Il n’est pas toujours évident de s’y retrouver dans la jungle que constituent les différents comités en entreprise, et les comités d’architecture ne font pas exception. Vous êtes perdus et ne savez pas comment définir la comitologie qui répondra aux besoins de votre organisation ? Suivez le guide !
Dans cet article, nous aborderons deux grandes étapes :
la définition de la comitologie d’architecture, dans un premier temps,
suivie par un focus sur l’animation de cette comitologie.
Une comitologie utile et intéressante doit être construite pour répondre à vos objectifs
Identifier clairement les objectifs de la comitologie
Les objectifs des organisations étant très divers, il est naturel qu’une myriade de comités d’architecture différents existent :
des comités transverses ou spécifiques à un programme de transformation,
des comités de partage entre architectes,
ou des comités d’arbitrage.
L’un des écueils principaux consiste à faire surgir dans les agendas autant de comités que de champignons après les premières pluies d’automne. On voit souvent des participants occasionnels se mélanger les pinceaux avec les trois ou quatre réunions portant un nom approchant. Et s’ils ne savent pas les différencier, nul doute qu’ils ignorent leurs objectifs…
Mais dans ce cas, comment créer une comitologie d’architecture claire, lisible et utile ?
Afin de choisir la plus adaptée, il est tout d’abord capital de bien comprendre le contexte de votre entreprise et d’identifier vos objectifs. Cela peut passer par des interviews mais aussi être exploré dans le cadre d’un audit de maturité de l’architecture, qui comporte un volet sur la comitologie.
Définir ensemble la comitologie qui répond aux objectifs identifiés
Une fois les objectifs clarifiés, la construction collaborative de la comitologie peut ensuite débuter !
Rhapsodies Conseil vous aide à dessiner la comitologie qui vous conviendra le mieux en s’appuyant sur :
les éléments de contexte,
un catalogue d’exemples de comités d’architecture,
un arbre de décision.
Votre connaissance fine de l’organisation dans laquelle vous évoluez sera également précieuse et devra être prise en compte.
Vous obtiendrez à terme une description des différents comités d’architecture à mettre en place précisant :
leurs objectifs,
la fréquence à laquelle ils seront tenus,
leurs périmètres respectifs,
les différents participants.
Ces éléments seront bien sûr diffusés au sein de l’organisation pour bien expliquer le rôle du ou des comités d’architecture. Bien communiquer en amont de la mise en place des comités permettra de s’assurer que tous les participants, récurrents ou occasionnels, n’aient pas de doutes sur leurs objectifs.
Il ne reste plus qu’à les mettre en œuvre et les animer !
Pas si simple me direz-vous ? Comment s’assurer que cette comitologie soit animée de manière efficace et réponde ainsi aux objectifs de l’organisation ?
Tout en évitant à tout un chacun d’écouter distraitement d’une oreille en travaillant sur un autre sujet en parallèle ou en traînant sur son téléphone…
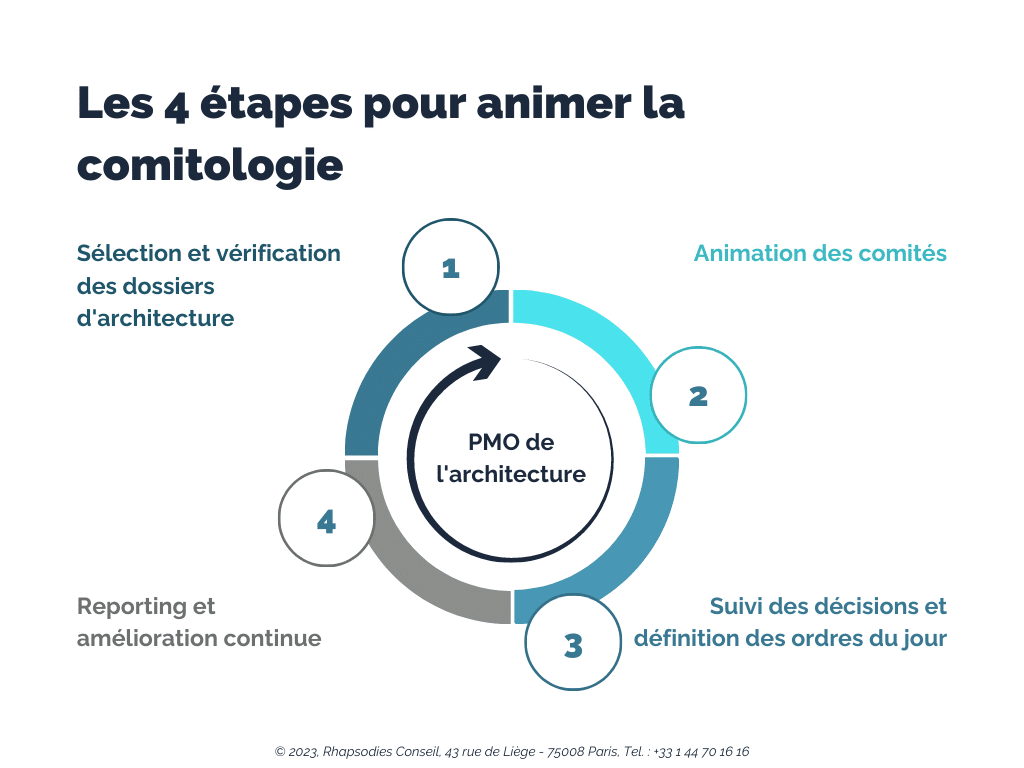
Eh bien, en s’appuyant sur le PMO de l’architecture !
Le PMO de l’architecture : cet acteur clé qui rend vos comités efficaces et productifs
Qui est le PMO de l’architecture ?
Ce terme de “PMO” a été dévoyé et il peut paraître n’être qu’un scribe qui n’apporte pas de vraie valeur ajoutée. Notre conviction chez Rhapsodies Conseil est la suivante : cet acteur doit avoir une culture de l’architecture d’entreprise. Il peut alors faire tellement plus pour l’équipe architecture que compléter un fichier excel une fois par mois !
Il dispose ainsi de nombreuses compétences :
bonne connaissance du SI
maîtrise de la gouvernance de l’architecture,
bon relationnel,
compréhension de l’organisation et du rôle de l’équipe d’architecture,
compréhension des enjeux projets,
connaissance des dossiers d’architecture et des modèles,
techniques d’animation de réunions.
C’est pourquoi il est le plus à même d’animer la comitologie d’architecture et de la rendre intéressante pour l’ensemble des participants, décideurs y compris.
La première activité du PMO de l’architecture : sélectionner et vérifier les dossiers d’architecture
C’est lui qui propose un ordre du jour en fonction de la maturité et du niveau d’urgence des dossiers d’architecture. Il vérifie que ceux-ci sont bien complets avant leur passage en comité. Il comprend les enjeux et peut donc appuyer les différents architectes dans la préparation de leurs dossiers. Il dispose aussi de templates de dossiers d’architecture afin de guider les architectes nouvellement arrivés dans la rédaction de leurs premiers dossiers.
Une bonne préparation avec des attendus précis, dont le PMO de l’architecture est le garant, permet d’éviter bien des désillusions en comité… Et de devoir à de nombreuses reprises rapporter les mêmes éléments complémentaires devant des participants qui ont oublié une bonne partie du sujet…
Le PMO de l’architecture est aussi en charge de l’animation des comités le jour J
L’animation des comités en tant que tels fait également partie de son rôle : il partage l’ordre du jour, suit le bon déroulement du comité, recueille les avis en séance et prend les notes explicatives. Il établit le relevé de décision et partage le compte-rendu aux différents participants.
Il peut aider à remettre le comité sur le droit chemin quand les échanges s’enlisent.
