Les actions majeures pour aligner la Gouvernance IT avec les ambitions de la DSI
Votre gouvernance IT n’est pas alignée avec les ambitions de votre DSI ?
Des signaux doivent vous mettre la puce à l’oreillle
Manque de repères sur l’avancée des projets métiers
Collecte d’informations hétérogènes, parfois contradictoires, à intervalles irréguliers
Des projets se lancent en dehors du contrôle de la DSI sur certains métiers ou géographies
…
L’équipe CIO Advisory vous dévoile les 4 grands axes majeurs pour réaligner votre gouvernance IT
Établissez une cartographie des référents métiers par géographie
Mettez en place les instances de gouvernance
Formalisez et partagez les priorités de la DSI
Définissez et partagez les KPI & les risques
Savez-vous que lancer les développements d’une solution sans modélisation de données, c’est comme construire une maison sans en avoir fait les plans ?
Si vous voulez avoir des solutions performantes et pérennes pour vos projets de transformation de vos SI, utilisez la modélisation de données, et en particulier la modélisation de données conceptuelle, comme un levier de performance.
Stocker des données n’est pas modéliser des données
Très souvent après avoir validé vos projets de transformation des SI pour atteindre les enjeux métier d’entreprise, l’objectif est de rapidement importer les premières données pour pouvoir les rendre ‘visibles’ et avoir des premiers résultats ‘concrets’.
Des développements sont donc lancés, sans l’étude préalable des données et des concepts nécessaires pour faire le lien avec le métier de l’entreprise. Ces développements conduisent à définir des tables et des jointures avec pour objectif de stocker des données. C’est la modélisation de données dite physique. L’objectif n’est pas le bon à ce stade. C’est une vision de solution court-termiste.
Une notion importante à appréhender est que le stockage des données et la structure de la base de données impactent directement la restitution, et donc l’usage des données. Cette structure est développée au travers du modèle de données physique.
Si vous mélangez les notions de modèle de données physique et de modèle de données conceptuel, et si vous ne comprenez pas bien les concepts fonctionnels manipulés, alors le modèle de données physiques ne répondra pas à tous les besoins adressés.
Toutes ces questions sont adressées au travers de la modélisation de données et en particulier la modélisation de données conceptuelle.
Dès lors, quels sont les objectifs de la modélisation de données ?
Nous avons vu que lorsque nous pensons modélisation de données, nous pensons tables, jointures, clefs étrangères. En réalité, cela revient à penser, tuyaux en PVC ou en cuivre, briques ou parpaings, avant même de savoir si nous souhaitons une maison de plain-pied ou à étages. La modélisation de données conceptuelle est donc une obligation.
Le modèle de données conceptuel conceptuel permet de définir des concepts (étonnant, non ?) transverses à l’entreprise, clairement définis entre les parties prenantes. Ces concepts sont liés pour répondre à un ensemble d’usages, qui lorsqu’ils sont regroupés dans des fonctions (définies au travers de l’architecture fonctionnelle), constitueront la solution informatique répondant aux besoins.
Le modèle de données conceptuel doit d’abord répondre à des usages propres au métier de l’entreprise. Prenons un modèle de données client par exemple. Il sera différent pour un assureur ou pour un industriel. Il sera également différent entre deux assureurs du fait de leur positionnement sur le marché. Le modèle conceptuel est donc basé sur l’utilisation des données qu’il contient : les usages valident le modèle.
La modélisation de données : une démarche à valeur ajoutée pour la DSI et surtout pour le métier
Le modèle de données conceptuel décrit les données stockées dans la solution de manière compréhensible par les métiers. D’autre part, il impose une démarche rigoureuse de conception concourant à la réussite du projet.
La modélisation de données doit ainsi commencer par lister les usages et les données sous-jacentes ou associées. S’entourer à la fois d’experts des données et d’experts métier est donc la clé. En effet, nous avons mis en évidence plus haut que le modèle de données conceptuel doit répondre aux deux enjeux à la fois :
Les experts des données sont responsables de découvrir et connaître les données, leur qualité réelle et leur utilisation réelle.
