La location de matériel informatique représente un coût non négligeable pour les entreprises, mais ces dépenses ne sont pas toujours maîtrisées, malgré les processus de contrôle interne. En cause, un manque de communication et de rapprochement des suivis. Explications…
La location de matériel informatique coûte plusieurs milliards d’euros aux entreprises françaises chaque année. Suivie par les loueurs, la DSI, la comptabilité, les gestionnaires du parc et des stocks, … tout porte à croire que les coûts de location sont bien maîtrisés. En réalité, ces multiples suivis aboutissent à des résultats très différents, sans que personne dans l’entreprise n’ait vraiment conscience de la réalité.
La première étape du diagnostic, consiste tout d’abord à identifier les processus et les acteurs impliqués dans la gestion du matériel, et notamment du matériel loué.
Un écart potentiel entre les visions de l’Entreprise et la vision du Loueur
Visions de l’Entreprise
En pratique, la responsabilité de la gestion des matériels informatiques est souvent répartie sur plusieurs acteurs qui ont eux-mêmes des objectifs spécifiques.
De fait, la vision du contenu du parc diffère au sein même de la DSI. Les trois sources principales d’information sont : celle de la Gestion de Parc, celle des Equipes IT (réseau et/ou télédistribution), celle de la Finance…
Le service de Gestion de Parc assure un rôle de gestion des biens dans un outil spécialisé, définit des processus de mise à jour mais n’est généralement pas en charge de l’exécution des opérations. La fiabilité de la Gestion de Parc est donc tributaire de nombreux acteurs dont la rigueur conditionne la qualité de la Gestion de Parc.
Les Equipes IT ont une gestion très technique des équipements basée sur des outils et différentes bases qui permettent d’enregistrer les équipements. Les équipes Réseau et de télédistribution savent identifier les équipements connectés et les utilisateurs associés. Les mécanismes techniques d’inventaire et d’identification réseau permettent d’avoir des informations très précises sur les équipements connectés. Cependant, toutes les machines en « attente » : déconnectées, rangées dans des placards, cassées, prêtées ne peuvent être identifiées. De même, ces outils n’adressent pas les périphériques (souris, claviers, écrans, câbles), Bien entendu, les outils de collecte ne font aucune différence entre les machines louées et celles achetées.
Le contrôle de gestion de la DSI suit le coût des machines dans son budget. Il utilise parfois les outils du loueur et dispose de moyens limités pour contrôler la facturation du parc loué..
Au fil du temps, il y a donc distorsion entre les vues de la Gestion de Parc, des Equipes IT, du financier. Résultat : un écart d’au moins 20% entre les différentes visions constatées dans de nombreuses entreprises.
Vision du Loueur
De son côté, le loueur a une vision statique. Il suit tout ce qu’il a loué : les ordinateurs mais aussi les écrans et autres périphériques.
Sa gestion est totalement décorrélée du cycle de vie des équipements : il ne sait pas s’il y a des équipements cassés, des mobiles perdus ou des serveurs obsolètes inutilisés. D’une part, parce que l’ensemble du matériel loué, quel que soit son état, devra être payé jusqu’à la fin de la période de location initiale, d’autre part parce que le loueur n’a quasiment jamais les données nécessaires pour mettre à jour son suivi.
La fin de vie du matériel : trop tard pour constater les écarts de suivi
En fin de contrat, le loueur reçoit la liste du matériel à récupérer.
Ce matériel est préparé par l’Entreprise. Il est collecté tant bien que mal dans les différentes directions ou implantations qui souvent n’ont pas en charge la gestion de leur parc de machines.
Le matériel est récupéré par un transporteur, qui n’assure pas le contrôle. Il est stocké et il peut se passer plusieurs semaines avant que le loueur traite le matériel récupéré.
Ces multiples étapes nécessitent la mise en œuvre précise de processus souvent mal maîtrisés par les acteurs. Ainsi la gestion de parc n’est pas forcément informée des retours ou des matériels manquants.
Le loueur met à jour sa base, donc la vue financière, mais n’informe pas forcément l’équipe de gestion de parc des éventuels écarts.