Un suivi est mis en place par le PMO pour que les décisions ne restent pas lettre morte
Suite aux comités, il réalise le suivi des dossiers en fonction des décisions :
passage en mode projet,
programmation d’un deuxième passage du dossier,
études à refaire ou à compléter.
Il établit donc les ordres du jour des prochains comités.
Ce suivi fin des ordres du jour permet d’éviter ce que l’on voit parfois :
un ordre du jour déformé car il a été mal compris par la personne chargée du suivi,
la présentation d’un sujet devant des décideurs qui ont oublié l’avoir demandé.
Il peut identifier les décisions qui donnent lieu à de la dette et en faire le suivi.
De plus, connaissant les différents dossiers en cours, il maîtrise les dépendances entre les sujets. Il est donc à même de prévenir les architectes dont les sujets peuvent être impactés par les décisions du comité. Le PMO de l’architecture ayant une vision globale de l’avancement des sujets, il peut créer du lien entre les architectes. Cela permet aussi d’assurer que l’ensemble des décisions prises lors des comités restent cohérentes.
Le PMO de l’architecture participe également à l’amélioration continue de la gouvernance de l’architecture
Enfin, son rôle transverse lui permet de construire le reporting de la comitologie : il suit le nombre de dossiers qui passent en comité, les décisions et les avis émis… Il peut alors proposer des améliorations de la comitologie afin d’optimiser la gouvernance de l’architecture. Il pourra donc vous aider à ajuster la comitologie si nécessaire en fonction de ce qu’il observe en comité et des issues des présentations.
J’ai tenu ce rôle pendant 1 an et eu la chance de travailler avec des collègues qui avaient aussi tenu ce rôle. J’espère que cette synthèse vous sera utile et que vous connaissez désormais mieux le PMO de l’architecture, cet acteur qui garantit le succès de vos comités. N’hésitez pas à nous contacter pour échanger sur vos retours d’expérience.
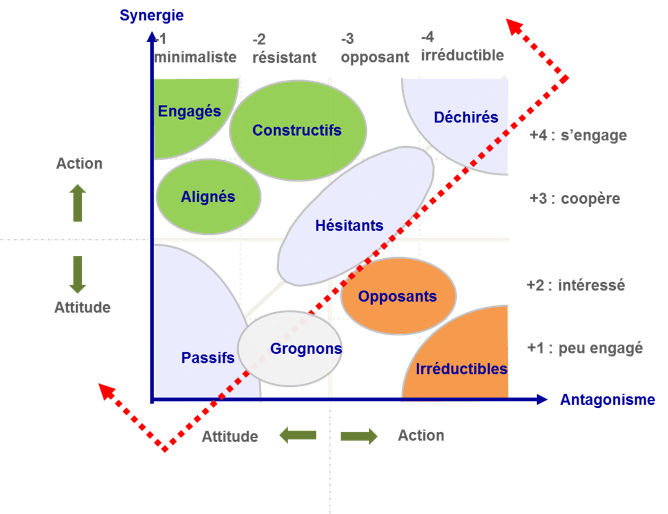
Cet outil, issu de la Socio-dynamique, permet d’identifier le niveau d’adhésion des partenaires (collaborateurs impactés) d’un projet. Elle est très pertinente pour évaluer les impacts d’une transformation et d’envisager une démarche d’accompagnement au changement. Simple à appréhender, mais pas si simple à exploiter, nous l’avons appliqué aux Avengers pour illustrer de manière ludique son utilisation.
Dans un projet de transformation, nous étudions quelquefois l’environnement avant de pouvoir proposer une stratégie de conduite du changement. Nous disposons de plusieurs outils pour identifier les potentiels contributeurs du projet de changement et assurer la réussite de ce dernier. Dans l’un de ces outils, nous retrouvons la matrice socio dynamique des acteurs :
Mais qu’est ce que c’est ? Comment procéder avec cette matrice ?
Et si nous tentions d’appliquer cette matrice à un sujet culturel, pouvant intéresser les plus grands comme les plus petits, je veux bien sûr parler des super-héros ! Marvel nous procure depuis des années la quantité nécessaire d’informations pour pouvoir mettre en œuvre cette matrice ; je vous propose donc de faire une analyse socio dynamique d’acteurs Marvel lors du projet de Thanos.
Quel est le projet ? Qui le porte ?
Pour rappel, quel est donc ce projet en 1 phrase ? Thanos désire recueillir les six pierres d’infinité (ayant le plus de pouvoir dans l’univers) pour exaucer son vœu, qui plus est, supprimer la moitié de l’univers pour rétablir l’équilibre, en un claquement de doigts. Le projet des super-héros est donc d’arrêter Thanos.
[SPOILER ALERT] Les super-héros tentent par le combat d’arrêter Thanos mais il est déjà doté d’une puissance inimaginable. Dr Strange constate, grâce à la pierre d’infinité du temps, que les Avengers n’ont qu’une seule chance sur plusieurs millions de l’emporter. Cependant, Thanos parvient à réunir les pierres et élimine la moitié de l’univers. Les super héros, plus de 4 ans après le claquement de doigt de Thanos, parviennent à remonter dans le temps pour réunir les 6 pierres d’infinité. Durant le combat final, Dr Strange rappelle à Iron Man qu’ils n’ont qu’une seule chance de l’emporter, le conduisant à accepter son sacrifice en utilisant lui-même les pierres d’infinité pour détruire Thanos.
Passons maintenant en revue l’ensemble des acteurs concernés par notre matrice :
Maintenant que nous avons identifié notre population, nous allons passer à l’étape suivante : la récolte d’informations.
Comment procéder à l’analyse sociodynamique ?
Généralement, nous débutons par des entretiens avec des personnes ciblées en rapport avec le projet final (les populations impactées, les différents métiers, statuts, les localisations différentes). Dans ce contexte cinématographique, nous avons re-visionné la saga Marvel pour cerner chacun des personnages et identifier leurs comportements, vis-à-vis du projet d’arrêter Thanos pour sauver l’univers.
Nous identifions donc les profils et postures de chacun des personnages en rapport avec l’objectif du projet ; ses tâches, ses réactions, ses collaborations. L’objectif de la matrice sociodynamique n’étant pas de mettre les personnes dans des cases, mais bien de répartir les populations par ambition afin de construire nos actions de changement ensuite (formation, communication, co-construction, coaching éventuels). Ce livrable est donc à prendre avec des pincettes et à ne faire circuler qu’à une population très restreinte et engagée dans l’accompagnement du changement en cours, pour la simple et bonne raison que nous nous basons principalement sur du ressenti et que la matrice peut être interprétée de plusieurs manières.