Les experts métiers sont responsables eux de décrire les usages actuels et cibles de ces données. Les usages étant les processus métiers de l’entreprise dans lesquels vont être utilisées ces données, mais aussi les contraintes liées à la mise à disposition de ces données (réglementaires, sécurité, etc.).
Construire et valider le modèle de données conceptuel est donc une démarche itérative afin d’échanger très régulièrement entre le métier, les experts de la donnée et la DSI.
Un modèle de données conceptuel performant est avant tout un modèle métier qui traduit des besoins métiers : on ne peut modéliser sans avoir une expression de besoin décrivant les usages.
La modélisation conceptuelle s’inscrit également dans une démarche de gouvernance des données. En effet, les premières questions posées naturellement quand le modèle de données se construit sont par exemple : quelle est la définition de ce concept ? dans quel cycle de vie s’inscrit-il ? etc. Les métiers définissent les concepts, les périmètres et les responsabilités avec le modèle de données conceptuel.
Avec cette démarche, en tant que DSI, vous minimisez les risques de choix court-termistes et de complexité de la solution développée. Vous bénéficierez ainsi d’une solution évolutive, maintenable, documentée et qui minimise également le shadow IT.
En tant que métier, cela vous permet d’être au plus proche des développements et vous comprenez grâce au modèle de données conceptuel, les données manipulées dans la solution. Vous minimisez ainsi les risques d’inadéquation avec les attentes métier.
En tant que responsable projet, product owner, ou responsable SI, imposez donc d’avoir une démarche de modélisation de données qui commence par un modèle conceptuel dans tous vos projets SI. Il est un facteur clef de réussite !
La modélisation de données : une compétence clé
La gestion du cycle de vie du modèle de données conceptuel et des impacts sur le stockage des données (base de données), doivent être suivis et validés par une personne experte en modélisation de données. Le cycle de vie du modèle de données est un processus lent dont les évolutions ne se voient pas forcément.
Une modélisation de données performante doit garantir une cohérence, une intégrité et une interopérabilité des données et des solutions. Une mauvaise modélisation de données crée ainsi lentement des blocages SI pour de futurs usages. Une illustration simple de cette mauvaise modélisation de données, est de laisser en attributs des données qui ont des cycles de vie différents de l’objet auquel ils sont rattachés. Multipliés par le nombre de données à l’échelle de l’entreprise et ajoutés à la complexité d’un modèle, ces problèmes de modélisation de données rendent le SI rigide.
La modélisation de données est donc une compétence spécifique. C’est une expertise qui s’acquiert au fur et à mesure des projets. Elle est nécessaire aux équipes de conception telles que les Business Analysts et les Architectes de données.
La modélisation de données, un facteur clef de succès de la transformation des SI
La modélisation des données est donc indispensable à un projet de développement de solution informatique. Comme évoqué précédemment, avec le modèle de données conceptuel, elle manipule des concepts métier de l’entreprise. Elle doit donc se projeter et anticiper les nouveaux concepts nécessaires aux nouvelles demandes client. Elle garantit ainsi l’agilité et l’évolutivité de votre solution face à la diversité des usages à adresser pour répondre aux demandes client en perpétuelle évolution.
Une question reste alors : la modélisation de données dépendant de la qualité des données des concepts métier, est-ce que les processus métier actuels de l’entreprise peuvent être modifiés pour fournir la qualité des données nécessaires aux nouvelles demandes client ?
Le site internet est une vitrine de l’entreprise, celui qui vous permet de vous présenter à vos partenaires, candidats, clients, prospects… bref, à tout votre écosystème. Il est donc primordial qu’il donne confiance quant à la gestion des données de vos visiteurs, et qu’il soit conforme à la réglementation en vigueur. Un site conforme au RGPD, transparent sur l’utilisation qu’il fait des données que le visiteur lui fournit, offre une bonne première impression et évite de devoir expliquer à vos clients que vous n’êtes pas conforme RGPD si la CNIL décide d’auditer votre entreprise.
Le RGPD n’est pas l’unique règle qu’il faille appliquer pour considérer son site internet comme absolument conforme (règle EPrivacy, régle de régulation des mentions légales, …). Nous nous sommes principalement focalisés ici sur le RGPD.
