
29 octobre 2024
Rhapsodies Digital
Antoine Belluard
Responsable technique Rhapsodies Digital
À Rhapsodies Digital, on aime construire des solutions numériques (oui oui), et on s’est dit qu’on avait envie de partager dans le détail ce qu’on fait. C’est donc avec une série d’articles que l’on va soulever le capot, et présenter les détails techniques de nos travaux.
On va commencer par parler de notre projet Solertia (car il est tout frais, le MVP vient de sortir), de son archi, le back, le front, et de comment on a fait tout ça.
Solertia, projet visant à lister, catégoriser et présenter des entreprises au savoir-faire exceptionnel, est aussi notre premier vrai projet interne, imaginé et réalisé par une équipe très réduite, mais passionnée !
On y va ?
Boring or not boring ?
Le choix de l’ennui : côté application
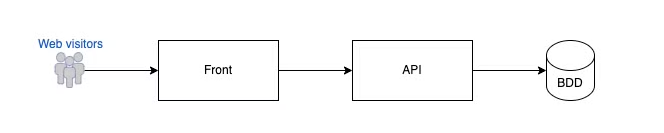
Le projet Solertia en gros résumé
À première vue, le projet présente une architecture très classique, avec un socle API et base de données consommée par un front.
L’avantage, c’est que si, un jour, on a envie d’exposer et de monétiser nos données, c’est presque déjà fait (bon, moyennant un système d’authentification et de rate-limit bien évidemment…). Et ça tombe bien, car c’est également une des ambitions du projet.
Autre avantage, notre front n’étant qu’une couche de présentation, il ne fera pas d’écriture sur nos données, tout comme les clients potentiels de notre API, on peut donc, sans vergogne, couper en deux nos routes et ajouter une protection supplémentaire sur tout ce qui est POST/PUT et DELETE.
Notre API/Back, sera de plus un proxy pour récupérer et agréger de la data sur nos fameuses entreprises, avec notamment des connexions API avec Pappers (et d’autres sources de données qui arriveront par la suite).
C’est pour cela que le full monolithe (bien qu’avec beaucoup d’avantages, on le rappelle, utilisé par exemple chez Stackoverflow), n’a pas retenu mon attention ici.
Le choix de l’ennui : côté base de données
TL;DR : j’aime bien PGSQL.

Une de mes technos préférées, je dois l’admettre, est PostgreSQL. Robuste, ultra-performante, sécurisée et éprouvée, les nombreuses qualités de cette base de donnée relationnelle open source ne sont plus à présenter.
Son excellente gestion du JSON, avec bon nombre de fonctions et d’opérateurs prêts à l’emploi (on en parlera plus en détails sur la partie backend), peuvent permettre, par exemple, de créer des requêtes dont le résultat est directement mappables sur un DTO.
Concernant le volume de données, quelques milliers d’entreprises, il me paraissait overkill d’utiliser ElasticSearch pour l’instant (qui nécessite son serveur et donc sa maintenance — ou alors des solutions SaaS hors de prix (coucou Algolia/Melisearch)), sachant que PG dispose d’un excellent module de recherche fulltext.
Puisqu’on a évoqué un peu de NoSQL, je n’ai pas retenu cette solution non plus, car on a quand même pas mal de relations à gérer, et n’étant pas non plus un fana des micro-services (quand ce n’est pas nécessaire), je n’avais pas envie de m’embêter à ce niveau-là. PostgreSQL est mon choix rationnel, par défaut, quand je cherche une base de donnée.
Car oui, il faut le reconnaître, le NoSQL est sexy et a d’autres avantages, et match très bien quand on a moultes services qui ont leur propre système de stockage. Mais bien souvent, ce n’est qu’une question de préférence sur la modélisation, au final, on peut très bien faire du NoSQL sur PG.
Comment qu’on se cache
TL;DR : un jour oui, mais pas maintenant.