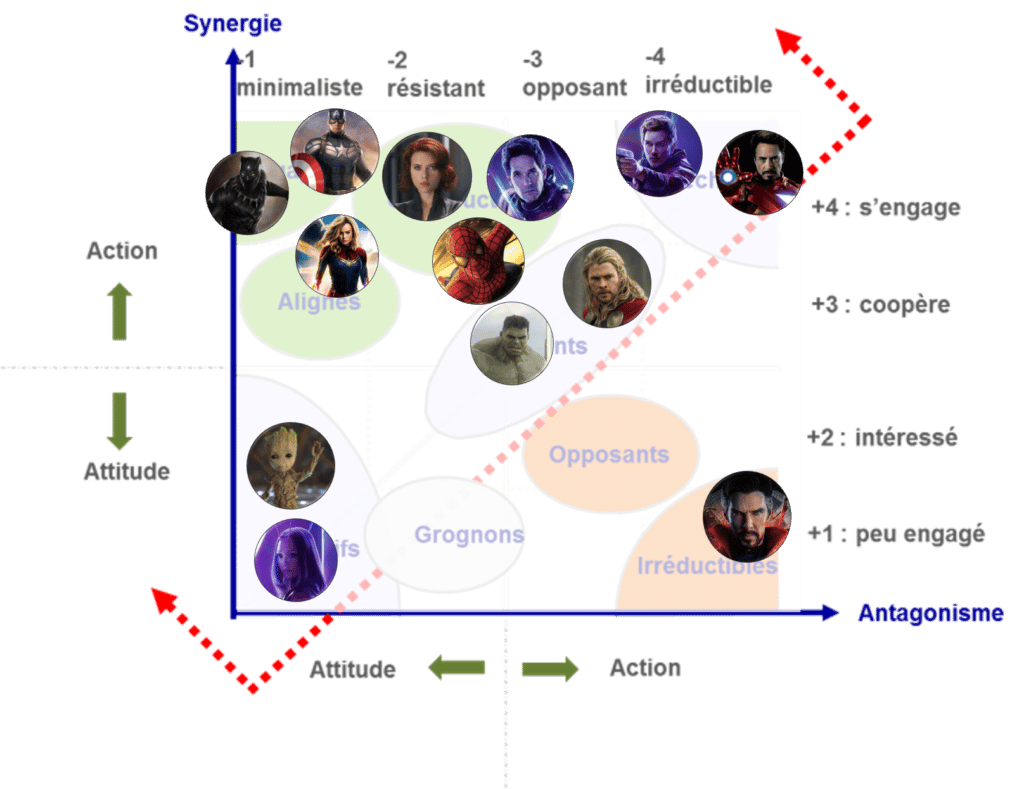
Voici le résultat de notre analyse dans le cas des Avengers :
Captain America (Steve Rogers) : Leader charismatique doté d’une force surhumaine, fin stratège militaire ayant le sens du sacrifice. Il se prend la tête avec Iron man car il a tendance à faire passer son équipe avant le collectif. Il n’oublie pas la mission mais il ne laissera personne derrière, même si ça compromet les objectifs principaux de la mission (cf. son ami Bucky, le soldat de l’hiver, cf. Wanda). C’est donc un “engagé”.
Iron Man (Tony Stark) : Génie électron-libre et égocentrique, ingérable, leader dans ses idées. Quand il a un projet en tête, il le met en œuvre peu importe l’avis des autres, et les risques du projet. Gros sens du sacrifice. Bourreau du travail. C’est un « déchiré ».
Black Widow (Natasha Romanoff) : Soldat redoutable, elle suit principalement les ordres, qui plus est, ceux de sa hiérarchie. Elle fait partie d’une « équipe », pour autant elle n’hésitera pas à avoir recours à son libre arbitre pour suivre une cause qu’elle estime juste. Elle est “constructive”.
Thor : Dieu du tonnerre doté d’un brushing incroyable, il a l’âme d’un leader mais ne veut pas l’être. Il a une grosse voix mais reste un “hésitant”. Il suit le groupe.
Hulk (Bruce Banner) : Génie se battant avec lui-même. Bruce Banner serait plutôt un suiveur, un intellectuel qui apporte des solutions à l’équipe alors que Hulk, quasiment immortel, reste un suiveur par rapport à un collectif afin de mettre ses capacités physiques au service des autres. Il est plus ingérable quand il est Hulk. C’est un “hésitant”.
Dr Strange : Focalisé sur la mission à long terme (protéger le monde et la pierre du temps qu’il détient) uniquement. Il n’hésite pas à faire passer au second plan tout autre priorité (la sécurité de son équipe) et à enfreindre des règles qu’il revendique par ailleurs s’il considère que cela peut mener à la réussite de son objectif à long terme. Il ne dévoile pas sa stratégie par peur de la faire échouer. Il se fiche de toute validation du groupe. C’est lui qui amène le projet à sa réussite de façon “dirty”. C’est un « irréductible ».
Captain Marvel : Pouvoir cosmique au service des autres. Elle est occupée par les autres problématiques galactiques et n’est pas très présente. C’est un “aligné”.
Starlord (Peter Quill) : Mi humain, mi celeste. Il est bien dans un groupe et se sent porteur à l’intérieur. Il cherche l’approbation des autres tout le temps et devient un élément “déchiré” quand il tombe amoureux de Gamora. Il va mettre à risque tout le plan pour tuer Thanos pour Gamora.
Groot :“Passif”, il collabore.
Mantis :“Passive”, elle collabore.
Ant-man (Scott Lang) : Il a de très bonnes idées mais ne sait pas comment les mettre en œuvre. Il est fan de Steve Rogers et suit les ordres du collectif. C’est un “constructif”.
Spider man (Peter Parker) : Pris sous l’aile d’Iron Man, ce jeune garçon est prêt à tout pour qu’on soit fier de lui. Il s’engage dans le collectif et a un sens du sacrifice. Il est un “constructif” car il n’écoute pas tout le temps les demandes qu’on lui fait.
Black Panther (t’challa) :“Engagé” pour sa nation et pour le projet !
Visualisation de l’analyse sur la matrice sociodynamique :
Le livrable : la matrice sociodynamique
La matrice n’est pas le genre de livrable à envoyer par mail sans voix off. Une présentation de toute la démarche et des réflexions menant à ces résultats sont nécessaires pour la compréhension du chef de projet ou du sponsor.
Toutes les théories de conduite du changement et de gestion de projet nous amènent très souvent, selon le contexte, à nous concentrer sur les “engagés” dans le projet et le ventre mou (nous y retrouvons les passifs, les hésitants notamment). Toutefois, d’autres pratiques d’accompagnement amèneraient à se concentrer sur les « irréductibles » et les “déchirés” pour la simple et bonne raison qu’ils tiennent un pouvoir. Ils ne sont pas d’accord et ils sont leaders là-dedans. Ils voient les changements sous un autre prisme et il est dommage de laisser de côté des éléments de réflexion pouvant mener à une réussite collective. Ils détiennent souvent la clé de la réussite du projet (au lieu de seulement réduire leurs postures à du sabotage).
Il est intéressant de constater que c’est ce qu’il se passe dans cette matrice Marvel : le projet de Thanos échoue grâce au sacrifice d’Iron man et d’une information si fortement retenue par Dr Strange. Etonnant non ? Ils étaient pourtant aux antipodes de la collaboration “classique”, pour autant, ils communiquent. L’ensemble des Avengers participent et ont une place très importante dans le projet, comme chacun des salariés d’une entreprise. La réussite finale du projet est la connivence de tous ces acteurs, humains, avec leurs propres problématiques et leurs propres manières de fonctionner. Avons-nous quelques pratiques et idées reçues à ruminer lors de nos prochaines missions ? Bien sûr, nous sommes sur l’exemple d’un contexte cinématographique, mais pensez-vous que cela s’éloigne vraiment de la réalité ?
L’objectif premier est d’attiser la réflexion de fond sur la gestion d’un changement ou d’un projet afin d’accompagner nos clients de la manière la plus pertinente possible. Tout l’environnement et chaque individu détient une force qu’il peut mettre à disposition du projet.
L’exercice tend à avoir une vue plus systémique et plus humaine, bien que la récolte d’informations reste très subjective.
Il en est de même en application aux Avengers, chaque fan des Marvel pourraient avoir une perception différente et ne pas être d’accord avec le positionnement des Avengers dans la matrice qui vient d’être effectuée. Etes-vous toutefois d’accord avec l’analyse finale ? Débattre et se concentrer sur l’environnement systémique d’un projet mène à des actions plus ciblées. Le deuil, les erreurs, les changements de dernière minute, les imprévus font partie d’un projet, c’est ce que nous pouvons remarquer également sur plusieurs films Marvel en rapport avec le projet d’arrêter Thanos. Facile à dire, difficile à mettre en place, la matrice sociodynamique est une aide à la prise de recul et c’est pour cela que nous accompagnons nos clients si bien, nous veillons à tous les éléments d’un projet, son histoire comprise.