Il n’est toutefois pas toujours aisé de démêler concrètement les impacts de la réglementation sur votre site et de savoir s’il est bien en phase avec celle-ci. Chez Rhapsodies Conseil, nous vous avons donc préparé une synthèse des quelques points clefs auxquels vous devez vous intéresser.
1. Les cookies
Première action du visiteur sur le site : le bandeau cookie
Un bandeau cookie, doit répondre à 3 obligations indispensables :
Acceptation, refus, paramétrage
Les boutons accepter tous les cookies et refuser tous les cookies sont obligatoires. L’interface ne doit pas avantager un choix plus qu’un autre, les deux boutons doivent, entre autre, avoir la même taille, la même forme et la même couleur.
Le bouton paramètrage n’a pas l’obligation d’être identique aux deux autres, et doit permettre de choisir quel type de cookie j’accepte et quel type de cookie je refuse.
Lors du paramètrage, lesopt-in doivent obligatoirement être désactivés par défaut. Accepter tel ou tel type de cookie doit résulter d’une action du visiteur.
Chaque type de cookie (Fonctionnel, Performance, Analytique, …) doit être décrit afin d’éclairer le visiteur dans son choix. Chaque choix doit se faire par finalité, c’est-à-dire que le visiteur peut refuser les cookies de Performance et de Publicité et accepter tous les autres sans que son parcours sur le site ne soit différent.
Tant que le visiteur n’a pas donné son accord explicite de dépôt de cookies (autre qu’obligatoire), aucun cookie ne doit être déposé.
L’utilisateur doit pouvoir revenir sur son choix dès qu’il le souhaite, il doit donc y avoir un moyen pour le visiteur de revenir sur le paramétrage des cookies afin de refuser/accepter les cookies.
Le bon fonctionnement du paramétrage des cookies & preuve de consentement
Il arrive souvent que, bien que le bandeau cookie permette de refuser le dépôt de certains cookies, celui-ci ne soit pas totalement fonctionnel. Il est donc primordial de vérifier régulièrement que l’outil de paramétrage est bien opérationnel.
Enfin, il est indispensable de pouvoir conserver la preuve du consentement (article 7 du RGPD).
Lien vers la charte des données ou charte des cookies
Le visiteur doit pouvoir accéder à la politique d’utilisation des cookies, rapidement et avant de faire son choix. Un lien vers la politique d’utilisation des cookies doit donc être présent sur le bandeau.
Cette Politique des cookies doit comprendre : une description de ce qu’est un cookie, une description de comment supprimer les cookies par navigateur, la finalité et la durée de conservation des cookies, le type de cookies et préciser (dans le cas d’un cookie tiers) le tiers en question et le lien vers sa propre politique de confidentialité ou de cookies. Contrairement aux idées reçues, la liste exhaustive des cookies n’est pas obligatoire.
ATTENTION : les cookies collectent des données personnelles, ils ne peuvent donc pas être transférés vers des pays où la réglementation sur la protection des données personnelles n’est pas conforme au RGPD. Les Etats-Unis, par exemple, ne donnent pas une protection sur les données personnelles suffisante pour que les données y soient envoyées. L’utilisation des Cookies Google Analytics (_ga, _gat, …) n’est donc pas acceptée.
2. Les mentions d’informations et la charte des données personnelles
Les mentions d’informations sont les petits textes se trouvant sous les « points de collecte de données » (Newsletter, point de contact, inscription, …). Afin de pouvoir faciliter la compréhension, j’aime décrire les mentions d’informations comme une « charte des données personnelles spécifique au point de collecte »
Une mention d’information doit notamment contenir certaines informations que sont :
Un rappel des données personnelles qui sont collectées suivi par l’utilisation qui en est faite ;
Un lien vers la charte des données personnelles ;
La base légale sur lequel s’appuie le traitement ;
Le destinataire des données (préciser si un transfert des données hors de l’UE est effectué) ;
La durée de conservation des données (non-obligatoire si celles-ci sont présentes dans la charte des données personnelles) ;
Le rappel des droits ;
Le point de contact (DPO).