Actuellement, le projet ne dispose pas d’un système de cache applicatif, autre que ce que les technos choisies font nativement. Nous verrons après le lancement du projet, car on aime bien itérer et donc pour l’instant, on préfère avoir notre BDD en frontal de notre API.
Parce que oui, développer un système de cache, ce n’est pas auto-magique, il ne suffit pas d’installer l’excellent Redis et hop, c’est fait. Il y a du code à écrire, et pas mal de cas à gérer, ainsi qu’une dépendance et un serveur supplémentaire.
Parlons technos applicatives !
Le choix du compilé côté Backend

S’il y a bien une chose que j’ai comprise au cours de mes derniers projets, c’est que l’interprété, c’est pratique, mais c’est coûteux en performance et donc en serveur.
Côté API, il est absolument vital que les performances soient au RDV, car c’est notre backend, c’est ce qui va exposer nos données, et c’est ce qui sera le plus gros bottleneck de notre architecture.
Ce que j’aime bien avec les exécutables, c’est qu’après avoir target une plateforme, on a pratiquement besoin de rien sur le serveur pour le faire tourner, couplé avec supervisord par exemple, on peut également avoir rapidement un système simple, auto-gérable. Le choix de docker en prod est par ailleurs plus envisageable, il suffit d’une alpine vanilla et c’est parti.
Les choix évidents : Rust vs Go
Secrètement, cela fait des années que je me forme au langage Rust, que j’adore et dont j’admire le design. Gestion de la mémoire fine sans garbage collector, syntaxe élégante, typage strict, friendly compilateur, zero-cost abstractions et performances proches du C/C++.
Néanmoins, son gros (et peut-être seul ?) défaut reste son niveau d’adoption professionnelle. Bien qu’on dénombre de plus en plus de success story après un passage à du Rust (Discord, AWS, Kernel Linux, 1Password…), le nombre de développeurs est actuellement limité, et la gymnastique mentale nécessaire pour coder en Rust est importante.
Je suis convaincu que le jour où on sera plus nombreux, je pousserai fort pour que l’on puisse construire nos backend en Rust pour participer également à la popularisation de ce langage.
Surtout que tokio (les créateurs de l’async sur le langage), avance à grands pas avec son framework web ultra-performant axum, qui je pense va tout éclater sur son passage. À l’heure où j’écris ces lignes, le projet est en v0.9.3.
Le vainqueur rationnel : Go
Et donc oui, spoiler alerte, le backend de Solertia est écrit en Go.
Rebuté par sa syntaxe dans un premier temps, loin d’être élégante, force est de constater que le langage est populaire. Certainement causé par la réécriture de pas mal de backend PHP/Nodejs/Java et avec un Google en back.
Il s’est rapidement imposé, comme un bon compromis simplicité d’utilisation/performances.
Bien qu’on s’écarte sensiblement des performances de Rust, il est sympa de voir que des calls API sont de l’ordre de la milliseconde, avec des appels BDD derrière de la transformation de data. Surtout une belle économie de CPU/RAM, juste parce qu’on utilise mieux les ressources et qu’on a besoin de peu de dépendances (genre curl en fait) sur le serveur.
Côté langage, Go est également typé strictement et se veut surtout une boîte à outils complète côté network. Et là oui, pour faire du web, c’est simple, nativement tout existe déjà dans le STD. De plus, sa gestion de la concurrence le rend très cool à utiliser.Côté librairies/framework, on est aussi très bien, avec bon nombre de choses qui existent (forcément, car le gros du truc est déjà présent dans le langage). Ici, on va juste teaser, en disant qu’on a un framework web (Gin), un semi-ORM un peu naze, mais pratique pour les migrations (Bun) et un truc génial pour auto-générer la documentation OpenAPI à partir de nos DTO d’entrée et de sortie (Huma).
NodeJS et Astro pour le front
Je vais vous l’avouer, je n’ai jamais été très grand partisan de NodeJS (étant plus côté PHP historiquement).