Disposer d’une bonne connaissance client est la pierre angulaire d’une expérience client réussie. Il s’agit du premier facteur clé de succès de l’omnicanalitéque nous avions évoqué dans un précédent article.
L’omnicanalité place le client et ses points de contacts au centre de la stratégie d’expérience client. C’est à partir de la connaissance du client que se définit l’ambition de marque d’une entreprise orientée client. Les points de contact offerts sont alors conçus pour répondre à cette promesse de marque. L’orientation produit n’est aujourd’hui plus d’actualité ; l’orientation client remet le client au centre des premières préoccupations de l’entreprise. En outre, l’orientation client suppose naturellement de bien connaître son client.
Nous comprenons ainsi l’enjeu de disposer d’une connaissance client pertinente et complète.
Mais que signifie bien connaître son client ? Comment se construit cette connaissance client ?
La connaissance client est un vaste domaine que nous vous proposons d’explorer dans cet article.
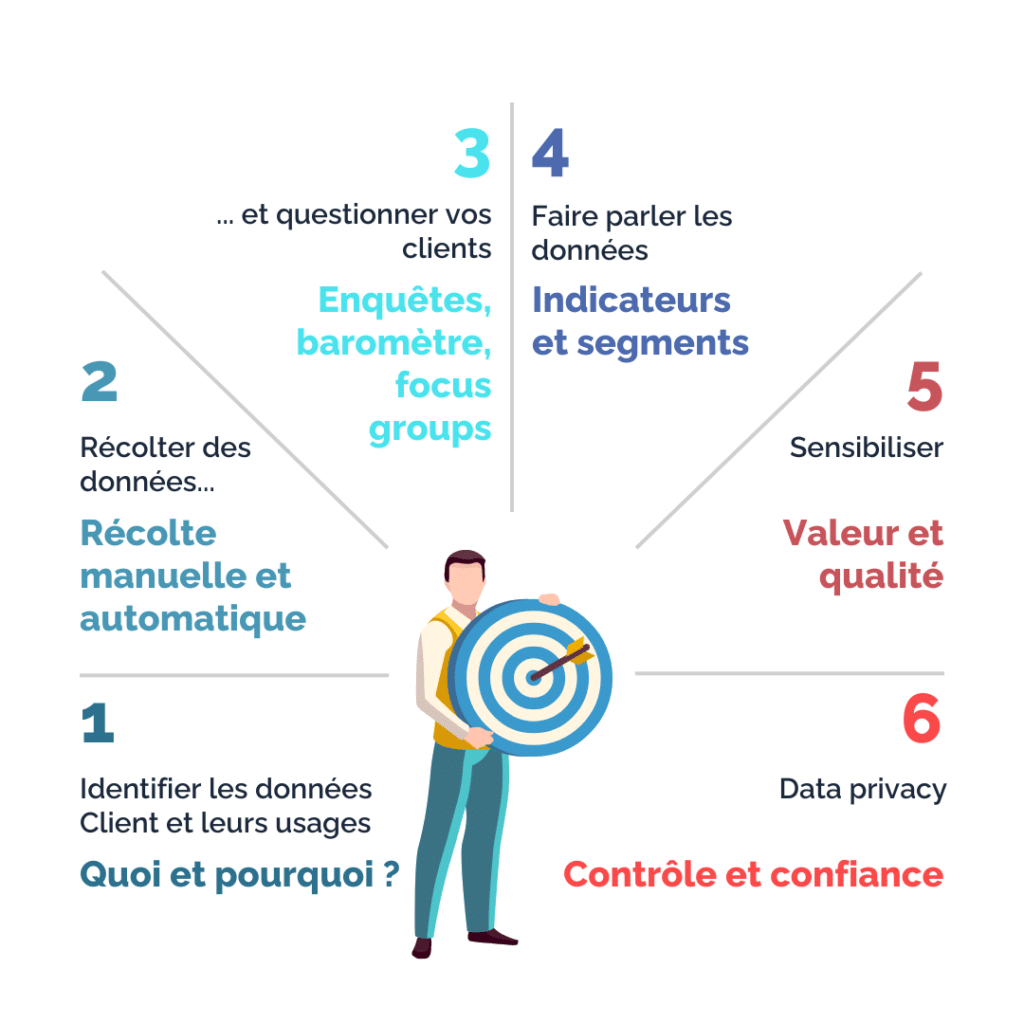
1. Identifier les données utiles et mettre en place des mesures de collecte ciblées
Les données client identifiées comme utiles peuvent couvrir un large éventail : données démographiques, de qualification, de consommation, de navigation, de sollicitation, de retours aux sollicitations, etc. Selon le secteur d’activité et la dimension du parc clients, ces données peuvent occuper un volume plus ou moins important. Dans l’ère du numérique durable et dans un souci d’efficacité opérationnelle, il devient aujourd’hui essentiel de bien sélectionner les données utiles qui permettent de répondre aux problématiques métier définies du marketing et du commerce. L’objectif est effectivement de cibler la « good Data », à la différence de la « full Data ».
Des mesures de collecte doivent ensuite être mises en place pour récupérer cette « good Data ». Ces données sont récupérées de deux manières : manuellement ou automatiquement. Les mesures de collecte manuelles adressent les collaborateurs amenés à interagir avec les clients. L’interaction avec le client est une opportunité à ne pas rater pour recueillir de l’information pertinente sur votre client : ses données de contact, ses centres d’intérêts, ses préférences de canal, etc. Les mesures de collecte automatique concernent les systèmes du front ou d’applications tierces, qui récupèrent automatiquement des données. Ces données sont par exemple issues du tunnel d’achat web ou d’une connexion d’un client sur son espace. Il peut s’agir de cookies (récoltés bien entendu avec consentement, à noter que l’utilisation des cookies tiers ne sera bientôt plus autorisée). Dans ce cas, les parcours doivent être réfléchis en amont pour identifier quelles données sont à récupérer et permettre par la suite cette récupération.
2. Demander directement à vos clients ce qu’ils souhaitent !
Si vous souhaitez connaître ce que pensent vos clients, leurs impressions, ou leurs attentes (en termes de produit, mais aussi d’expérience), il suffit parfois de leur demander ! Pour cela, plusieurs techniques existent.Au niveau du client, il est par exemple possible d’insérer sur son parcours web des questions bien choisies qui permettent ainsi de lui proposer les pages, les offres ou produits répondant à son besoin. Les réponses à ces questions sont par ailleurs enregistrées et pourront servir pour la prochaine visite. Attention bien entendu à ne pas alourdir le parcours. C’est une technique à utiliser avec parcimonie. Il est également recommandé d’envoyer un questionnaire de satisfaction après chaque interaction afin de récupérer le retour du client sur son expérience. Ce type d’enquête peut être qualifié de transactionnelle, car elle fait suite à une transaction entre le client et l’entreprise.
Au niveau de votre base de clients, une bonne pratique consiste à régulièrement la sonder, avec des enquêtes ou des baromètres. Ces enquêtes permettent d’avoir un avis général sur la marque et non sur un cas d’usage précis. Elles ne sont en outre pas nominatives. Il s’agit là d’enquêtes relationnelles. Les résultats sont globaux, ils donnent une température générale d’appréciation de votre marque. Les indicateurs les plus classiques issus de ce type d’enquête sont les taux de satisfaction et le NPS (Net Promoter Score). Ce type de données, marqueurs de la perception de vos clients, sont appelées des « Insights ».