Pour le loueur, les matériels non restitués continuent forcément à être loués.
Beaucoup d’entreprises continuent donc de payer ne sachant pas où est le matériel. Faute d’information, aucun contrat ne peut être clôturé, et peu d’entreprises utilisent à bon escient la clause de non-restitution.
Les multiples raisons des écarts
Une liste à la Prévert de « petites raisons » explique la dérive entre la réalité terrain et les informations des équipes qui assurent le suivi des matériels loués pendant la durée du contrat.
D’abord, l’informatique sait où sont les machines utilisées mais souvent peu d’analyses permettent de suivre les matériels obsolètes ; les ordinateurs remisés dans un placard, etc… L’urgence faisant loi, le smartphone cassé est remplacé au plus vite, et le vieux mobile est abandonné dans un tiroir.
Certaines machines sont récupérées par les collaborateurs. Il ne s’agit pas forcément de vol, mais d’équipement en double pour le travail à la maison. Même si le manager en est informé, il n’a généralement pas le réflexe de communiquer cette information au service de Gestion de Parc.
De plus, les DRH ou les managers ne savent pas que les postes sont loués et ils laissent parfois partir les collaborateurs avec leur portable ou leur tablette. Or, le matériel n’appartient pas à l’entreprise.
Pour toutes ces petites raisons, les équipements deviennent donc « invisibles » pour le Gestionnaire du Parc mais continuent à être bien réels pour le Loueur qui facture ses loyers.
Les mesures de suivi : d’abord plus de communication
La première chose est d’organiser la communication entre les services au sein de la DSI, mais aussi avec le management, la DRH… Tous doivent savoir que le matériel n’appartient pas à l’entreprise et qu’il ne peut être ni jeté, ni donné, ni vendu…. Le Loueur est le propriétaire
La mise en place d’outil de reporting (type tableau de bord), avec un rapprochement régulier entre les différentes sources d’information permet de déclencher des actions correctrices. A chaque mesure, l’entreprise réduira un peu plus les coûts du matériel informatique et de l’ensemble du parc informatique loué. La fonction de Gestionnaire de Parc est responsable de ce rapprochement. Il est, connu et reconnu, fera le lien entre la vision des utilisateurs, celles des différentes équipes (techniques, logistiques, comptables…) et les informations du loueur et suivra les plans d’actions.
Cependant il est difficile de sensibiliser tous les collaborateurs au fait que le matériel n’appartient pas à l’entreprise mais au loueur.
Il est donc important de prévoir dès la signature des contrats avec le Loueur, un taux de non-restitution pour réduire le coût d’éventuels matériels perdus à la fin de la période de location.
L’intérêt d’un contrat de location dépend entre autres de la capacité de l’Entreprise à gérer le cycle de vie de ses équipements (entrées, sorties, pertes, casses, ..) et du contenu de toutes les dispositions contractuelles associées (taux de non-restitution, type de matériel à restituer..).
Le marché du Serverless ou FaaS a bondi de manière importante en 2018, porté entre autres par la popularité grandissante de AWS Lambda, Azure Functions ou de Google Cloud Functions. Mais en quoi consiste une architecture Serverless ? Cela consiste à exécuter des fonctions sur le cloud sans se soucier de la conception de l’architecture technique et du provisionnement de serveurs. La facturation de ce type de service étant basée sur le temps que le traitement aura mis pour s’exécuter. Il y a donc toujours besoin de serveurs mais la conception et la gestion de ceux-ci sera réalisée à 100% par le fournisseur Cloud.