On peut néanmoins reconnaître que son extrême popularité a généré tout un tas de truc quand même bien cool comme Typescript et Astro, excellent framework web que l’on m’a fait découvrir très récemment (big-up à Renaud qui se reconnaitra s’il est dans les parages !). Et également, côté performance, il ne se défend pas si mal que ça. Le souci, c’est qu’on paie ça avec un nombre absolument dingue de dépendance nécessaire.
Mais l’histoire de ce choix est, en réalité, un peu plus complexe que ça.
Un truc que fait très bien Astro, c’est la génération d’un build statique (du pur HTML/CSS avec un très peu de javascript côté client). Et ça, pour le coup, j’aime bien, car ça me rappelle le côté exécutable, presque ennuyeux, prêt à l’hébergement sur un bucket (par exemple), avec 0 dépendances côté serveur et des performances forcément extraordinaires.
Le seul “soucis”, c’est que c’est complexe à mettre en place quand on a du contenu dynamique. On n’a ici pas des masses de choix :
- Option A : On (re)génère des portions ou l’intégralité du site via des Hook et autre système automatisé dès que la data change.
- Option B : On fait nos appels API côté client.
La deuxième solution ne me plait guère, car cela veut dire que si on veut implémenter un rate-limit pour protéger et monétiser notre API, les conséquences seront subies côté client (ou alors, on ajoute un BFF, mais ça nécessite une autre app et donc de la complexité), et qu’on va nécessairement perdre de la performance et donc l’intérêt d’un build statique.
Donc, je suis plutôt partisan ici de la première solution, sauf que c’est quand même assez compliqué à mettre en place, surtout qu’on a, en plus, un moteur de recherche à implémenter (oui, des solutions pour le build statique existent, mais on verra plus tard !).
Limités par le temps et les ressources de développement, on va donc la jouer interprété côté serveur, avec les technos qui permettent de générer un static, et on migrera vers cette solution par la suite, ça, c’est certain.
Et PHP alors ?
Croyez-moi bien qu’avec mes 8 ans d’xp en développement PHP/Symfony (et j’adore le langage depuis sa version 7), cette piste a été étudiée, finalement rejetée, car j’avais envie d’expérimenter d’autres choses, principalement pour ouvrir mes chakras (bien qu’elle fonctionne très bien !).
De plus, pour la génération de build statique (qui est, rappelons-le, notre cible idéale), on a des solutions qui sont, selon moi, bien moins éprouvées que côté NodeJS. Et de toute façon, on a de l’interactivité forte côté UI, donc on aura forcément besoin de JavaScript.
Le Backoffice
Ce qu’on a dit jusqu’à présent, c’est super, mais il faut quand même à un moment pouvoir administrer nos données, car ça ne se fait pas tout seul (dommage…).
Et bon, ouvrir un éditeur de base de données et faire les modifs comme ça, directement en prod, c’est bien nature, un peu trop à mon goût.
Le p’tit soucis, c’est que faire un back-office, c’est pénible car :
- Peu de valeur quand il s’agit d’un CRUD classique (c’est notre cas).
- Peu de valeur quand c’est en usage interne, on ne va pas le vendre ni le faire utiliser à d’autres personnes (c’est notre cas).
- Les formulaires ajoutent toujours de la complexité, d’autant plus que ça prend du temps.
- Oui, on a plein de générateurs de BO qui existent pour se simplifier la vie, mais cela reste une app et donc un truc à maintenir.
Si seulement il existait des solutions qui permettent de faire du drag & drop de composants, de gérer l’authentification et les droits des utilisateurs, de créer des formulaires en 4 clics, plug & play sur n’importe quelle API, ça serait vraiment cool pour notre use case !
Ah, mais si ça existe et ça s’appelle Retool !
Grâce à cet outil et à sa version gratuite, on a pu monter un BO en quelques jours, autour des endpoints d’écriture de notre API. Sa base est solide pour faire des formulaires et des listings simples, sur les résultats de notre API. On définit les endpoints, on map les champs sur les inputs et pouf, ça marche.
