
2 décembre 2020
– 5 min de lecture
Erik Zanga
Manager Architecture
Vous avez des APIs pour interconnecter les systèmes ? Parfait c’est une belle première étape. Asseyons-nous maintenant pour parler de résilience et de découplage… Une nouvelle étape s’ouvre : les APIs Asynchrones ? Mais quelle obscure clarté, quelle douce violence est-ce donc que cela ??
Un petit récap, pourquoi parler d’APIs asynchrones ?
Le sujet des APIs asynchrones résonne depuis quelques années dans la tête des architectes, et ces derniers en font de plus en plus un de leurs objectifs : une API, donc un contrat d’interface bien défini, qui s’affranchit des défauts des APIs. Comme disait le sage Bruno dans son article : “Favoriser l’asynchronisme est un bon principe de conception de flux”.
Ce besoin d’éviter un couplage fort et de créer des SAS de décompression entre les différentes applications / parcours est certainement cohérent, mais est à priori en contradiction avec la nature même des API et du protocole HTTP. Alors comment concilier le meilleur de ces deux mondes ?
Commençons par les bases, une API asynchrone, concrètement, c’est quoi ?
Une API asynchrone est une API recevant, par exemple, la commande d’un client, client qui n’attend pas la réponse de celle-ci dans l’immédiat. Le seul retour mis à disposition par l’API, dans un premier temps, est la prise en compte de la demande (un « acknowledgement » : vous avez bien votre ticket, merci d’attendre).
Le fournisseur d’API effectue les actions nécessaires pour satisfaire la requête, sans forcément être contraint par des timeouts, en gros il peut prendre son temps pour en garantir la bonne exécution.
Et dans la pratique ?
En pratique, cette architecture peut être garantie par le couple API qui poste dans une queue / topic assurés par un outil de type MOM.
L’API déverse les informations dans une queue (ou topic) du MOM, informations qui sont ensuite prises en compte suivant les disponibilités des applications en aval. L’application appelée devient un consommateur d’un flux asynchrone, ce qui permet de découpler les deux.
Pour notifier, ça passe crème
Ce type de comportement est facilement mis en place lorsque nous nous trouvons dans des cas de figure non critiques, dans lesquels par exemple on doit notifier un utilisateur LinkedIn de l’anniversaire d’un de ses contacts : en tant que client, tant pis si l’information n’arrive pas, nous pouvons accepter un manque de fiabilité.
Un peu moins quand l’objectif porte sur un échange critique
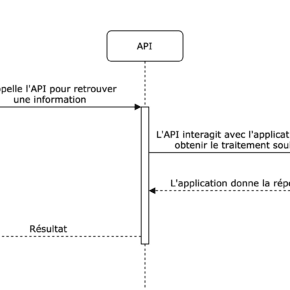
Tout change quand le demandeur s’attend à quelque-chose, soit une information soit une confirmation forte de la livraison de l’information , car cet aspect demeure crucial pour son bon fonctionnement. Dans une API synchrone, nous l’obtenons à la fin de la transaction.
Dans le cas asynchrone, comment garantir le même comportement lorsque la transaction se termine ?
C’est à ce niveau que les avantages de l’asynchronisme induisent une complication de gestion, complication dont souvent les équipes n’ont pas conscience. Une confirmation de réception (“acknowledgement”) est dans ces cas insuffisante (ex. votre transaction bancaire s’est bien passée, comme par exemple un virement).
Mais alors comment notifier le client du résultat ?
La mise en place d’une logique de réponse peut être construite de deux façons différentes.