Toutes les informations peuvent se trouver dans un texte sous le point de collecte, il est possible de créer une page spécifique à la mention d’information accessible via un lien (cf. exemple ci-dessus). L’important est de respecter le principe de transparence qui implique que les informations soient présentées d’une forme claire. Il est conseillé que cela soit ludique et adapté aux interlocuteurs concernés.
La charte des données personnelles quant à elle est indispensable dès qu’une donnée personnelle est collectée sur le site. Cette charte doit comprendre les informations suivantes :
Le nom du responsable de traitement ;
Les finalités de traitement ;
Les bases légales sur lesquelles reposent les traitements (si un traitement repose sur le consentement, il faut préciser que celui-ci peut être retiré) ;
Les destinataires des données (avec précision si les données sont transférées hors de l’UE et les garantis quant au respect des règles de sécurités imposées par le RGPD (anonymisation, pseudonymisation, …)) ;
La durée de conservation des données personnelles ;
Le rappel des droits des personnes (accès, limitation, suppression, opposition, rectification et portabilité) ;
Le contact pour faire valoir ses droits (DPO) ;
Le droit de déposer une réclamation auprès de la CNIL ;
L’existence (ou non) d’une prise de décision automatisée ;
La source des données s’il existe une collecte indirecte.
La charte doit être mise à jour dès qu’un nouveau traitement est créé.
Il est possible que vous n’ayez pas besoin de créer de charte des données personnelles. C’est le cas si les mentions d’informations de tous les points de collecte de votre site internet contiennent des mentions d’informations spécifiques et complètes comprenant les informations obligatoires. Si vous répondez à ce cas de figure, il vous faudra cependant une charte des cookies.
3. CGU, CGV, mentions légales
Les CGU ne sont pas obligatoires mais apportent un cadre d’utilisation du site internet (droits et obligations respectives à l’éditeur et au visiteur). Si votre site internet n’est qu’une vitrine et qu’il ne permet pas la création d’un compte, un achat, le dépôt d’un commentaire, … il n’est pas obligatoire d’avoir des CGU.
Cependant, celles-ci sont indispensables dans les cas contraires. En effet, les CGU peuvent être considérées comme le “règlement intérieur du site”. Elles donnent les droits de l’utilisateur, ses responsabilités et également celles en cas de non-respect.
Les droits de l’utilisateur doivent être précisés, par exemple dans le cas de la création d’un espace personnel. Ces dispositions des conditions générales d’utilisation permettent d’engager la responsabilité de l’utilisateur en cas de dommage résultant du non-respect desdites obligations.
Francenum.gouv.fr
L’utilisateur du site doit accepter explicitement les CGU pour qu’elles puissent être considérées comme légales.
Contrairement aux CGU, les CGV sont obligatoires dès que le site propose un service de paiement, vente, livraison en ligne. Les CGV correspondent à la politique commerciale du site internet (modalité de paiement, délais de livraison, rétractation, …). Elles sont particulièrement utiles en cas de contentieux. Cependant, il n’est pas obligatoire de les avoir disponibles directement sur votre site internet, si vos clients sont professionnels (B2B). Elles le sont si vos clients sont des particuliers (obligation précontractuelle d’information du vendeur). Pour chaque vente, les CGV doivent être acceptées par le particulier (B2C).
Les mentions légales sont les informations permettant d’identifier facilement les responsables du site. Pour une personne physique, il faut inclure :
Le nom et le prénom ;
L’adresse du domicile ;
Le numéros de téléphone et l’adresse mail.
Pour une personne morale (une société), il faut inclure :
Le nom de l’entreprise et le numéro SIRET ;
La forme juridique de la société ;
Le montant de son capital social ;
L’adresse du siège social.
Il est aussi impératif de préciser les mentions relatives à la propriété intellectuelle :
La propriété intellectuelle des photos, images, illustrations, textes qui ne sont pas les vôtre (à minima la source des tactes).
En complément de ces informations, il est indispensable d’inclure :
Le nom de l’hébergeur et sa raison sociale ;
L’adresse de l’hébergeur ;
Le numéros de SIRET de l’hébergeur ;
Le numéro de téléphone de l’hébergeur.
