
8 juin 2021
– 6 min de lecture
Jean-Baptiste Piccirillo
Manager Transformation Data
La data science est devenue un levier clé aujourd’hui, pour mettre les données au service de bénéfices et de problématiques métiers : Automatisation de tâches & de choix, Fourniture de nouveaux services « intelligents », Amélioration de l’expérience client, Recommandations, etc.
C’est aussi une discipline qui passionne par son caractère particulièrement « innovant », encore aujourd’hui, mais qui génère des croyances sur ce qu’elle peut réellement apporter à une organisation. Certains dirigeants ont souvent donné trop de valeur intrinsèque à la discipline, s’attendant à des retours importants sur leurs investissements (data lake & armées de data scientist / engineers).
En réalité, la Data Science n’est qu’une technique qui a besoin de méthodologie et de discipline. A ce titre, elle nécessite au préalable de très bien définir les problèmes métiers à résoudre. Et quand bien même le problème est bien défini, et le modèle statistique pour y répondre performant, cela ne suffit pas encore. Le modèle doit être utilisable « en pratique » dans les processus métiers opérationnels, s’intégrer parfaitement dans l’expérience utilisateur, etc.
Quels principes clés peut-on se proposer d’appliquer pour maximiser la valeur de cette capacité ? Essayons ici de donner quelques pistes.
Comprendre le métier : analyser les risques, les besoins d’optimisation, les nouvelles opportunités
L’identification d’usages métier, qui nécessitent des méthodes d’analyse de données avancées, est une étape clé. Ces usages ne tombent souvent pas du ciel. Une démarche proactive avec les métiers est nécessaire pour les identifier. C’est d’autant plus vrai lorsque le métier est encore peu familiarisé avec les techniques de data science, et ce qu’il est possible d’en tirer concrètement.
C’est un travail de “business analysis”, dont la Data Science n’a absolument pas le luxe de se passer contrairement à ce qui est pratiqué parfois : Comment travaille le métier aujourd’hui ? Quels sont ses enjeux, ses drivers, ses axes d’innovation, ses axes d’optimisations des processus opérationnels en place, et quelles données sont manipulées aujourd’hui, comment et pour quoi faire ? Quel est le niveau de qualité de la donnée, manque-t-il des informations clés pour répondre aux problèmes quotidiens, ou pour innover ? etc.
Quand on est au clair sur toutes ces questions, on est prêt à identifier des usages concrets avec le métier, qui pourraient bénéficier de techniques d’analyse avancée.
Comprendre l’usage et le système concerné : adopter le point de vue systémique !
Imaginons que nous cherchons à prédire le flux de patients sur un jour donné dans un hôpital, afin d’adapter les ressources, les processus, les dispositifs pour limiter le temps d’attente. Il convient, avant de foncer tête baissée dans l’analyse des données, de comprendre l’ensemble de la problématique. Par exemple, les approches de « system thinking » peuvent être tout à fait adaptées pour que le data scientist s’assure de ne pas oublier de paramètres clés dans la dynamique du problème qu’il veut résoudre. Ainsi, il n’oubliera pas non plus des données clés pour son modèle (existantes ou dont il faudrait organiser la collecte à l’avenir pour améliorer le modèle).
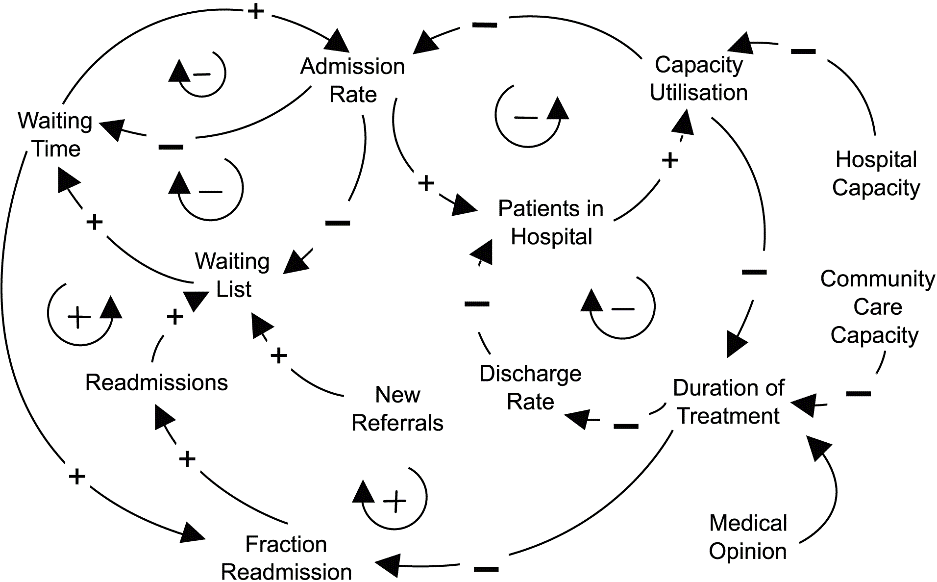