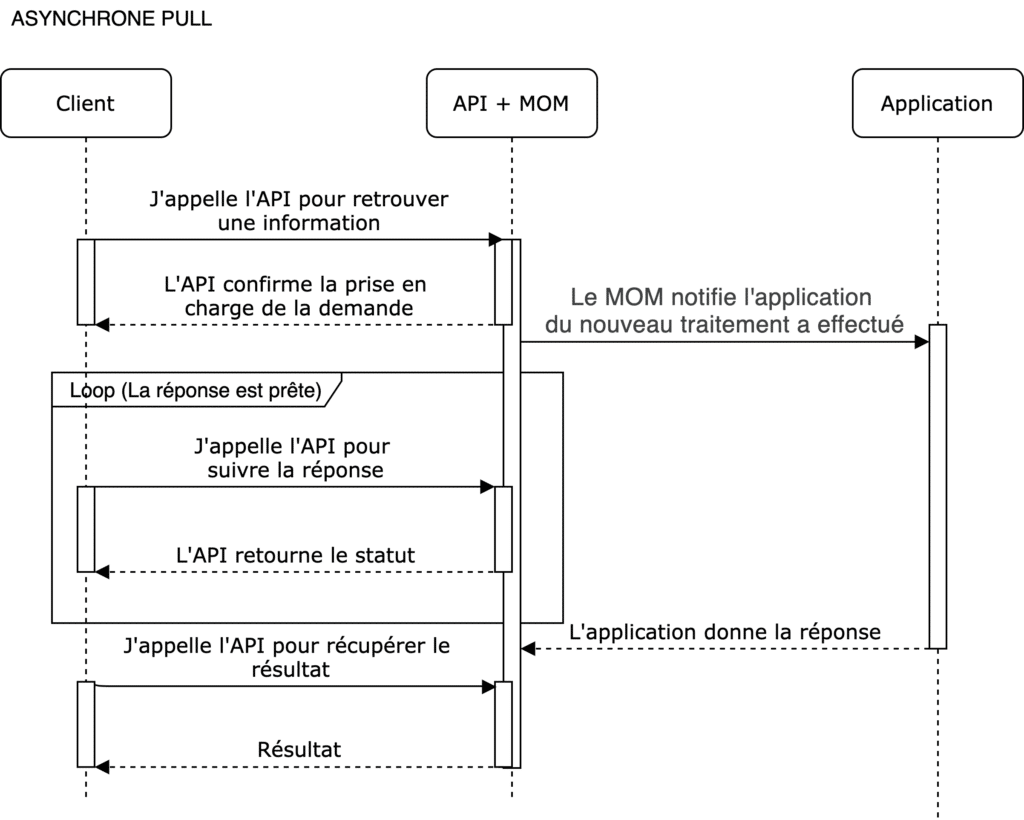
En mode PULL
Le mode pull présuppose que l’action soit toujours à l’initiative du client.
L’API met à disposition le statut de l’action (sous forme de numéro de suivi), sans notifier le client. C’est au client de venir vérifier le statut de sa demande, en faisant des requêtes de suivi à des intervalles réguliers.
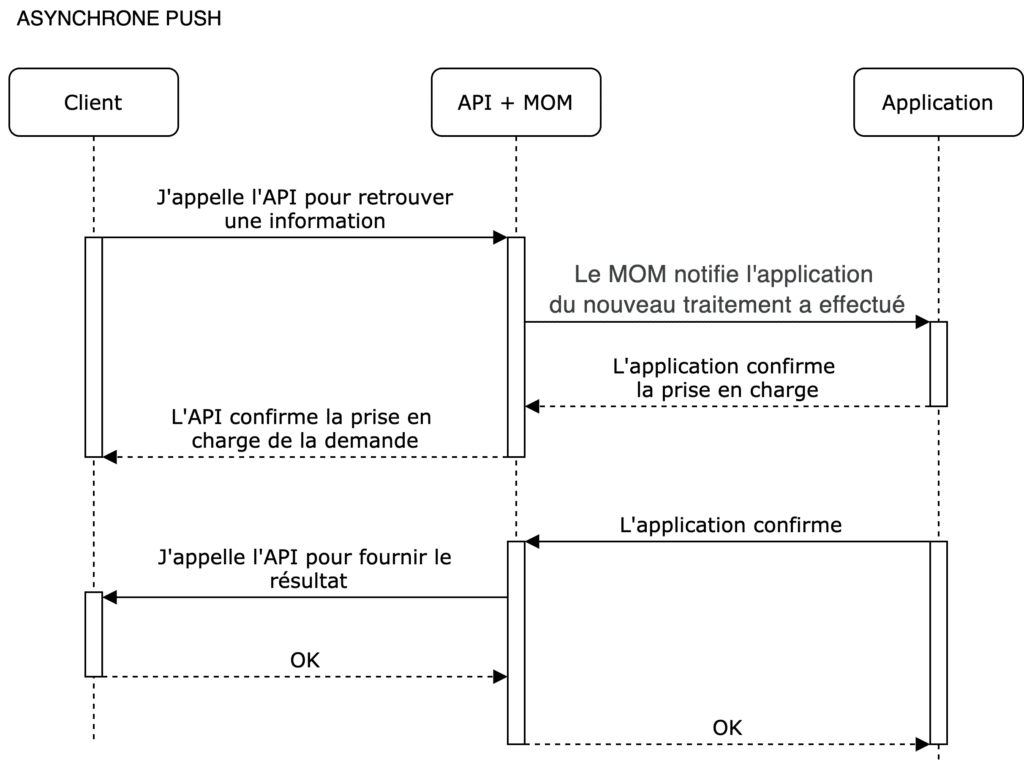
En mode PUSH
Le mode push suppose que le canal de communication soit ouvert dans les deux sens, et que le serveur ne soit pas forcément tenu d’attendre une requête du client pour “pousser” l’information.