Certaines activités impliquent d’ajouter certaines informations :
le numéro d’inscription au registre du commerce et des sociétés (RCS) (et numéro de TVA intercommunautaire, si vous en avez un) ;
le numéro d’immatriculation au répertoire des métiers (RM) ;
le nom du directeur/codirecteur ou responsable de la publication (si vous proposez des articles, des blogs, des informations, …) ;
le nom et l’adresse de l’autorité vous ayant délivré l’autorisation d’exercer (si votre activité est soumise à un régime d’autorisation).
4. Le principe de minimisation
Très souvent, on a tendance à vouloir collecter le plus de données possibles « au cas où », sans finalité précise. Cependant, depuis le RGPD, le principe de minimisation limite cette tendance.
Le principe de minimisation prévoit que les données à caractère personnel doivent être adéquates, pertinentes et limitées à ce qui est nécessaire au regard des finalités pour lesquelles elles sont traitées.
CNIL
Ainsi, il n’est plus possible de collecter des données ne pouvant pas être justifiées par la finalité de traitement. Par exemple, demander le genre de la personne pour une inscription à une Newsletter n’est pas possible, sauf si on le justifie (par ex. le contenu de la Newsletter est différent selon que l’on est un homme ou une femme).
Ces quelques points vous donnent une première approche à avoir pour vérifier que votre site est bien conforme. La revue du site est aussi un bon moyen de faire une passe sur les données collectées et lancer une véritable mise en conformité de vos traitements de données (bases de données, contrats, CRM, …).
Chez Rhapsodies Conseil, nous nous appuyons sur des outils internes et externes qui ont fait leurs preuves et sur l’expertise de consultants expérimentés pour analyser la conformité de vos sites internet.
Rhapsodies Conseil a participé à la table ronde FPF organisée par France Payments Forum le 8 avril 2021. Lors de cet événement, Hervé de France Payments Forum, Damien de Galitt, Sami de Hipay, Jean-Michel de Mercatel, Aude de Market Pay, Hervé de Arkea, Régis de Worldline et Ikbel, notre Senior Manager et expert Digital Payment Experience ont échangé sur les nouveaux modes de paiement en point de vente.
Ce sujet, bien que les événements liés à la pandémie de COVID-19 soient d’actualité, a été choisi étant donné que la Commission Européenne a établi une nouvelle stratégie de paiement.
Le débat présenté a permis de montrer les scénarios potentiels d’évolutiondes paiements au point de vente et les préalables qu’il faudrait lever pour les réaliser.
Vous souhaitez (re)voir la table ronde en partie ou en intégralité? Cliquez sur le bouton play situé ci-dessous.
Les données sont partout et nulle part et sont bien souvent intangibles. Notre quotidien devient petit à petit un flot permanent de données générées, collectées et traitées. Elles sont cependant un moyen pour atteindre des objectifs et non une finalité.
Les entreprises doivent donc avoir la capacité à naviguer vers leurs objectifs business, sur une rivière qui deviendra vite un océan de données. L’important maintenant est donc de savoir si elles ont les moyens de braver les éléments.
Les ‘éléments’ auxquels il faut faire face
1. L’obligation de la donnée
La donnée est omniprésente. Données personnelles, confidentielles, de navigation, de consentement, data science, data platform, data visualization, chief data officer font partie d’une longue liste de termes qui font le quotidien des experts mais aussi du client consommateur. Les données sont aujourd’hui un asset reconnu et à forte valeur ajoutée (1). Elles sont aussi un asset pérenne du fait des usages numériques et des opportunités business qui se réinventent tous les jours.
Premier constat donc, l’obligation de la donnée. Elle est un passage obligatoire pour mieux connaître les consommateurs, répondre à leurs nouveaux besoins et être innovant.
2. La surabondance
La digitalisation croissante dans tous les secteurs, les réseaux sociaux, l’IOT, la mobilité, l’utilisation croissante des smartphones sont des exemples qui provoquent une forte augmentation de la génération de données. Les sources se multiplient, les besoins en stockage également (2). Par conséquent, nous sommes vite confrontés à une problématique grandissante : comment maîtriser toutes ces données ? Comment faire face à ce flot surabondant ? Et comment en tirer des informations utiles sans être noyé ?