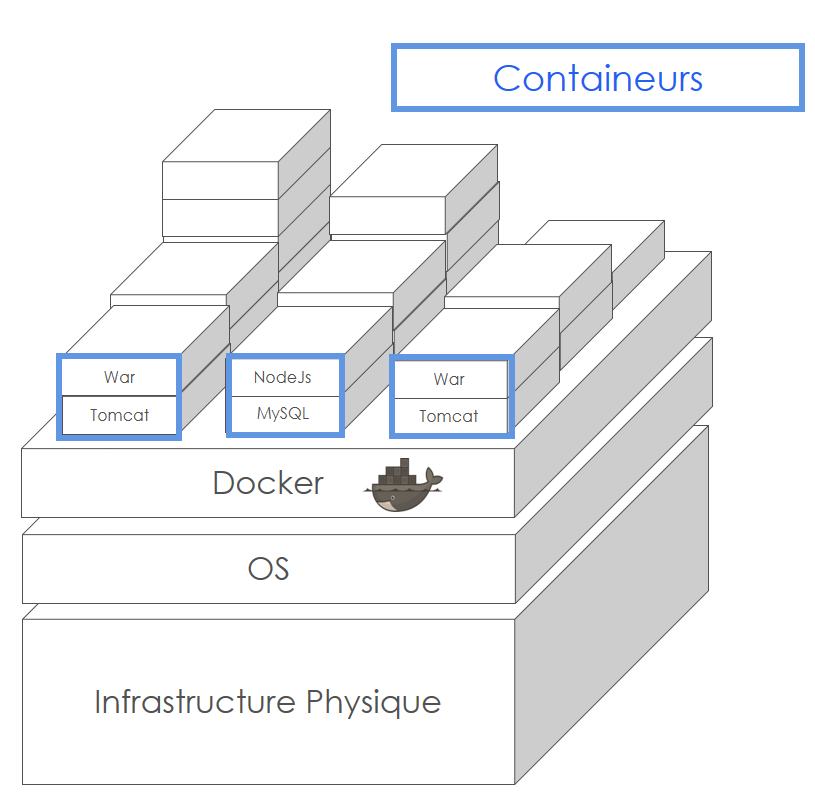
La différence avec une architecture basée sur des containers ?
La containérisation reprend les concepts de la virtualisation mais ajoute de la souplesse.
Un container est un sous-système pré-configuré par le biais d’une image. Celle-ci définit ce que le conteneur embarque à sa création (serveur d’application, application, etc.), normalement le minimum indispensable pour votre application (fonction ou micro-service).
Le Serverless est une architecture qui repose sur un concept simple : l’abstraction complète des ressources machine.
Il vous suffira par exemple d’avoir un compte AWS, cliquer “Create function” depuis la console, configurer quelques paramètres techniques comme la taille de la mémoire allouée et le temps de timeout maximum toléré, copier votre code et voilà !
Avantages et inconvénients
Le principal avantage de ce type d’architecture est le coût. Vous ne paierez que ce vous utiliserez basé sur des métriques à la seconde. Plus besoin de louer des ressources comme des machines virtuelles que vous n’utilisiez jamais à 100% ou de payer un nombre d’utilisateurs qui n’étaient pas connectés en permanence dans l’outil. Par exemple pour une fonction AWS Lambda à laquelle vous aurez attribué 128 Mo de mémoire et que vous prévoyez d’exécuter 30 millions de fois en un mois (pour une durée de 200 ms par exécution), vos frais ne seront que 10€/mois environ ! Si cela correspond à un pic saisonnier atteint en période de solde et que la moyenne d’exécution correspondra à la moitié de cette charge vous ne paierez que ce que vous aurez consommé. À titre de comparaison, un serveur virtuel de 1 coeur et 2 Go de RAM facturé au mois sera facturé 12€/mois, peu importe la charge. Et si un serveur de ce type ne suffisait pas, il faudra prévoir le coût d’une plus grosse instance ou d’une deuxième. Il est donc évident que le FaaS permet d’optimiser vos coûts par rapport à du IaaS ou du PaaS.
Le second avantage est qu’il n’y a pas besoin de gérer et maintenir l’infrastructure. Vous n’arrivez pas sur vos projets Agiles à anticiper vos besoins d’infrastructure ? Vous pensez qu’attendre 1 jour pour avoir une machine virtuelle c’est encore trop long ? Vous trouvez bien le principe des microservices mais vous trouvez compliqué de gérer une architecture technique distribuée ? Une architecture Serverless ou FaaS vous simplifiera la vie de ce point de vue.