Ce type de représentation (ici : Causal loop diagram), peut permettre au métier de s’exprimer sur le processus, sur l’identification des variables clés, et de formuler ses intuitions sur les paramètres et les dynamiques en jeu qui peuvent influer sur la variable à prédire ! (ici les influences positives ou négatives entre les variables structurantes décrivant la dynamique du système).
Le diagramme ci-dessus n’est qu’un exemple de représentation systémique, on peut adopter d’autres types de représentation du système au besoin. L’important étant d’étendre la compréhension du système, qui peut nous amener à identifier des variables cachées (non intuitives a priori).
Concrétiser un usage : prototyper au plus tôt avec le métier, dans son environnement de travail, au risque de rester éternellement au statut de POC !
Une fois que le système est bien défini, et que les hypothèses et intuitions sont posées, il faut comprendre : comment le modèle analytique sera concrétisé en pratique, qui sera l’utilisateur final, quel est son environnement de travail actuel et comment on pourra intégrer les résultats d’un modèle statistique dans son travail quotidien.
Une technique simple et confortable pour le métier : faire un prototype rapide, même avec des fausses données pour commencer, des faux résultats de modèles statistiques. Bref, l’idée est rapidement de se projeter dans l’usage final de la manière la plus concrète possible, pour aider le métier à s’inscrire dans sa future expérience. Évidemment, nous ne resterons pas éternellement avec des fausses données.
L’objectif est d’être tout à fait au clair, dès le départ, sur le produit fini que l’on veut atteindre, et de s’assurer que le métier le soit tout à fait (ce qui est loin d’être toujours le cas). Ensuite, nous pourrons pousser le prototype plus loin (des vrais données, des vraies conditions pour évaluer la performance, etc.).
Cette méthode permet au data scientist de se mettre à la place de l’utilisateur final, et de mieux comprendre comment son modèle devra aider (est-ce qu’il doit apporter juste une classification, un niveau de probabilité, des informations contextuelles sur la décision prise par le modèle, est-ce qu’il doit favoriser le temps de réponse, l’explicabilité, la performance du modèle, etc.). Toutes ces questions trouvent rapidement une réponse quand on se projette dans le contexte d’usage final.
Interagir par itération avec le business, éviter l’effet Kaggle
Nous pouvons rencontrer parfois un comportement (compréhensible), qui est de vouloir faire le modèle le plus performant possible, à tout prix. On passe des heures et des jours en feature engineering, tuning du modèle, on tente toutes combinaisons possibles, on ajoute / teste des données exotiques (au cas où) qui ne sont pourtant pas identifiées en phase de “business analysis”. Je l’appellerai l’effet « Data Challenge » ou l’effet « KAGGLE*».
Et après avoir passé des jours enfermés dans sa grotte, on arrive tout fier devant le métier en annonçant une augmentation de 1% du score de performance du modèle, sans même avoir songé que 1% de moins pourrait tout à fait répondre aux exigences du métier…
Comme on dit… « Le mieux est l’ennemi du bien ». Pour éviter cet effet tunnel qui peut être tentant pour l’analyste (qui veut annoncer le meilleur score à tout prix ou qui joue trop sur Kaggle*), des itérations les plus fréquentes possibles avec le métier sont clés.
Arrêtons-nous au bon moment ! Et cela vaut pour toutes les phases du projet. Commençons par chiffrer le système décrit en phase de business analyse, avec des données réelles, et itérons avec le métier sur cette base. Cela permet d’améliorer déjà la compréhension du problème du data scientist, et du métier concerné. Et cela a déjà une vraie valeur pour le métier ! Alors qu’aucun modèle statistique n’a été conçu pour le moment.