Les prévisions (3) tablent en effet sur une multiplication par trois ou quatre du volume annuel de données créées tous les cinq ans. Les chiffres sont implacables.
Le deuxième constat est donc la surabondance. Un océan numérique déferle et chaque entreprise, peu importe sa taille, devra y faire face.
3. L’éphémère
Le numérique génère de nouvelles habitudes chez le consommateur : l’instantanéité, le choix abondant et la rapidité de changement. (offre, prix, produit, etc.). Ces habitudes se traduisent par des besoins de plus en plus éphémères. Elles raccourcissent les durées de vie des produits et des services, ou imposent de continuellement se renouveler pour se différencier. Les opportunités marchés sont nombreuses et il faut aller vite pour les saisir le premier. Être le premier est ainsi souvent synonyme de leadership sur le marché. (exemple : Tesla, Airbnb, Uber) L’éphémérité des besoins impose donc d’accélérer en permanence tous les processus internes, métier et SI.
Le troisième constat est donc l’éphémère (besoin, produits, services) qui devient de plus en plus présent. Il est ainsi nécessaire d’être de plus en plus réactif pour s’adapter et évoluer rapidement face à ces changements permanents.
4. L’innovation permanente
Le numérique engendre aussi une accélération de l’innovation. Il rend accessible au plus grand nombre la possibilité de réinventer son quotidien. Cette accélération permanente rend plus rapidement obsolète l’invention d’hier.
Qui aurait en effet pensé que nous allions pouvoir partager nos appartements il y a 10 ans ? Qui aurait pensé que payer sa place de parking se ferait sur son téléphone ? Et surtout qui aurait pensé qu’un téléphone deviendrait l’accès privilégié à toutes nos innovations de demain ?
Le dernier constat est donc l’innovation permanente. Comme pour l’instantanéité, cela génère un besoin de flexibilité et de rapidité fort pour pouvoir suivre le rythme d’innovations imposé par le monde digital.
5. La capillarité de la donnée
Quel est le point commun aux constats précédents ? La donnée. La donnée est présente dans tous les processus et tous les usages en contact ou non avec le client. Ainsi la donnée, par nature, telle la propagation d’un liquide sur une surface, oblige à s’interroger sur les briques du SI qui l’utilisent pendant ces processus et ces usages : c’est la capillarité des données.
Ensuite avec de l’expertise et de la méthodologie, tout s’enchaîne! La définition des besoins et la conception fonctionnelle au travers du prisme “donnée” dans une vision d’ensemble, feront que naturellement par capillarité, vous adresserez le cycle de vie de la donnée, sa valeur et l’architecture de votre SI pour répondre à ces besoins.
Survivre grâce au SI Data Centric
Dans ce contexte de surabondance, d’éphémérité et d’innovation permanente, comment alors maîtriser son patrimoine de données ? Il s’agit de raisonner données et non plus SI. L’objectif devient la gestion de la donnée. Se poser la question de comment gérer des données permet en effet d’adresser ces changements détaillés précédemment et par capillarité, le SI. Un SI centré sur les données est donc le moyen d’adresser ces vagues de changements et de résister aux éléments. En effet, gérer les données impliquent des notions d’unicité, de qualité, de volumétrie, de performance, de confidentialité, d’échanges, de réglementations. L’amélioration de la conception du SI pour faire face à ce nouveau contexte est donc immédiate.
Les fonctions à adresser par le SI, qu’elles soient métiers ou techniques, et la gouvernance nécessaire à la gestion des données vont soulever des questions qui permettront d’adresser ce nouveau contexte d’éphémérité et de surabondance. L’innovation permanente oblige, elle, à industrialiser la livraison des nouvelles fonctionnalités de ce SI centré sur les données. Le SI se construit ainsi autour de la donnée : flexible, modulaire, et industrialisé. Par exemple des référentiels (produits, clients, fournisseurs, etc.) sont mis en place, garantissant la qualité et la mise à jour des données utilisées par toute l’entreprise. Un autre exemple est que les données collectées sont conservées à un seul endroit brutes puis standardisées pour identifier les relations entre elles. Ou encore des outils permettant d’avoir la définition, le cycle de vie et le propriétaire de chaque donnée sont déployés. Le SI devient ainsi un SI centré sur les données. (“Data Centric”).