Il y a cependant des désavantages. Les AWS Lambda et Azure Functions sont des technologies propriétaires qui vous rendront complètement dépendant de votre fournisseur. Si un jour vous désirez migrer sur une autre plateforme, il vous faudra revoir le code de votre application notamment si celui-ci fait appel à des services ou infrastructure propre à ce fournisseur (lire un fichier dans un container S3 par exemple ne sera pas de la même façon que de le lire sur un Azure Blob). L’autre point important aussi à surveiller est que ces services sont bridés en termes de ressources et ne conviendront donc pas pour des applications nécessitant des performances élevées.
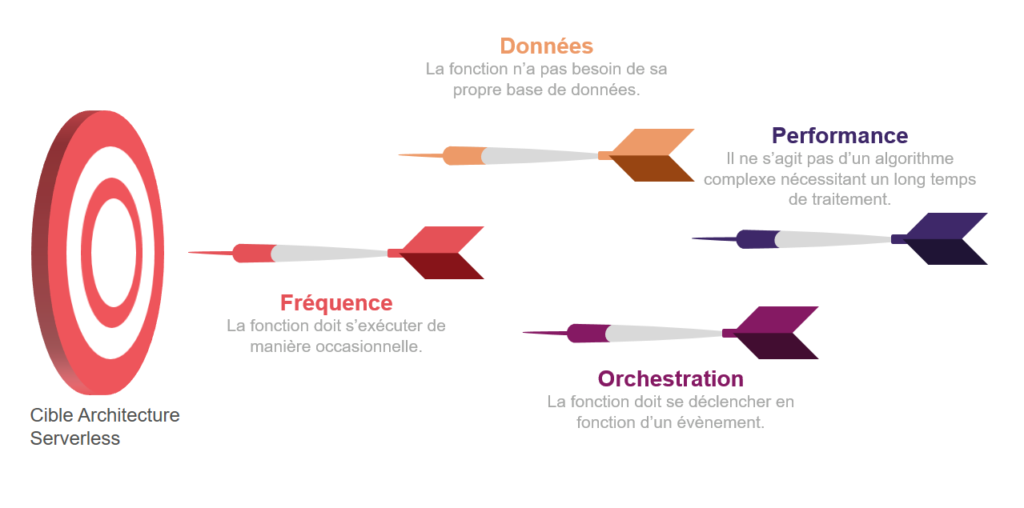
Pour quels cas d’usage ?
Une architecture Serverless peut convenir lorsque les critères suivants sont réunis :
Cela peut être par exemple :
Le lancement d’une requête comme l’appel d’une API pour récupérer les données de météo et les déposer dans la base de données utilisée par une application mobile.
L’envoi de notification par messagerie pour prévenir un groupe d’utilisateurs d’un événement.
Le transfert et la vérification du format de fichiers multimédias pour un site permettant à des photographes de partager leur travail.
En résumé, il s’agit d’une nouvelle façon de concevoir votre architecture solution, pouvant vous permettre de réaliser des économies importantes mais qui vous rendra plus dépendant du fournisseur Cloud que vous aurez retenu.
Chaque année, elle arrive au mois de novembre. Le contenu en est connu depuis presque un an, mais c’est souvent dans l’urgence que des établissements financiers s’en préoccupent pour respecter l’échéance.
Alors à quelques semaines du terme du 17 novembre 2019, savez-vous ce qui vous attend dans cette nouvelle Release ?
Bonne nouvelle ! Pas d’évolution sur le SDD !
En revanche, si de 2014 à 2017, le virement européen a connu peu d’évolution, 2019 prolonge le mouvement initialisé en 2018, avec l’apparition d’une nouvelle famille de R?messages (ou “messages connexes”) : les “Inquiries”, avec ses mises à jour associées.
La Release 2019 complète également les “Requests” et leur ajoute les “Status Updates” associés.