Certaines technologies et patterns d’architecture, permettent de mettre en place ce mode de communication, pour citer les plus connus :
- Le protocole websocket permettant l’ouverture de canaux pour établir une communication bidirectionnelle entre serveur et client,
- Les mécanismes de CallBack et Webhooks,
- Les constructions réalisées avec des MOMs, basées sur des queues / topics d’aller et d’autres de retour, qui se traduisent en patterns request / reply implémentés par certains de ces outils,
- Basés sur des solutions similaires au précédent point, des patterns d’architecture custom permettant de gérer ces aller-retours entre applications.
Les patterns schématisés ci-dessous ne sont pas exhaustifs mais ont pour objectif de montrer des exemples réels de contraintes, en termes de flux, apportées par les trois modes : synchrone, asynchrone pull et asynchrone push.
- Synchrone
- Asynchrone Pull
- Asynchrone Push
Mais alors, push ou pull ?
L’utilisation d’un pattern par rapport à l’autre doit être réfléchie, car donner un avis tranché sur la meilleure solution est assez compliqué sans connaître l’environnement et les contraintes. Les deux techniques sont fondamentalement faisables mais le choix dépendra du besoin réel, des patterns supportés par les socles déjà déployés et des applications difficilement intégrables en synchrone.
Notre avis est d’éviter au maximum les solutions pull, car ces méthodes impliquent des aller-retour inutiles entre les applications.
Comment mettre du liant entre aller et retour ?
La mise en place d’une API asynchrone présuppose donc une certaine attention à l’intégrité fonctionnelle entre la requête et la réponse, qui ne sont pas, dans le cas de l’asynchronisme, forcément liées par la même transaction.
Pour garantir l’intégrité fonctionnelle et le lien entre la requête et la réponse, surtout dans le cas d’une notification PUSH, un échange d’informations pour identifier et coupler les deux étapes est nécessaire. L’utilisation d’informations spécifiques dans l’entête des requêtes, comme dans le cas d’APIs synchrones, est une solution performante, tout en s’assurant d’avoir mis en place les bonnes pratiques de sécurité visant à éviter l’intrusion de tiers dans la communication. Sans vouloir réinventer la roue, les mécanismes déjà en place pour d’autres technologies peuvent être repris, comme par exemple les identifiants de corrélation, chers au MOMs, identifiants qui permettent de créer un lien entre les différentes communications.
Si on utilise des mécanismes non natifs aux API, pourquoi passer par une API et pas par un autre moyen asynchrone ?
Le choix de passer par une API a plusieurs raisons, suivant le cas d’usage :
- c’est le standard actuel auquel la plupart des solutions ont adhéré, avec un fonctionnement API first même si le besoin est asynchrone
- l’éventuelle gestion par API gateway, rendue possible sur une construction asynchrone par cette solution, demeure très pratique pour la gestion des échanges, avec des avantages que les protocoles / solutions asynchrones classiques ne sont pas prêts d’intégrer
Cela ne limite pas pour autant le spectre d’APIs asynchrones au seul HTTP. Bien que le standard OpenAPI soit fortement focalisé HTTP, d’autres standards ont été conçus expressément pour les cas d’usage asynchrone.
Exemple, la spécification AsyncAPI. Cette spécification se veut agnostique du protocole de communication avec le serveur, qui peut être du HTTP, mais également du AMQP, MQTT, Kafka, STOMP, etc. standards normalement employés par des MOMs.
Conclusion
En conclusion, notre conviction est que l’asynchronisme est vraiment la pièce manquante aux approches API. L’APIsation a été un formidable bond en termes de standardisation des interfaces mais reste jusque là coincée dans son carcan synchrone. L’heure de la pleine maturité a sonnée !