Il s’adaptera donc naturellement aux futurs changements du marché grâce à tout ce qu’implique la donnée. Il devient un socle solide adressant différents usages sans forcément avoir besoin de transformation en profondeur, longue et coûteuse. Pourquoi ? Car encore une fois, gérer une donnée et faire en sorte qu’elle soit collectée, de qualité, sous contrôle, disponible partout en temps réel et en unitaire ou en masse, intégrées aux processus cœur de métier de l’entreprise, est universel et adaptable à tout usage.
Intrinsèquement la donnée est agnostique de l’usage qu’elle sert. C’est le SI Data Centric qui garantit cette fonction, et assure la survie de l’entreprise dans la jungle digitale.
Conclusion
S’impliquer fortement dans l’évolution du SI est donc nécessaire. L’objectif est de commencer petit mais de commencer Data Centric. Usage après usage, votre SI se construit toujours plus résilient aux différentes vagues de cet océan de données. Un autre bénéfice, et non des moindres : l’innovation des équipes n’étant plus ralentie par le SI, elle s’en trouve ainsi décuplée.
Construire un SI Data Centric, c’est la garantie d’avoir un SI modulaire et adaptable qui répond aux enjeux d’aujourd’hui et de demain. Il est ainsi une base solide sur laquelle construire la pérennité de l’entreprise dans ce nouveau contexte.
Nous aurions pu dresser ici un panorama des technologies, mais mis à part l’intérêt artistique de la présentation, même si l’analyse de notre exemple est très pertinente, sa plus-value en termes d’architecture s’en serait trouvée limitée (1).
Certains proposent une vision basée sur les prérogatives technologiques.
Cette approche (2) oublie la finalité du stockage de la donnée et ne propose qu’un nombre limité de solutions. Nous préférons donc proposer une approche axée sur l’usage de la donnée et sur le besoin utilisateur…
Faisons un rapide tour d’horizon des technologies
Aujourd’hui lorsque nous parlons de data stores, plusieurs familles sont représentées :
Les bases de données relationnelles : Oracle, SQLServeur, MySQL, PostgreSQL, …
D’autres technologies (de stockage ou autres) qui, même si elles permettent de répondre à certains besoins, ne sont pas réellement des bases de données : AWS S3, Azure Blobstorage, Stockage HDFS, Elastic Search, …
Bref, plus de 350 bases de données sont répertoriées à ce jour. Certaines sont uniquement disponibles en PaaS, d’autres sont hybrides et certaines plus traditionnelles ne sont pas éligibles au Cloud(3). Il est donc indispensable de construire une méthodologie qui permette de choisir la technologie qui réponde au besoin.
Pas facile de faire son choix !
Répondre à notre question initiale est bien plus complexe aujourd’hui qu’il y a quelques années, tant les usages ont évolués et les technologies se sont multipliées.
Toutefois pour ne pas se tromper, les bonnes questions à adresser en amont sont les suivantes :
De quelle manière l’application va-t-elle consommer les données : via des appels directs, une couche d’API, des requêtes GraphQL ?
Est-ce que les fonctionnalités attendues doivent être portées uniquement par la base de données ? Ou est-ce que des composants supplémentaires sont nécessaires ?
Est-ce que les transactions doivent être ACID (4) ?
A quelles contraintes du théorème CAP(Consistency, Availability, Partition tolerance) (5) la base de données doit-elle répondre en priorité ?
Quelles structures ou formats de données se prêtent le mieux à l’usage demandé : clé/valeur, colonne, document ou encore graph ?
Quelle va être la volumétrie de ces données ? Quels sont les besoins en termes de performances, de résilience ?
Pour quel type d’usage ? (Décisionnel ? Transactionnel ? Événementiel ?)
Pour quelle nature de données ? (IoT ? Géographiques ? Coordonnées GPS ? Données chronologiques ? Spatio-temporelles ?)
D’autres considérations doivent également être prisent en compte :
Quel sera l’écosystème dans lequel va être hébergée mon application (Cloud ou On Premise) ?
