche Data sur la partie stratégique qu’est la valorisation financière : c’est pour eux le levier principal et les bénéfices sont d’ores et déjà palpables. Fort de ce succès, le groupe a pour objectif en 2020 de continuer à appliquer cette méthode et de la promouvoir auprès de l’ensemble des parties-prenantes, pour qu’elle soit partagée avec les autres entités du groupe.
Les autres success stories qui peuvent vous intéresser