Retour vers le Futur
Petit rappel de la construction des messages liés au Virement SCT : l’origine remonte à 2008, avec un complément en 2010 :
Tableau 1 – Les messages historiques du SEPA Credit Transfer
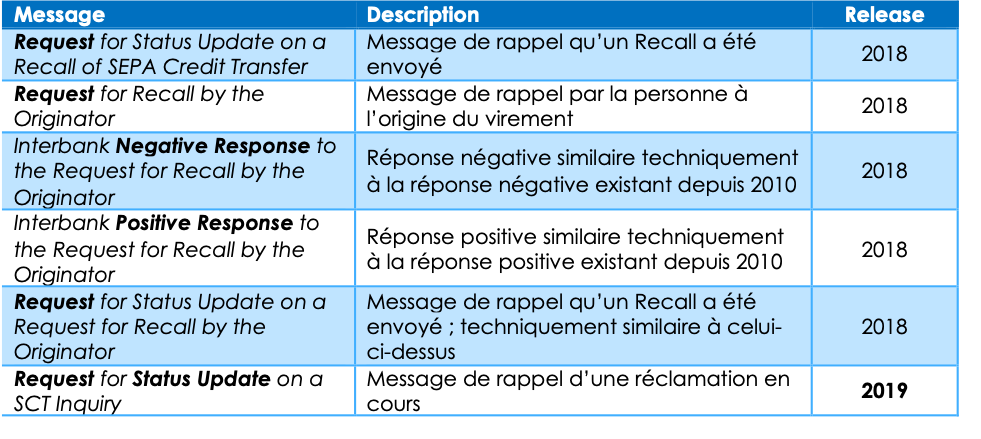
Les Requests
Les Requests s’enrichissent dans cette release 2019 : ces “requêtes entre banques” sont des messages destinés à interroger le confrère sur le sort d’une demande antérieure.
Par exemple, après un Recall (message historique de rappel de fonds), en l’absence de réponse, la banque émettrice s’enquiert de sa demande via un Request for Recall (message apparu en 2018).
Cette famille, apparue en novembre 2018, annonçait le prélude à une multiplication des messages qui se concrétise dans la release 2019.
En Novembre 2019, il sera possible de faire des Request for Status Update qui permettront de connaître la destinée des messages précédemment envoyés.
Tableau 2 – Les Requests et les Status Updates
Les Requests for Status Update accompagnent les Requests et Inquiries : ils ont été définis pour rappeler au destinataire qu’une requête (Request), qu’une enquête (Inquiry) ou qu’un rappel de fonds (Recall) a été émis et reste à ce jour sans réponse.
En principe, une banque se doit de faire un retour sur tous les R-messages imposant une réponse. Ces messages permettront d’identifier plus facilement les établissements qui, par habitude, ne répondent pas aux messages.
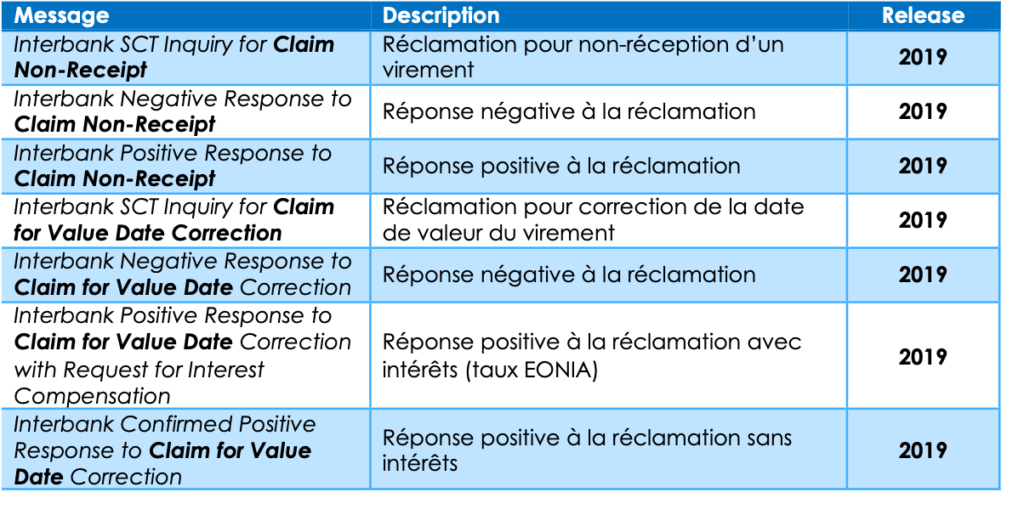
Les Inquiries
La famille des Inquiries est la nouveauté 2019. Les Inquiries sont des messages d’investigation.