Y a t’il besoin d’accéder aux données lorsque l’application est déconnectée de la base de données ?
Est-ce que je souhaite m’inscrire dans un écosystème intégré (certains éditeurs fournissent des composants qui n’ont plus rien à voir avec le stockage de la données (6)) ?
Quel est le niveau de maturité des équipes de développement, des équipes chargées d’assurer le RUN et l’assistance technique ?
Quel est le niveau de sécurité à appliquer pour protéger les données ?
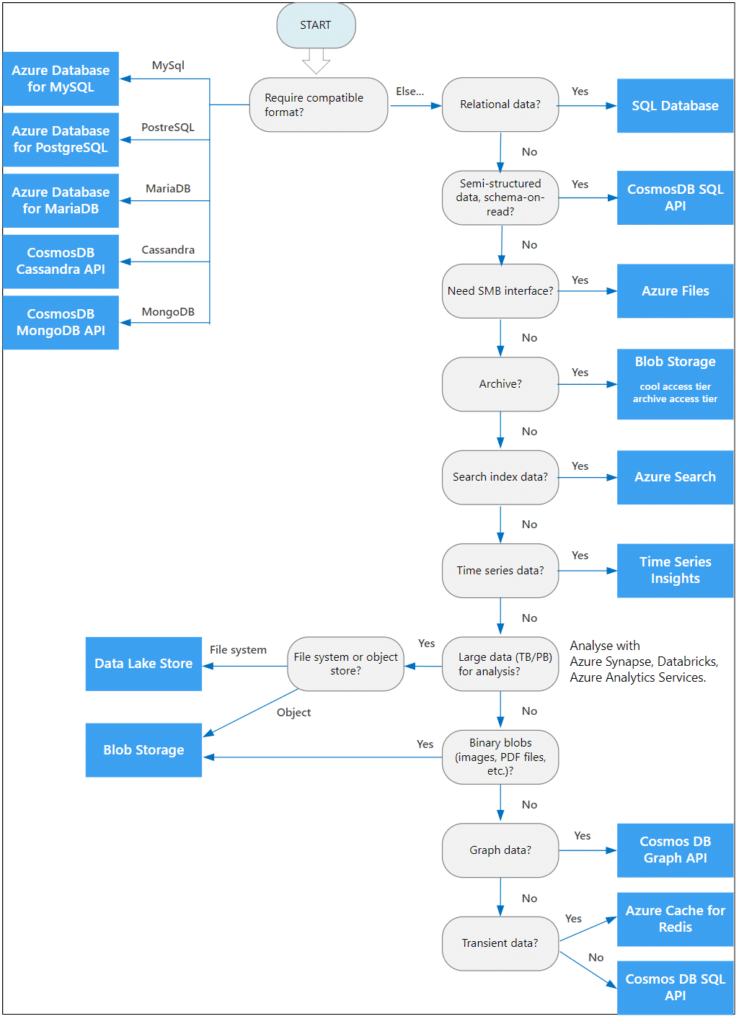
Au cas par cas, suivant l’usage qui sera fait des données, selon le type des données, selon le niveau de protection nécessaire, nous vous conseillons de construire un arbre de décision cohérent avec l’ensemble des contraintes à appliquer.
Dans certains cas, la solution pour simplifier la spécialisation du stockage sera complétée par une orientation microservice. Cette approche permettra d’exposer et de consommer les données de manière beaucoup plus souple qu’avec l’approche monolithique traditionnelle (un seul data store pour toutes vos données).
Pour en savoir plus sur ces sujets, nous vous invitons à consulter nos articles dédiés :
La solution, concentrez-vous sur le besoin initial
Que l’on se le dise, il n’y aura pas de solution permettant de répondre à l’ensemble des besoins. Les projets qui réussissent sont ceux qui se concentrent sur le besoin initial, prennent en compte le savoir-faire de l’équipe en charge du projet et qui, lorsque le besoin évolue, complètent leur architecture en restant concentrés sur le besoin métier.
En conclusion, la solution de stockage ne doit pas être choisie uniquement en fonction des contraintes technologiques, mais bien en fonction de l’usage qui sera fait de la donnée.