Si un modèle nécessite des données inexistantes, organisons la collecte de ces données avec le Chief data officer, dans le temps. Mais ne nous battons pas à vouloir faire un modèle avec des miettes, si nous savons que cela ne permettra pas d’être à la hauteur des attentes opérationnelles.
Le Data Scientist peut avoir aussi ce réflexe un peu étrange de dire « On va essayer, on va faire avec ce qu’on a et on verra ! » comme s’il croyait lui-même que son métier relève de l’incantation.
Evidemment, je ne fais là aucune généralité. Le rôle d’expert nous oblige à prendre nos responsabilités, et à dire « Non, après examen et quelques tests, je ne suis pas confiant du tout pour répondre à votre besoin avec les données qu’on a aujourd’hui ». Humilité, responsabilité et transparence, à chaque itération avec le métier, sont de mise.
On trouve souvent ce risque de dérive dans la relation Expert vs Métier. Ne tombons pas dans le piège de jouer sur l’ignorance de l’autre pour se créer un travail inutile !
Ces quelques principes sont peut-être évidents pour certains, utiles pour d’autres ! En tous les cas, chez Rhapsodies Conseil, au sein de notre équipe Transformation Data, nous essayons d’appliquer cela systématiquement, et nous pensons que c’est le minimum vital.
- Pour éviter de faire perdre du temps à nos clients (et de l’argent), nous commençons nos missions BI & Analytics, systématiquement avec une « micro mission » préliminaire qui nous permet de valider la réelle valeur & la faisabilité de l’innovation recherchée (avec toutes les parties prenantes, en faisant des analyses flash des données…) avant d’aller plus loin !
- Nous considérons que dans tout projet de Data Science, le prototype métier, tel que décrit dans l’article, est obligatoire. Nous proposons systématiquement un prototypage métier, toujours dans le soucis de bien projeter la valeur attendue pour le métier !
- Nous allons plus loin sur la solution que l’analyse avancée des données. Notre expertise globale sur la transformation data, nous permet y compris sur des missions BI & Analytics, de ne pas hésiter à relever si pertinents des axes clés d’amélioration sur la gouvernance de certaines données, l’organisation, la data quality, la stratégie data long terme de l’organisation ou la culture data de l’entreprise, qui pourraient être profitables ou indispensables à l’usage traité.
Pour nous, traiter un usage BI & Analytics, c’est le traiter dans son ensemble, de manière systémique ! Notre solution finale n’est pas un modèle statistique. Notre solution finale est potentiellement un modèle statistique, mais aussi une gouvernance adaptée pour avoir la qualité de données nécessaire, un modèle qui s’adapte à l’expérience utilisateur souhaitée (et pas l’inverse), et un suivi du ROI de l’usage analytique et de sa pertinence par rapport à la stratégie de l’entreprise.
Les autres articles qui peuvent vous intéresser
26 novembre 2024

Transformation Data
L’IA sera source de valeur si la data est maîtrisée et gouvernée au sein des organisations
15 avril 2024

Transformation Data
Mettre ses données en Open Data : Prérequis et Perspectives – PARTIE 3
22 février 2024

Transformation Data
La Culture Open Source – Partie 2 : Histoire et Lien avec l’Open Data

18 octobre 2023

Transformation Data