Pour affiner vos produits ou parcours ou trouver des solutions à vos points de douleur, il reste enfin la possibilité de convier un échantillon représentatif de votre base clients pour un ou plusieurs ateliers de travail. Il s’agit là de Focus Groups. Les travaux en direct avec des clients sont très bénéfiques, car ils permettent de mettre en évidence des impressions ou intuitions faussées, parfois nourries au sein de l’entreprise en raison d’un manque de prise de recul.
3. Faire parler vos données client : calculs et rapprochements
Les nouvelles technologies ont évolué extrêmement vite ces dernières années, pour permettre aux entreprises de stocker et d’analyser des données dont le volume croît de manière exponentielle. C’est ainsi qu’est apparue la notion de « Big Data ». Les nouveaux usages, dont la digitalisation de parcours, sont entre autres à l’origine de ce volume grandissant. Ces données sont souvent éparpillées dans plusieurs systèmes (DMP, CRM, ERP, ITSM,…), ce qui nécessite un travail de centralisation et de traitement pour les rendre exploitables. Bien entendu, les modalités de stockage et de purge de ces données doivent être réfléchies pour répondre aux enjeux du numérique durable et aux contraintes RGDP qui sont abordées plus bas dans cet article. Ces données (bien choisies en amont) constituent tout de même une vraie mine d’or pour qui sait les faire parler.
Faire parler les données, c’est construire de nouvelles données à partir de données dites « brutes ». Il peut s’agir d’indicateurs (ex : panier moyen), de segments (ex : RFM – Récence, Fréquence, Montant), ou de simples calculs (ex : nombre de mois depuis le dernier achat). Le calcul de ce type de données fait suite à la réflexion des équipes du marketing client. Ce type de données vient ainsi soutenir leur stratégie client. L’analyse poussée de ces données de masse, opérée par des spécialistes tels que des Data Scientists, permet aussi d’identifier des rapprochements qui peuvent parfois être surprenants. Le cas d’école le plus connu est la mise en évidence du lien entre l’achat de couches pour bébé et de bières par les jeunes papas dans une grande surface américaine. L’analyse poussée de gros volumes de données permet donc de décrypter finement les comportements client, et déceler des clés de compréhension pour favoriser le cross-selling, l’up-selling ou simplement améliorer l’expérience client, et ainsi fidéliser.
4. Bien visualiser et communiquer vos données pour mieux décider
La mise en visualisation des données est une étape cruciale à ne pas négliger. Une fois les données client récoltées et travaillées pour mieux comprendre le comportement de vos clients et leurs attentes, il est nécessaire de pouvoir visualiser ces données régulièrement pour identifier les évolutions et ajuster votre stratégie de relation client. Pour cela, deux éléments clés sont à déterminer en amont : les indicateurs à afficher et les modalités de mise à disposition. Le suivi de ces indicateurs sera facilité par la simplicité d’accès et de lecture de ceux-ci.
Le suivi des données client est primordial pour l’aide à la décision sur les sujets orientés client. D’une part, il permet d’identifier l’impact des actions marketing sur la base clients et d’en évaluer les performances. D’autre part, il permet d’identifier les ajustements à réaliser dans le calcul des indicateurs, comme une évolution devenue nécessaire de la segmentation comportementale. Enfin, il est important de diffuser régulièrement certains indicateurs orientés client au sein de l’entreprise, afin de sensibiliser les collaborateurs sur la valeur de la donnée et son rôle dans l’amélioration de l’expérience client.
5. Sensibiliser l’ensemble des collaborateurs sur la valeur des données client
L’acculturation à la valeur des données client est nécessaire pour sécuriser, d’une part la récolte des données, et d’autre part le bon usage de ces données.
Les collaborateurs en interaction avec les clients doivent comprendre les enjeux de la récolte des données et de leur qualité. Comprendre ces enjeux favorise leur engagement et leur implication dans cette récolte dont ils sont les premiers acteurs. Ceci est d’autant plus vrai s’ils bénéficient eux-mêmes dans leur quotidien de l’utilisation de ces données pour optimiser leur interaction avec le client. Ainsi la compréhension des enjeux fait partie intégrante de ce processus d’acculturation à la valeur des données. Ce processus doit bien entendu comporter un volet sur la qualité des données, pour des raisons évidentes d’utilisabilité.
La sensibilisation au bon usage de la donnée est également un facteur clé essentiel d’une entreprise orientée client. Comme évoqué plus haut, l’orientation client place le client au centre de sa stratégie. Cela suppose de bien le connaître pour planifier les bonnes actions : il s’agit alors d’être « data-driven ». La direction joue bien entendu un rôle prépondérant dans cette acculturation. Elle doit insuffler au sein de son organisation cet état d’esprit au travers de principes établis qui permettent de poser le cadre, mais également au travers d’une organisation décloisonnée et de formations spécifiques.
6. Prendre en compte les contraintes réglementaires et en faire une force !
Cet article évoque toutes les mesures nécessaires pour disposer d’une connaissance client complète et pertinente sur la base de données client. Mais qu’en est-il des contraintes réglementaires sur l’utilisation de ces données ?
Le RGPD (Règlement Général sur la Protection des Données), appliqué depuis 2018 en Union Européenne, pose un cadre sur la récolte et l’utilisation des données client. Ce règlement a vocation à permettre au citoyen européen de contrôler l’utilisation de ses données personnelles. Le RGPD entre ainsi en jeu dès la récolte des données client, puisque celle-ci est soumise au consentement du client. Le RGPD encadre par la suite l’utilisation de ces données et les finalités associées, ainsi que les modalités de conservation, de sécurité et les droits des personnes sur leurs données (ex : accès, rectification, suppression, portabilité). Ce règlement a donné naissance à une activité encore relativement récente au sein de l’entreprise : la Data Privacy.
Souvent perçus comme une contrainte par les acteurs du marketing client, les enjeux de la Data Privacy visent cependant la transparence sur les actions menées par les entreprises sur la base des données client. Le client est donc rassuré et la Data Privacy est ainsi transformé en véritable vecteur de confiance ! Pour cela, il est essentiel de maîtriser l’ensemble des modalités relatives à la Data Privacy, pour limiter les contraintes et interagir pertinemment avec les clients dont le consentement a été obtenu.
Vous avez maintenant toutes les clés pour bien connaître vos clients ! Vous l’aurez compris, bien connaître vos clients implique aussi d’une part de bien maîtriser votre portefeuille de données, et d’autre part de mettre en place une architecture qui optimise son usage. Pour en savoir plus sur le sujet, nous vous invitons à consulter nos expertises Transformation Data et Architectures.
Les projets d’API Management sont fondamentalement simples. Il s’agit de faire échanger des données d’un système A vers un système B. Mais c’est sans compter sur le fait qu’un projet d’API Management fait intervenir un grand nombre d’acteurs, ce qui engendre de la complexité.
Les acteurs de la gestion des API
Pour commencer, nous pouvons énumérer les acteurs typiques impliqués :
Le CxO qui a décidé que les API faisaient partie de la stratégie de l’entreprise, mais qui ne vous donne pas un parrainage très fort ;
Les autres CxOs qui ont d’autres priorités que les APIs ;
L’équipe A qui veut accéder à des données, mais qui n’a pas le temps de s’occuper de vous ;
L’équipe B qui est responsable de données exposées, mais qui n’a pas de temps à vous consacrer ;
Les développeurs de la solution qui veulent accéder aux données ;
Les développeurs de la solution qui exposent les données ;
Les membres de l’équipe de gestion de l’API ;
Et au moins un architecte, bien évidemment !
On voit bien qu’il y a une multiplicité d’acteurs, qui vont tous pousser dans leur propre direction. Et on perd rapidement toute forme de coordination si :
L’équipe de gestion de l’API ne joue pas un rôle de coordination constructif ;
Il n’y a pas de parrainage des membres du CxO.