Par exemple, l’émetteur demande d’enquêter sur l’absence de réception d’un virement ou sur une demande de modification de date de valeur.
Ces messages peuvent améliorer certains processus internes dans les banques, comme dans le traitement des vérifications et des contestations ; plus globalement, l’objectif européen est d’encadrer des pratiques existantes de gré à gré entre banques.
Ces nouveaux messages bénéficieront surtout aux banques ne disposant pas des relations interbancaires suffisantes pour gérer par téléphone auprès d’une banque estonienne, le cas d’un virement non reçu.
Ils affranchissent en effet les Back-Offices bancaires des barrières linguistiques et des décalages horaires.
Tableau 3 – Nouveauté 2019 – les Inquiries
Les Inquiries peuvent faire l’objet d’une Request for Status Update pour rappeler au confrère qu’une demande est en cours (cf. §2).
Une Release souvent jugée à faible Valeur Ajoutée par les Banques Françaises…
Le socle européen de base du virement SEPA s’étend à présent à 19 messages (sans compter les ajouts nationaux, comme les ACVS et les CAI pour la France).
Fallait-il s’imposer ces nouvelles contraintes, se demanderont sans doute les banques, pour traiter des cas d’exception ?
La Release s’impose à tous !
Outre la force de la réglementation, la Release s’impose pour suivre les prochaines évolutions réglementaires et fonctionnelles.
D’un côté, la Release 2019 démontre bien la disparité entre les pratiques nationales : elle est bien accueillie en Allemagne et plus froidement en France. Mais n’est-ce pas précisément la volonté et le rôle du régulateur d’uniformiser les pratiques à l’échelle de l’Europe et faire émerger des acteurs pan-européens ?
D’un autre côté, les banques voient les coûts de mise en oeuvre de la Release. Alors qu’elles investissent pour se transformer au numérique et à l’instantanéité, ces changements sont le plus souvent subis et les banques peinent à y trouver un retour sur investissement.
La nouvelle réglementation, un paradoxe avec le SCT Inst…
Le rapprochement entre la Release 2019 et le passage au numérique instantané souligne un paradoxe.
En effet, que penser des nouveaux messages de correction des dates de valeur alors que l’autre virement européen, le SCT Inst (alias Instant Payment) fait disparaître la notion-même de date de valeur et de règlement ? Si le SCT Inst se présente de plus en plus généralement comme le remplaçant (“the new standard”) du SCT classique dans plusieurs pays européens, fallait-il créer ces nouveaux messages ?
En synthèse, l’adoption de la Release SEPA 2019 au sein des banques se fait sans enthousiasme, avec un contenu chargé (l’un des plus lourd qu’ait connu le SCT) et sans retour sur investissement clairement identifié.
Néanmoins, elle reste obligatoire pour toutes les banques européennes, même si certaines essaieront de conserver un traitement manuel sur certains processus.
Et puisqu’il faudra bien y passer, autant bien comprendre les mécanismes européens et les attendus de cette Release. C’était l’objet de cet article, que nous pouvons poursuivre en bilatéral sur demande… parallèlement aux actions à engager pour accélérer le déploiement du SCT Inst et s’affranchir du SCT Classique !
Une révolution est en cours dans nos cités. Les utilisateurs délaissent les moyens mis à leurs dispositions par les conseils régionaux et les mairies pour des solutions écologiques, innovantes, souples, facturées à l’usage et dont le bénéfice est immédiat.
Toutefois, bien que pratique, cette nouvelle mode urbaine génère du stress également, comment s’adapter à ces nouveaux usages ? Certaines municipalité ont tenté de les interdire, d’autres se posent la question de la réglementation, quel est le risque pour l’usager et pour les autres usagers, doit on permettre à ces utilisateurs de consommer ces services alors que nous ne l’avions pas prévu ?
