
14 décembre 2020
– 2 min de lecture
Sébastien Grenier-Fontaine
Nous aurions pu dresser ici un panorama des technologies, mais mis à part l’intérêt artistique de la présentation, même si l’analyse de notre exemple est très pertinente, sa plus-value en termes d’architecture s’en serait trouvée limitée (1).

Certains proposent une vision basée sur les prérogatives technologiques.
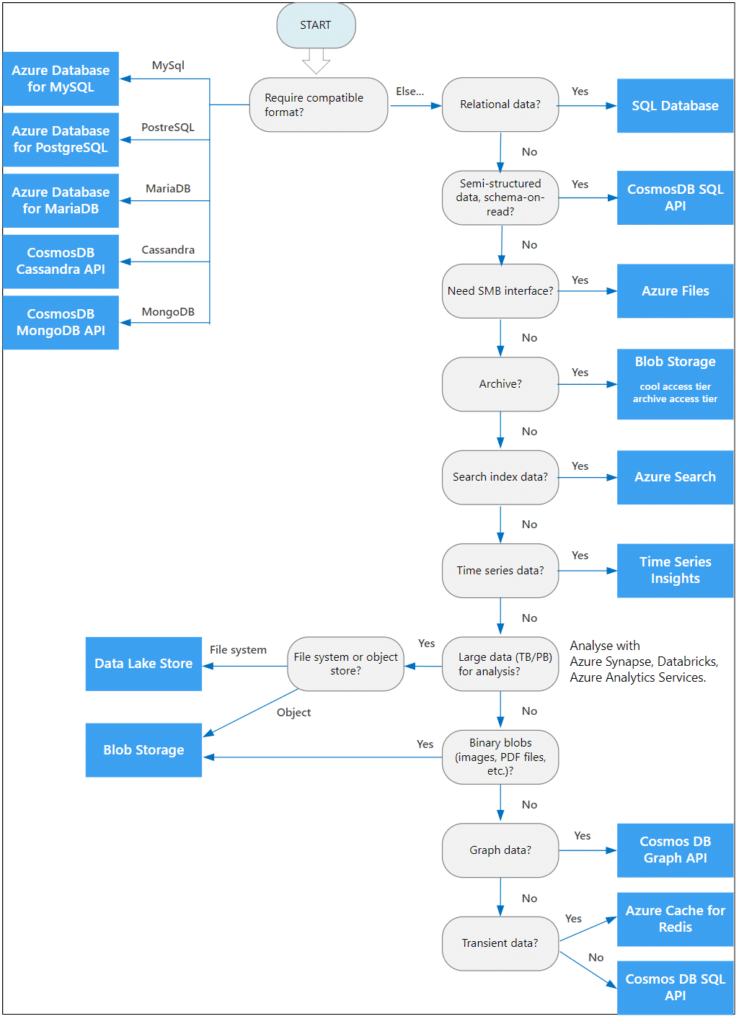
Cette approche (2) oublie la finalité du stockage de la donnée et ne propose qu’un nombre limité de solutions. Nous préférons donc proposer une approche axée sur l’usage de la donnée et sur le besoin utilisateur…
Faisons un rapide tour d’horizon des technologies
Aujourd’hui lorsque nous parlons de data stores, plusieurs familles sont représentées :
- Les bases de données relationnelles : Oracle, SQLServeur, MySQL, PostgreSQL, …
- Les bases de données NoSQL (colonne, document, clé/valeur, graphe, …) : MongoDB, Cassandra, Redis, Couchbase, SQream DB, Neo4j, Azure Cosmos DB, Amazon DynamoDB, Marklogic, …
- D’autres technologies (de stockage ou autres) qui, même si elles permettent de répondre à certains besoins, ne sont pas réellement des bases de données : AWS S3, Azure Blobstorage, Stockage HDFS, Elastic Search, …
Bref, plus de 350 bases de données sont répertoriées à ce jour. Certaines sont uniquement disponibles en PaaS, d’autres sont hybrides et certaines plus traditionnelles ne sont pas éligibles au Cloud(3). Il est donc indispensable de construire une méthodologie qui permette de choisir la technologie qui réponde au besoin.
Pas facile de faire son choix !
Répondre à notre question initiale est bien plus complexe aujourd’hui qu’il y a quelques années, tant les usages ont évolués et les technologies se sont multipliées.
Toutefois pour ne pas se tromper, les bonnes questions à adresser en amont sont les suivantes :
- De quelle manière l’application va-t-elle consommer les données : via des appels directs, une couche d’API, des requêtes GraphQL ?
- Est-ce que les fonctionnalités attendues doivent être portées uniquement par la base de données ? Ou est-ce que des composants supplémentaires sont nécessaires ?
- Est-ce que les transactions doivent être ACID (4) ?
- A quelles contraintes du théorème CAP(Consistency, Availability, Partition tolerance) (5) la base de données doit-elle répondre en priorité ?
- Quelles structures ou formats de données se prêtent le mieux à l’usage demandé : clé/valeur, colonne, document ou encore graph ?
- Quelle va être la volumétrie de ces données ? Quels sont les besoins en termes de performances, de résilience ?
- Pour quel type d’usage ? (Décisionnel ? Transactionnel ? Événementiel ?)
- Pour quelle nature de données ? (IoT ? Géographiques ? Coordonnées GPS ? Données chronologiques ? Spatio-temporelles ?)
D’autres considérations doivent également être prisent en compte :
- Quel sera l’écosystème dans lequel va être hébergée mon application (Cloud ou On Premise) ?
- Y a t’il besoin d’accéder aux données lorsque l’application est déconnectée de la base de données ?
- Est-ce que je souhaite m’inscrire dans un écosystème intégré (certains éditeurs fournissent des composants qui n’ont plus rien à voir avec le stockage de la données (6)) ?
- Quel est le niveau de maturité des équipes de développement, des équipes chargées d’assurer le RUN et l’assistance technique ?
- Quel est le niveau de sécurité à appliquer pour protéger les données ?
Au cas par cas, suivant l’usage qui sera fait des données, selon le type des données, selon le niveau de protection nécessaire, nous vous conseillons de construire un arbre de décision cohérent avec l’ensemble des contraintes à appliquer.
Dans certains cas, la solution pour simplifier la spécialisation du stockage sera complétée par une orientation microservice. Cette approche permettra d’exposer et de consommer les données de manière beaucoup plus souple qu’avec l’approche monolithique traditionnelle (un seul data store pour toutes vos données).
Pour en savoir plus sur ces sujets, nous vous invitons à consulter nos articles dédiés :
- Comment bien découper en micro services ?
- Les Grands principes de réussite de votre projet plateforme Data Centric
La solution, concentrez-vous sur le besoin initial
Que l’on se le dise, il n’y aura pas de solution permettant de répondre à l’ensemble des besoins. Les projets qui réussissent sont ceux qui se concentrent sur le besoin initial, prennent en compte le savoir-faire de l’équipe en charge du projet et qui, lorsque le besoin évolue, complètent leur architecture en restant concentrés sur le besoin métier.
En conclusion, la solution de stockage ne doit pas être choisie uniquement en fonction des contraintes technologiques, mais bien en fonction de l’usage qui sera fait de la donnée.
1 : https://mattturck.com/data2020/
2 : https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-decision-tree#feedback
3 : https://db-engines.com/en/ranking
4 : https://fr.wikipedia.org/wiki/Propri%C3%A9t%C3%A9s_ACID
5 : https://fr.wikipedia.org/wiki/Th%C3%A9or%C3%A8me_CAP
6 : https://www.mongodb.com/cloud/stitch