Le défi de la complexité
Il est donc nécessaire de maîtriser la complexité de l’entreprise et la complexité due à ses interactions et à ses acteurs. En effet, selon la théorie des systèmes complexes, la complexité du système « entreprise » réside dans le nombre élevé d’acteurs et le nombre élevé d’interactions entre eux !
Ce qui est complexe, ce n’est pas de faire une API avec un acteur, mais de faire une API avec, par et pour de multiples acteurs.
Il est donc fondamental de :
Chercher à aligner tous les acteurs dans la même direction par une très bonne communication, des explications sur les bonnes pratiques, etc. ;
Faire de l’équipe de gestion des API un point d’échange central pour toute conversation sur les API ;
Infuser les connaissances dans toutes les équipes autant que possible.
A partir de là, on peut déduire deux prérequis :
Une gouvernance claire, simple et efficace est essentielle ;
Un sponsorship solide doit garantir l’alignement de l’entreprise sur un projet d’API.
Le mode d’organisation le plus souvent utilisé est le mode de gouvernance que j’appelle open source. L’équipe API encadre, guide, aide, soutient, mais surtout permet à chacun de contribuer facilement et efficacement.
De ces activités et défis ainsi énumérés, nous pouvons ainsi déduire deux types d’activités.
Deux typologies d’activités de l’équipe API
On peut ainsi diviser les activités d’une équipe API en deux types d’activités : les activités régaliennes et les activités étendues. En effet, la gouvernance d’une équipe de gestion d’API doit fixer un cadre dans lequel tous les acteurs impliqués dans les API doivent s’inscrire, afin que tous les acteurs puissent pleinement travailler.
Les activités régaliennes
Nous pouvons appeler activités régaliennes les activités pour lesquelles l’équipe de gestion des API a toute l’autorité et ne peut être supprimée. Dans ces activités, nous pouvons mettre :
La mise en œuvre et l’administration technique de la plateforme API Management.
La définition des meilleures pratiques de gestion d’API.
Les formats des ateliers de définition des API – pour passer de réunions interminables et contre-productives à des réunions efficaces et productives. J’ai personnellement réduit par 4 le nombre d’ateliers, juste en repensant la façon dont nous les animons !
L’organisation des ateliers API – Pour être le moteur des sujets API, mais libre à l’équipe API Management de laisser les équipes concernées s’organiser elles-mêmes si elles sont suffisamment autonomes.
La gestion de la formation et de la communication – Pour assurer l’adhésion des équipes, et pour démontrer la valeur ajoutée des équipes d’API Management.
Les activités étendues
Certaines activités doivent cependant être menées non pas sur un mode purement régalien mais sur un modèle beaucoup plus collaboratif, car après tout, il s’agit d’organiser les échanges entre au moins deux systèmes :
Définir et gérer le cycle de vie des API avec les projets et les architectes fonctionnels – Même si l’équipe API a le dernier mot, elle reste au service des projets et du métier ! Ne l’oubliez jamais !
Travailler avec les architectes sur l’alignement des besoins en API dans une feuille de route claire – Les architectes sont censés avoir une vision à moyen et long terme des besoins futurs, les équipes API sont censées s’aligner sur eux !
Outiller pour les développeurs afin d’apporter les bons outils et cadres de travail – Dire à un projet « allez-y et faites l’API » n’est pas suffisant ! Dites-le à un projet Legacy ! C’est aux équipes API de travailler avec les projets pour moderniser la base technique, la distribuer et la partager avec d’autres équipes de développement.
Contribuer à l’idéation avec les métiers pour trouver de nouvelles idées d’API – Le but étant de tirer le maximum de valeur des actifs de l’entreprise.
2 typologies de gouvernance, ou plutôt 2 “curseurs” de gouvernance
Enumérer une liste de tâches n’est pas pour autant équivalent à définir une gouvernance API.
De ces deux typologies d’activités, on remarque que le pattern “décentralisée” revient forcément.
En effet, le mode de gouvernance qu’on pourrait appeler “décentralisée” revient très souvent. Dans ce mode de gouvernance, l’équipe d’API Management a comme but principal de permettre à tout à chacun de contribuer facilement et efficacement. Ainsi, charge à l’équipe API Management de cadrer, orienter, aider, d’apporter du support, mais pas nécessairement d’implémenter et définir les APIs. C’est une logique de gouvernance qui cherche avant tout à permettre aux autres équipes de travailler de manière autonome.
Dans une logique totalement inverse, l’autre mode de gouvernance que l’on rencontre régulièrement est une gouvernance centralisée. Le centre de compétence d’API regroupe alors toutes les compétences nécessaires, et travaille de manière auto-suffisante.
Pour autant, rares sont les entreprises qui mettent en place une gouvernance aussi “marquée” par une de ces deux logiques. Toute la question est de pouvoir s’adapter à l’organisation de l’entreprise et de son SI, mais aussi de s’adapter à la maturité et à l’autonomie des équipes en place. Il faut toutefois bien chercher à autonomiser les équipes, sans quoi il vous sera impossible de “scaler” votre organisation autour des APIs, sans compter les effets de bord d’une logique de tour d’ivoire…
J’ai analysé Pro Santé Connect, un service fort intéressant avec plein de potentiels, réalisé dans les règles de l’art et qui suit les standards actuels du domaine de l’authentification. Mon retour : j’adore ! (oui bon laissez-moi mes kiffes hein…).
Pro Santé Connect, c’est quoi ?
Il s’agit d’un service d’authentification et d’identification des professionnels de santé.
Ce service est construit sur les bases des standards du marché actuel : OAUTH2 pour l’authentification et, cerise sur le gâteau, de l’OpenID Connect pour avoir le complément d’information d’identification qui va bien : que pouvons-nous demander de plus ?
À quoi sert Pro Santé Connect ?
Ce service permet qu’un organisme d’état certifie :
La personne qui est en train de s’authentifier est bien celle qu’elle dit être, avec des preuves à l’appui ;
La personne qui accède à mon site dispose bien de certaines caractéristiques qui ne viennent pas d’une auto-déclaration mais d’informations recensées et vérifiées au niveau des organismes d’État ;
Ces informations sont transmises de façon sécurisée et non corruptibles (jetons JWT signés).
Pour être clair, il fonctionne un peu comme France Connect, mais son caractère médical, associé aux caractéristiques spécifiques de la profession, sécurisé et complété par l’OiDC, ouvre la possibilité d’exploiter beaucoup plus d’informations : quel est son lieu de travail ? dans quel établissement ? quelle spécialisation médicale le professionnel pratique ? et d’autres encore…
Pour finir, ces informations peuvent être propagées à des applications tierces, avec un simple transfert de jeton sécurisé, ce qui permet d’éviter les surcoûts et les efforts d’authentification à plusieurs niveaux.
Et alors, on en pense quoi de ce service d’authentification ?
J’adore. Je n’aurais pas fait mieux, ni pire… Techniquement ça a l’air de tenir la route et même plus.
L’utilisation de standards reconnus et plébiscités par le marché, alors que personnellement j’en ai ch…, pardon bavé… Veuillez m’excuser, j’ai eu un peu de mal dans le passé avec des standards d’interconnexion mal documentés, incompréhensibles… Ils étaient pondus par des organismes publics qui, dans un souci de sécurisation, avaient rédigé des documents illisibles et impossibles à utiliser. Bref, je pense qu’ils n’ont jamais rencontré de problèmes de sécurité, vu que personne n’a dû réussir à les implémenter…
Dans le cas de Pro Santé Connect, ceux qui ont déjà implémenté de l’OAUTH2 ou de l’OiDC, se retrouvent dans un cadre familier, clair, bien documenté, enfin un vrai plaisir (bon au moins de mon point de vue hein… laissez moi ce plaisir…). Pour les autres, ces standards sont tellement bien documentés que, avec un peu d’effort de lecture, on peut vite en comprendre les concepts.