Les infrastructures actuelles ne sont pas compatibles avec ces nouveaux usages, la pression des utilisateurs est telle qu’il faut trouver des solutions palliatives pour leur permettre de les utiliser en toute sécurité.
Ces précurseurs bousculent l’ordre établi qui se voit devancé sur les problématiques de développement durable et de transport.
Quel cadre proposer pour que tout le monde y trouve son compte sans pour autant bloquer ceux qui suivent le modèle historique mais que l’on aimerait réussir à convertir aux nouveaux usages ?
Ces réflexions sont en cours à Lyon, à Bordeaux, à Paris, ainsi que dans la majorité des métropoles régionales, et les villes rurales réfléchissent à offrir ces services même si la pression et l’impact sont moins importants.
Ces questions autour des vélos et des trottinettes en libre service ont peu de rapport avec l’IT ou avec nos DSI mais elles rappellent un sujet qui revient depuis plusieurs années : le Shadow IT.
Les utilisateurs consomment des services informatiques sans en informer leur DSI, les contraintes de sécurité sont ignorées, les fournisseurs multiples, la même solution peut être consommée plusieurs fois sans qu’il n’y ait d’optimisation des coûts.
Faut-il l’interdire ? Est-ce que l’entreprise acceptera de retarder son plan de transformation, la sortie d’un nouveau produit ou pire de dégrader la satisfaction client pour respecter les exigences de l’IT ?
Les problématiques se ressemblent, les solutions sont tout aussi éclectiques et dépendent à chaque fois de l’environnement, du cadre et des besoins. L’entreprise doit aujourd’hui permettre à ses utilisateurs, à ses clients internes d’utiliser des solutions compétitives au time-to-market imbattable et correspondant à leurs besoins. Mais l’entreprise doit aussi garantir la sécurité de son SI, de ses données et de son activité.
Ces nouvelles solutions ont généralement des attributs communs, elles sont hébergées dans le cloud, ne nécessite pas d’installation et la configuration est à la portée de tous.
L’enjeu pour les sociétés, quelle que soit leur taille, est de permettre la consommation de ces nouveaux services, de faciliter leur usage dans le respect des normes de sécurité en gardant la maîtrise des coûts qu’ils induisent.
L’entreprise se voit donc imposer une transformation vers le cloud par ses clients internes, ses employés, qui se demandent pourquoi les outils qu’ils utilisent au travail sont moins performants et conviviaux que ceux qu’ils utilisent à la maison.
Quels sont les bénéfices que l’entreprise tirera de cette transformation ?
Quelles sont les étapes à respecter ?
Ce sont les thèmes que nous développerons dans nos prochains articles.
La valeur des données pour une entreprise n’est plus à démontrer : les rapports des analystes fourmillent d’exemples d’entreprises qui ont su valoriser leurs données et en mesurer les bénéfices, que ce soit en revenus directs (augmentation des ventes, innovation produits & services,…) ou en économies réalisées (performance financière & opérationnelle, réduction des risques,…). Dans un cas comme dans l’autre, ces bénéfices se chiffrent souvent en dizaines de millions d’euros par an !
Cette prise de conscience s’est accélérée ces dernières années avec la montée en maturité de technologies (IoT, Big Data, IA, …) permettant de collecter massivement des données, de lever les contraintes de stockage et de multiplier le champ des possibles en matière d’analyse et d’exploitation de ces données en temps réel.
Cependant, après les phases d’expérimentation, l’industrialisation de ces technologies est freinée par la capacité des entreprises à réellement maîtriser leurs données : les analystes estiment qu’une mauvaise qualité des données est en cause dans 40% des initiatives métier qui n’atteignent pas leurs objectifs.
Dans ce contexte : Par où commencer ? Quelles initiatives lancer ? Comment s’y prendre pour construire une feuille de route Data permettant de maîtriser et de valoriser son patrimoine de données ?
Ce livre blanc s’adresse à tous les acteurs de la Data et propose une approche concrète et opérationnelle, orientée risques et valeur, pour définir une feuille de route Data.