Après, il y a quand même des désavantages par rapport à un BO développé maison, certaines choses m’ont bien frustré, comme l’absence de gestion avancée des images par exemple, car le système ne propose qu’un bête input d’upload de fichier, exit donc les jolis croppers et les résolutions fixes en fonction du champ.
Une infra (plutôt) simple
Avant de terminer cet (long) article, j’aimerais tout même partager quelques mots sur l’infra choisie pour l’hébergement du projet.
Étant très sensible à la philosophie Dev Ops, mais avec des connaissances limitées en Infra as Code (IAC) et en administration réseau, j’avais tout même envie d’un environnement propre avec, surtout, de la facilité au niveau du déploiement. L’IAC puisqu’on en parle, est, selon moi, l’un des aspects les plus importants à mettre en place, parce qu’elle constitue une description exhaustive de ce qui est online.
Côté hébergement, cela fait maintenant quelques années également que j’évolue dans des environnements “cloud”, où l’approche budgétaire et la grande flexibilité sous-jacente permettent d’appliquer l’agilité et l’itération plus facilement au domaine du système, notamment encore fois, lorsque les forces vives sont réduites. Il était donc naturel pour moi d’implémenter ces outils pour Solertia.
Le Cloud de Scaleway
Etant plutôt à l’aise avec les services d’AWS, j’ai également voulu innover, et de tester les services de Scaleway, qui est européen par nature.
On retrouve tout ce qu’il faut pour construire ce que l’on désire ici :
- Containers “serverless” pour pousser des images docker en prod, sans s’embêter avec Kubernetes (quelques défauts néanmoins, comme un manque de flexibilité sur les paramètres de l’autoscaller, et des healthcheck abstraits).
- Containers registry et Bucket (compatible API AWS S3!) pour sauvegarder nos artifacts, backends terraform et par ailleurs assets statiques comme les images.
- Base de données managée PGSQL (uniquement en v15 malheureusement, alors que la 16 est dispo depuis presque un an).
- SDK terraform plutôt bien documenté, qui m’a permis, en ma qualité de gros n00b de cette techno, de faire mon IAC de façon plutôt fluide.
- Monitoring natif sur Grafana, plutôt fourni.
Comme décrit plus haut, j’aime itérer et faire vivre l’architecture, ici, on ne présente que ce qui propulsera le MVP. Il est possible que cela change dans le futur (pourquoi s’en priver ? c’est un des aspects sympa qu’offre le cloud).
Docker couplé avec une CI/CD chez Gitlab
Bon c’est super tout ça, mais je n’aime pas spécialement l’idée de construire mes images docker sur mon poste et de les mettre en prod via la console UI de Scaleway.
Fort heureusement, nous utilisons Gitlab, qui avec sa puissante et beginner-friendly CI/CD m’a permis de mettre en place, pour les deux projets :
- La chaîne de lint, test et build
- La partie déploiement avec upload de l’image sur le registry, modification du projet terraform avec nouvelle version, apply et migrations, base de données (uniquement côté API).
Le cycle quant à lui est honteusement simple : À chaque nouvelle branche, la CI nous dit si c’est bien (ou pas, très objective qu’elle est), et à chaque nouveau tag sur main, ça déploie.