Des informations certifiées, complètes, simples à lire ? Il est où le pépin ?
C’est beau tout ça, magnifique, dans ce monde parfait nous n’avons plus rien à craindre ! Plus de questions à se poser ! Nah…
Bon ce n’est pas forcément le cas, une alerte reste d’actualité et se base sur un concept cher à pas mal de DSI : la qualité des données traitées et leur fraîcheur.
Si le service a une chance de marcher tel qu’il est présenté, la collecte des informations devra se faire :
Dans des délais très courts, à partir du changement de situation du professionnel de santé ;
Avec une qualité irréprochable.
Or, la fusion de plusieurs référentiels dans un seul (le RPPS), en cours, plus l’effort que l’ANS semble mettre dans cette initiative, laissent présager des bons résultats.
En conclusion
La voie est la bonne, techniquement pas de surprise, une implémentation reconnue et éprouvée, un service qui nous plaît !
Et maintenant nous attendons le même service pour les personnes physiques, en lien avec Mon Espace Santé et les domaines associés !
Dans un récent post de blog, le Gartner prévoit que d’ici 2030, 60% des données d’entrainement des modèles d’apprentissage seront générées artificiellement. Souvent considérées comme substituts de qualité moindre et uniquement utiles dans des contextes réglementaires forts ou en cas de volumétrie réduite ou déséquilibrée des datasets, les données synthétiques ont aujourd’hui un rôle fort à jouer dans les systèmes d’IA.
Nous dresserons donc dans cet article un portrait des données synthétiques, les différents usages gravitant autour de leur utilisation, leur histoire, les méthodologies et technologies de génération ainsi qu’un rapide overview des acteurs du marché.
Les données synthétiques, outil de performance et de confidentialité des modèles de machine learning
Vous avez dit données synthétiques ?
Le travail sur les données d’entrainement lors du développement d’un modèle de Machine Learning est une étape d’amélioration de ses performances parfois négligée, au profit d’un fine-tuning itératif et laborieux des hyperparamètres. Volumétrie trop faible, déséquilibre des classes, échantillons biaisés, sous-représentativité ou encore mauvaise qualité sont tout autant de problématiques à adresser. Cette attention portée aux données comme unique outil d’amélioration des performances a d’ailleurs été mis à l’honneur dans une récente compétition organisée par Andrew Ng, la Data-centric AI competition.
Également, le renforcement des différentes réglementations sur les données personnelles et la prise de conscience des particuliers sur la valeur de leurs données et la nécessité de les protéger imposent aujourd’hui aux entreprises de faire évoluer leurs pratiques analytiques. Fini « l’open bar » et les partages et transferts bruts, il est aujourd’hui indispensable de mettre en place des protections de l’asset données personnelles.
C’est ainsi qu’entre en jeu un outil bien pratique quand il s’agit d’adresser de front ces deux contraintes : les données synthétiques.
Par opposition aux données « traditionnelles » générées par des événements concrets et retranscrivant le fonctionnement de systèmes de la vie réelle, elles sont générées artificiellement par des algorithmes qui ingèrent des données réelles, s’entraînent sur les modèles de comportement, puis produisent des données entièrement artificielles qui conservent les caractéristiques statistiques de l’ensemble de données d’origine.
D’un point de vue utilisabilité data on peut alors adresser des situations où :
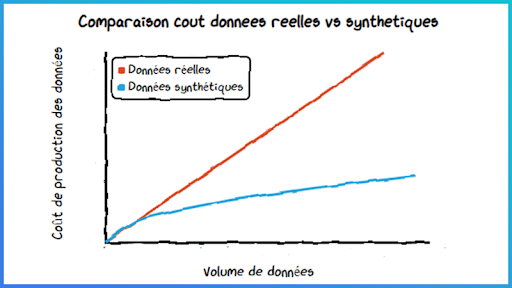
La donnée est coûteuse à collecter ou à produire – certains usages nécessitent par exemple l’acquisition de jeux de données auprès de data brokers. Ici, la génération et l’utilisation de données synthétiques permettent de diminuer les coûts d’acquisition et favorisent ainsi une économie d’échelle pour l’usage data considéré.
Le volume de données existant n’est pas suffisant pour l’application souhaitée – on peut citer les cas d’usage de détection de fraude ou de classification d’imagerie médicale, où les situations « d’anomalie » sont souvent bien moins représentées dans les jeux d’apprentissage. Dans certains cas, la donnée n’existe simplement pas et le phénomène que l’on souhaite modéliser n’est pas présent dans les datasets collectés. Dans ce cas d’usage, la génération de données synthétiques est toutefois à différencier des méthodes de « data augmentation », technique consistant à altérer une donnée existante pour en créer une nouvelle. Dans le cas d’une base d’images par exemple, ce processus d’augmentation pourra passer par des rotations, des colorisations, l’ajout de bruits… l’objectif étant d’aboutir à différentes versions de l’image de départ.
Il n’est pas nécessaire d’utiliser des données réelles, comme lors du développement d’un pipeline d’alimentation en données. Dans ces situations, un dataset synthétique peut être largement suffisant pour pouvoir itérer rapidement sur la mise en place de l’usage, sans se préoccuper de l’alimentation en données réelles en amont.
Mais comme vu précédemment, ces données synthétiques permettent aussi d’adresser certaines problématiques de confidentialité des données personnelles. En raison de leur nature synthétique, elles ne sont pas régies par les mêmes réglementations puisque non représentatives d’individus réels. Les data scientists peuvent donc utiliser en toute confiance ces données synthétiques pour leurs analyses et modélisations, sachant qu’elles se comporteront de la même manière que les données réelles. Cela protège simultanément la confidentialité des clients et atténue les risques (sécuritaires, concurrentiels, …) pour les entreprises qui en tirent parti, tout en levant les barrières de conformité imposées par le RGPD…
Parmi les bénéfices réglementaires de cette pratique :
Les cyber-attaques par techniques de ré-identification sont, par essence, inefficaces sur des jeux de données synthétiques, à la différence de datasets anonymisés : les données synthétiques n’étant pas issues du monde réel, le risque de ré-identification est ainsi nul.
La réglementation limite la durée pendant laquelle une entreprise peut conserver des données personnelles, ce qui peut rendre difficile la réalisation d’analyses à plus long terme, comme lorsqu’il s’agit de détecter une saisonnalité sur plusieurs années. Ici, les données synthétiques s’avèrent pratiques puisque non identifiantes : les entreprises ont ainsi le droit de conserver leurs données synthétiques aussi longtemps qu’elles le souhaitent. Ces données pourront être réutilisées à tout moment dans le futur pour effectuer de nouvelles analyses qui n’étaient pas menées auparavant ou même technologiquement irréalisables au moment de la collecte des données.
L’utilisation de services tiers (ex : ressources de stockage / calcul dans le cloud) nécessitent la transmission de données (parfois personnelles et sensibles) vers ce service. Il en va de même pour le partage de données avec des tiers pour réalisation d’analyses externes. En plus du casse-tête habituel de la conformité, cela peut (et devrait) être une préoccupation importante pour les entreprises, car une faille de sécurité peut rendre vulnérables à la fois leurs clients et leur réputation. Dans ce cas, utiliser des données synthétiques permet de réduire les risques liés aux transferts de données (vers des tiers, des fournisseurs de cloud, des prestataires ou encore des entités hors UE pour les entreprises européennes).
Un peu d’histoire…
L’idée de mettre en place des techniques de préservation de la confidentialité des données via les données synthétiques date d’une trentaine d’années, période à laquelle le US Census Bureau (organisme de recensement américain) décida de partager plus largement les données collectées dans le cadre de son activité. A l’époque, Donald B. Rubin, professeur de statistiques à Harvard, aide le gouvernement américain à régler des problèmes tels que le sous-dénombrement, en particulier des pauvres, dans un recensement, lorsqu’il a eu une idée, décrite dans un article de 1993 .
« J’ai utilisé le terme ‘données synthétiques’ dans cet article en référence à plusieurs ensembles de données simulées. Chacun semble avoir pu être créé par le même processus qui a créé l’ensemble de données réel, mais aucun des ensembles de données ne révèle de données réelles – cela présente un énorme avantage lors de l’étude d’ensembles de données personnels et confidentiels. »
Les données synthétiques sont nées.
Par la suite, on retrouvera des données synthétiques dans le concours ImageNet de 2012 et, en 2018, elles font l’objet d’un défi d’innovation lancé par le National Institute of Standards and Technology des États-Unis sur la thématique des techniques de confidentialité. En 2019, Deloitte et l’équipe du Forum économique mondial ont publié une étude soulignant le potentiel des technologies améliorant la confidentialité, y compris les données synthétiques, dans l’avenir des services financiers. Depuis, ces données artificielles ont infiltré le monde professionnel et servent aujourd’hui des usages analytiques multiples.
Méthodologies de génération de données synthétiques
Pour un dataset réel donné, on peut distinguer 3 types d’approche quant à la génération et l’utilisation de données synthétiques :
Données entièrement synthétiques – Ces données sont purement synthétiques et ne contiennent rien des données d’origine.
Données partiellement synthétiques – Ces données remplacent uniquement les valeurs de certaines caractéristiques sensibles sélectionnées par les valeurs synthétiques. Les valeurs réelles, dans ce cas, ne sont remplacées que si elles comportent un risque élevé de divulgation. Ceci est fait pour préserver la confidentialité des données nouvellement générées. Il est également possible d’utiliser des données synthétiques pour adresser les valeurs manquantes de certaines lignes pour une colonne donnée, soit par méthode déterministe (exemple : compléter un âge manquant avec la moyenne des âges du dataset) ou statistique (exemple : entraîner un modèle qui déterminerait l’âge de la personne en fonction d’autres données – niveau d’emploi, statut marital, …).
Données synthétiques hybrides – Ces données sont générées à l’aide de données réelles et synthétiques. Pour chaque enregistrement aléatoire de données réelles, un enregistrement proche dans les données synthétiques est choisi, puis les deux sont combinés pour former des données hybrides. Il est prisé pour fournir une bonne préservation de la vie privée avec une grande utilité par rapport aux deux autres, mais avec un inconvénient de plus de mémoire et de temps de traitement.
GAN ?
Certaines des solutions de génération de données synthétiques utilisent des réseaux de neurones dits « GAN » pour « Generative Adversarial Networks » (ou Réseaux Antagonistes Génératifs).
Vous connaissez le jeu du menteur ? Cette technologie combine deux joueurs, les « antagonistes » : un générateur (le menteur) et un discriminant (le « devineur »). Ils interagissent selon la dynamique suivante :
Le générateur ment : il essaie de créer une observation de dataset censée ressembler à une observation du dataset réel, qui peut être une image, du texte ou simplement des données tabulaires.
Le discriminateur – devineur essaie de distinguer l’observation générée de l’observation réelle.
Le menteur marque un point si le devineur n’est pas capable de faire la distinction entre le contenu réel et généré. Le devineur marque un point s’il détecte le mensonge.
Plus le jeu avance, plus le menteur devient performant et marquera de points. Ces « points » gagnés se retrouveront modélisés sous la forme de poids dans un réseau de neurones génératif.
L’objectif final est que le générateur soit capable de produire des données qui semblent si proches des données réelles que le discriminateur ne puisse plus éviter la tromperie.
Pour une lecture plus approfondie sur le sujet des GANs, il en existe une excellente et détaillée dans un article du blog Google Developers.
Un marché dynamique pour les solutions de génération de données synthétiques
Plusieurs approches sont aujourd’hui envisageables, selon que l’on souhaite s’équiper d’une solution dédiée ou bien prendre soi-même en charge la génération de ces jeux de données artificielles.
Parmi les solutions Open Source, on peut citer les quelques librairies Python suivantes :
Mais des éditeurs ont également mis sur le marché des solutions packagées de génération de données artificielles. Aux Etats-Unis, notamment, les éditeurs spécialisés se multiplient. Parmi eux figurent Tonic.ai, Mostly AI, Latice ou encore Gretel.ai, qui affichent de fortes croissances et qui ont toutes récemment bouclé d’importantes levées de fond
Un outil puissant, mais…
Même si l’on doit être optimiste et confiant quant à l’avenir des données synthétiques pour, entre autres, les projets de Machine Learning, il existe quelques limites, techniques ou business, à cette technologie.
De nombreux utilisateurs peuvent ne pas accepter que des données synthétiques, « artificielles », non issues du monde réel, … soient valides et permettent des applications analytiques pertinentes. Il convient alors de mener des initiatives de sensibilisation auprès des parties prenantes business afin de les rassurer sur les avantages à utiliser de telles données et d’instaurer une confiance en la pertinence de l’usage. Pour asseoir cette confiance :
Bien que de nombreux progrès soient réalisés dans ce domaine, un défi qui persiste est de garantir l’exactitude des données synthétiques. Il faut s’assurer que les propriétés statistiques des données synthétiques correspondent aux propriétés des données d’origine et mettre en place une supervision sur le long terme de ce matching. Mais ce qui fait également la complexité d’un jeu de données réelles, c’est qu’il capture les micro-spécificités et les cas hyper particuliers d’un cas d’usage donné, et ces « outliers » sont parfois autant voire plus important que les données plus traditionnelles. La génération de données synthétiques ne permettra pas d’adresser ni de générer ce genre de cas particuliers à valeur.
Également, une attention particulière est à porter sur les performances des modèles entrainés, partiellement ou complètement, avec des données synthétiques. Si un modèle performe moins bien en utilisant des données synthétiques, il convient de mettre cette sous-performance en regard du gain de confidentialité et d’arbitrer la perte de performance que l’on peut accepter. Dans le cas contraire où un modèle venait à mieux performer quand entrainé avec des données synthétiques, cela peut lever des inquiétudes quand à sa généralisation future sur des vraies données : un monitoring est donc nécessaire pour suivre les performances dans le temps et empêcher toute dérive du modèle, qu’elle soit de concept ou de données.
Aussi, si les données synthétiques permettent d’adresser des problématiques de confidentialité, elles ne protègent naturellement pas des biais présents dans les jeux de données initiaux et ils seront statistiquement répliqués si une attention n’y est pas portée. Elles sont cependant un outil puissant pour les réduire, en permettant par exemple de « peupler » d’observations synthétiques des classes sous-représentées dans un jeu de données déséquilibré. Un moteur de classification des CV des candidats développé chez Amazon est un exemple de modèle comportant un biais sexiste du fait de la sous représentativité des individus de sexe féminin dans le dataset d’apprentissage. Il aurait pu être corrigé via l’injection de données synthétiques représentant des CV féminins.
On conclura sur un triptyque synthétique imageant bien la puissance des sus-cités réseaux GAN, utilisés dans ce cas là pour générer des visages humains synthétiques, d’un réalisme frappant.
Il est à noter que c’est également cette technologie qui est à l’origine des deepfakes, vidéos mettant en scène des personnalités publiques ou politiques tenant des propos qu’ils n’ont en réalité jamais déclarés (un exemple récent est celui de Volodymyr Zelensky, président Ukrainien, victime d’un deepfake diffusé sur une chaine de télévision d’information).