La full picture
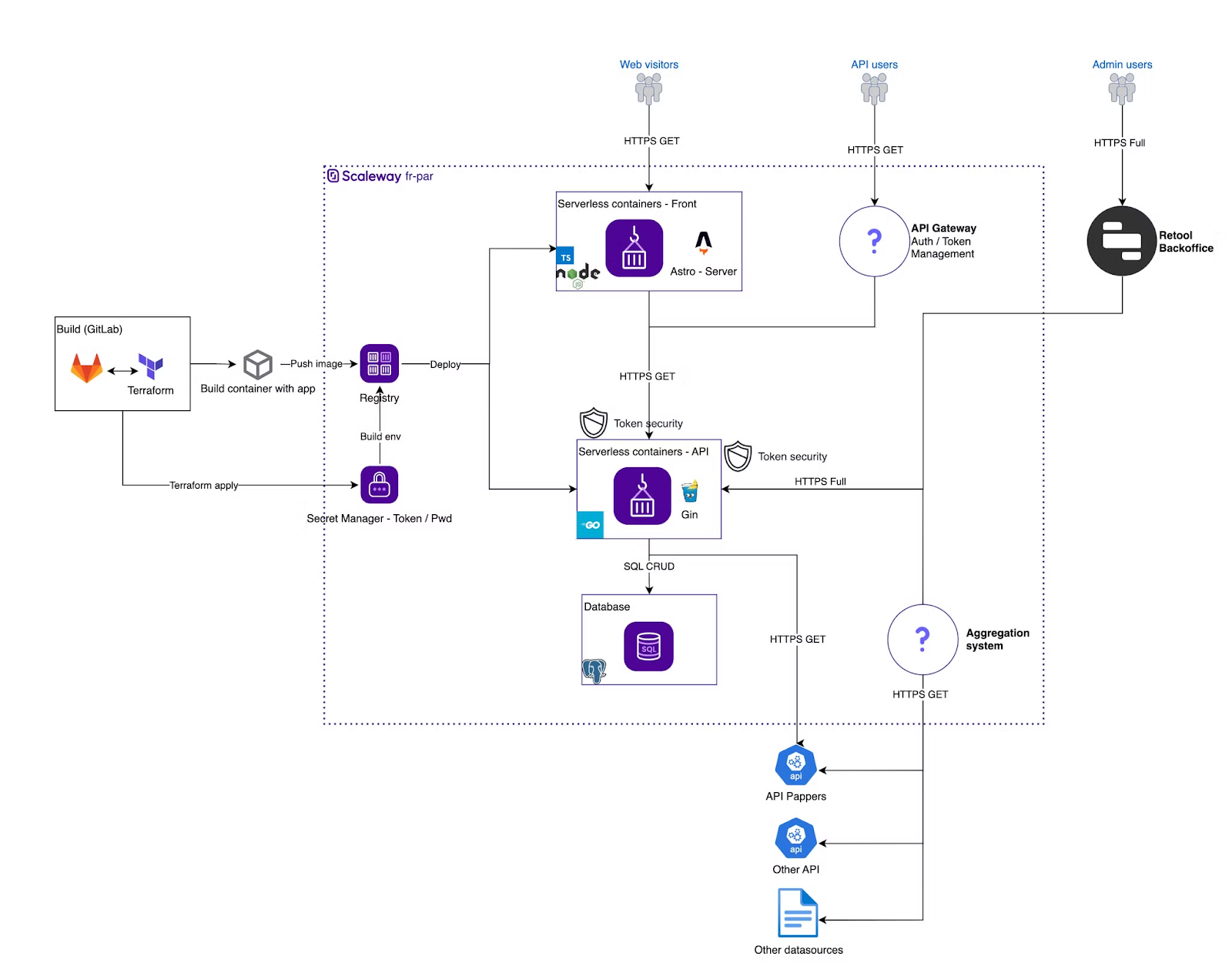
Pour conclure, ce qu’il va falloir améliorer
Voici une mini-liste non exhaustive de ce que j’ai mal/pas fait, et que j’aimerais donc pousser par la suite :
- L’auto-scalling et healthcheck côté containers, trop obscure actuellement.
- Le cache, mais on en a déjà parlé.
- Instant T-Shirt XXL : Faire un build statique pour le front, et donc enlever un serveur traditionnel.
Merci de m’avoir lu !
Écrit par Antoine Belluard – Responsable technique chez Rhapsodies Digital, j’ai une dizaine d’années d’expérience dans le développement informatique. Passionné par la programmation et la technologie, et poussé par un fort impostor-syndrome, je suis en apprentissage continu.